A 68000 XBYTE interpreter seems very doable. Opcodes are 16-bit, but I think XBYTE will read the high byte first due to big-endianness. If not, the low byte would be read first and stored, then the high byte decoded by XBYTE. Either way the low byte, which is mostly octal encoded, should not be decoded by XBYTE.
Not sure on XBYTE being very useful, since beyond the first nybble, the next thing to check is often in the bottom byte. One also needs to mind the prefetch queue when running from ext RAM and self-modifying code when running from hub.
A CPU emulator will be slow if using random read instructions such as RDWORD to fetch opcodes. If XBYTE can be used then it should be used, always. The FIFO emulates a prefetch queue automatically and the only issue is that self-modifying nearby code might not work because the instruction is already in the pipeline. However if that is the case why would anyone write self-modifying code that cannot run? The FIFO could be reloaded if a memory write address >= PC instead of any write address.
I think the best XBYTE option for the 68000 (and the only practicable one) is to decode the high nibble of the opcode only. The LUT table will be the smallest possible at 16 longs (smaller than for 6502, 8080, Z80 or 8086) leaving most of LUT RAM for 'manual' decoding of other opcode bits or instruction emulation. It would be interesting to see how much of the 68000 could fit into reg & LUT RAM.
A 68000 XBYTE interpreter seems very doable. Opcodes are 16-bit, but I think XBYTE will read the high byte first due to big-endianness. If not, the low byte would be read first and stored, then the high byte decoded by XBYTE. Either way the low byte, which is mostly octal encoded, should not be decoded by XBYTE.
Not sure on XBYTE being very useful, since beyond the first nybble, the next thing to check is often in the bottom byte. One also needs to mind the prefetch queue when running from ext RAM and self-modifying code when running from hub.
A CPU emulator will be slow if using random read instructions such as RDWORD to fetch opcodes. If XBYTE can be used then it should be used, always. The FIFO emulates a prefetch queue automatically and the only issue is that self-modifying nearby code might not work because the instruction is already in the pipeline. However if that is the case why would anyone write self-modifying code that cannot run? The FIFO could be reloaded if a memory write address >= PC, instead of any write address.
I think the best XBYTE option for the 68000 is to decode the high nibble of the opcode only. The LUT table will be the smallest possible at 16 longs (smaller than for 6502, 8080, Z80 or 8086) leaving most of LUT RAM for 'manual' decoding of other opcode bits or instruction emulation. It would be interesting to see how much of the 68000 could fit into reg & LUT RAM.
The speed loss from random read is negligible compared to:
Having to track the virtual PC and the ext. RAM prefetch queue left on every code read, anyways
Having to read the low byte of the instruction word separately (and in case of MOVE, combine it with the top byte because the destination operand crosses the boundary.
Having to proactively reload the FIFO to avoid stale code
Having to reload the FIFO every time the code goes off into hubexec
I haven't looked at a 68000 emulator but I have restarted work on a cycle-accurate (slow) Z80. Non-prefixed instructions can be executed using two-stage decoding, freeing up nearly 100 EXECF longs compared to a fast version but the net gain will be lower, e.g. due to T-state handling.
We'd probably need ~110 longs free to do the HyperRam read and write code so that's a good start.
Will code be read from external RAM, written to hub RAM, then executed from hub RAM?
Yes, that's due to using the streamer. On streamer reads from pins the COG doesn't actually see the data on the pins, they go straight into HUB RAM first and then get read back from there by the emulator. Perhaps at sysclk/2 you could try to read the pins to get at these data bytes if the instruction phase is aligned right, but that path is then different to any read bursts and would need more space. It could speed up things a little though by not needing that extra hub read cycle of 9-15 clocks after the data has already been read from the pins.
@Wuerfel_21 said:
Help I can't stop. Not sure if this even runs realtime, would have to hook a video driver up...
What exactly have you got working? All I see is screenshots.
As I said in the post before that, the Mega Drive VDP (what makes the graphics happen). Currently I'm just feeding it with VRAM dumps from a PC emulator.
I've actually hooked it up to your video code now. Too slow for 250 MHz, but 325 is OK. Not sure if it'd handle the worst case of 20 16-wide sprites on a line, otoh I think the main culprit is the compositor cog (which combines the layer data generated by the other), whose timing is mostly indifferent to what's actually on the screen.
Working so far:
- A/B Plane, including fine H/V scrolling, including line/column scrolling
- Sprites, including accurate masking and overflow behavior
- Priority between the Planes and Sprites
- Window plane, partially
- H40 and H32 modes (320x224 vs 256x224)
Not yet:
- Anything that'd be needed to actually connect to a 68k emulator (register interface, interrupts, etc)
- Actually changing video settings for H32 mode (currently just sits left-justified in the H40 frame)
- Shadow/Highlight mode
- Correct priority for window plane
- Window plane on left/right side
Pictured: Sonic and Tails just chilling on this column surrounded by lava. That's some attitude alright.
Anyways, rendered real-time at 325 MHz.
I haven't looked at a 68000 emulator but I have restarted work on a cycle-accurate (slow) Z80. Non-prefixed instructions can be executed using two-stage decoding, freeing up nearly 100 EXECF longs compared to a fast version but the net gain will be lower, e.g. due to T-state handling.
We'd probably need ~110 longs free to do the HyperRam read and write code so that's a good start.
Will code be read from external RAM, written to hub RAM, then executed from hub RAM?
Yes, that's due to using the streamer. On streamer reads from pins the COG doesn't actually see the data on the pins, they go straight into HUB RAM first and then get read back from there by the emulator. Perhaps at sysclk/2 you could try to read the pins to get at these data bytes if the instruction phase is aligned right, but that path is then different to any read bursts and would need more space. It could speed up things a little though by not needing that extra hub read cycle of 9-15 clocks after the data has already been read from the pins.
It would be better for an emulator to read code and data from hub RAM only. Is it one byte from HyperRam every sysclk/2 once streamer is running?
Well, currently they don't get updated at all, they're just hardcoded. But making that happen is on the agenda. It will need a similar technique to OPN2cog where the registers need to be converted to a more convenient representation when the CPU writes them. It also needs little-endian VRAM data, so that must be swapped on write, too.
Vertical scroll (VSRAM) is updated every line and per-line scrolling is a built-in feature of the VDP (and the scroll table lives in VRAM so when it is written mid-frame, that should work)
Currently I am trying to optimize the compositing cog enough to squeeze in shadow/highlight mode. As it was, it was just one instruction away from being too slow (at 325 MHz!). Now I've unrolled it and tapped into the immense energy of MUXQ to aggregate priority bits from 4 pixels simultaneously, which may have freed up just enough cycles.
Problem is that I can't find a reliable description of how it actually works. There's multiple conflicting ones, so I'll have to do some research.
For those playing along at home, in Shad/HL mode, each pixel can be either shadowed (RGB values halved), normal or highlighted (RGB values doubled). This depends on the output from the 3 layers.
What I've confirmed so far:
The base state is shadow when the priority bit of both planes is low. This is regardless of whether the planes actually have any pixels in them. Otherwise, it is normal.
Sprite pixels with colors 14,30,46,62 and 63 affect the state. (Note that this only concerns the topmost sprite pixel sent to compositing)
Color 63 shadows, Color 62 highlights. Highlight from a sprite and shadow from the background cancel out. Both of these are invisible.
The other ones render normally, but are not affected by shadowing
The background color is affected by shadow/highlight
What I'm still missing:
What role does the sprite priority play?
What happens with the Window plane?
Can low priority sprites shadow/highlight a high priority plane in front of them?
@TonyB_ said:
It would be better for an emulator to read code and data from hub RAM only. Is it one byte from HyperRam every sysclk/2 once streamer is running?
Yes I know. But the cartridge ROM sizes are larger than Hub RAM allows hence the need for external RAM. Maybe some caching/preloading could help but that also burns more precious COG RAM space.
It is one byte streamed to HUB at sysclk/2 rate, yes. You can actually go to sysclk/1 rates for the data phase but its less reliable and it doesn't buy much for single transfers because the address phase is still done at sysclk/2. The v1 ISSI HyperRAM that the Parallax breakout board uses is technically being overclocked at P2 speeds above 200MHz when performing sysclk/1 reads, yet sysclk/2 operation still remains within the rated speed. This breakout board typically reaches its overclocked limit for sysclk/1 reads just above 300MHz for a P2-EVAL at room temp. Newer v2 HyperRAM is rated faster (166/200MHz) and shouldn't need to be overclocked at for a 325MHz P2.
The PSRAM stuff Parallax is considering for a future P2 Edge is able to transfer data over its 16 bit bus at 288MB/s at its rated speed but I've had it operating at 325MB/s with no apparent issues using my driver. The write speed is lessened though because it always needs to write 32 bit aligned data (the native storage size). PSRAM has no byte lane masking signal unlike HyperRAM with it's RWDS pin so for byte or word writes you need to read the old data first, update it with MUXQ and then write it back. It's far less of an issue for the larger burst write transfers, but it limits the performance for single and very short write bursts and consumes more COG RAM space to deal with all these extra cases. If you only write longs it's not a problem.
@rogloh said:
What exactly have you got working? All I see is screenshots.
As I said in the post before that, the Mega Drive VDP (what makes the graphics happen). Currently I'm just feeding it with VRAM dumps from a PC emulator.
I've actually hooked it up to your video code now. Too slow for 250 MHz, but 325 is OK. Not sure if it'd handle the worst case of 20 16-wide sprites on a line, otoh I think the main culprit is the compositor cog (which combines the layer data generated by the other), whose timing is mostly indifferent to what's actually on the screen.
Working so far:
- A/B Plane, including fine H/V scrolling, including line/column scrolling
- Sprites, including accurate masking and overflow behavior
- Priority between the Planes and Sprites
- Window plane, partially
- H40 and H32 modes (320x224 vs 256x224)
Not yet:
- Anything that'd be needed to actually connect to a 68k emulator (register interface, interrupts, etc)
- Actually changing video settings for H32 mode (currently just sits left-justified in the H40 frame)
- Shadow/Highlight mode
- Correct priority for window plane
- Window plane on left/right side
Pictured: Sonic and Tails just chilling on this column surrounded by lava. That's some attitude alright.
Anyways, rendered real-time at 325 MHz.
Fantastic @Wuerfel_21 . You really need a 68k P2 emulator.
I think I used to get around 12-16 16x16 pixel masked sprites per line on a P1 (4 COGs, 80 MIPS IIRC) after rendering the tiles, so hopefully a single P2 COG being effectively 2 times faster @325MHz and with far more memory bandwidth could do 20, but I don't know how much of the total P2's COG cycles you have available per scan line for your sprites, and this time available depends on the actual video scan line update rate too.
@TonyB_ said:
It would be better for an emulator to read code and data from hub RAM only. Is it one byte from HyperRam every sysclk/2 once streamer is running?
Yes I know. But the cartridge ROM sizes are larger than Hub RAM allows hence the need for external RAM. Maybe some caching/preloading could help but that also burns more precious COG RAM space.
It is one byte streamed to HUB at sysclk/2 rate, yes.
I'm not arguing against external RAM. I wasn't very clear before so I'll try again:
It would be better for an emulator to read code and data from hub RAM only therefore it is good thing that external RAM data are streamed to and from hub RAM. The emulator would not want to access external RAM directly as it much easier to use XBYTE and RFxxxx.
@TonyB_ said:
It would be better for an emulator to read code and data from hub RAM only. Is it one byte from HyperRam every sysclk/2 once streamer is running?
Yes I know. But the cartridge ROM sizes are larger than Hub RAM allows hence the need for external RAM. Maybe some caching/preloading could help but that also burns more precious COG RAM space.
It is one byte streamed to HUB at sysclk/2 rate, yes.
I wasn't very clear before so I'll try again:
It would be better for an emulator to read code and data from hub RAM only therefore it is good thing that external RAM data are streamed to and from hub RAM. The emulator would not want to access external RAM directly anyway as it much easier to use XBYTE and RFxxxx.
Aha, yes now I see your point.
Normally I would recommend a separate COG to do all the external memory accesses and all client COGs will only need to read/write HUB RAM and the mailbox. In this case with an emulator, latency becomes critical and to reduce it (as well as saving a COG) the extra mailbox polling overhead can be eliminated and the memory driver is incorporated into the emulator COG(s). Luckily the model of getting the external memory read results from HUB RAM after making the memory request still remains. It also lets you pre-fetch / cache additional instructions.
@rogloh said:
What exactly have you got working? All I see is screenshots.
As I said in the post before that, the Mega Drive VDP (what makes the graphics happen). Currently I'm just feeding it with VRAM dumps from a PC emulator.
I've actually hooked it up to your video code now. Too slow for 250 MHz, but 325 is OK. Not sure if it'd handle the worst case of 20 16-wide sprites on a line, otoh I think the main culprit is the compositor cog (which combines the layer data generated by the other), whose timing is mostly indifferent to what's actually on the screen.
Working so far:
- A/B Plane, including fine H/V scrolling, including line/column scrolling
- Sprites, including accurate masking and overflow behavior
- Priority between the Planes and Sprites
- Window plane, partially
- H40 and H32 modes (320x224 vs 256x224)
Not yet:
- Anything that'd be needed to actually connect to a 68k emulator (register interface, interrupts, etc)
- Actually changing video settings for H32 mode (currently just sits left-justified in the H40 frame)
- Shadow/Highlight mode
- Correct priority for window plane
- Window plane on left/right side
Pictured: Sonic and Tails just chilling on this column surrounded by lava. That's some attitude alright.
Anyways, rendered real-time at 325 MHz.
Fantastic @Wuerfel_21 . You really need a 68k P2 emulator.
I think I used to get around 12-16 16x16 pixel masked sprites per line on a P1 (4 COGs, 80 MIPS IIRC) after rendering the tiles, so hopefully a single P2 COG being effectively 2 times faster @325MHz and with far more memory bandwidth could do 20, but I don't know how much of the total P2's COG cycles you have available per scan line for your sprites, and this time available depends on the actual video scan line update rate too.
The problem here is not neccessarily rendering the tiles/sprites, it is rendering exactly like a Mega Drive, including cutting the right sprite when the limit overflows. I tried to write an explanation of how sprite rendering works here and I literally couldn't, but it involves an intermediate list of up to 20 (16 in H32) sprites, partial caching of the sprite table, magic X positions that stop the sprite scanning, but only if there are any normal sprites before it, a limit of 40 (32 in H32) total sprite tiles on a line and the strange order in which they start to be dropped and aaaaaaaaaaaaaaaaaaaa.
Anyways, someone made a test screen for this and it passes all but one test. Somehow. I tried fixing that remaining test condition, but it didn't work properly and it is a very obscure one that I don't think ever comes up in a game. And yes, that means my janky VDP emulation is actually better in that regard than GensKMod (which I use to capture VRAM dumps)
Also, I think I may have found the answer to some of my shad/hl worries, I think. I am fairly certain now that a non 62 or 63 color from a high priority sprite is never affected by the planes' shadow state. And I guess a high priority plane is not affected by a low priority 62/63 sprite?
Hey @Wuerfel_21 so if the external memory is for replacing cartridge ROM use, shouldn't that mean you would only need to write into external RAM once at the start to get the application/game loaded into external memory out of SD/Flash etc and then only perform reads after this until something else needs to be loaded? If so, you should then be able to reduce the overhead of the code in COG/LUTRAM by overlaying the external memory read routine with the write routine. Doing this would reduce its space requirement in COG RAM competing with the emulator's own space, as the write code consumes ~50 longs (bytes/words/bursts) vs 37 longs for reads. Write executable code reduces further down to 42 longs of code space if burst only writes are supported vs including support for single writes as well, or a few less if locks are not used.
Update: Also by doing only long aligned burst writes to load resources into external RAM initially, this would then bypass the whole read-modify-write issue with PSRAM too.
Just benchmarked some HyperRAM read code for inline execution with my logic analyzer by toggling a pin on entry/exit of my read routine and capturing the transfer. Results for sysclk/2 reads at 5MHz excluding any lock delays or reading back the data from the hub RAM but including the simulated call/return overheads with NOPs, was a read subroutine execution time of 24.58us. This scales down to 0.492us for a 250MHz P2 and 0.378us at 325MHz to do a single word read once you have setup the address and do a CALLPA to trigger the read. I don't think it will come down a lot more from this. The R/W gap between address/data phase is already very small, there's not a lot of time wasted.
Update: I think I managed to shave it down to 23us by not waiting for the final data phase completion with waitxfi before ending the transfer by raising the CS pin. Thankfully on the logic analyzer it looks like the CS pin is still being raised after the final clock cycle so I think the data should still (just) be getting into the P2 pipeline but I need to confirm with real HW. This trick only works for single transfers, not bursts which would have to wait to the end.
The setup latency is a real problem with HyperRAM, and PSRAM has a similar clock delay (~16 clocks to read the first element IIRC), but it's clock speed is 2x HyperRAM which should speed things quite a lot. I should try to code that one inline as well to compare it. A lot of my code is already executing while the transfer is happening so I'm not wasting any time where I have free cycles.
Also for reference, inline HyperRAM single word writes take 25.21us at 5MHz or 0.504us at 250MHz and 0.388us at 325MHz. Again without lock overhead, however this includes call/return overhead and it would require the data and the external memory write address to be already setup in their allotted registers. Here's the write:
@TonyB_ said:
How many P2 cycles would it take to read a block of say 32 or 64 bytes from HyperRam?
Sorry I missed this post earlier.
It would pretty much be the above numbers I've measured for the single word transfer plus the additional 30 bytes read at sysclk/2 (so ~60 additional P2 clocks) for a 32 byte read (total ~183 clocks), etc. In theory you could read at sysclk/1 to halve the transfer time of the data burst portion, but that is more complex code and burns more COGRAM space for switching setxfrq rates and delaying phases etc. It also exceeds the spec of HyperRAM when running the P2 above 200MHz and makes the input timing tricky and more restrictive over temperature ranges etc. Sysclk/2 is safer for HyperRAM.
I think PSRAM might be the better choice for console emulator use given its reduced latency but I'll still need to double check the timing there to prove that. I do know it could take some additional COG resources as it needs 16 LUT RAM entries too. A future P2 Edge is considering to use 16 bit wide PSRAM memory with 4 chips which is great for high resolution video use. In an ideal world the 16 bit PSRAM data bus could also be optionally split into two 8 bit buses if there were two independent clocks and chip selects wired to the memories, so you could then do an emulator in one pair of PSRAM chips and have another pair of PSRAMs free for either somewhat lower resolution shared video use, or to run another independent emulator in it's own address space without competition with other COGs. This would chew up 20 GPIO pins though instead of 18 but it is more flexible as you could either split or combine the PSRAMs for higher total performance depending on the application.
This extra GPIO wiring option might not be a possibility for the next gen P2 Edge if we need to keep an 8 bit GPIO block free at P32-P39. Perhaps it could make sense for an internally mounted L-shaped P2 EVAL PSRAM breakout I'd discussed a while back with @VonSzarvas where we could have some more control pins accessible and we could mount more optional RAMs on the reverse side for 64MB total (or for other SPI devices with the same pinout). In that configuration you could have up to 4 independent PSRAM banks for example. That would be great for multiple emulators operating in parallel accessing their memories directly if they can tolerate the reduced transfer rates with narrower data buses. For single element word transfers the narrower bus is not that much slower and latency still dominates. It just takes a few more clock cycles to read the short data. It does affect preload/caching performance if that gets used however.
@TonyB_ said:
How many P2 cycles would it take to read a block of say 32 or 64 bytes from HyperRam?
Sorry I missed this post earlier.
It would pretty much be the above numbers I've measured for the single word transfer plus the additional 30 bytes read at sysclk/2 (so ~60 additional P2 clocks) for a 32 byte read (total ~183 clocks), etc.
Thanks for the info. In summary then at 250MHz: 32 byte read ~0.75us and 64 byte read ~1.0us with ~0.5us setup time for each.
Checking the Mega Drive spec, ROM read bandwidth is 5MBps for 68000 and ~1.2MBps for Z80. You are correct that only read routine needed for external RAM after writing cartridge data.
Just coded the PSRAM equivalent for single element transfers only and captured the timing on the logic analyzer. Burst reads are more complex and are not included in the code at this point. Latency at 5MHz with sysclk/2 transfers is far better when compared to HyperRAM. Now only 15.17us @5MHz or 0.304us @250MHz or 0.234us @ 325MHz for a single byte/word or long read in the routine itself (again excluding any lock overheads or reading back the result from HUB).
37 COGRAM longs + 16 LUT longs were needed for this read code once the HW is setup initially. Burst reads would need more code space to support them. You can't wrap beyond the page boundary at full speed but this would not be a problem for cache reads if the line size is less than the page size and a multiple of 2 or if you put the RAM into its wrap mode which is designed for caching.
Update: read bursts only add 3 5 more COGRAM instructions (incurred for both singles and burst reads). This pushes the prior read number mentioned above to 17.21us @5MHz (86 clocks). The other thing to be aware of is that when reading bytes, or words from HUB, you need to read the data from some address offset in HUB RAM or within the long aligned address that is read, which will introduce more instructions. Right now this inline PSRAM read code routine does not sort this out (though it could with more instructions). This is because the memory is not byte or word addressable.
E.g., reading the external memory word at (byte) address $22 needs something like this with 3 more instructions at the end to select the desired word:
mov address, #$22
callpa #2, #read_mem ' read 2 bytes, address will get long aligned to $20 during the read and 4 bytes will be read (instead of 2)
rdlong data, hub
test address, #1 wc
if_nc getword data, data, #0
if_c getword data, data, #1
For byte reads you could do this (assuming pa is free to use so as not to clobber the current address)
mov address, #$22
callpa #1, #read_mem ' read 1 byte, address will get long aligned to $20 during the read and 4 bytes will be read (instead of 1)
rdlong data, hub
mov pa, #3
and pa, address
altgb pa, #data
getbyte data
@Wuerfel_21 said:
By burst read you mean just one long? Or just "not too much at once"?
Burst reads in general are more than one long being accessed. Though you can consider a 3 byte read a burst too. I've typically called the individual byte, word or longs reads "single" reads, and in my main memory drivers I have code paths dedicated/optimized for them. Bursts can be any length really. In this simplified inline case however, the inline reads of arbitrary length are all just bundled together and they all work the same way and stream some number of bytes from external RAM to HUB RAM.
Think the burst read code could be in Hubexec? It would be useful for DMA.
Can't be Hub-exec because it needs the fifo+streamer. Has to be run in COG-exec mode for this.
@Wuerfel_21 said:
By burst read you mean just one long? Or just "not too much at once"?
Burst reads in general are more than one long being accessed. Though you can consider a 3 byte read a burst too. I've typically called the individual byte, word or longs reads "single" reads, and in my main memory drivers I have code paths dedicated/optimized for them. Bursts can be any length really. In this simplified inline case however, the inline reads of arbitrary length are all just bundled together and they all work the same way and stream some number of bytes from external RAM to HUB RAM.
Think the burst read code could be in Hubexec? It would be useful for DMA.
Can't be Hub-exec because it needs the fifo+streamer. Has to be run in COG-exec mode for this.
Hmm well, could probably just just use the normal read function for DMA then, reading some 64 bytes or smth at a time. They need to be endian-swapped, so we couldn't directly burst into VRAM, anyways.
What triggers this DMA? Just some CPU code based activation or is it some peripheral device in another COG? Does the console emulator normally need to execute code and do DMA at the same time, or should it be okay to pause the CPU while the transfer happens given the emulator COG needs to actually execute the external RAM reading code?
@rogloh said:
What triggers this DMA? Just some CPU code based activation or is it some peripheral device in another COG? Does the console emulator normally need to execute code and do DMA at the same time, or should it be okay to pause the CPU while the transfer happens given the emulator COG needs to actually execute the external RAM reading code?
It is triggered by the CPU, yes. The 68k is halted during the transfer. The Z80 is not, but it shouldn't try to access the 68k bus during DMA, so it is generally turned off manually before triggering DMA. (This plus crappy sound code is why some games have scratchy sample playback)
Well, I think I got the shadow/highlight mode down now. It very certainly wouldn't work if you tried to highlight lots of pixels, because that takes 5 extra cycles per pixel... Shadowing is free though.
(Also, where I previously said that this runs at 325 MHz, I was an idiot, it's actually 327.6 MHz that I'm using)
This screen is actually a bad example of shad/hl, since it the only magic colors used are the 14,30,46 ones (presumably on accident, since that is an undocumented feature/bug). It does however demonstrate that the base state depends on just the priority bits from the planes. Plane A contains the background, all low priority. Plane B is just empty tiles, but with vertical bands of alternating priorities. B is then line-scrolled to make these bands go diagonal on the screen.


Comments
I know I should be doing other things, but somehow this is happening now (Mega Drive VDP)
Help I can't stop. Not sure if this even runs realtime, would have to hook a video driver up...

A CPU emulator will be slow if using random read instructions such as RDWORD to fetch opcodes. If XBYTE can be used then it should be used, always. The FIFO emulates a prefetch queue automatically and the only issue is that self-modifying nearby code might not work because the instruction is already in the pipeline. However if that is the case why would anyone write self-modifying code that cannot run? The FIFO could be reloaded if a memory write address >= PC instead of any write address.
I think the best XBYTE option for the 68000 (and the only practicable one) is to decode the high nibble of the opcode only. The LUT table will be the smallest possible at 16 longs (smaller than for 6502, 8080, Z80 or 8086) leaving most of LUT RAM for 'manual' decoding of other opcode bits or instruction emulation. It would be interesting to see how much of the 68000 could fit into reg & LUT RAM.
The speed loss from random read is negligible compared to:
Yes, that's due to using the streamer. On streamer reads from pins the COG doesn't actually see the data on the pins, they go straight into HUB RAM first and then get read back from there by the emulator. Perhaps at sysclk/2 you could try to read the pins to get at these data bytes if the instruction phase is aligned right, but that path is then different to any read bursts and would need more space. It could speed up things a little though by not needing that extra hub read cycle of 9-15 clocks after the data has already been read from the pins.
What exactly have you got working? All I see is screenshots.
As I said in the post before that, the Mega Drive VDP (what makes the graphics happen). Currently I'm just feeding it with VRAM dumps from a PC emulator.
I've actually hooked it up to your video code now. Too slow for 250 MHz, but 325 is OK. Not sure if it'd handle the worst case of 20 16-wide sprites on a line, otoh I think the main culprit is the compositor cog (which combines the layer data generated by the other), whose timing is mostly indifferent to what's actually on the screen.
Working so far:
- A/B Plane, including fine H/V scrolling, including line/column scrolling
- Sprites, including accurate masking and overflow behavior
- Priority between the Planes and Sprites
- Window plane, partially
- H40 and H32 modes (320x224 vs 256x224)
Not yet:
- Anything that'd be needed to actually connect to a 68k emulator (register interface, interrupts, etc)
- Actually changing video settings for H32 mode (currently just sits left-justified in the H40 frame)
- Shadow/Highlight mode
- Correct priority for window plane
- Window plane on left/right side
Pictured: Sonic and Tails just chilling on this column surrounded by lava. That's some attitude alright.
Anyways, rendered real-time at 325 MHz.
It would be better for an emulator to read code and data from hub RAM only. Is it one byte from HyperRam every sysclk/2 once streamer is running?
@Wuerfel_21 are you updating the video registers each scanline also? like palettes X and Y scroll offsets etc? for each plane and sprites?
Looks awesome though
Well, currently they don't get updated at all, they're just hardcoded. But making that happen is on the agenda. It will need a similar technique to OPN2cog where the registers need to be converted to a more convenient representation when the CPU writes them. It also needs little-endian VRAM data, so that must be swapped on write, too.
Vertical scroll (VSRAM) is updated every line and per-line scrolling is a built-in feature of the VDP (and the scroll table lives in VRAM so when it is written mid-frame, that should work)
Ok cool, was just checking, can't wait to see how you get on with it though it's looking very good so far!")
Currently I am trying to optimize the compositing cog enough to squeeze in shadow/highlight mode. As it was, it was just one instruction away from being too slow (at 325 MHz!). Now I've unrolled it and tapped into the immense energy of MUXQ to aggregate priority bits from 4 pixels simultaneously, which may have freed up just enough cycles.
Problem is that I can't find a reliable description of how it actually works. There's multiple conflicting ones, so I'll have to do some research.
For those playing along at home, in Shad/HL mode, each pixel can be either shadowed (RGB values halved), normal or highlighted (RGB values doubled). This depends on the output from the 3 layers.
What I've confirmed so far:
Sprite pixels with colors 14,30,46,62 and 63 affect the state. (Note that this only concerns the topmost sprite pixel sent to compositing)
The background color is affected by shadow/highlight
What I'm still missing:
Yes I know. But the cartridge ROM sizes are larger than Hub RAM allows hence the need for external RAM. Maybe some caching/preloading could help but that also burns more precious COG RAM space.
It is one byte streamed to HUB at sysclk/2 rate, yes. You can actually go to sysclk/1 rates for the data phase but its less reliable and it doesn't buy much for single transfers because the address phase is still done at sysclk/2. The v1 ISSI HyperRAM that the Parallax breakout board uses is technically being overclocked at P2 speeds above 200MHz when performing sysclk/1 reads, yet sysclk/2 operation still remains within the rated speed. This breakout board typically reaches its overclocked limit for sysclk/1 reads just above 300MHz for a P2-EVAL at room temp. Newer v2 HyperRAM is rated faster (166/200MHz) and shouldn't need to be overclocked at for a 325MHz P2.
The PSRAM stuff Parallax is considering for a future P2 Edge is able to transfer data over its 16 bit bus at 288MB/s at its rated speed but I've had it operating at 325MB/s with no apparent issues using my driver. The write speed is lessened though because it always needs to write 32 bit aligned data (the native storage size). PSRAM has no byte lane masking signal unlike HyperRAM with it's RWDS pin so for byte or word writes you need to read the old data first, update it with MUXQ and then write it back. It's far less of an issue for the larger burst write transfers, but it limits the performance for single and very short write bursts and consumes more COG RAM space to deal with all these extra cases. If you only write longs it's not a problem.
Fantastic @Wuerfel_21 . You really need a 68k P2 emulator.
I think I used to get around 12-16 16x16 pixel masked sprites per line on a P1 (4 COGs, 80 MIPS IIRC) after rendering the tiles, so hopefully a single P2 COG being effectively 2 times faster @325MHz and with far more memory bandwidth could do 20, but I don't know how much of the total P2's COG cycles you have available per scan line for your sprites, and this time available depends on the actual video scan line update rate too.
I'm not arguing against external RAM. I wasn't very clear before so I'll try again:
It would be better for an emulator to read code and data from hub RAM only therefore it is good thing that external RAM data are streamed to and from hub RAM. The emulator would not want to access external RAM directly as it much easier to use XBYTE and RFxxxx.
How many P2 cycles would it take to read a block of say 32 or 64 bytes from HyperRam?
Aha, yes now I see your point.
Normally I would recommend a separate COG to do all the external memory accesses and all client COGs will only need to read/write HUB RAM and the mailbox. In this case with an emulator, latency becomes critical and to reduce it (as well as saving a COG) the extra mailbox polling overhead can be eliminated and the memory driver is incorporated into the emulator COG(s). Luckily the model of getting the external memory read results from HUB RAM after making the memory request still remains. It also lets you pre-fetch / cache additional instructions.
The problem here is not neccessarily rendering the tiles/sprites, it is rendering exactly like a Mega Drive, including cutting the right sprite when the limit overflows. I tried to write an explanation of how sprite rendering works here and I literally couldn't, but it involves an intermediate list of up to 20 (16 in H32) sprites, partial caching of the sprite table, magic X positions that stop the sprite scanning, but only if there are any normal sprites before it, a limit of 40 (32 in H32) total sprite tiles on a line and the strange order in which they start to be dropped and aaaaaaaaaaaaaaaaaaaa.
Anyways, someone made a test screen for this and it passes all but one test. Somehow. I tried fixing that remaining test condition, but it didn't work properly and it is a very obscure one that I don't think ever comes up in a game. And yes, that means my janky VDP emulation is actually better in that regard than GensKMod (which I use to capture VRAM dumps)
Also, I think I may have found the answer to some of my shad/hl worries, I think. I am fairly certain now that a non 62 or 63 color from a high priority sprite is never affected by the planes' shadow state. And I guess a high priority plane is not affected by a low priority 62/63 sprite?
tl;dr; SEGA engineers are madmen.
Hey @Wuerfel_21 so if the external memory is for replacing cartridge ROM use, shouldn't that mean you would only need to write into external RAM once at the start to get the application/game loaded into external memory out of SD/Flash etc and then only perform reads after this until something else needs to be loaded? If so, you should then be able to reduce the overhead of the code in COG/LUTRAM by overlaying the external memory read routine with the write routine. Doing this would reduce its space requirement in COG RAM competing with the emulator's own space, as the write code consumes ~50 longs (bytes/words/bursts) vs 37 longs for reads. Write executable code reduces further down to 42 longs of code space if burst only writes are supported vs including support for single writes as well, or a few less if locks are not used.
Update: Also by doing only long aligned burst writes to load resources into external RAM initially, this would then bypass the whole read-modify-write issue with PSRAM too.
Just benchmarked some HyperRAM read code for inline execution with my logic analyzer by toggling a pin on entry/exit of my read routine and capturing the transfer. Results for sysclk/2 reads at 5MHz excluding any lock delays or reading back the data from the hub RAM but including the simulated call/return overheads with NOPs, was a read subroutine execution time of 24.58us. This scales down to 0.492us for a 250MHz P2 and 0.378us at 325MHz to do a single word read once you have setup the address and do a CALLPA to trigger the read. I don't think it will come down a lot more from this. The R/W gap between address/data phase is already very small, there's not a lot of time wasted.
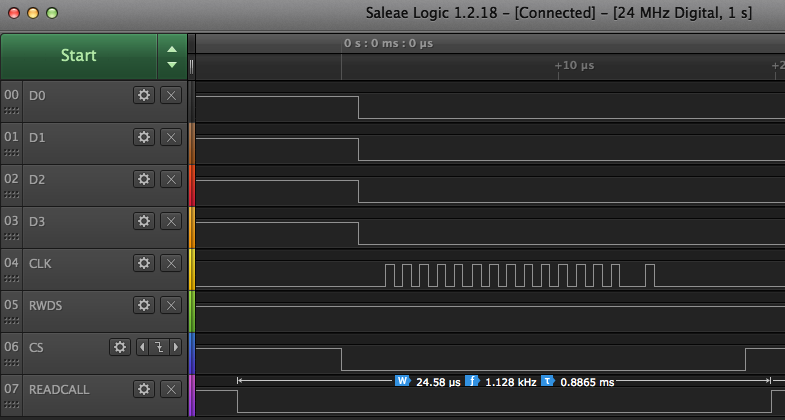
Update: I think I managed to shave it down to 23us by not waiting for the final data phase completion with waitxfi before ending the transfer by raising the CS pin. Thankfully on the logic analyzer it looks like the CS pin is still being raised after the final clock cycle so I think the data should still (just) be getting into the P2 pipeline but I need to confirm with real HW. This trick only works for single transfers, not bursts which would have to wait to the end.
The setup latency is a real problem with HyperRAM, and PSRAM has a similar clock delay (~16 clocks to read the first element IIRC), but it's clock speed is 2x HyperRAM which should speed things quite a lot. I should try to code that one inline as well to compare it. A lot of my code is already executing while the transfer is happening so I'm not wasting any time where I have free cycles.
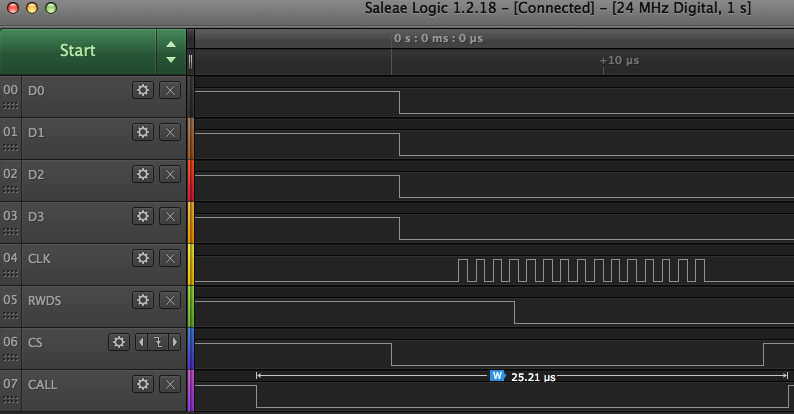
Also for reference, inline HyperRAM single word writes take 25.21us at 5MHz or 0.504us at 250MHz and 0.388us at 325MHz. Again without lock overhead, however this includes call/return overhead and it would require the data and the external memory write address to be already setup in their allotted registers. Here's the write:
Sorry I missed this post earlier.
It would pretty much be the above numbers I've measured for the single word transfer plus the additional 30 bytes read at sysclk/2 (so ~60 additional P2 clocks) for a 32 byte read (total ~183 clocks), etc. In theory you could read at sysclk/1 to halve the transfer time of the data burst portion, but that is more complex code and burns more COGRAM space for switching setxfrq rates and delaying phases etc. It also exceeds the spec of HyperRAM when running the P2 above 200MHz and makes the input timing tricky and more restrictive over temperature ranges etc. Sysclk/2 is safer for HyperRAM.
I think PSRAM might be the better choice for console emulator use given its reduced latency but I'll still need to double check the timing there to prove that. I do know it could take some additional COG resources as it needs 16 LUT RAM entries too. A future P2 Edge is considering to use 16 bit wide PSRAM memory with 4 chips which is great for high resolution video use. In an ideal world the 16 bit PSRAM data bus could also be optionally split into two 8 bit buses if there were two independent clocks and chip selects wired to the memories, so you could then do an emulator in one pair of PSRAM chips and have another pair of PSRAMs free for either somewhat lower resolution shared video use, or to run another independent emulator in it's own address space without competition with other COGs. This would chew up 20 GPIO pins though instead of 18 but it is more flexible as you could either split or combine the PSRAMs for higher total performance depending on the application.
This extra GPIO wiring option might not be a possibility for the next gen P2 Edge if we need to keep an 8 bit GPIO block free at P32-P39. Perhaps it could make sense for an internally mounted L-shaped P2 EVAL PSRAM breakout I'd discussed a while back with @VonSzarvas where we could have some more control pins accessible and we could mount more optional RAMs on the reverse side for 64MB total (or for other SPI devices with the same pinout). In that configuration you could have up to 4 independent PSRAM banks for example. That would be great for multiple emulators operating in parallel accessing their memories directly if they can tolerate the reduced transfer rates with narrower data buses. For single element word transfers the narrower bus is not that much slower and latency still dominates. It just takes a few more clock cycles to read the short data. It does affect preload/caching performance if that gets used however.
Thanks for the info. In summary then at 250MHz: 32 byte read ~0.75us and 64 byte read ~1.0us with ~0.5us setup time for each.
Checking the Mega Drive spec, ROM read bandwidth is 5MBps for 68000 and ~1.2MBps for Z80. You are correct that only read routine needed for external RAM after writing cartridge data.
Just coded the PSRAM equivalent for single element transfers only and captured the timing on the logic analyzer. Burst reads are more complex and are not included in the code at this point. Latency at 5MHz with sysclk/2 transfers is far better when compared to HyperRAM. Now only 15.17us @5MHz or 0.304us @250MHz or 0.234us @ 325MHz for a single byte/word or long read in the routine itself (again excluding any lock overheads or reading back the result from HUB).
37 COGRAM longs + 16 LUT longs were needed for this read code once the HW is setup initially. Burst reads would need more code space to support them. You can't wrap beyond the page boundary at full speed but this would not be a problem for cache reads if the line size is less than the page size and a multiple of 2 or if you put the RAM into its wrap mode which is designed for caching.
Update: read bursts only add 3 5 more COGRAM instructions (incurred for both singles and burst reads). This pushes the prior read number mentioned above to 17.21us @5MHz (86 clocks). The other thing to be aware of is that when reading bytes, or words from HUB, you need to read the data from some address offset in HUB RAM or within the long aligned address that is read, which will introduce more instructions. Right now this inline PSRAM read code routine does not sort this out (though it could with more instructions). This is because the memory is not byte or word addressable.
E.g., reading the external memory word at (byte) address $22 needs something like this with 3 more instructions at the end to select the desired word:
mov address, #$22 callpa #2, #read_mem ' read 2 bytes, address will get long aligned to $20 during the read and 4 bytes will be read (instead of 2) rdlong data, hub test address, #1 wc if_nc getword data, data, #0 if_c getword data, data, #1For byte reads you could do this (assuming pa is free to use so as not to clobber the current address)
mov address, #$22 callpa #1, #read_mem ' read 1 byte, address will get long aligned to $20 during the read and 4 bytes will be read (instead of 1) rdlong data, hub mov pa, #3 and pa, address altgb pa, #data getbyte dataBy burst read you mean just one long? Or just "not too much at once"?
Think the burst read code could be in Hubexec? It would be useful for DMA.
Burst reads in general are more than one long being accessed. Though you can consider a 3 byte read a burst too. I've typically called the individual byte, word or longs reads "single" reads, and in my main memory drivers I have code paths dedicated/optimized for them. Bursts can be any length really. In this simplified inline case however, the inline reads of arbitrary length are all just bundled together and they all work the same way and stream some number of bytes from external RAM to HUB RAM.
Can't be Hub-exec because it needs the fifo+streamer. Has to be run in COG-exec mode for this.
Hmm well, could probably just just use the normal read function for DMA then, reading some 64 bytes or smth at a time. They need to be endian-swapped, so we couldn't directly burst into VRAM, anyways.
What triggers this DMA? Just some CPU code based activation or is it some peripheral device in another COG? Does the console emulator normally need to execute code and do DMA at the same time, or should it be okay to pause the CPU while the transfer happens given the emulator COG needs to actually execute the external RAM reading code?
It is triggered by the CPU, yes. The 68k is halted during the transfer. The Z80 is not, but it shouldn't try to access the 68k bus during DMA, so it is generally turned off manually before triggering DMA. (This plus crappy sound code is why some games have scratchy sample playback)
Well, I think I got the shadow/highlight mode down now. It very certainly wouldn't work if you tried to highlight lots of pixels, because that takes 5 extra cycles per pixel... Shadowing is free though.
(Also, where I previously said that this runs at 325 MHz, I was an idiot, it's actually 327.6 MHz that I'm using)
This screen is actually a bad example of shad/hl, since it the only magic colors used are the 14,30,46 ones (presumably on accident, since that is an undocumented feature/bug). It does however demonstrate that the base state depends on just the priority bits from the planes. Plane A contains the background, all low priority. Plane B is just empty tiles, but with vertical bands of alternating priorities. B is then line-scrolled to make these bands go diagonal on the screen.