@evanh said:
The Edge Card has an SD slot. I gather you're thinking of using two at once then?
No, I only need one. I still just don't trust booting off flash and then accessing the on board SD card reader on the P2 Edge (even though that is the simplest/preferable solution). I hate the idea of it locking up and preventing boot unless the system is manually powered down. If I could safely use the on board reader along with SPI flash for booting I'd just get one of these and route it to the front or back panel somewhere. I guess if I can make the front panel switch power off the system I might at least have a way to reset in case of problems.
I'm making progress again with details of smartpin/streamer/bit-bash timing interactions of using the SD command set in 4-bit mode. Every line of assembly has to be checked and tested and thrashed out over and over. Assumptions about what is happening is such a bug fest! I guess I'm not helping by testing and comparing about four alternative solutions at the same time. The start-bit search method has been something of thorn. It's funny, I get bogged down and too tired to concentrate from the myriad of ideas and options popping up as I go. I enjoy the puzzle too much I suspect. Never getting to the end.
I did think I'd be well into integrating with Flexspin's FAT filesystem by now but alas I've not even touched that beyond checking that the #ifdef switch works for flipped back and forth with the SPI based driver.
It's funny, I get bogged down and too tired to concentrate from the myriad of ideas and options popping up as I go. I enjoy the puzzle too much I suspect. Never getting to the end.
In this case, maybe best to just focus on one piece at a time until it works. Eg. single sector reads, then single sector writes, then try multi-reads etc.
I can't help myself. I want to optimise as I go. It's all good. I'm much happier that I've put the time in to tests the options. Learnt behaviours of the hardware.
Gotta write this one down! I've bumped into some really specific bug in one of my methods ...
CMD17 "single block read" fails to wait on a WAITSE1 instruction on every fourth block of the SD card, offset +2 (eg: block 2, block 6, block 10, ...). Moving the WAITSE1 out of Fcache fixes it, changing it to a WAITSE2 fixes it, and changing the call path also makes it go away. All of these are fully repeatable.
I can't see any change in behaviour coming from the SD card with the different block numbers, and indeed a different SD card makes no diff either. Err, I didn't look at the scope close enough. Changing to an SD card with longer block latency fails on all block numbers. So latency is a factor I guess ... WAITSE2 still fixes it in this situation.
I've done compares of the compiled binaries with the only diff being these two instructions ... and their encoding checks out.
This is buggy:
setse1 #0b001<<6 | PIN_CLK // trigger on rising edge
waitse1 // wait for clocking to complete
This is fine:
setse2 #0b001<<6 | PIN_CLK // trigger on rising edge
waitse2 // wait for clocking to complete
Well that sounds curious. My best guess would be that there's a hazard between SETSEx and WAITSEx, so if SE1 was previously set, it might not get unset fast enough. Though that doesn't track with the regular pattern... Does putting a NOP inbetween work? What is the previous SE1?
@Wuerfel_21 said:
Well that sounds curious. My best guess would be that there's a hazard between SETSEx and WAITSEx, so if SE1 was previously set, it might not get unset fast enough. Though that doesn't track with the regular pattern... Does putting a NOP inbetween work? What is the previous SE1?
Tried that and also uses of POLLSE1. No effect.
PS: Here's a fuller snippet of the offending code:
fltl #PIN_CLK
wrpin mclk, #PIN_CLK // revert to regular clock gen
wxpin mclkr, #PIN_CLK
// start-bit found, now read the data block
xinit mleadin, #0 // lead-in delay from here at sysclock/1
setq mnco // streamer transfer rate (takes effect with buffered command below)
xzero mdat, #0 // rx buffered-op, aligned with clock via lead-in
dirh #PIN_CLK // clock timing starts here
wypin clocks, #PIN_CLK // first pulse outputs during second clock period
rdpin j, #PIN_CD // count of latency clocks searching for start-bit
// begin thumb twiddling
// CRC check of five-byte response, Reference code courtesy of Ariba
loc ptrb, #resp
mov pb, #5
mov crc, #0
cr7lp
rdbyte pa, ptrb++
movbyts pa, #0b00_01_10_11
setq pa
crcnib crc, #0x48 // CCITT polynomial is 1 + x3 + x7 (0x09 reversed for CRCNIB)
crcnib crc, #0x48
djnz pb, #cr7lp
// end thumb twiddling
setse1 #0b110<<6 | PIN_CLK // trigger on high level
waitse1 // wait for clocking to complete
// waitxfi // wait for rx data completion before resuming hubexec
ret
Huh, I was applying the full 100 ms spec'd timeout to block latency during the start-bit search and decided to also swap it's WAITSE1 to a WAITSE2. And guess what, that flipped the bug around. It's now buggy with a WAITSE2 on the block completion instead of with WAITSE1.
So it's not a timeout problem, it didn't have a timeout and now it does. But that event setup in the start-bit search code has a lingering effect of some sort ... here's the whole function:
static uint32_t rxblock( const uint8_t * buf, const uint32_t rxlag )
{
uint32_t i, j, crc;
// locate data block start-bit
_pinf( PIN_DAT );
_pinf( PIN_CD ); // reset latency counter
_pinstart( PIN_CLK, P_PWM_SMPS | P_OE | P_INVERT_OUTPUT | // clock gen stops when PIN_DAT3 goes low
(PIN_DAT3 - PIN_CLK & 7)<<28 | P_INVERT_A | // smartA input select
(PIN_DAT3 - PIN_CLK & 7)<<24 | P_INVERT_B, // smartB input select
1 | 10<<16, 5 ); // clock rate of sysclock/10
__asm {
getct j
add j, ##_clkfreq / 10 // SDHC 100 ms timeout of start-bit search, Nac (SD spec 4.12.4)
setse2 #0b100<<6 | PIN_DAT3 // trigger on low level, preferred to falling edge trigger
// because DAT pins idle high during command and response and also ensures best chance
// of seeing an early start-bit.
}
_pinl( PIN_CD ); // latency counter
__asm volatile { // "volatile" enforces unoptimised use of FCACHE
wrfast nowait, buf // setup FIFO for streamer use
setxfrq nowait // set streamer to sysclock/1 for lead-in timing
add mleadin, rxlag // adjust lead-in delay for rx lag compensation
setq j // apply the 100 ms timeout
waitse2 wc // wait for start-bit, C is set if timed-out
dirl #PIN_CLK
wrpin mclk, #PIN_CLK // revert to regular clock gen
wxpin mclkr, #PIN_CLK
// start-bit found, now read the data block
if_nc xinit mleadin, #0 // lead-in delay from here at sysclock/1
if_nc setq mnco // streamer transfer rate (takes effect with buffered command below)
if_nc xzero mdat, #0 // rx buffered-op, aligned with clock via lead-in
dirh #PIN_CLK // clock timing starts here
if_nc wypin clocks, #PIN_CLK // first pulse outputs during second clock period
rdpin j, #PIN_CD // count of latency clocks searching for start-bit
// begin thumb twiddling
// CRC check of five-byte response, Reference code courtesy of Ariba
loc ptrb, #resp
mov pb, #5
mov crc, #0
cr7lp
rdbyte pa, ptrb++
movbyts pa, #0b00_01_10_11
setq pa
crcnib crc, #0x48 // CCITT polynomial is 1 + x3 + x7 (0x09 reversed for CRCNIB)
crcnib crc, #0x48
djnz pb, #cr7lp
// end thumb twiddling
if_nc setse2 #0b110<<6 | PIN_CLK // trigger on high level
if_nc waitse2 // wait for clocking to complete
// waitxfi // wait for rx data completion before resuming hubexec
ret
mclk long P_PULSE | P_OE | P_INVERT_OUTPUT | P_SCHMITT_A
mclkr long DAT_DIV | DAT_DIV/2<<16
clocks long 512 * 2 + 16 + 1 // nibble count + 16-bit CRC + stop-bit
nowait long 0x8000_0000 // tells RDFAST/WRFAST not to wait for FIFO ready
mnco long 0x8000_0000UL / DAT_DIV + (0x8000_0000UL % DAT_DIV > 0UL ? 1 : 0) // round up upon non-zero remainder
mleadin long X_IMM_32X1_1DAC1 | DAT_DIV * 2 + 9 // + rxlag, first nibble to store is subsequent to the start-bit
mdat long X_4P_1DAC4_WFBYTE | PIN_DAT0<<17 | X_PINS_ON | X_ALT_ON | 512 * 2 // mode and nibble count
}
_pinf( PIN_CD ); // reset latency counter
crc = _rev( crc )>>24 | 1;
#ifdef _DIAG
printf( " CRC = %02x Data latency = %d clocks\n", crc, j );
// for( i = 0; i <= 799/32; i++ ) { // diag
for( j = 0; j < 32; j++ )
// printf( " %02x", buf[i*32+j] );
printf( " %02x", buf[j] );
puts("");
// }
#endif
return crc; // calculated CRC of command response - with stop-bit added
}
@evanh said:
... But that event setup in the start-bit search code has a lingering effect of some sort ...
It doesn't make any sense. I've got a response handler that uses SETSE1/WAITSE1 pairs three times in one function, including a timeout in the middle, and never had this sort of bug with that.
I wonder if things like this are a result of doing the SETSEn instruction while the condition itself is true, vs the condition being false at the time, then soon followed by the WAITSEn instruction.
I'm now getting quicker/easier results by measuring the bug's impact using a smartpin counter, and debugging code enabled, instead of having to rely on the oscilloscope. And with help from the more frequent occurrences of the second SD card, seems I was wrong about the call path too. The bug is happening both ways.
I had thought it only occurred when debugging was off. But that was just when it became obvious on the scope.
Oh, wow, you were both right. It was totally a lingering event trigger. My previous tests using POLLSEn to clear it were always placed immediately following the SETSEn - which didn't work. It needs one instruction spacing after the SETSEn before adding a POLLSEn to guarantee any prior active trigger won't interfere. eg:
setse2 #0b110<<6 | PIN_CLK // trigger on high level
nop
pollse2
waitse2
PS: This shows up most severely with level triggering, but it's not impossible for a badly timed edge trigger to also glitch a reused SETSEn transition.
setse2 #0 // cancel active trigger before reuse
setse2 #0b110<<6 | PIN_CLK // trigger on high level
waitse2
I'm going to class this as a bug in the Verilog code for SETSEn instructions ... or all event setup instructions. err, it can only apply to selectable event sources, so SETPAT may be another.
It's same glitch effect that occurs when switching ADC input sources, and when changing the sysclock source too. Hence the shenanigans with multiple HUBSET's to reliably change frequency.
Okay, in light of this, I've made a design decision to setup SETSE1 upon each fresh SD command and it solely is used for checking the clock smartpin completion. All other event uses are now performed using SE2 as needed. Both are also reset ahead of each fresh command.
@evanh said:
Oh, wow, you were both right. It was totally a lingering event trigger. My previous tests using POLLSEn to clear it were always placed immediately following the SETSEn - which didn't work. It needs one instruction spacing after the SETSEn before adding a POLLSEn to guarantee any prior active trigger won't interfere.
Ah, thanks. I already knew that the event system is edge triggered, e.g. an event which state is already active won't cause a trigger if not cleared previously. But I didn't know that there is a NOP necessary.
Ah, it's faster to reset the event hardware than adding nop+poll. See the second post - https://forums.parallax.com/discussion/comment/1558763/#Comment_1558763.
What I've found is not about the retriggering mechanism of recurring events. That works fine. What I've found is a flaw in the SETSEn instructions, in how they initially configure and arm those events.
@Wuerfel_21 said:
The real problem I think is that CMD and DAT activity can overlap. So you need to do this sort of waiting for the start bit on both CMD and DAT0 simulataneously. I think, anyways.
@rogloh said:
I was concerned about this overlap too although I never saw any overlap in my testing, but in theory based on that diagram I guess it could happen.
Not seeing that happen either. My guess is it can only happen if command queuing is enabled. Ie: A particular block read data out is never going to start before its accompanying command response is already out.
Roger, A minor refinement to the full SD wiring - Reading the spec, the DAT pins aren't meant to have any pull-ups. You won't need the second resistor network component in later revision.
DAT3 (Pin 2 of the uSD card) in particular has a controllable internal 50k pull-up within the card, defaults on. This is intended as an alternative Card Detect mechanism. No biggie though, I like how you've done the card detect with your add-on board.
EDIT: Fixed the pin number. uSD is different pin order!
EDIT2: Hmm, that's weird. It seems I'm making too many assumptions again. I've found an "example" within the spec PDF itself. I got a problem with it though. There is two pull-up resistors on DAT3. I'm not sure how that is meant to perform as a card detect.
BTW, I like that you've got a pull-up on the CLK pin. I'm now relying on that during the power cycling as a known card input to ensure no chance the card glitching the pin during power up or down. With that CLK pull-up, I can measure the charge/discharge of the power rail so thereby measure when the spec is truly met. Particularly during power down where the supply capacitor discharges at different rates depending on individual SD Card inserted.
@evanh said:
BTW, I like that you've got a pull-up on the CLK pin...
Yeah having (slightly weak) pullups/pulldowns as appropriate on most signals in general are useful. Floating inputs are never ideal and the resistors helps stabilize things faster after any hot swap.
Due the availability of extra GPIO pins on the breakout I made use of real HW switch signals on the reader itself to detect the card presence instead of the pullup option which may require talking to the card first to activate/deactivate etc, while any COGs can easily passively monitor the IO pin state on their own and/or use it to trigger interrupts to perform other operations etc. Simpler is sometimes better.
Just been bashing my head trying to use the official CMD19 tuning for my rx timing calibration. This would've been a nice to have solution as I'm not entirely happy with my current solution using basic responses.
Alas it wasn't to be. Should have realised it earlier of course. Have just searched the PDF for when CMD19 can be use and surprise surprise found the SD card needs switched to a UHS mode first:
CMD19 sends a tuning block to the host to determine sampling point.
UHS50 and UHS104 cards support CMD19 in 1.8V signaling. Sampling clock
tuning is required for UHS104 host and optional for UHS50 host.
PS: Had done a nice commented reference table of the tuning pattern too:
Just chased down a glaring and significant bug that wasn't causing any problem until a special combination of tight timing occurred. Again, it hit me in the face once I dug out the scope and looked. The CMD out to clock phase was 180 deg out! It is amazing there wasn't a cacophony of errors from it.
The only place it showed any problem was with a CMD12 cancellation command when I switched to sysclock/2 and using a faster turnaround of CMD output to response start-bit searching. Strangely it created a truncated command. So it still wasn't the bad phasing causing any issue. It was the almost entirely missing CRC at the end of the command. Short by six bits.
The root cause had been weeks back when I added an entirely different feature - The ability to toggle the compiling between use of PULSE and TRANSITION modes for smartpin clock gen. In the process I'd made an assumption about the CMD tx/clock phase adjustment when using transition mode but I'd never verified the assumption.
And I don't yet have an explanation for the truncated CRC either - Since it has come right on its own with the correct phase adjustment.
Doh! LOL, I'd switched out the fast test routine. The bug wasn't fixed at all. Turns out the bad clock phase still wasn't causing any issue. It was just an incidental find.
The actual bug is a crappy one. Very poorly thought out hack. Another one I'd also added a some weeks back. It was triggering an unexpected clocks-complete event that then meant the start-bit search kicked off before the command transmit was complete.


Comments
The Edge Card has an SD slot. I gather you're thinking of using two at once then?
Having an I2C port might be handy.
No, I only need one. I still just don't trust booting off flash and then accessing the on board SD card reader on the P2 Edge (even though that is the simplest/preferable solution). I hate the idea of it locking up and preventing boot unless the system is manually powered down. If I could safely use the on board reader along with SPI flash for booting I'd just get one of these and route it to the front or back panel somewhere. I guess if I can make the front panel switch power off the system I might at least have a way to reset in case of problems.
https://www.ebay.com.au/itm/162837010654
Yeah was thinking about that as well.
I'm making progress again with details of smartpin/streamer/bit-bash timing interactions of using the SD command set in 4-bit mode. Every line of assembly has to be checked and tested and thrashed out over and over. Assumptions about what is happening is such a bug fest! I guess I'm not helping by testing and comparing about four alternative solutions at the same time. The start-bit search method has been something of thorn. It's funny, I get bogged down and too tired to concentrate from the myriad of ideas and options popping up as I go. I enjoy the puzzle too much I suspect. Never getting to the end.
I did think I'd be well into integrating with Flexspin's FAT filesystem by now but alas I've not even touched that beyond checking that the #ifdef switch works for flipped back and forth with the SPI based driver.
In this case, maybe best to just focus on one piece at a time until it works. Eg. single sector reads, then single sector writes, then try multi-reads etc.
I can't help myself. I want to optimise as I go. It's all good. I'm much happier that I've put the time in to tests the options. Learnt behaviours of the hardware.
Gotta write this one down! I've bumped into some really specific bug in one of my methods ...
CMD17 "single block read" fails to wait on a WAITSE1 instruction on every fourth block of the SD card, offset +2 (eg: block 2, block 6, block 10, ...). Moving the WAITSE1 out of Fcache fixes it, changing it to a WAITSE2 fixes it, and changing the call path also makes it go away. All of these are fully repeatable.
I can't see any change in behaviour coming from the SD card with the different block numbers, and indeed a different SD card makes no diff either. Err, I didn't look at the scope close enough. Changing to an SD card with longer block latency fails on all block numbers. So latency is a factor I guess ... WAITSE2 still fixes it in this situation.
I've done compares of the compiled binaries with the only diff being these two instructions ... and their encoding checks out.
This is buggy:
setse1 #0b001<<6 | PIN_CLK // trigger on rising edge waitse1 // wait for clocking to completeThis is fine:
setse2 #0b001<<6 | PIN_CLK // trigger on rising edge waitse2 // wait for clocking to completeWell that sounds curious. My best guess would be that there's a hazard between SETSEx and WAITSEx, so if SE1 was previously set, it might not get unset fast enough. Though that doesn't track with the regular pattern... Does putting a NOP inbetween work? What is the previous SE1?
Okay, I now wonder if a prior event timeout setting that is done with SE1 might be lingering ...
Tried that and also uses of POLLSE1. No effect.
PS: Here's a fuller snippet of the offending code:
fltl #PIN_CLK wrpin mclk, #PIN_CLK // revert to regular clock gen wxpin mclkr, #PIN_CLK // start-bit found, now read the data block xinit mleadin, #0 // lead-in delay from here at sysclock/1 setq mnco // streamer transfer rate (takes effect with buffered command below) xzero mdat, #0 // rx buffered-op, aligned with clock via lead-in dirh #PIN_CLK // clock timing starts here wypin clocks, #PIN_CLK // first pulse outputs during second clock period rdpin j, #PIN_CD // count of latency clocks searching for start-bit // begin thumb twiddling // CRC check of five-byte response, Reference code courtesy of Ariba loc ptrb, #resp mov pb, #5 mov crc, #0 cr7lp rdbyte pa, ptrb++ movbyts pa, #0b00_01_10_11 setq pa crcnib crc, #0x48 // CCITT polynomial is 1 + x3 + x7 (0x09 reversed for CRCNIB) crcnib crc, #0x48 djnz pb, #cr7lp // end thumb twiddling setse1 #0b110<<6 | PIN_CLK // trigger on high level waitse1 // wait for clocking to complete // waitxfi // wait for rx data completion before resuming hubexec retHuh, I was applying the full 100 ms spec'd timeout to block latency during the start-bit search and decided to also swap it's WAITSE1 to a WAITSE2. And guess what, that flipped the bug around. It's now buggy with a WAITSE2 on the block completion instead of with WAITSE1.
So it's not a timeout problem, it didn't have a timeout and now it does. But that event setup in the start-bit search code has a lingering effect of some sort ... here's the whole function:
static uint32_t rxblock( const uint8_t * buf, const uint32_t rxlag ) { uint32_t i, j, crc; // locate data block start-bit _pinf( PIN_DAT ); _pinf( PIN_CD ); // reset latency counter _pinstart( PIN_CLK, P_PWM_SMPS | P_OE | P_INVERT_OUTPUT | // clock gen stops when PIN_DAT3 goes low (PIN_DAT3 - PIN_CLK & 7)<<28 | P_INVERT_A | // smartA input select (PIN_DAT3 - PIN_CLK & 7)<<24 | P_INVERT_B, // smartB input select 1 | 10<<16, 5 ); // clock rate of sysclock/10 __asm { getct j add j, ##_clkfreq / 10 // SDHC 100 ms timeout of start-bit search, Nac (SD spec 4.12.4) setse2 #0b100<<6 | PIN_DAT3 // trigger on low level, preferred to falling edge trigger // because DAT pins idle high during command and response and also ensures best chance // of seeing an early start-bit. } _pinl( PIN_CD ); // latency counter __asm volatile { // "volatile" enforces unoptimised use of FCACHE wrfast nowait, buf // setup FIFO for streamer use setxfrq nowait // set streamer to sysclock/1 for lead-in timing add mleadin, rxlag // adjust lead-in delay for rx lag compensation setq j // apply the 100 ms timeout waitse2 wc // wait for start-bit, C is set if timed-out dirl #PIN_CLK wrpin mclk, #PIN_CLK // revert to regular clock gen wxpin mclkr, #PIN_CLK // start-bit found, now read the data block if_nc xinit mleadin, #0 // lead-in delay from here at sysclock/1 if_nc setq mnco // streamer transfer rate (takes effect with buffered command below) if_nc xzero mdat, #0 // rx buffered-op, aligned with clock via lead-in dirh #PIN_CLK // clock timing starts here if_nc wypin clocks, #PIN_CLK // first pulse outputs during second clock period rdpin j, #PIN_CD // count of latency clocks searching for start-bit // begin thumb twiddling // CRC check of five-byte response, Reference code courtesy of Ariba loc ptrb, #resp mov pb, #5 mov crc, #0 cr7lp rdbyte pa, ptrb++ movbyts pa, #0b00_01_10_11 setq pa crcnib crc, #0x48 // CCITT polynomial is 1 + x3 + x7 (0x09 reversed for CRCNIB) crcnib crc, #0x48 djnz pb, #cr7lp // end thumb twiddling if_nc setse2 #0b110<<6 | PIN_CLK // trigger on high level if_nc waitse2 // wait for clocking to complete // waitxfi // wait for rx data completion before resuming hubexec ret mclk long P_PULSE | P_OE | P_INVERT_OUTPUT | P_SCHMITT_A mclkr long DAT_DIV | DAT_DIV/2<<16 clocks long 512 * 2 + 16 + 1 // nibble count + 16-bit CRC + stop-bit nowait long 0x8000_0000 // tells RDFAST/WRFAST not to wait for FIFO ready mnco long 0x8000_0000UL / DAT_DIV + (0x8000_0000UL % DAT_DIV > 0UL ? 1 : 0) // round up upon non-zero remainder mleadin long X_IMM_32X1_1DAC1 | DAT_DIV * 2 + 9 // + rxlag, first nibble to store is subsequent to the start-bit mdat long X_4P_1DAC4_WFBYTE | PIN_DAT0<<17 | X_PINS_ON | X_ALT_ON | 512 * 2 // mode and nibble count } _pinf( PIN_CD ); // reset latency counter crc = _rev( crc )>>24 | 1; #ifdef _DIAG printf( " CRC = %02x Data latency = %d clocks\n", crc, j ); // for( i = 0; i <= 799/32; i++ ) { // diag for( j = 0; j < 32; j++ ) // printf( " %02x", buf[i*32+j] ); printf( " %02x", buf[j] ); puts(""); // } #endif return crc; // calculated CRC of command response - with stop-bit added }It doesn't make any sense. I've got a response handler that uses SETSE1/WAITSE1 pairs three times in one function, including a timeout in the middle, and never had this sort of bug with that.
I wonder if things like this are a result of doing the SETSEn instruction while the condition itself is true, vs the condition being false at the time, then soon followed by the WAITSEn instruction.
SETSEx is meant to clear any prior event. And I've also tried using POLLSE1 to do the same. I tried again about 15 minutes ago.
I'm now getting quicker/easier results by measuring the bug's impact using a smartpin counter, and debugging code enabled, instead of having to rely on the oscilloscope. And with help from the more frequent occurrences of the second SD card, seems I was wrong about the call path too. The bug is happening both ways.
I had thought it only occurred when debugging was off. But that was just when it became obvious on the scope.
Still can't explain why it happens though.
Oh, wow, you were both right. It was totally a lingering event trigger. My previous tests using POLLSEn to clear it were always placed immediately following the SETSEn - which didn't work. It needs one instruction spacing after the SETSEn before adding a POLLSEn to guarantee any prior active trigger won't interfere. eg:
setse2 #0b110<<6 | PIN_CLK // trigger on high level nop pollse2 waitse2PS: This shows up most severely with level triggering, but it's not impossible for a badly timed edge trigger to also glitch a reused SETSEn transition.
Ha! An improvement:
setse2 #0 // cancel active trigger before reuse setse2 #0b110<<6 | PIN_CLK // trigger on high level waitse2I'm going to class this as a bug in the Verilog code for SETSEn instructions ... or all event setup instructions. err, it can only apply to selectable event sources, so SETPAT may be another.
It's same glitch effect that occurs when switching ADC input sources, and when changing the sysclock source too. Hence the shenanigans with multiple HUBSET's to reliably change frequency.
Okay, in light of this, I've made a design decision to setup SETSE1 upon each fresh SD command and it solely is used for checking the clock smartpin completion. All other event uses are now performed using SE2 as needed. Both are also reset ahead of each fresh command.
Ah, thanks. I already knew that the event system is edge triggered, e.g. an event which state is already active won't cause a trigger if not cleared previously. But I didn't know that there is a NOP necessary.
Ah, it's faster to reset the event hardware than adding nop+poll. See the second post - https://forums.parallax.com/discussion/comment/1558763/#Comment_1558763.
What I've found is not about the retriggering mechanism of recurring events. That works fine. What I've found is a flaw in the SETSEn instructions, in how they initially configure and arm those events.
And I've now made a demo program for the tricks'n'traps - https://forums.parallax.com/discussion/comment/1558770/#Comment_1558770
Not seeing that happen either. My guess is it can only happen if command queuing is enabled. Ie: A particular block read data out is never going to start before its accompanying command response is already out.
Roger,
A minor refinement to the full SD wiring - Reading the spec, the DAT pins aren't meant to have any pull-ups. You won't need the second resistor network component in later revision.
DAT3 (Pin 2 of the uSD card) in particular has a controllable internal 50k pull-up within the card, defaults on. This is intended as an alternative Card Detect mechanism. No biggie though, I like how you've done the card detect with your add-on board.
EDIT: Fixed the pin number. uSD is different pin order!
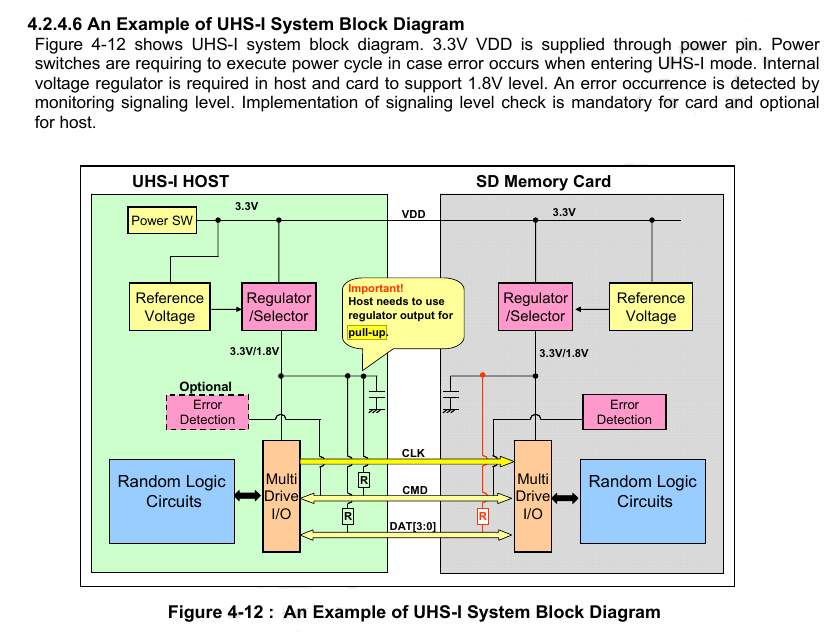
EDIT2: Hmm, that's weird. It seems I'm making too many assumptions again. I've found an "example" within the spec PDF itself. I got a problem with it though. There is two pull-up resistors on DAT3. I'm not sure how that is meant to perform as a card detect.
BTW, I like that you've got a pull-up on the CLK pin. I'm now relying on that during the power cycling as a known card input to ensure no chance the card glitching the pin during power up or down. With that CLK pull-up, I can measure the charge/discharge of the power rail so thereby measure when the spec is truly met. Particularly during power down where the supply capacitor discharges at different rates depending on individual SD Card inserted.
EDIT: A little rewording for clarity.
Yeah having (slightly weak) pullups/pulldowns as appropriate on most signals in general are useful. Floating inputs are never ideal and the resistors helps stabilize things faster after any hot swap.
Due the availability of extra GPIO pins on the breakout I made use of real HW switch signals on the reader itself to detect the card presence instead of the pullup option which may require talking to the card first to activate/deactivate etc, while any COGs can easily passively monitor the IO pin state on their own and/or use it to trigger interrupts to perform other operations etc. Simpler is sometimes better.
Just been bashing my head trying to use the official CMD19 tuning for my rx timing calibration. This would've been a nice to have solution as I'm not entirely happy with my current solution using basic responses.
Alas it wasn't to be. Should have realised it earlier of course. Have just searched the PDF for when CMD19 can be use and surprise surprise found the SD card needs switched to a UHS mode first:
PS: Had done a nice commented reference table of the tuning pattern too:
static uint8_t calpat[136] = { 0xFF,0x0F,0xFF,0x00,0xFF,0xCC,0xC3,0xCC,0xC3,0x3C,0xCC,0xFF,0xFE,0xFF,0xFE,0xEF, 0xFF,0xDF,0xFF,0xDD,0xFF,0xFB,0xFF,0xFB,0xBF,0xFF,0x7F,0xFF,0x77,0xF7,0xBD,0xEF, 0xFF,0xF0,0xFF,0xF0,0x0F,0xFC,0xCC,0x3C,0xCC,0x33,0xCC,0xCF,0xFF,0xEF,0xFF,0xEE, 0xFF,0xFD,0xFF,0xFD,0xDF,0xFF,0xBF,0xFF,0xBB,0xFF,0xF7,0xFF,0xF7,0x7F,0x7B,0xDE, // 4 x serial CRC16 encoded parallel: DAT3=C59Fh A2E5h 8D06h DAT0=E946h 0xF9,0x50,0x3A,0x4B,0xC5,0x48,0x8F,0xBC };Huh, CMD19 is used for UHS-I exclusively. It's illegal in UHS-II, same as 3 Volt modes.
Just chased down a glaring and significant bug that wasn't causing any problem until a special combination of tight timing occurred. Again, it hit me in the face once I dug out the scope and looked. The CMD out to clock phase was 180 deg out! It is amazing there wasn't a cacophony of errors from it.
The only place it showed any problem was with a CMD12 cancellation command when I switched to sysclock/2 and using a faster turnaround of CMD output to response start-bit searching. Strangely it created a truncated command. So it still wasn't the bad phasing causing any issue. It was the almost entirely missing CRC at the end of the command. Short by six bits.
The root cause had been weeks back when I added an entirely different feature - The ability to toggle the compiling between use of PULSE and TRANSITION modes for smartpin clock gen. In the process I'd made an assumption about the CMD tx/clock phase adjustment when using transition mode but I'd never verified the assumption.
And I don't yet have an explanation for the truncated CRC either - Since it has come right on its own with the correct phase adjustment.
Doh! LOL, I'd switched out the fast test routine. The bug wasn't fixed at all. Turns out the bad clock phase still wasn't causing any issue. It was just an incidental find.
The actual bug is a crappy one. Very poorly thought out hack. Another one I'd also added a some weeks back. It was triggering an unexpected clocks-complete event that then meant the start-bit search kicked off before the command transmit was complete.
Two decent bugs crushed! I'm happy.")
Good work fixing bugs. So what is the summary of where you are at now evanh? What can your code do at this stage?