@cgracey said:
I am glad you are using the interpreter. So much thought and effort has gone into it. I think, initially, it was around 4KB. Now it's just a little over 6KB and does WAY more. I am always thinking about how it could be improved and how future silicon could make it faster.
Careful, you'll end up with something that looks a lot like an x86 processor
(in the sense that they optimize for being able to run a set of complex[citation needed] bytecodes really quickly)
I'd guess the biggest cycle contribution on P2 is just grabbing data from the stack in hub RAM at 9..16 cycles cost, which is sort of a general pain point for anything that can't easily be reformulated into using FIFO or block transfer. The actual 6 cycle cost of entering the bytecode handler is probably negligable.
Maybe the trick would be to keep the "live" expression stack as a separate entity in cogRAM. Would have to have the compiler work around it if an expression tree ever gets deeper than 16 or so values...
Stephen Moraco had Claude Opus analyze it to make suggestions for how to make it more efficient. It discovered, by looking at the compiler, too, that NEXT/QUIT are always followed by a pop bytecode, so the NEXT/QUIT bytecodes could also do the pop, automatically. The thing is, those are seldom used and it's probably not worth blowing up the interpreter for, unless there is a very sympathetic way to do it.
Since when would there be a dedicated NEXT/QUIT bytecode? Aren't NEXT/QUIT just jumps (with appropriate pops to clear loop state in front of them)? Don't let yourself get brainrotted by the AI slop, you're too good for that.
Ha, yes, I think they are just jumps. I wasn't at my computer, so I was kind of making stuff up like AI does. The whole thing has gotten so complex that it's hard for me to remember all the details.
I have thought the same things about putting the stack in cog RAM, but the checks for overflows and underflows would be about as long as reading or writing the hub. So, I've kind of come to the conclusion that there needs to be some kind of stack virtualizer that is kind of like the FIFO. Your idea of having the compiler track stack depth is good, but, I think we would need extra bytecodes to handle instances where the stack must be flushed or loaded.
I just remembered that the RDLUT/WRLUT instructions can take PTRA/PTRB expressions, just like RDLONG/WRLONG can. RDLUT tales 3 clocks. whereas RDLONG takes 9-16 clocks. WRLUT takes 2 clocks, whereas WRLONG takes 3-10 clocks. So, the LUT could be used as a faster stack, but then there'd be less room for code. Stack-based machines are easy to design. Working out variable lifetimes for good compilation is a lot more complicated.
Bugfix release to restore the resizable terminal window, as a "bonus" the window shows the width and height in characters while resizing.
Also, updated the offscreen window check, I'm not sure if this fixes the issues with the window position (can't reproduce here) but implements a slightly better check.
The update for PNut v55 is at a good point, it needs some more testing.
Thank you, Marco. Just to show you what I'm seeing, this is the upper-left offset from my screen to the Spin Tools. I think I used the Maximize button yesterday -- could that be affecting what Spin Tools is seeing for size and position?
@JonnyMac said:
Thank you, Marco. Just to show you what I'm seeing, this is the upper-left offset from my screen to the Spin Tools. I think I used the Maximize button yesterday -- could that be affecting what Spin Tools is seeing for size and position?
Ahhh.... yes, the maximized window... there is a subtle difference between Windows and Linux, for some reasons Windows sets negative x and y for a maximized window, this makes the check believe the title bar is offscreen and resets the position.
Sorry, I need to do that better, maybe I shuld also keep track of the maximized state since it isn't restored exactly as it should.
The PNut v55 update is nearly done, I need to do some more tests, I think I can do a release in the weekend or monday, if that's not a big problem I'll do the fix for the complete release.
@cgracey said:
Marco, how did it go witth the new bytecodes?
Good so far, I have implemented the compressed bytecodes in all places, the most difficult were the post effects associated to bitfieds but I think I got them.
I have recompiled with PNut v55 all the tests I have and are all passing.
I need to do a bit more tests to be sure I haven't missed something critical and it is done.
@cgracey said:
Marco, how did it go witth the new bytecodes?
Good so far, I have implemented the compressed bytecodes in all places, the most difficult were the post effects associated to bitfieds but I think I got them.
I have recompiled with PNut v55 all the tests I have and are all passing.
I need to do a bit more tests to be sure I haven't missed something critical and it is done.
Updated Spin2 interpreter and bytecode generation to PNut v55.
Added preferences toolbar icon and shortcut key (F5).
Also added a preferences dialog button to the terminal window to quickly change the terminal preferences.
Reviewed and (hopefully) fixed the offscreen window checks, now also it correctly keeps the maximized window state allowing to restore the "normal" window size (the size and position it had before maximizing) across sessions.
Thank you, Marco! The screen position gotchas I was seeing seem to be resolved. Thank you for adding the F5 hotkey for Preferences, and for the terminal preferences button on that dialog -- that's very handy.
Hi Macca,
I don't know, if this has been discussed before, but here is something like an idea.
I find, that SKIP and XBYTE is the most unreadable part of PASM. XBYTE can be worse, because the skip-encoding might be on another screen than the code block.
So what about making this more readable? The actual code could be shown in another window, while a cursor is visible at the same time in the LUT line at the skip-encoding. Each of the lines of the code block could have a check box, if this line shall be executed and the line should be highlightend, if it's box is checked. Unchecked lines just barely visible. The editor could then "re-calculate" the skip-encoding. This would enable to easily insert a line in the code block.
If another line in the lut table is selected, then the check-boxes shall be updated accordingly.
Cheers Christof
@"Christof Eb." said:
I don't know, if this has been discussed before, but here is something like an idea.
I find, that SKIP and XBYTE is the most unreadable part of PASM. XBYTE can be worse, because the skip-encoding might be on another screen than the code block.
So what about making this more readable? The actual code could be shown in another window, while a cursor is visible at the same time in the LUT line at the skip-encoding. Each of the lines of the code block could have a check box, if this line shall be executed and the line should be highlightend, if it's box is checked. Unchecked lines just barely visible. The editor could then "re-calculate" the skip-encoding. This would enable to easily insert a line in the code block.
If another line in the lut table is selected, then the check-boxes shall be updated accordingly.
That's a good idea, don't know how difficult would be to allow editing.
It could start with a specialized hover doc popup window that display the code pointed by the address label with lines grayed-out if skipped, provided the line uses a recognizable pattern.
If the pattern is something like this:
Hovering on i_branch or i_log_ind_y could display a popup with the code portion starting from that label with the pattern applied (and I just realized that the pattern I have used in that specific case is not much standard since it uses the last 4 bits as cycle counter...).
The editor has a small feature to create the skip patterns.
Enable the block selection with Edit -> Block selection then select the column describing the pattern, then select Edit -> Make skip patter to build the binary pattern and copy to clipboard.
The column should contains letters to indicate executed lines and pipes to indicate skipped lines.
Not much but better than nothing...
Someone (sorry I don't remember who) developed a program to automatically update skip patters in a source, I don't remember the details but maybe it could be a candidate to be used as an external tool, the edited source should be automatically updated after running the program.
@macca said:
Someone (sorry I don't remember who) developed a program to automatically update skip patters in a source, I don't remember the details but maybe it could be a candidate to be used as an external tool, the edited source should be automatically updated after running the program.
I've used skipping just once so far. And even then it wasn't for multifunction code snippets, but rather for extending loop execution conditions beyond just the two C and Z flags. Saved me from needing to add a bunch more test and branch instructions within a performance code block - Which would've also collapsed the existing uses of C and Z.
I am having an issue with Spin Tools popups on macos
When an on-hover popup is active in Spin tools, for example displaying the value of a constant, using the keyboard to switch to another window makes that popup appear on top of that other window. The only way to remove it is to switch back to Spin Tools. This problem also appears in another scenario: if I have an active window that only partially covers Spin Tools window, for example calculator, and I move the mouse pointer so it is over a constant in Spin Tools editor, a popup for the constant appears, and the calculator window disappears completely. When mouse pointer is moved away from the constant, the popup gets hidden, and the calculator window comes back
@"Andrey Demenev" said:
I am having an issue with Spin Tools popups on macos
When an on-hover popup is active in Spin tools, for example displaying the value of a constant, using the keyboard to switch to another window makes that popup appear on top of that other window. The only way to remove it is to switch back to Spin Tools. This problem also appears in another scenario: if I have an active window that only partially covers Spin Tools window, for example calculator, and I move the mouse pointer so it is over a constant in Spin Tools editor, a popup for the constant appears, and the calculator window disappears completely. When mouse pointer is moved away from the constant, the popup gets hidden, and the calculator window comes back
That's a known issue and is common to all OSes, it is also a bit difficult to fix because of how the popup window needs to be handled, I'll see what I can do.


Comments
Ha, yes, I think they are just jumps. I wasn't at my computer, so I was kind of making stuff up like AI does. The whole thing has gotten so complex that it's hard for me to remember all the details.
I have thought the same things about putting the stack in cog RAM, but the checks for overflows and underflows would be about as long as reading or writing the hub. So, I've kind of come to the conclusion that there needs to be some kind of stack virtualizer that is kind of like the FIFO. Your idea of having the compiler track stack depth is good, but, I think we would need extra bytecodes to handle instances where the stack must be flushed or loaded.
Flexspin puts local variables in cogRAM. That is except when referenced. Then they go on the stack.
As such, when writing code, I explicitly create local copies of globals when I know there is repeated use in a function.
PS: I wouldn't know if the interpreter uses cogRAM automatically for locals. Correct me if so.
I just remembered that the RDLUT/WRLUT instructions can take PTRA/PTRB expressions, just like RDLONG/WRLONG can. RDLUT tales 3 clocks. whereas RDLONG takes 9-16 clocks. WRLUT takes 2 clocks, whereas WRLONG takes 3-10 clocks. So, the LUT could be used as a faster stack, but then there'd be less room for code. Stack-based machines are easy to design. Working out variable lifetimes for good compilation is a lot more complicated.
Released version 0.55.1
Bugfix release to restore the resizable terminal window, as a "bonus" the window shows the width and height in characters while resizing.
Also, updated the offscreen window check, I'm not sure if this fixes the issues with the window position (can't reproduce here) but implements a slightly better check.
The update for PNut v55 is at a good point, it needs some more testing.
Thank you, Marco. Just to show you what I'm seeing, this is the upper-left offset from my screen to the Spin Tools. I think I used the Maximize button yesterday -- could that be affecting what Spin Tools is seeing for size and position?
Ahhh.... yes, the maximized window... there is a subtle difference between Windows and Linux, for some reasons Windows sets negative x and y for a maximized window, this makes the check believe the title bar is offscreen and resets the position.
Sorry, I need to do that better, maybe I shuld also keep track of the maximized state since it isn't restored exactly as it should.
The PNut v55 update is nearly done, I need to do some more tests, I think I can do a release in the weekend or monday, if that's not a big problem I'll do the fix for the complete release.
As always, Marco, thank you for your efforts and making Spin Tools better with every release
Marco, how did it go witth the new bytecodes?
Good so far, I have implemented the compressed bytecodes in all places, the most difficult were the post effects associated to bitfieds but I think I got them.
I have recompiled with PNut v55 all the tests I have and are all passing.
I need to do a bit more tests to be sure I haven't missed something critical and it is done.
Okay. Sounds good! Thank you for doing this.
Marco: Would you consider adding a toolbar button that takes us directly to the Preferences dialog?
Also, you may want to add the Spin Tools version number to the main window title.
I noticed Chip did this for PNut and it can be helpful when helping others.
Released version 0.56.0
Updated Spin2 interpreter and bytecode generation to PNut v55.
Added preferences toolbar icon and shortcut key (F5).
Also added a preferences dialog button to the terminal window to quickly change the terminal preferences.
Reviewed and (hopefully) fixed the offscreen window checks, now also it correctly keeps the maximized window state allowing to restore the "normal" window size (the size and position it had before maximizing) across sessions.
Thank you, Marco! The screen position gotchas I was seeing seem to be resolved. Thank you for adding the F5 hotkey for Preferences, and for the terminal preferences button on that dialog -- that's very handy.
Hi Macca,
I don't know, if this has been discussed before, but here is something like an idea.
I find, that SKIP and XBYTE is the most unreadable part of PASM. XBYTE can be worse, because the skip-encoding might be on another screen than the code block.
So what about making this more readable? The actual code could be shown in another window, while a cursor is visible at the same time in the LUT line at the skip-encoding. Each of the lines of the code block could have a check box, if this line shall be executed and the line should be highlightend, if it's box is checked. Unchecked lines just barely visible. The editor could then "re-calculate" the skip-encoding. This would enable to easily insert a line in the code block.
If another line in the lut table is selected, then the check-boxes shall be updated accordingly.
Cheers Christof
That's a good idea, don't know how difficult would be to allow editing.

It could start with a specialized hover doc popup window that display the code pointed by the address label with lines grayed-out if skipped, provided the line uses a recognizable pattern.
If the pattern is something like this:
Hovering on i_branch or i_log_ind_y could display a popup with the code portion starting from that label with the pattern applied (and I just realized that the pattern I have used in that specific case is not much standard since it uses the last 4 bits as cycle counter...).
The editor has a small feature to create the skip patterns.
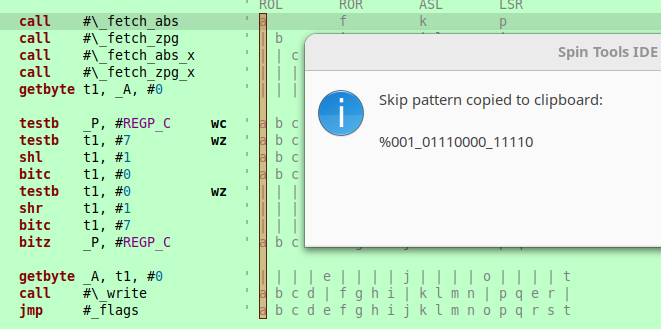
Enable the block selection with Edit -> Block selection then select the column describing the pattern, then select Edit -> Make skip patter to build the binary pattern and copy to clipboard.
The column should contains letters to indicate executed lines and pipes to indicate skipped lines.
Not much but better than nothing...
Someone (sorry I don't remember who) developed a program to automatically update skip patters in a source, I don't remember the details but maybe it could be a candidate to be used as an external tool, the edited source should be automatically updated after running the program.
That's me. Old post:
https://forums.parallax.com/discussion/171125/skip-patterns-generated-automatically
Zip file is out-of-date. I doubt anyone else has tried my skip pattern generator but I use it all the time.
I've used skipping just once so far. And even then it wasn't for multifunction code snippets, but rather for extending loop execution conditions beyond just the two C and Z flags. Saved me from needing to add a bunch more test and branch instructions within a performance code block - Which would've also collapsed the existing uses of C and Z.
I am having an issue with Spin Tools popups on macos
When an on-hover popup is active in Spin tools, for example displaying the value of a constant, using the keyboard to switch to another window makes that popup appear on top of that other window. The only way to remove it is to switch back to Spin Tools. This problem also appears in another scenario: if I have an active window that only partially covers Spin Tools window, for example calculator, and I move the mouse pointer so it is over a constant in Spin Tools editor, a popup for the constant appears, and the calculator window disappears completely. When mouse pointer is moved away from the constant, the popup gets hidden, and the calculator window comes back
That's a known issue and is common to all OSes, it is also a bit difficult to fix because of how the popup window needs to be handled, I'll see what I can do.
Was looking for something else in the Spin2 documentation and came across this feature -- it works in PNut but not in Spin Tools.
Since it only uses constant values the table can be created in a dat section.
Here's the original code in PNut