

Console Emulation
 System
Posts: 46
System
Posts: 46
in Propeller 2
This discussion was created from comments split from: SNEcog for P2.
Comments
Emulator Info Center
To avoid having to comb through this entire thread, I have edited this topmost post to collect the most important info:
MegaYume is a SEGA Megadrive Emulator for P2+PSRAM, it can be found here: https://github.com/IRQsome/MegaYume or here: https://git.sr.ht/~wuerfel_21/MegaYume
Similarly, NeoYume emulates SNK NeoGeo AES and lives here: https://github.com/IRQsome/NeoYume or here: https://git.sr.ht/~wuerfel_21/NeoYume
MisoYume, the SNES emulator (get it?) is currently in beta - find ZIP releases in this thread or grab from https://github.com/IRQsome/MisoYume or https://git.sr.ht/~wuerfel_21/MisoYume
(SourceHut mirrors are being evaluted right now... see also the main project page: https://sr.ht/~wuerfel_21/p2-dreamy-emulators/)
Happy gaming!
For more P2 funny business, consider also:
original post below.
The Mega Drive / Genesis Sonic 1 green hill music sets the noise to use channel 2's freq and then sets that to zero. This didn't work properly. Actual PSG-only VGMs probably don't do this. Also, one of the fixed noise frequencies was wrong, I think.
Well, the Mega Drive VDP basically has nothing to do with the TMS9918 anymore. It isn't even compatible (breaking the few Master System games that rely on these compat modes). It is, however, a nice one to emulate, I think, since it has very few settings to it. As far as I can tell, it's just H40 vs H32 and shadow+highlight mode on/off. And the graphics are in a nice sane format (none of the pseudo-bitplane craziness that the SNES has).
We'd also need a semi-cycle-accurate Z80 emu to actually drive the sound. From the research I've done, most games
Also, there's the fun issue that both the 68k and the Z80 have access to cartridge ROM, which is too big (usually between 512K and 4M) to fit in P2 RAM, so some way of giving both low-latency access to external RAM is neccessary.
Anyways, another interesting system to emulate would be the Turbografx/PCEngine. That's just a 6502-like CPU, custom PSG and custom video chip. Could probably even do the Super CD-ROM² system. (which I am told you are required to pronounce as "Super CD ROM ROM"). That wouldn't even require external RAM (8K built-in RAM + 64k VRAM + 256k System card RAM + 64k ADPCM RAM + 2K save RAM = ~400K), unless the Arcade System card and its 2M of DMA-only DRAM is needed.
How low a latency is required?
My current driver can probably do in the ballpark of ~1uS per individual access on a fast P2 > 250MHz. Some of that latency is due to the memory technology (eg. preparing HyperRAM address setup), some is from the mailbox polling latency and some is the overall service overhead maintaining per COG state and executing the request type, such as setting up CS pins/banks/streamer transfer clocks, mailbox notification etc.
Uuhhhh, IDK really. The Z80, as said, needs semi-accurate timing, but I think it has to wait a few cycles to access the bus, so uhhhhhhh IDK. On the 68k side, a memory access usually takes 4 cycles, which for 7.67 MHz 68k clock and 250 MHz P2 clock translates to about 130 P2 cycles, though a lot of that should be spent on the instruction itself. Note that word/long access is always word-aligned. Instructions will probably have to be pre-fetched a couple at a time to improve performance.
I think the ideal way of doing things is to have the RAM code run in both the Z80 and 68k cogs and just use a lock to prevent collisions. The RAM code would be super bare bones, since it mostly just needs to read single values or a few for instruction prefetch. There is the special case of VRAM/CRAM/VSRAM DMA, which would run into the access length limit, but with that the raw bandwidth advantage can make up for overhead.
I did a PC Engine emulator in C++ some 10++ years ago, so I know that system inside out. (well, I used to at least ) It is very simple in every way and it is without doubt possible to get running on the P2 in full speed. I have the source code laying around still. It emulated like 98% of all games perfectly and the other 2% had graphics glitces because they used raster interrupts with extremely tight timing and my bus arbitration code didn't work exactly as the real machine. There were no documentation easily available (at that time) of exactly how it worked, so I pretty much did shot in the dark. But I didn't use any tricks to get games working like Ootake did. Ootake checked for specific rom files and manipulated the timings to get the games running.
) It is very simple in every way and it is without doubt possible to get running on the P2 in full speed. I have the source code laying around still. It emulated like 98% of all games perfectly and the other 2% had graphics glitces because they used raster interrupts with extremely tight timing and my bus arbitration code didn't work exactly as the real machine. There were no documentation easily available (at that time) of exactly how it worked, so I pretty much did shot in the dark. But I didn't use any tricks to get games working like Ootake did. Ootake checked for specific rom files and manipulated the timings to get the games running.
I like how PC Engine games used character scrolling, sprites and raster interrupt tricks to emulate parallax scrolling and many layers. Some games could even fool you that you really played a Genesis or SNES instead.
These games springs to mind:
The PC Engine actually beat both the SNES and Genesis when it came to the number of colors on a single screen with its 16 backgrounds + 16 sprite palettes, each with 4 bits / 16 colors. (well a little bit less with the transparent sprite colors). The PSG was the worst part of the system and didn't allow any kind of modulation. While you could do arbitrary waveforms, 32 sample in size. You still couldn't update those samples while the PSG was running audio. (if I remember correctly) But, you could set an audio channel to output samples instead of the normal arbitrary waveforms, but that needed timer interrupts + CPU intervention, so games didn't use that feature very much.
Wow, that's awesome!
I really love the animated sequences in the CD-ROM² games. Whoever decided not to include video decompression HW was a genius")
Ys I&II has 5 minutes of intro sequence (and another sequence when you beat the first game and advance to the second). And it's for the original 64k system cards. No idea why the names aren't matched to the visuals though.

This game actually has so much music that they couldn't fit it all and so the towns all play PSG music, leading to a very funny moment near the beginning of Ys 2, where you go through a tunnel from the town to the ruins or whatever it was. You just go through a door and suddenly the PSG town music is replaced by very load rock music from the CD.
Yes that is basically a different application. My current memory driver is primarily targeted for real-time video/audio COG use or potentially for a code caching driver + other general purpose access from multiple COGs needing external memory expansion (like a memory mapped filesystem application). For emulators you'll want lowest latency and exclusive or perhaps at most dual COG access, to a single memory bank only, likely making only short random requests. As soon as two COGs need to share it the latency becomes variable and a problem.
A lowest latency driver could probably be developed for the case where only a single bank is used and any burst requests issued always have to be less than the device limit (i.e. not automatically broken up by the memory driver). Without the burst control no priority COG preemption can occur (so no need to load/save current transfer state per COG). With only a single bank the pin control registers can be fixed at startup time instead of read dynamically per bank saving a few more clocks. To save more cycles the driver would also lose its other fancy features like request lists, graphics copies/fills, and read/modify/write masking. For the lowest latency case you'd also want your video output to be read out of HUB memory (or sourced from an independent memory bank) so as not to affect latency for the emulator accesses. In many small emulated systems the screen resolution is low anyway so I'd imagine the video data could probably come from HUBRAM in most cases. Sprite based video driver source data would likely be built in HUBRAM anyway.
Single COG access is straightforward and it could send a COGATN to the memory driver to notify a new request is ready. For dual COG use a HUB based lock could be used, but that adds more HUBRAM cycle overhead to get/set the lock. I would envisage it either having strict priority scheduling between two COG mailboxes (which could create starvation if continuously overloaded), or alternating COG polling (round-robin) where you give each COG half the opportunities to access the RAM. In that case COGATN couldn't be used to notify the driver of a request because you don't know which COG sourced the ATN and you might miss one if they happen around the same time.
I'd be interested to see how much latency can be improved by peeling away the things identified above. Gut feeling it could save maybe around 30-40% of the overhead cycles but probably not a lot more that this. With all the execf/skipf stuff the current code is already pretty tight and the polling code instruction sequence already gets optimized down for the number of active COGs (but it still transfers 8 COGs or 24 longs of mailbox data in a setq burst which is somewhat wasteful vs the 9 longs for two COGs and the management mailbox for a two active COG setup). A COGATN based request notification would be the fastest way to go there, but may not work out with two COGs.
A quick count for the HyperRAM driver code just now identified about 60 P2 clocks could be shaved for a single byte read with all these features pared out. The current total execution time in this read path is in the vicinity of 206-227 clocks (it includes HUB timing variation from two writes and the mailbox read). So the 30-40% savings is likely in the right ballpark. It's not like it will be sped up massively from the code today unless everything it did gets incorporated directly into the emulator COG itself. That's the only way to get it to the minimum cycle count but it would restrict it to one COG or maybe two if LUT sharing could be used and you had the space (but then the streamer apparently can't be used which is another issue there).
Update: If you bypass the whole driver COG mailbox and entirely hard code the byte read code (fixed at sysclk/2) directly inside a single emulator COG using static latency/delays etc I count in the vicinity 75-82 P2 instruction clocks needed to read a single byte from HyperRAM at any address. There might be a few extra cycles taken by the waitxfi while the transfer completes, but this number is reasonably close. It assumes everything is already setup in registers and the byte read code is called directly as a subroutine. I don't see it getting too much faster than that. Maybe only a few instructions here or there because you still have to setup the streamer, control the pins, set the transfer clocks, deal with odd/even addresses, address and data phase in the streamer and read back the data from the HUB destination. It also consumes at least 35 longs for code and 10 for data and this is just for the byte reads, no writes or bursts which would similarly add more COG space.
That sounds, though for the 68k, it'd make sense to read words as the basic unit, which I guess wouldn't add too many cycles. Does this include the ops to release the pins after the access? (which would be needed to share the bus with another cog + another 20 cycles to handle the lock)
Words or bytes or longs can be read using this approach where hub is some hub buffer scratch address or the final destination of where you want your burst read:
callpa #1, #readmem ' read a byte rdbyte data, hub callpa #2, #readmem ' read a word rdword data, hub callpa #4, #readmem ' read a long rdlong data, hub callpa len, #readmem ' reads some number of bytes (len) into hub addressIt does essentially include the instructions to release the pins in this instruction count yes. You could tri-state the CS and CLK pins at the end instead of driving them high (assuming a pullup exists).
Could also invert them, wouldn't need a pullup yet allows both cogs to drive them low.
Yeah if it works out with the HW that could be done too. For reads, the data bus is left tri-stated at the end. RWDS is an input for reads but can be ignored if you use fixed latency read mode. For writes you'd need RWDS to be left tri-stated at the end of the write which it already is doing as well as tri-stating the data bus pins.
Single byte/word/long and burst write code would take up an additional 49 COGRAM longs for code plus 6 more for its storage. Executes in ~88 P2 clocks plus the transfer time which is length dependent. This is all hard coded for sysclk/2.
Another advantage of having the memory code in the cogs is that it saves a cog. I think that is just what is needed for the MD emulator. I'd use the cogs as such then:
All purely theoretical of course.
Seems like a reasonable COG allocation. I take it that the Z80 is in there to control the audio? I'm not very familiar with MegaDrive hardware, never used one.
Does the Z80 really need full access to external memory as well as the 68k or could it run from HUB RAM?
Would the P2 be able to fully emulate the 68k CPU ISA with room for all the memory read stuff I wonder?
I think the 68k is big-endian. Hopefully that won't be of concern for the emulation. We do have MOVBYTS after all.
Yes, it is there just to run the audio (and to provide Master System compatibility). Most games just set and forget it and don't even care if it's actually working.
Yes, it can and does freely read from cartridge ROM (which needs to be in ext RAM due to size), and I think main RAM, too. It does incur a few cycles of delay and can cause glitches if it tries doing so while DMA is active. It does have its own 8K of RAM that doesn't go through the main bus, which is what it usually runs from. Sometimes it also isn't used at all and the 68k drives the sound directly.
Probably not. The less common ops and addressing modes can be moved to hubexec. The 68k timing is not of importance, so if it looses speed on some ops it can make it up on others, like the divide/multiply ones. (or on DMA, which can be much faster).
Yes, just movbyts on load/store to deal with the endianess.
Also, @VonSzarvas , could the console emulation topic please be split?
Unrelatedly, OPN2cog is actually done now, all examples written, all videos uploaded, post drafted, just waiting on @ersmith to release new flexspin version that has the "bad value in MaskMove" error fixed, so I don't have to ship a git build yet again.
sure. where to spilt? maybe reference the # post numbers?
I think from #14 onwards would be good
I was looking through the 68000 instruction set. Hopefully that could also be emulated by the P2 and instructions and data read/written from external Hyper memory in the cycles available. It looks like each 68000 bus cycle typically takes 4 68000 clocks. This is 0.5us per access for an 8MHz 68k which is (just) in the ballpark for HyperRAM. But I think you'll need to clock the P2+HyperRAM at its higher speeds around 250-300MHz or thereabouts. Each single access is going to be around 74 P2 clocks plus the HyperRAM latency (~24 P2 clocks) and also the hub RAM read timing on top of that (9-15 clocks) before this read item is ready to be processed / executed by the P2 emulator COG. You'll need some more margin for emulator overheads too, plus if you want to use your lock approach for sharing the external memory with a second emulator COG that will also take more cycles. It might make sense to pre-load 2 or more instructions on each instruction read (eg, 32 bits) instead of only one word at a time given that most of the time taken to read is to go setup the transfer, and each extra byte read only adds 2 P2 clock cycles (@ sysclk/2 transfer rate). That might help linear code shave some clocks if it can read from the pre-loaded area every second instruction on average instead of requiring another memory cycle.
Also bear in mind that the 16MB P2 HyperRAM from ISSI that is used on the Parallax breakout board can't cross its 8MB boundary in a sequential burst. This is due to the fact that it has two 8MB dies on the 16MB chip. Other sized RAMs or newer single die RAMs from other vendors won't necessarily have this issue. You could try test for this on every access to handle that special case (my driver doesn't bother) but it obviously adds more overhead to test for this every time. The other way is to just not do this type of access at that address if you can control your software/memory allocation.
Prefetching more instruction words would probably be advantageous. The few cycles lost to a branch are more than made up for by cases where the prefetching works.
The address decoding in the mega drive limits the cartridge size to 4MB, anyways, so it won't matter.
Yes I suspect pre-fetching should be useful in most non-branch cases but works only with non self modifying code in the queue (unless that special case is also detected and handled). If you need cycle-accuracy things may get a bit tricky. Do you think you will need fine cycle accuracy in this application?
That's good news. No need to deal with it.
There's a lot of addressing modes to deal with in the 68k.
The doesn't need to be cycle accurate for most games. The Z80 needs to have very roughly accurate timing to correctly play samples. The only thing that actually needs to be in external RAM is ROM so no self-modification worries.
Cool, seems like there is scope for such a P2 project if you can get these emulator COGs going. Z80 should be fine, just the 68k might be harder. Uses those 4-16 bit opcodes and more complex address mode decoding plus many fields are 2-3 bits which are not ideal to extract. Be good if someone had already started one, but not sure if they have.
The original Macintosh used the 68000 chip at 8MHz too. Be fun to see a P2 being an old Mac.
I haven't looked at a 68000 emulator but I have restarted work on a cycle-accurate (slow) Z80. Non-prefixed instructions can be executed using two-stage decoding, freeing up nearly 100 EXECF longs compared to a fast version but the net gain will be lower, e.g. due to T-state handling.
The 68000 has 68K transistors compared to 29K transistors for the 8086. As the latter only just fits in one cog's reg & LUT RAM, the chances of the 68000 doing the same are almost certainly nil. Thus a substantial proportion of 68000 instructions will have to run from hub RAM, probably with a lot of code duplication to reduce/eliminate branching. Luckily the original Macintosh had only 64K ROM and 128K RAM.
I know very little about the 68000 but I read that it uses octal instruction encoding similar to the 8080/Z80/8086 to a certain extent. Does an octal version of the 68000 instruction set make more sense than a hexadecimal version?
A couple of P2 instructions that manipulate octets would have been very handy, especially swapping bits 0-2 and 3-5. Also shift right + zero extend in a single instruction, which could be a future enhancement of an existing instruction.
A lot of that transistor count likely just comes from having 16 32bit registers instead of 8 16bit registers in the 8086. Also, no segmentation nonsense. And yes, some instructions will need to go to hubexec, the obvious first candidates being
The Mega Drive has 64K RAM, 64K VRAM and a couple bits and bobs here and there, so not a lot either.
The 68000 instruction encoding kindof looks like this. Lots of 3-bit fields, but some decent alignments.
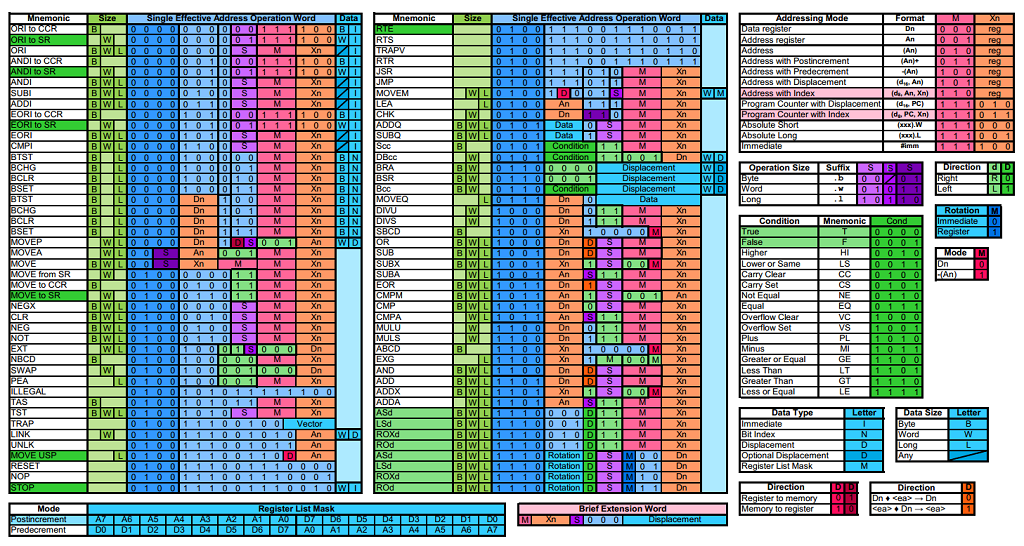
The top nibble is more or less the opcode. The operand that can have addressing modes applied is always in the bottom 6 bits. In the common case of just a data/address register, this results in bits 4 and 5 being zero and the bottom nibble containing the register number (assuming address registers are placed after data registers). Condition codes are also nibble-aligned.
Thanks for the info. I found PDF versions of the opcode map at
http://goldencrystal.free.fr/M68kOpcodes-v2.3.pdf &
http://eab.abime.net/attachment.php?attachmentid=26807&d=1287955614
A 68000 XBYTE interpreter seems very doable. Opcodes are 16-bit, but I think XBYTE would read the high byte first due to big-endianness. If not, the low byte would be read first using RFBYTE and stored, then the high byte decoded by XBYTE. Either way the low byte, which is mostly octal encoded, should not be decoded by XBYTE.
Not sure on XBYTE being very useful, since beyond the first nybble, the next thing to check is often in the bottom byte. One also needs to mind the prefetch queue when running from ext RAM and self-modifying code when running from hub.
Speaking of which, I think the best way to manage the prefetch queue is like this: there's a function pointer that is called to get one word from the code stream into
code_word. This is set to eithergetROMCodeorgetRAMCodeon a jump instruction. These would look something like thisgetRAMCode rdword code_word,hubPC add hubPC,#2 _ret_ add virtualPC,#2 getROMCode ijz prefetchIndex,#reloadPrefetch altgw prefetchIndex,#prefetchQueue_end getword code_word _ret_ add virtualPC,#2 ' .... prefetchQueue word 0[8] ' assume queue is 8 words long prefetchQueue_endreloadPrefetchwould just load the queue fromvirtualPCand setprefetchIndexto -9.The interesting part about doing it this way is that on a branch, the displacement can simply be added onto
prefetchIndexand if it remains in the valid range between -9 and -1 (which can be checked with a single CMP), the queue does not need reloading, which would accelerate small loops and forward branches.We'd probably need ~110 longs free to do the HyperRam read and write code so that's a good start.
Will code be read from external RAM, written to hub RAM, then executed from hub RAM?