@TonyB_ said:
Sprites are superimposed onto background and won't your code detect collisions between sprites and background as well as sprite-sprite collisions?
No because the sprites are written to different a HUB RAM scan line pixel buffer to those used by the background tiles (A/B) before going to the compositor COG. The buffer is cleared before the sprites are drawn. The compositor COG then merges the A, B and S layers together taking account of the priority and background colour (at least that is how I understand it working, but I didn't write it so I might have missed some key parts there).
Thanks for the info. Reading data from a sprite-only buffer before writing to the same address is a good way of detecting sprite collision, however I don't see how OR in your code can work. If corresponding old and new bytes are both non-zero then collision has occurred, however TEST will not detect this all the time unless the same bit in both is always set. It would help to know what the sprite data bytes consist of.
Yeah, true, you would have to somehow check just the new sprite's non-zero bytes in the original hub data and logically OR only those pixels, taking account of transparency. That would likely chew up a lot more cycles. Not sure if Wuerfel_21 is going to do a collision test anyway so it might be somewhat moot now.
Yeah, implementing the collision flag isn't worth it. It really isn't used much at all, given that it really just tells you if any two sprites ovelap, one frame after the fact, which isn't very useful at all.
It's basically just there because the Master System VDP has it, which has it because the TMS9918 has it, where due to the low sprite count it may have some actual use, but still not a lot.
Even the more granular collision flags on the C64 aren't used much (its sprite-background collision flags are used quite a bit though)
@Wuerfel_21 said:
Yeah, implementing the collision flag isn't worth it. It really isn't used much at all, given that it really just tells you if any two sprites ovelap, one frame after the fact, which isn't very useful at all.
It's basically just there because the Master System VDP has it, which has it because the TMS9918 has it, where due to the low sprite count it may have some actual use, but still not a lot.
The TI VDP has 1-bit patterns which sprites use but I think the Mega Drive doesn't support any TI modes, so the latter's sprite collision must be done differently.
So, finally starting on the 68000 and already realized a neat optimization.
The "second register" field that many opcodes have is 3 bits in size and 9 bits up. A pain to extract, right?
Well, assuming the virtual registers are aligned in cog RAM, one may simply MUXQ them into the D field of an instruction!
Neat trick. Can you do the same for the S field as well in some instructions? It looks like some of those 3 bit register indexes are located there too at bits 0-2.
@rogloh said:
Neat trick. Can you do the same for the S field as well in some instructions? It looks like some of those 3 bit register indexes are located there too at bits 0-2.
Yep, but there's some oddities with the address registers sometimes.
I wish I had this much time... Well I used to have that 10+ years ago when I made the PC Engine emulator and was single without kids. . The PC Engine emulator is still on my P2 ToDo list, but that list is quite big and I have got very little time for the P2 right now!
When you do find time for it, please post about it, the PCE is my favorite console! I'd love to see it run on a P2
Another observation: rather than try to implement them using a jump table or something, it seems the most efficient implementation of conditions is to use a big bit array. The fact that only the bottom 4 bits of SR are relevant makes it really fast:
getnib pb,mk_opword,#2
altd pb,#mk_condition_truth_table
testb 0-0,mk_sr wc
'' Condition is now in C flag
mk_condition_truth_table
'' Remember, status register is %XNZVC
long $10001 * %1111_1111_1111_1111 '' %0000 : True
long $10001 * %0000_0000_0000_0000 '' %0001 : False
long $10001 * %0000_0101_0000_0101 '' %0010 : High
long $10001 * %1111_1010_1111_1010 '' %0011 : Low or same
long $10001 * %0101_0101_0101_0101 '' %0100 : carry clear
long $10001 * %1010_1010_1010_1010 '' %0101 : carry set
long $10001 * %0000_1111_0000_1111 '' %0110 : not equal
long $10001 * %1111_0000_1111_0000 '' %0111 : equal
long $10001 * %0011_0011_0011_0011 '' %1000 : overflow clear
long $10001 * %1100_1100_1100_1100 '' %1001 : overflow set
long $10001 * %0000_0000_1111_1111 '' %1010 : plus
long $10001 * %1111_1111_0000_0000 '' %1011 : minus
long $10001 * %1100_1100_0011_0011 '' %1100 : greater or equal (N==V)
long $10001 * %0011_0011_1100_1100 '' %1101 : less than (N!=V)
long $10001 * %0000_1100_0000_0011 '' %1110 : greater than (N==V)&!Z (???)
long $10001 * %1111_0011_1111_1100 '' %1111 : less or equal (N!=V)|Z (???)
I guess since each pair is opposites, the table could be trimmed to 8 entries....
With such lookup code:
getnib pb,mk_opword,#2
shr pb,#1 wc
altd pb,#mk_condition_truth_table
testb 0-0,mk_sr xorc
'' Condition is now in C flag
which would also have the advantage of being able to test for %0000 and %0001 inline.
Nice work. P2 has a plethora of features that should help you put together this 68k emulator.
Don't forget these ones too, they might be useful for something down the track:
ALTB bitindex 'set next D field to bitindex[13:5]
TESTB 0,bitindex WC 'read bit[bitindex[4:0]] into C
Looks like pretty good progress so far if you've done all the red items.
Thinking about your emulator's external memory performance, is there anything possible to do in your design regarding some pre-fetch of code to save making lots of often sequential requests for the next instruction? This would potentially be helpful both HUB access (setq burst transfers) and any external memory driver access which incurs latency for each request made, but can transfer multiple items at a time when requested with only a small incremental cost per item. Those snippets of straight line code between branches could benefit with such an approach.
@rogloh said:
Looks like pretty good progress so far if you've done all the red items.
Thinking about your emulator's external memory performance, is there anything possible to do in your design regarding some pre-fetch of code to save making lots of often sequential requests for the next instruction? This would potentially be helpful both HUB access (setq burst transfers) and any external memory driver access which incurs latency for each request made, but can transfer multiple items at a time when requested with only a small incremental cost per item. Those snippets of straight line code between branches could benefit with such an approach.
Yea, that's what I have planned. See earlier in this thread.
As currently implemented, there's just a function pointer that is called to get the next opcode/extension word.
Also, after banging my head against the wall for a while because I forgot to actually read the operand I set up (no idea where the weird register contents I was seeing came from though), the shifts seem to work now.
@Wuerfel_21 said:
Another observation: rather than try to implement them using a jump table or something, it seems the most efficient implementation of conditions is to use a big bit array. The fact that only the bottom 4 bits of SR are relevant makes it really fast:
getnib pb,mk_opword,#2
altd pb,#mk_condition_truth_table
testb 0-0,mk_sr wc
'' Condition is now in C flag
mk_condition_truth_table
'' Remember, status register is %XNZVC
long $10001 * %1111_1111_1111_1111 '' %0000 : True
long $10001 * %0000_0000_0000_0000 '' %0001 : False
long $10001 * %0000_0101_0000_0101 '' %0010 : High
long $10001 * %1111_1010_1111_1010 '' %0011 : Low or same
long $10001 * %0101_0101_0101_0101 '' %0100 : carry clear
long $10001 * %1010_1010_1010_1010 '' %0101 : carry set
long $10001 * %0000_1111_0000_1111 '' %0110 : not equal
long $10001 * %1111_0000_1111_0000 '' %0111 : equal
long $10001 * %0011_0011_0011_0011 '' %1000 : overflow clear
long $10001 * %1100_1100_1100_1100 '' %1001 : overflow set
long $10001 * %0000_0000_1111_1111 '' %1010 : plus
long $10001 * %1111_1111_0000_0000 '' %1011 : minus
long $10001 * %1100_1100_0011_0011 '' %1100 : greater or equal (N==V)
long $10001 * %0011_0011_1100_1100 '' %1101 : less than (N!=V)
long $10001 * %0000_1100_0000_0011 '' %1110 : greater than (N==V)&!Z (???)
long $10001 * %1111_0011_1111_1100 '' %1111 : less or equal (N!=V)|Z (???)
I guess since each pair is opposites, the table could be trimmed to 8 entries....
With such lookup code:
getnib pb,mk_opword,#2
shr pb,#1 wc
altd pb,#mk_condition_truth_table
testb 0-0,mk_sr xorc
'' Condition is now in C flag
which would also have the advantage of being able to test for %0000 and %0001 inline.
Questions:
1. Is Condition is now in C flag equivalent to C if condition true, NC if condition not true ?
2. Do you plan to use XBYTE for your 68000 emulator?
@TonyB_ said:
Questions:
1. Is Condition is now in C flag equivalent to C if condition true, NC if condition not true ?
Yes.
Do you plan to use XBYTE for your 68000 emulator?
Already said that, XBYTE is not very applicable to this. Haven't even found a place where SKIP would be beneficial yet.
One of the advantages of XBYTE is no need to implement and continually update a PC register (assuming it never wraps around to zero). Instead, use GETPTR to read PC. Another advantage is SKIPF comes for free. Code compression is 3 or more when I've used skipping for a CPU emulator. Main disadvantage of XBYTE is FIFO not available for hubexec or streamer.
@TonyB_ said:
One of the advantages of XBYTE is no need to implement and continually update a PC register (assuming it never wraps around to zero). Instead, use GETPTR to read PC.
Another advantage is SKIPF comes for free. Code compression is 3 or more when I've used skipping for a CPU emulator. Main disadvantage of XBYTE is FIFO not available for hubexec or streamer.
Yep, totally need hubexec, so no other FIFO usage.
Well, only BCD and multiprecision stuff left to complete the basic CPU implementation.
Then on to exception handling. Then try hooking some I/O up? I guess.
Great progress @Wuerfel_21. Hopefully you can use HUB RAM for initial testing or you'll be needing my external memory stuff when you exceed 512kB. Am still putting it all together today with a simpler example for PSRAM, to be released asap.
@rogloh said:
Great progress @Wuerfel_21. Hopefully you can use HUB RAM for initial testing or you'll be needing my external memory stuff when you exceed 512kB. Am still putting it all together today with a simpler example for PSRAM, to be released asap.
Columns is only 128k, that should work (and I think I'll keep the ability for keeping everything in hub even when the PSRAM driver is integrated). From testing in Exodus and Genecyst, Columns also doesn't hang with the Z80 disabled, so it really seems like a good candidate for a "useful" test case. Will probably start with a simpler ROM though.
Another interesting optimization: since the vector table is in ROM, I can cache it, pre-byteswapped, in hub, so I can simply read one with a single AUGS+RDLONG
rdlong mk_branchto,##mk_vectorcache+$04
doesn't matter a whole lot for speed, since the exception handling path is terribly slow on a real 68000 (allegedly, 44 cycles for a normal interrupt.), so if anything it may enter the handler too early (might have to delay raster IRQs a bit to compensate ), but makes the code easier to undestand.
Speaking of, I wonder if megadrive games that have to fiddle with the VDP on a line-by-line basis (OutRun comes to mind) actually use the horizontal interrupt or if they just poll the scanline register... Should probably check that.
Based on what you've done so far, do you expect a fast P2 (I think you were targeting 320MHz) should be able to emulate the 68k at suitable rates for the Megadrive (wasn't it around 7-8 MHz or so ?) Are most instructions emulated within the budget?
@rogloh said:
Based on what you've done so far, do you expect a fast P2 (I think you were targeting 320MHz) should be able to emulate the 68k at suitable rates for the Megadrive (wasn't it around 7-8 MHz or so ?) Are most instructions emulated within the budget?
Not sure yet. I think it won't be able to run fast instructions like MOVE.W Dn,Dn and other word ops involving a memory operand in ROM quite fast enough, but any longword op or ones using complex adressing modes or involving RAM accesses (including stack ops!) should be a good bit faster. MOVEQ in particular is also really fast because it is fixed size, takes up an entire nibble (or "line", as motorola calls it) and doesn't need to decode an operand:
'' Note that this is placed in hub because there is no benefit to it
'' being ion cog/lut, given that is completely branchless
mk_nibble_7 ' MOVEQ
mov pb,mk_opword
and pb,mk_dreg_mask
signx mk_opword,#7 wcz
bitc mk_sr,#MK_NEG_BIT
bitz mk_sr,#MK_ZERO_BIT
andn mk_sr,#MK_OVER_MASK|MK_CARRY_MASK
alti pb,#%000_100_000
.moveop _ret_ mov mk_d0,mk_opword
Oh, and MULU/MULS/DIVU/DIVS completely smash the real 68000
(Not sure if my DIVx are entirely accurate though. luckily, the processor discards overflowing results, so I don't need to worry about accuracy of those)
Then again, not sure how fast the ROM opcode fetch (and associated branch penalties) will be.
Also, define "suitable rates for the Megadrive". Aside from maybe the aforementioned OutRun and similiarly tricky cases, I think most games will just experience more slowdown than usual if the 68000 isn't up to snuff. The Z80 timing seems more important, but only for correct audio speed/pitch. And of course, a Z80 emu on a 320MHz P2 is going to need a speed limiter more than any optimization.
68k emu opens the way for 68k based machines emulation. Atari ST. Amiga. While Amiga has several custom chip to emulate too, ST was a lot simpler machine with a simple video shifter and Yamaha 3-channel sound chip.
@TonyB_ said:
One of the advantages of XBYTE is no need to implement and continually update a PC register (assuming it never wraps around to zero). Instead, use GETPTR to read PC.
Another advantage is SKIPF comes for free. Code compression is 3 or more when I've used skipping for a CPU emulator. Main disadvantage of XBYTE is FIFO not available for hubexec or streamer.
Yep, totally need hubexec, so no other FIFO usage.
It should be possible to call a routine in hub RAM from cog/LUT RAM, then restart XBYTE after the call. Must Could use GETPTR to read PC beforehand and adjust it afterwards. Best to read any remaining opcodes from the FIFO before the call destroys them.
How many longs have been used so far for the 68K emulator?
~~~~> @Wuerfel_21 said:
MOVEQ in particular is also really fast because it is fixed size, takes up an entire nibble (or "line", as motorola calls it) and doesn't need to decode an operand:
'' Note that this is placed in hub because there is no benefit to it
'' being in cog/lut, given that is completely branchless
mk_nibble_7 ' MOVEQ
mov pb,mk_opword
and pb,mk_dreg_mask
signx mk_opword,#7 wcz
bitc mk_sr,#MK_NEG_BIT
bitz mk_sr,#MK_ZERO_BIT
andn mk_sr,#MK_OVER_MASK|MK_CARRY_MASK
alti pb,#%000_100_000
.moveop _ret_ mov mk_d0,mk_opword
I don't want to keep banging on about it, but MOVEQ would be reallyreally fast with XBYTE.
Tremble at the might of the BCD addition implementation!
The .doit bit is mostly just a straight translation of the referenced C++ code. I feel like some of these ops can defo be factored out, but I'm too lazy to figure that out
mk_hub_abcd ' ABCD
' isolate register nos
mov mk_optmp0,mk_opword
and mk_optmp0,#7 ' source
mov mk_optmp2,mk_opword
shr mk_optmp2,#9
and mk_optmp2,#7 ' destination
' check for -(An),-(An) mode
testb mk_opword,#3 wc
if_c jmp #.memmode
alts mk_optmp0,#mk_d0
getbyte mk_optmp1,0-0,#0
alts mk_optmp2,#mk_d0
getbyte mk_memvalue,0-0,#0
.doit
' See: https://github.com/flamewing/68k-bcd-verifier/blob/master/bcd-emul.cc#L52
' compute ss
testb mk_sr,#MK_EXT_BIT wc
mov mk_optmp0,mk_memvalue
addx mk_optmp0,mk_optmp1
' compute bc
mov mk_optmp2,mk_memvalue
and mk_optmp2,mk_optmp1
andn mk_memvalue,mk_optmp0 ' note: don't need the original operands anymore
or mk_optmp2,mk_memvalue
andn mk_optmp1,mk_optmp0 ' note: ^^
or mk_optmp2,mk_optmp1
and mk_optmp2,#$88
' compute dc
mov mk_memvalue,mk_optmp0
add mk_memvalue,#$66
xor mk_memvalue,mk_optmp0
and mk_memvalue,#$110
shr mk_memvalue,#1
' compute corf
or mk_memvalue,mk_optmp2
sca mk_memvalue,##$4000 ' equivalent to >> 2
sub mk_memvalue,0-0
' compute result
add mk_memvalue,mk_optmp0
' write to register if needed
test mk_opword,#3 wc
if_nc and mk_opword,mk_dreg_mask ' don't need opword anymore
if_nc alti mk_opword,#%000_100_000
if_nc setbyte 0-0,mk_memvalue,#0
' compute carry
testb mk_optmp0,#7 wc
testbn mk_memvalue,#7 andc
testb mk_optmp2,#7 orc
muxc mk_sr,#MK_CARRY_MASK|MK_EXT_MASK
' compute overflow
testbn mk_optmp0,#7 wc
testb mk_memvalue,#7 andc
bitc mk_sr,#MK_OVER_BIT
' compute zero flag
test mk_memvalue,#255 wz
if_nz bitl mk_sr,#MK_ZERO_BIT
' compute neg flag
testb mk_memvalue,#7 wc
_ret_ bitc mk_sr,#MK_NEG_BIT
' returns either to nextop or mk_writef
.memmode
altd mk_optmp0,#mk_a0
sub 0-0,#1
alts mk_optmp0,#mk_a0
mov mk_effaddr,0-0
call #mk_setup_ea8
call mk_readf
mov mk_optmp1,mk_memvalue
altd mk_optmp2,#mk_a0
sub 0-0,#1
alts mk_optmp2,#mk_a0
mov mk_effaddr,0-0
call #mk_setup_ea8
' - jmp into mk_readf
' - returns into .doit
' - returns into mk_writef
push mk_writef
loc pb,#.doit
push pb
jmp mk_readf


Comments
A cycle-accurate Z80 cog would have plenty of spare time for video, reducing the workload of dedicated video cogs somewhat.
Yeah, true, you would have to somehow check just the new sprite's non-zero bytes in the original hub data and logically OR only those pixels, taking account of transparency. That would likely chew up a lot more cycles. Not sure if Wuerfel_21 is going to do a collision test anyway so it might be somewhat moot now.
Yeah, implementing the collision flag isn't worth it. It really isn't used much at all, given that it really just tells you if any two sprites ovelap, one frame after the fact, which isn't very useful at all.
It's basically just there because the Master System VDP has it, which has it because the TMS9918 has it, where due to the low sprite count it may have some actual use, but still not a lot.
Even the more granular collision flags on the C64 aren't used much (its sprite-background collision flags are used quite a bit though)
The TI VDP has 1-bit patterns which sprites use but I think the Mega Drive doesn't support any TI modes, so the latter's sprite collision must be done differently.
So, finally starting on the 68000 and already realized a neat optimization.
The "second register" field that many opcodes have is 3 bits in size and 9 bits up. A pain to extract, right?
Well, assuming the virtual registers are aligned in cog RAM, one may simply MUXQ them into the D field of an instruction!
Neat trick. Can you do the same for the S field as well in some instructions? It looks like some of those 3 bit register indexes are located there too at bits 0-2.
Yep, but there's some oddities with the address registers sometimes.
Something tells me that
SUB D7,D1should probably not write $6DBA into D0...Edit: yep, stupid mistake, was swapping the secondary operand with the opcode, not the primary operand.... $0001 - $9247 = $6DBA
Hi there. These forums are so informative and helpful") 192.168.1.1 panoramacharter.ltd
192.168.1.1 panoramacharter.ltd
When you do find time for it, please post about it, the PCE is my favorite console! I'd love to see it run on a P2")
Another observation: rather than try to implement them using a jump table or something, it seems the most efficient implementation of conditions is to use a big bit array. The fact that only the bottom 4 bits of SR are relevant makes it really fast:
getnib pb,mk_opword,#2 altd pb,#mk_condition_truth_table testb 0-0,mk_sr wc '' Condition is now in C flagmk_condition_truth_table '' Remember, status register is %XNZVC long $10001 * %1111_1111_1111_1111 '' %0000 : True long $10001 * %0000_0000_0000_0000 '' %0001 : False long $10001 * %0000_0101_0000_0101 '' %0010 : High long $10001 * %1111_1010_1111_1010 '' %0011 : Low or same long $10001 * %0101_0101_0101_0101 '' %0100 : carry clear long $10001 * %1010_1010_1010_1010 '' %0101 : carry set long $10001 * %0000_1111_0000_1111 '' %0110 : not equal long $10001 * %1111_0000_1111_0000 '' %0111 : equal long $10001 * %0011_0011_0011_0011 '' %1000 : overflow clear long $10001 * %1100_1100_1100_1100 '' %1001 : overflow set long $10001 * %0000_0000_1111_1111 '' %1010 : plus long $10001 * %1111_1111_0000_0000 '' %1011 : minus long $10001 * %1100_1100_0011_0011 '' %1100 : greater or equal (N==V) long $10001 * %0011_0011_1100_1100 '' %1101 : less than (N!=V) long $10001 * %0000_1100_0000_0011 '' %1110 : greater than (N==V)&!Z (???) long $10001 * %1111_0011_1111_1100 '' %1111 : less or equal (N!=V)|Z (???)I guess since each pair is opposites, the table could be trimmed to 8 entries....
With such lookup code:
getnib pb,mk_opword,#2 shr pb,#1 wc altd pb,#mk_condition_truth_table testb 0-0,mk_sr xorc '' Condition is now in C flagwhich would also have the advantage of being able to test for %0000 and %0001 inline.
Nice work. P2 has a plethora of features that should help you put together this 68k emulator.
Don't forget these ones too, they might be useful for something down the track:
Well, I implemented a good chunk and so far it all fits nicely into memory, so that's a plus.
But now I need to implement the shift ops and decode that accursed %0100 opcode group
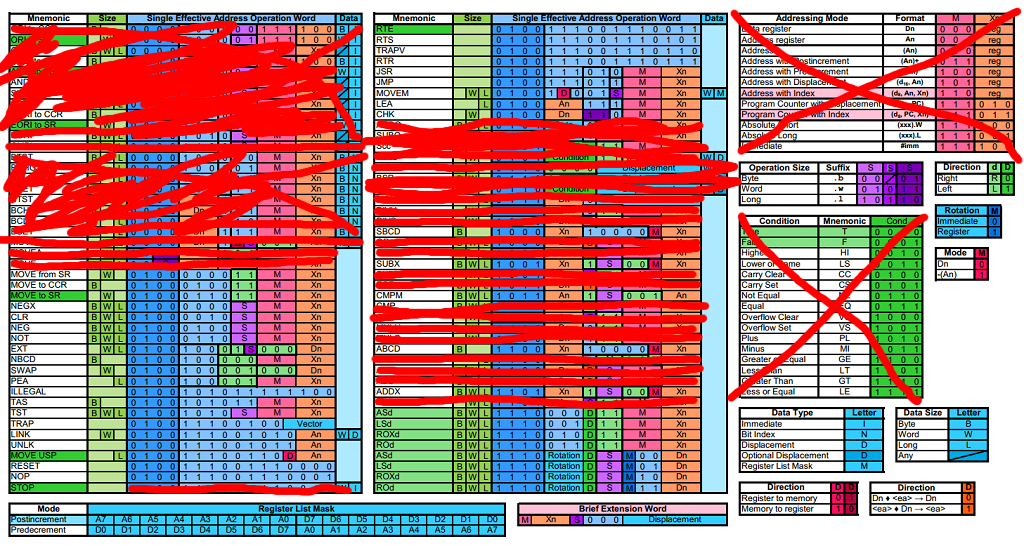
Also nothing related to I/O, supervisor mode and interrupts yet, but especially the latter two can go on the slow path.
Looks like pretty good progress so far if you've done all the red items.
Thinking about your emulator's external memory performance, is there anything possible to do in your design regarding some pre-fetch of code to save making lots of often sequential requests for the next instruction? This would potentially be helpful both HUB access (setq burst transfers) and any external memory driver access which incurs latency for each request made, but can transfer multiple items at a time when requested with only a small incremental cost per item. Those snippets of straight line code between branches could benefit with such an approach.
Yea, that's what I have planned. See earlier in this thread.
As currently implemented, there's just a function pointer that is called to get the next opcode/extension word.
Also, after banging my head against the wall for a while because I forgot to actually read the operand I set up (no idea where the weird register contents I was seeing came from though), the shifts seem to work now.
IDK, I should really find a proper test program.
So that's the state for today:
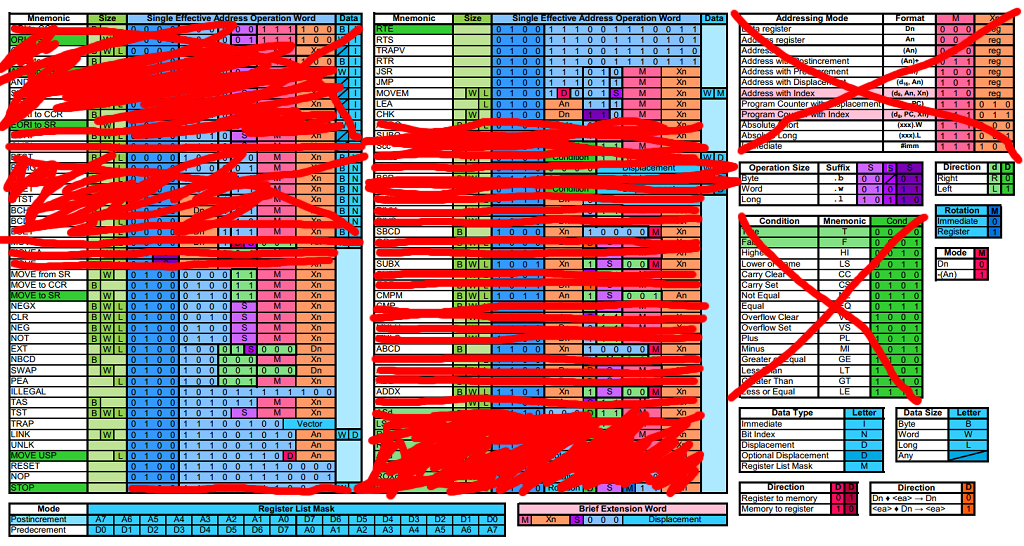
Questions:
1. Is
Condition is now in C flagequivalent toC if condition true, NC if condition not true?2. Do you plan to use XBYTE for your 68000 emulator?
Yes.
Already said that, XBYTE is not very applicable to this. Haven't even found a place where SKIP would be beneficial yet.
One of the advantages of XBYTE is no need to implement and continually update a PC register (assuming it never wraps around to zero). Instead, use GETPTR to read PC. Another advantage is SKIPF comes for free. Code compression is 3 or more when I've used skipping for a CPU emulator. Main disadvantage of XBYTE is FIFO not available for hubexec or streamer.
Yep, totally need hubexec, so no other FIFO usage.
Well, only BCD and multiprecision stuff left to complete the basic CPU implementation.

Then on to exception handling. Then try hooking some I/O up? I guess.
Great progress @Wuerfel_21. Hopefully you can use HUB RAM for initial testing or you'll be needing my external memory stuff when you exceed 512kB. Am still putting it all together today with a simpler example for PSRAM, to be released asap.
Columns is only 128k, that should work (and I think I'll keep the ability for keeping everything in hub even when the PSRAM driver is integrated). From testing in Exodus and Genecyst, Columns also doesn't hang with the Z80 disabled, so it really seems like a good candidate for a "useful" test case. Will probably start with a simpler ROM though.
Another interesting optimization: since the vector table is in ROM, I can cache it, pre-byteswapped, in hub, so I can simply read one with a single AUGS+RDLONG
doesn't matter a whole lot for speed, since the exception handling path is terribly slow on a real 68000 (allegedly, 44 cycles for a normal interrupt.), so if anything it may enter the handler too early (might have to delay raster IRQs a bit to compensate") ), but makes the code easier to undestand.
), but makes the code easier to undestand.
Speaking of, I wonder if megadrive games that have to fiddle with the VDP on a line-by-line basis (OutRun comes to mind) actually use the horizontal interrupt or if they just poll the scanline register... Should probably check that.
Based on what you've done so far, do you expect a fast P2 (I think you were targeting 320MHz) should be able to emulate the 68k at suitable rates for the Megadrive (wasn't it around 7-8 MHz or so ?) Are most instructions emulated within the budget?
Not sure yet. I think it won't be able to run fast instructions like
MOVE.W Dn,Dnand other word ops involving a memory operand in ROM quite fast enough, but any longword op or ones using complex adressing modes or involving RAM accesses (including stack ops!) should be a good bit faster. MOVEQ in particular is also really fast because it is fixed size, takes up an entire nibble (or "line", as motorola calls it) and doesn't need to decode an operand:'' Note that this is placed in hub because there is no benefit to it '' being ion cog/lut, given that is completely branchless mk_nibble_7 ' MOVEQ mov pb,mk_opword and pb,mk_dreg_mask signx mk_opword,#7 wcz bitc mk_sr,#MK_NEG_BIT bitz mk_sr,#MK_ZERO_BIT andn mk_sr,#MK_OVER_MASK|MK_CARRY_MASK alti pb,#%000_100_000 .moveop _ret_ mov mk_d0,mk_opwordOh, and MULU/MULS/DIVU/DIVS completely smash the real 68000
(Not sure if my DIVx are entirely accurate though. luckily, the processor discards overflowing results, so I don't need to worry about accuracy of those)
Then again, not sure how fast the ROM opcode fetch (and associated branch penalties) will be.
Also, define "suitable rates for the Megadrive". Aside from maybe the aforementioned OutRun and similiarly tricky cases, I think most games will just experience more slowdown than usual if the 68000 isn't up to snuff. The Z80 timing seems more important, but only for correct audio speed/pitch. And of course, a Z80 emu on a 320MHz P2 is going to need a speed limiter more than any optimization.
68k emu opens the way for 68k based machines emulation. Atari ST. Amiga. While Amiga has several custom chip to emulate too, ST was a lot simpler machine with a simple video shifter and Yamaha 3-channel sound chip.
It should be possible to call a routine in hub RAM from cog/LUT RAM, then restart XBYTE after the call. Must Could use GETPTR to read PC beforehand and adjust it afterwards. Best to read any remaining opcodes from the FIFO before the call destroys them.
How many longs have been used so far for the 68K emulator?
~~~~> @Wuerfel_21 said:
MOVEQ in particular is also really fast because it is fixed size, takes up an entire nibble (or "line", as motorola calls it) and doesn't need to decode an operand:
I don't want to keep banging on about it, but MOVEQ would be really really fast with XBYTE.
Tremble at the might of the BCD addition implementation!
The
.doitbit is mostly just a straight translation of the referenced C++ code. I feel like some of these ops can defo be factored out, but I'm too lazy to figure that outmk_hub_abcd ' ABCD ' isolate register nos mov mk_optmp0,mk_opword and mk_optmp0,#7 ' source mov mk_optmp2,mk_opword shr mk_optmp2,#9 and mk_optmp2,#7 ' destination ' check for -(An),-(An) mode testb mk_opword,#3 wc if_c jmp #.memmode alts mk_optmp0,#mk_d0 getbyte mk_optmp1,0-0,#0 alts mk_optmp2,#mk_d0 getbyte mk_memvalue,0-0,#0 .doit ' See: https://github.com/flamewing/68k-bcd-verifier/blob/master/bcd-emul.cc#L52 ' compute ss testb mk_sr,#MK_EXT_BIT wc mov mk_optmp0,mk_memvalue addx mk_optmp0,mk_optmp1 ' compute bc mov mk_optmp2,mk_memvalue and mk_optmp2,mk_optmp1 andn mk_memvalue,mk_optmp0 ' note: don't need the original operands anymore or mk_optmp2,mk_memvalue andn mk_optmp1,mk_optmp0 ' note: ^^ or mk_optmp2,mk_optmp1 and mk_optmp2,#$88 ' compute dc mov mk_memvalue,mk_optmp0 add mk_memvalue,#$66 xor mk_memvalue,mk_optmp0 and mk_memvalue,#$110 shr mk_memvalue,#1 ' compute corf or mk_memvalue,mk_optmp2 sca mk_memvalue,##$4000 ' equivalent to >> 2 sub mk_memvalue,0-0 ' compute result add mk_memvalue,mk_optmp0 ' write to register if needed test mk_opword,#3 wc if_nc and mk_opword,mk_dreg_mask ' don't need opword anymore if_nc alti mk_opword,#%000_100_000 if_nc setbyte 0-0,mk_memvalue,#0 ' compute carry testb mk_optmp0,#7 wc testbn mk_memvalue,#7 andc testb mk_optmp2,#7 orc muxc mk_sr,#MK_CARRY_MASK|MK_EXT_MASK ' compute overflow testbn mk_optmp0,#7 wc testb mk_memvalue,#7 andc bitc mk_sr,#MK_OVER_BIT ' compute zero flag test mk_memvalue,#255 wz if_nz bitl mk_sr,#MK_ZERO_BIT ' compute neg flag testb mk_memvalue,#7 wc _ret_ bitc mk_sr,#MK_NEG_BIT ' returns either to nextop or mk_writef .memmode altd mk_optmp0,#mk_a0 sub 0-0,#1 alts mk_optmp0,#mk_a0 mov mk_effaddr,0-0 call #mk_setup_ea8 call mk_readf mov mk_optmp1,mk_memvalue altd mk_optmp2,#mk_a0 sub 0-0,#1 alts mk_optmp2,#mk_a0 mov mk_effaddr,0-0 call #mk_setup_ea8 ' - jmp into mk_readf ' - returns into .doit ' - returns into mk_writef push mk_writef loc pb,#.doit push pb jmp mk_readfSo how full is the COG+LUT RAM now @Wuerfel_21 ?