Oh, I think my info on highlight was flaky. Apparently it doesn't double the RGB values, it halves them, but shifts them up into the top half. This is nice, because that means the code now not only works without any slow pixel mixer ops, but I also saved one instruction overall by merging it into the shadowing case.
After also fixing something related to sprite flipping, this dump from Vectorman now renders correctly:
Implemented side window. For how useful of a feature it seems like, it was actually difficult to find a game that uses it. Truxton does, but doesn't horizontally scroll, so ehhh not sure if that works.
Implemented interlaced double resolution mode. Isn't hooked up to actually interlace/bob the display, but renders right. (Bottom of the screen is glitched because the game writes VSRAM and the sprite table mid-frame, which a VRAM dump doesn't capture. And obviously the screengrab only captures one field)
Looking good. If you need to interlace the output and source different video data on alternate fields it can be done in the video driver too. But your sprite driver could probably do this step per field and just share the same line buffer feeding the video driver I imagine. A pure frame-buffer application (non-sprite) would be different and need the video driver to do this step.
It appears the main unknown left here is if you can get a full 68k emulator into a single COG. How confident are we on this missing piece? Be bad if it is a show stopper after all your hard work on all the other parts.
@rogloh said:
Looking good. If you need to interlace the output and source different video data on alternate fields it can be done in the video driver too. But your sprite driver could probably do this step per field and just share the same line buffer feeding the video driver I imagine. A pure frame-buffer application (non-sprite) would be different and need the video driver to do this step.
Yeah, it alternates between rendering the fields. It'd just need to be hooked up to the video driver's field counter and it'd work. For linedoubled VGA output, everything needs to be shifted down by one line every other frame to simulate interlacing, IDK how that's best done.
It appears the main unknown left here is if you can get a full 68k emulator into a single COG. How confident are we on this missing piece? Be bad if it is a show stopper after all your hard work on all the other parts.
Well, I thought the VDP might be a showstopper, that's why I made it (and without some dank optimizations, full shadow/highlight support would have been a problem - loads of bit magic, unrolling and SKIPF down in the compositor cog)
Anyways, I've attached what I've got. As said, needs 2 cogs at 327 MHz (though 302 also seems to work?). Outputs over VGA (though with some (un-)commenting, you can also get DEBUG bitmap output). Go to the bottom and you will find different dumps to uncomment.
The render cog has some optimizations left unsqueezed. In particular, if VRAM was at a known 64k-aligned address, that could already be added onto the base address registers to save some cycles here and there.
By the way, I noticed you are trying out your own CLKMODE values. You can now set this field to zero and just give the frequency and the video driver will compute the "best" setting to minimize the error. You could just set 0 instead of $01C732FB below. But if you need to tweak the PLL multipliers and dividers manually to experiment there you still can.
vga_timing 'VGA resolution 640x480 60Hz with 25.2MHz pixel clock
long $01C732FB
long 327_600_000
'_HSyncPolarity___FrontPorch__SyncWidth___BackPorch__Columns
' 1 bit 7 bits 8 bits 8 bits 8 bits
long (video.SYNC_NEG<<31) | ( 16<<24) | ( 96<<16) | ( 48<<8 ) | (640/8)
'_VSyncPolarity___FrontPorch__SyncWidth___BackPorch__Visible
' 1 bit 8 bits 3 bits 9 bits 11 bits
long (video.SYNC_NEG<<31) | ( 10<<23) | ( 2<<20) | ( 33<<11) | 480
long 13 << 8 ' $0ccccccc+1
long 0
long 0 ' reserved for CFRQ parameter
Ah, I just pull the values PNut computes. IIRC your frequency calculation didn't work as well or something.
Also, just to brag, here is the H32 sprite overflow/mask test screen on my VDP. All but one weird behaviour correctly emulated
And this is what Gens KMod (which I use to dump VRAM/CRAM and view register settings) does, lol (The pass on test 6 is a false positive because test 5 fails)
@rogloh said:
It appears the main unknown left here is if you can get a full 68k emulator into a single COG. How confident are we on this missing piece? Be bad if it is a show stopper after all your hard work on all the other parts.
I think it's unlikely that a 68000 emulator will need two cogs.
Just tried your last zipped code above but I can't get any image output. It has a black VGA output only. If I uncomment out this code below I can see some test stripes so I know the video is being generated by the video driver. I think when the vdpc_entry is spawned it is either just driving out black or otherwise crashing in my setup. Used 5.3.1 as well as 5.4.3 of flexspin. Monitor sees 640x480 VGA but black screen only if the last coginit call below is enabled. Not sure if the version you posted needs something else to make it work other than changing the A/V pins.
coginit(COGEXEC_NEW,@vdpr_entry,0)
repeat p from 0 to 64
outBuffer[p] := p*$04030201
'coginit(COGEXEC_NEW,@vdpc_entry,0)
This is a pity as I wanted to test out some code that saves 6 instructions in your sprtloop which I think should help.
Ok @Wuerfel_21, if you want some more cycles saved, instead of doing all this in your existing unrolled code
rdlong vdpr_tiledata,vdpr_tmp4
' Prepare tilebuffer
mov vdpr_tilebuffer1,vdpr_tile
shr vdpr_tilebuffer1,#13 ' Just pal+priority
shl vdpr_tilebuffer1,#4
movbyts vdpr_tilebuffer1,#%%0000
mov vdpr_tilebuffer2,vdpr_tilebuffer1
testb vdpr_tile,#11 wc ' mirror bit
if_nc skipf hnormal_skipf
if_c skipf hmirror_skipf
' Unrolled decode
getnib vdpr_tmp1,vdpr_tiledata,#4
setnib vdpr_tilebuffer2,vdpr_tmp1,#6 ' normal
setnib vdpr_tilebuffer1,vdpr_tmp1,#0 ' mirror
getnib vdpr_tmp1,vdpr_tiledata,#5
setnib vdpr_tilebuffer2,vdpr_tmp1,#4 ' normal
setnib vdpr_tilebuffer1,vdpr_tmp1,#2 ' mirror
getnib vdpr_tmp1,vdpr_tiledata,#6
setnib vdpr_tilebuffer2,vdpr_tmp1,#2 ' normal
setnib vdpr_tilebuffer1,vdpr_tmp1,#4 ' mirror
getnib vdpr_tmp1,vdpr_tiledata,#7
setnib vdpr_tilebuffer2,vdpr_tmp1,#0 ' normal
setnib vdpr_tilebuffer1,vdpr_tmp1,#6 ' mirror
getnib vdpr_tmp1,vdpr_tiledata,#0
setnib vdpr_tilebuffer1,vdpr_tmp1,#6 ' normal
setnib vdpr_tilebuffer2,vdpr_tmp1,#0 ' mirror
getnib vdpr_tmp1,vdpr_tiledata,#1
setnib vdpr_tilebuffer1,vdpr_tmp1,#4 ' normal
setnib vdpr_tilebuffer2,vdpr_tmp1,#2 ' mirror
getnib vdpr_tmp1,vdpr_tiledata,#2
setnib vdpr_tilebuffer1,vdpr_tmp1,#2 ' normal
setnib vdpr_tilebuffer2,vdpr_tmp1,#4 ' mirror
getnib vdpr_tmp1,vdpr_tiledata,#3
setnib vdpr_tilebuffer1,vdpr_tmp1,#0 ' normal
setnib vdpr_tilebuffer2,vdpr_tmp1,#6 ' mirror
' make transparent pixels go to zero
test vdpr_tilebuffer1,vdpr_pixnibtest+0 wz
if_z setbyte vdpr_tilebuffer1,#0,#0
test vdpr_tilebuffer1,vdpr_pixnibtest+1 wz
if_z setbyte vdpr_tilebuffer1,#0,#1
test vdpr_tilebuffer1,vdpr_pixnibtest+2 wz
if_z setbyte vdpr_tilebuffer1,#0,#2
test vdpr_tilebuffer1,vdpr_pixnibtest+3 wz
if_z setbyte vdpr_tilebuffer1,#0,#3
test vdpr_tilebuffer2,vdpr_pixnibtest+0 wz
if_z setbyte vdpr_tilebuffer2,#0,#0
test vdpr_tilebuffer2,vdpr_pixnibtest+1 wz
if_z setbyte vdpr_tilebuffer2,#0,#1
test vdpr_tilebuffer2,vdpr_pixnibtest+2 wz
if_z setbyte vdpr_tilebuffer2,#0,#2
test vdpr_tilebuffer2,vdpr_pixnibtest+3 wz
if_z setbyte vdpr_tilebuffer2,#0,#3
you can do this to save 6 instructions for each tile/sprite :
rdlong vdpr_tiledata,vdpr_tmp4
' Prepare tilebuffer
mov pa, vdpr_tile
shr pa, #13 ' Just pal+priority
shl pa, #4
testb vdpr_tile, #11 wc ' mirror
if_nc splitb vdpr_tiledata ' reverse nibbles in tile
if_nc rev vdpr_tiledata
if_nc movbyts vdpr_tiledata, #%%0123
if_nc mergeb vdpr_tiledata
getword vdpr_tilebuffer1, vdpr_tiledata, #1 ' first group
movbyts vdpr_tilebuffer1, #%%3120
mergew vdpr_tilebuffer1
movbyts vdpr_tilebuffer1, #%%3120
splitw vdpr_tilebuffer1
getword vdpr_tilebuffer2, vdpr_tiledata, #0 ' second group
movbyts vdpr_tilebuffer2, #%%3120
mergew vdpr_tilebuffer2
movbyts vdpr_tilebuffer2, #%%3120
splitw vdpr_tilebuffer2
' make transparent pixels go to zero
test vdpr_tilebuffer1,vdpr_pixnibtest+0 wz
if_nz setnib vdpr_tilebuffer1,pa,#1
test vdpr_tilebuffer1,vdpr_pixnibtest+1 wz
if_nz setnib vdpr_tilebuffer1,pa,#3
test vdpr_tilebuffer1,vdpr_pixnibtest+2 wz
if_nz setnib vdpr_tilebuffer1,pa,#5
test vdpr_tilebuffer1,vdpr_pixnibtest+3 wz
if_nz setnib vdpr_tilebuffer1,pa,#7
test vdpr_tilebuffer2,vdpr_pixnibtest+0 wz
if_nz setnib vdpr_tilebuffer2,pa,#1
test vdpr_tilebuffer2,vdpr_pixnibtest+1 wz
if_nz setnib vdpr_tilebuffer2,pa,#3
test vdpr_tilebuffer2,vdpr_pixnibtest+2 wz
if_nz setnib vdpr_tilebuffer2,pa,#5
test vdpr_tilebuffer2,vdpr_pixnibtest+3 wz
if_nz setnib vdpr_tilebuffer2,pa,#7
It appears to still display tiles okay with this change but you might need to check its output carefully. I used "pa" as a temp variable, you might like it to be something else.
There's another similar unrolled loop in your vpdr_renderplane routine, which might be able to use the same technique to save about 4 instructions or so there too.
Update: yes it works there also and saves 3 instructions in that loop too. Just tried it. There might even be another shorter mergew/movbyts sequence that works better than what I stumbled upon, didn't dig further once I found one that worked.
Uhm, I think your code is giving sonic a pretty bad sunburn
Luckily, the solution is is simple, just remove the shl pa,#4 (also, I replaced the usage of pa with vdpr_tmp1), which was causing it to ignore sprite priority and palette. That's also another saved op in a hot loop!
@rogloh said:
Used 5.3.1 as well as 5.4.3 of flexspin. Monitor sees 640x480 VGA but black screen only if the last coginit call below is enabled.
Update: got it working in PropTool instead.
You see this? This is what my code does to flexspin.
@Wuerfel_21 said:
Uhm, I think your code is giving sonic a pretty bad sunburn
Yeah I wanted you to check it carefully as I'm not familiar with the regular colours to pick that up.
Luckily, the solution is is simple, just remove the shl pa,#4 (also, I replaced the usage of pa with vdpr_tmp1), which was causing it to ignore sprite priority and palette. That's also another saved op in a hot loop!
Good, I'm glad it is in loop that was tight that affects all tiles/sprites and you found yet another savings there too. Hopefully this frees up quite a bit with 40 tiles and 20 more sprites per line sharing the path. That's potentially 60x7 = 420 instructions, which is over a 2us per scan line @325MHz.
You see this? This is what my code does to flexspin.
Yeah not sure why it fails on flexspin. It builds but doesn't run. Must be a difference somewhere, which is weird because it is mostly PASM2 code which should be identical. Perhaps it's memory layout related.
Good, I'm glad it is in loop that was tight that affects all tiles/sprites and you found yet another savings there too. Hopefully this frees up quite a bit with 40 tiles and 20 more sprites per line sharing the path. That's potentially 60x7 = 420 instructions, which is over a 2us per scan line @325MHz.
That's not how it works. On any line (in H40 mode), there are 2 planes of 40 or 41 tiles (the latter if scrolling partially through a tile). Then there can be up to 20 sprites, but each of them can be 1,2,3 or 4 tiles wide, though there is a limit of 40 sprite tiles total. So the plane tile loop actually runs up to 82 times and the sprite one up to 40 times.
@TonyB_ said:
@rogloh said:
Put $20_20_20_20 in a reg and use muxc to save four cycles.
Yeah done that. It's only per-line, but the compositor needs all the cycles it can, lol.
Have you tried MUXNIBS? It's in the instruction set specifically for VDP-style transparent pixels.
Only useful if you're actually drawing to a 4bpp buffer, whereas this is technically using 8bpp index buffers.
Here's all the optimizations integrated. I've also made vdpr_renderPlane use the FIFO to save some more cycles. The limiting factor is still the compositing. Good luck trying to understand what that code even does, lol.
Just tried to test on flexspin to see what is wrong and it doesn't even compile for me:
Reordering the OBJ above the VAR block makes it compile, but yes, black screen. However, the highlighted pixels from the Vectorman dump do show up, so it's probably the updateCRAM32 spin function that is gonked.
Edit: no, for some reason the cog just loads zeroes regardless of what the cram32 array contains
Edit 2: no wait i'm stupid
Yeah I had to reorder the OBJ block too. That's due to some fairly recent change in Flexspin.
Gut feeling tells me it will probably be some type of addressing problem with how Flexspin lays out its memory vs PropTool and/or could be related to access of uninitialized data perhaps. I will be interested to hear what it is when you figure it out.
OMG, just reading through your compositor code figuring out what it is doing @Wuerfel_21 . That's one serious piece of code. Looks very optimized already. It would have taken quite a while to get that all figured out and working right.
Well done.
@rogloh said:
OMG, just reading through your compositor code figuring out what it is doing @Wuerfel_21 . That's one serious piece of code. Looks very optimized already. It would have taken quite a while to get that all figured out and working right.
Well done.
Yeah, as is, it's basically better than it needs to be (being that its load is mostly constant). It runs properly down to 302 MHz, whereas I think that around 325 is what the combined emulator should target. Could probably improve the OPN2 quality a bit, too, at that speed (improve EG and PSG update rates).
Then again, I'm thinking that having an additional plane for menus and such would be useful to have, and that code would go into the compositor.
Also, what do you think is the best method to affecting the video output based on register settings? (i.e. switch pixel clocks for H40 vs H32, set interlaced vs progressive on SDTV, make the screen bob on VGA to simulate interlace, etc)
@Wuerfel_21 said:
Also, what do you think is the best method to affecting the video output based on register settings? (i.e. switch pixel clocks for H40 vs H32, set interlaced vs progressive on SDTV, make the screen bob on VGA to simulate interlace, etc)
Right now, to change the display resolution/timing or interlaced vs progressive SDTV I imagine you'll need something to trigger on whatever registers control this in your emulator to go and restart the video COG and give it the new startup parameters with the new PLL & display settings so it will make the necessary adjustments and output in the new manner. The interlaced mode output for a graphics region in VGA output mode will just source data from different frame buffers on alternate frames which may not help much in the end given your full screen sprite rendering is dynamic computed already and doesn't really rely on or use a static frame buffer in memory for its operation (unless you were planning to overlay some static regions perhaps as menus outside of gameplay or something).
@Wuerfel_21 said:
Also, what do you think is the best method to affecting the video output based on register settings? (i.e. switch pixel clocks for H40 vs H32, set interlaced vs progressive on SDTV, make the screen bob on VGA to simulate interlace, etc)
Right now, to change the display resolution/timing or interlaced vs progressive SDTV I imagine you'll need something to trigger on whatever registers control this in your emulator to go and restart the video COG and give it the new startup parameters with the new PLL & display settings so it will make the necessary adjustments and output in the new manner. The interlaced mode output for a graphics region in VGA output mode will just source data from different frame buffers on alternate frames which may not help much in the end given your full screen sprite rendering is dynamic computed already and doesn't really rely on or use a static frame buffer in memory for its operation (unless you were planning to overlay some static regions perhaps as menus outside of gameplay or something).
Ah, so the timing and interlace flag can only be reloaded by restarting the video? Well, not too bad, because mode changes causes video glitches on HW, too.
I think the bobbing can be facilitated by messing with the "first rewrap" field before the next frame starts?
I wish I had this much time... Well I used to have that 10+ years ago when I made the PC Engine emulator and was single without kids. . The PC Engine emulator is still on my P2 ToDo list, but that list is quite big and I have got very little time for the P2 right now!
@Wuerfel_21 , do you plan to add collision detection somewhere (in your VDPR component perhaps), and, if so, will that likely slow it down quite a bit? Did the Genesis/MD expect sprite collision to be handled by the main CPU only or was there some HW support for this? Hopefully adding any sprite collision detection would still remain below 325MHz...?
Update: if it is just basic non-zero pixel detection you might be able to do something like this, where a "collision" reg gets cleared at start of the sprite loop, and tested at the end to see if something collided (pa/pb are just used as temp regs in sample below). It might only add 16-23 clocks to the sprite loop, some of which were thankfully reclaimed by my earlier suggested optimization. You might even be able to position this code somewhere convenient in the overall loop to take advantage of the fixed hub cycle latency, given that you would be writing to the same address pair in hub memory soon after the read using that wmlong instruction. That might bring down the cycle overhead of the rdlong from its worst case number.
```
' Figure out where to draw
mov vdpr_tmp1,ptra
add vdpr_tmp1,vdpr_sprHpos
setq #1 ' NEW CODE - read 2 longs for 8 pixels of sprite tile already at this address
rdlong pa, vdpr_tmp1 ' NEW CODE
or collision, pa ' NEW CODE
or collision, pb ' NEW CODE
setq #1
wmlong vdpr_tilebuffer1,vdpr_tmp1
There is a simple hardware collision flag just like that, but apparently almost nothing uses it because it's basically pointless (it really just says "any two sprites collided"). Probably not worth it.
@rogloh said:
@Wuerfel_21 , do you plan to add collision detection somewhere (in your VDPR component perhaps), and, if so, will that likely slow it down quite a bit? Did the Genesis/MD expect sprite collision to be handled by the main CPU only or was there some HW support for this? Hopefully adding any sprite collision detection would still remain below 325MHz...?
Update: if it is just basic non-zero pixel detection you might be able to do something like this, where a "collision" reg gets cleared at start of the sprite loop, and tested at the end to see if something collided (pa/pb are just used as temp regs in sample below). It might only add 16-23 clocks to the sprite loop, some of which were thankfully reclaimed by my earlier suggested optimization.
Sprites are superimposed onto background and won't your code detect collisions between sprites and background as well as sprite-sprite collisions?
@TonyB_ said:
Sprites are superimposed onto background and won't your code detect collisions between sprites and background as well as sprite-sprite collisions?
No because the sprites are written to different a HUB RAM scan line pixel buffer to those used by the background tiles (A/B) before going to the compositor COG. The buffer is cleared before the sprites are drawn. The compositor COG then merges the A, B and S layers together taking account of the priority and background colour (at least that is how I understand it working, but I didn't write it so I might have missed some key parts there).
@TonyB_ said:
Sprites are superimposed onto background and won't your code detect collisions between sprites and background as well as sprite-sprite collisions?
No because the sprites are written to different a HUB RAM scan line pixel buffer to those used by the background tiles (A/B) before going to the compositor COG. The buffer is cleared before the sprites are drawn. The compositor COG then merges the A, B and S layers together taking account of the priority and background colour (at least that is how I understand it working, but I didn't write it so I might have missed some key parts there).
Thanks for the info. Reading data from a sprite-only buffer before writing to the same address is a good way of detecting sprite collision, however I don't see how OR in your code can work. If corresponding old and new bytes are both non-zero then collision has occurred, however TEST will not detect this all the time unless the same bit in both is always set. It would help to know what the sprite data bytes consist of.


Comments
Oh, I think my info on highlight was flaky. Apparently it doesn't double the RGB values, it halves them, but shifts them up into the top half. This is nice, because that means the code now not only works without any slow pixel mixer ops, but I also saved one instruction overall by merging it into the shadowing case.
After also fixing something related to sprite flipping, this dump from Vectorman now renders correctly:
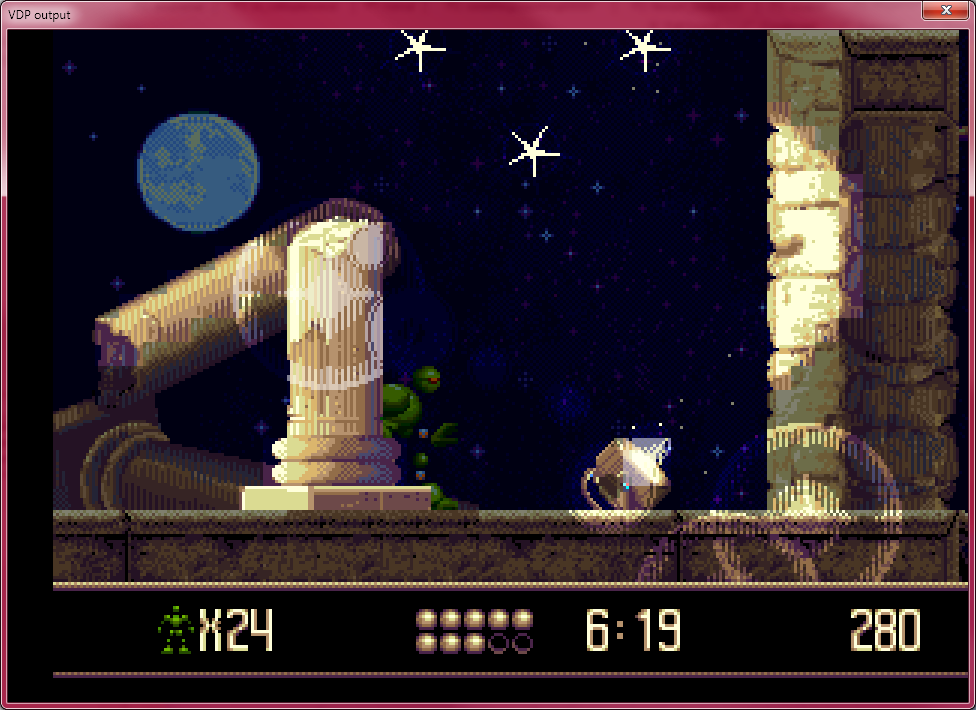
VDP is mostly done now, I think.
Actually reloads register data from hub now.
Implemented side window. For how useful of a feature it seems like, it was actually difficult to find a game that uses it. Truxton does, but doesn't horizontally scroll, so ehhh not sure if that works.
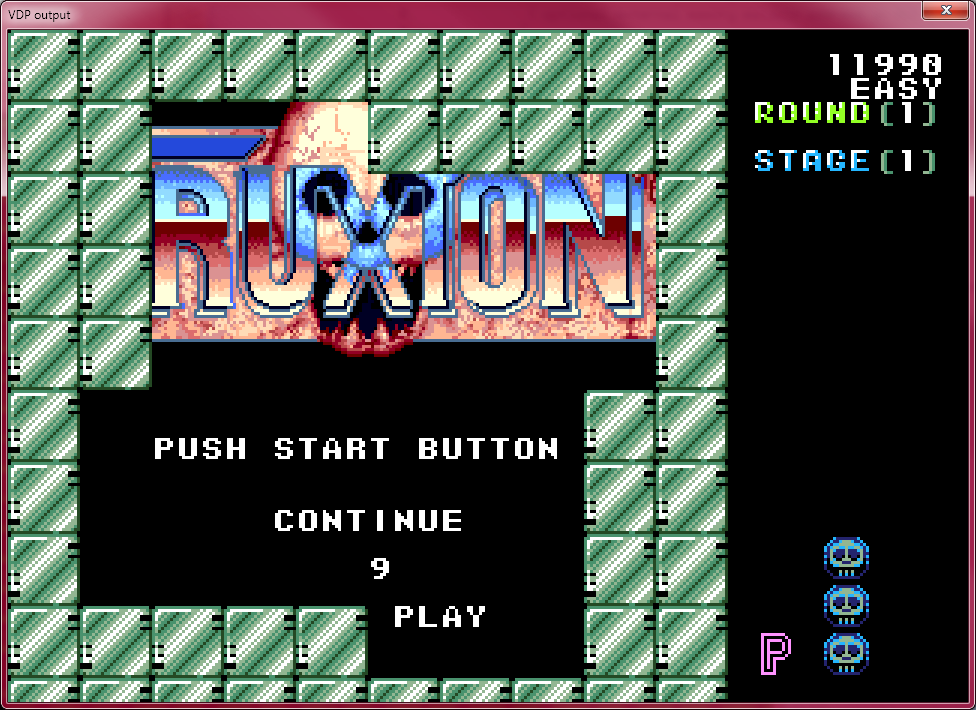
Implemented interlaced double resolution mode. Isn't hooked up to actually interlace/bob the display, but renders right. (Bottom of the screen is glitched because the game writes VSRAM and the sprite table mid-frame, which a VRAM dump doesn't capture. And obviously the screengrab only captures one field)

Looking good. If you need to interlace the output and source different video data on alternate fields it can be done in the video driver too. But your sprite driver could probably do this step per field and just share the same line buffer feeding the video driver I imagine. A pure frame-buffer application (non-sprite) would be different and need the video driver to do this step.
It appears the main unknown left here is if you can get a full 68k emulator into a single COG. How confident are we on this missing piece? Be bad if it is a show stopper after all your hard work on all the other parts.
Yeah, it alternates between rendering the fields. It'd just need to be hooked up to the video driver's field counter and it'd work. For linedoubled VGA output, everything needs to be shifted down by one line every other frame to simulate interlacing, IDK how that's best done.
Well, I thought the VDP might be a showstopper, that's why I made it (and without some dank optimizations, full shadow/highlight support would have been a problem - loads of bit magic, unrolling and SKIPF down in the compositor cog)
Anyways, I've attached what I've got. As said, needs 2 cogs at 327 MHz (though 302 also seems to work?). Outputs over VGA (though with some (un-)commenting, you can also get DEBUG bitmap output). Go to the bottom and you will find different dumps to uncomment.
The render cog has some optimizations left unsqueezed. In particular, if VRAM was at a known 64k-aligned address, that could already be added onto the base address registers to save some cycles here and there.
By the way, I noticed you are trying out your own CLKMODE values. You can now set this field to zero and just give the frequency and the video driver will compute the "best" setting to minimize the error. You could just set 0 instead of $01C732FB below. But if you need to tweak the PLL multipliers and dividers manually to experiment there you still can.
vga_timing 'VGA resolution 640x480 60Hz with 25.2MHz pixel clock long $01C732FB long 327_600_000 '_HSyncPolarity___FrontPorch__SyncWidth___BackPorch__Columns ' 1 bit 7 bits 8 bits 8 bits 8 bits long (video.SYNC_NEG<<31) | ( 16<<24) | ( 96<<16) | ( 48<<8 ) | (640/8) '_VSyncPolarity___FrontPorch__SyncWidth___BackPorch__Visible ' 1 bit 8 bits 3 bits 9 bits 11 bits long (video.SYNC_NEG<<31) | ( 10<<23) | ( 2<<20) | ( 33<<11) | 480 long 13 << 8 ' $0ccccccc+1 long 0 long 0 ' reserved for CFRQ parameterAh, I just pull the values PNut computes. IIRC your frequency calculation didn't work as well or something.
Also, just to brag, here is the H32 sprite overflow/mask test screen on my VDP. All but one weird behaviour correctly emulated
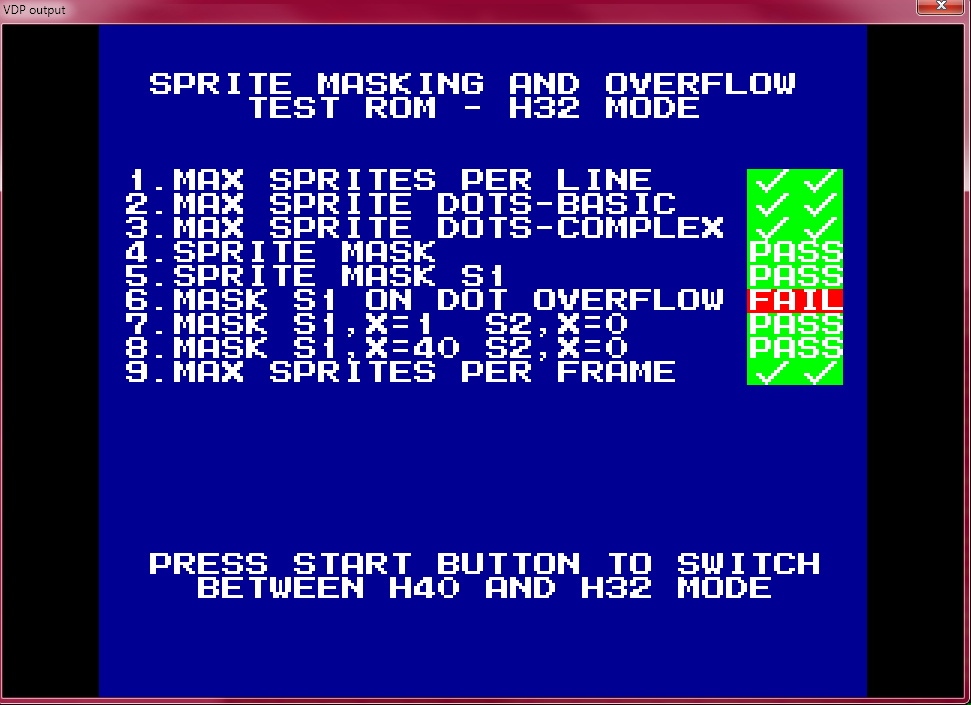
And this is what Gens KMod (which I use to dump VRAM/CRAM and view register settings) does, lol (The pass on test 6 is a false positive because test 5 fails)
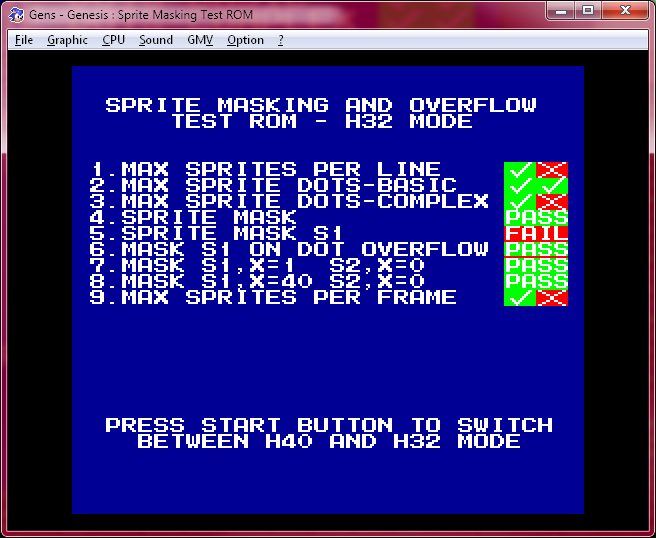
I think it's unlikely that a 68000 emulator will need two cogs.
Here's two free clock cycles if things are tight:
Change
vdpr_linelp .linewait rdlong vdpr_tmp1,vdpr_linecnt add vdpr_tmp1,#2 cmp vdpr_tmp1,vdpr_curline wz if_e jmp #.linewait mov vdpr_curline,vdpr_tmp1 'debug(sdec(vdpr_curline)) cmps vdpr_curline,##-1 wc if_b jmp #vdpr_linelp cmps vdpr_curline,#224 wc if_ae jmp #vdpr_linelp ' where are you setting the z flag for if_ae?to
vdpr_linelp .linewait rdlong vdpr_tmp1,vdpr_linecnt add vdpr_tmp1,#2 cmp vdpr_tmp1,vdpr_curline wz if_e jmp #.linewait mov vdpr_curline,vdpr_tmp1 'debug(sdec(vdpr_curline)) fges vdpr_tmp1,##-1 wc if_nc fle vdpr_tmp1,#224 wc ' or perhaps 223 if_c jmp #vdpr_linelpThat's not where things would be tight") That's just the outer per-scanline loop
That's just the outer per-scanline loop
if_ae is just if_nc and if_b is just if_c. Good to have those memorized.
Ok yeah IDK where you critical parts are. Just looking for any general optimizations...
Here's a few more:
Initialize vdp_screenwidth as 32 in a long, and instead of this:
testb vdpr_flags,#VDPFLAG_H40 wc if_c mov vdpr_screenwidth,#40 if_nc mov vdpr_screenwidth,#32Do this:
testb vdpr_flags,#VDPFLAG_H40 wc bitc vdpr_screenwidth,#3Same thing for vdpr_tileline_mask with only one bit different, also vdpr_planewidth.
testb vdpc_flags,#VDPFLAG_SHADHL wc if_c mov vdpc_4prioIdxes_base, ##$20_20_20_20 ' Shad/HL mode if_nc mov vdpc_4prioIdxes_base, #0 ' Normal modecould use muxc to save a cycle above.
That's even less critical code. The critical stuff is
vdpr_renderPlane, the sprite stuff, aswell as the entire vdpc cog (unrolled madness down there)Just tried your last zipped code above but I can't get any image output. It has a black VGA output only. If I uncomment out this code below I can see some test stripes so I know the video is being generated by the video driver. I think when the vdpc_entry is spawned it is either just driving out black or otherwise crashing in my setup. Used 5.3.1 as well as 5.4.3 of flexspin. Monitor sees 640x480 VGA but black screen only if the last coginit call below is enabled. Not sure if the version you posted needs something else to make it work other than changing the A/V pins.
This is a pity as I wanted to test out some code that saves 6 instructions in your sprtloop which I think should help.
Update: got it working in PropTool instead.
Ok @Wuerfel_21, if you want some more cycles saved, instead of doing all this in your existing unrolled code
rdlong vdpr_tiledata,vdpr_tmp4 ' Prepare tilebuffer mov vdpr_tilebuffer1,vdpr_tile shr vdpr_tilebuffer1,#13 ' Just pal+priority shl vdpr_tilebuffer1,#4 movbyts vdpr_tilebuffer1,#%%0000 mov vdpr_tilebuffer2,vdpr_tilebuffer1 testb vdpr_tile,#11 wc ' mirror bit if_nc skipf hnormal_skipf if_c skipf hmirror_skipf ' Unrolled decode getnib vdpr_tmp1,vdpr_tiledata,#4 setnib vdpr_tilebuffer2,vdpr_tmp1,#6 ' normal setnib vdpr_tilebuffer1,vdpr_tmp1,#0 ' mirror getnib vdpr_tmp1,vdpr_tiledata,#5 setnib vdpr_tilebuffer2,vdpr_tmp1,#4 ' normal setnib vdpr_tilebuffer1,vdpr_tmp1,#2 ' mirror getnib vdpr_tmp1,vdpr_tiledata,#6 setnib vdpr_tilebuffer2,vdpr_tmp1,#2 ' normal setnib vdpr_tilebuffer1,vdpr_tmp1,#4 ' mirror getnib vdpr_tmp1,vdpr_tiledata,#7 setnib vdpr_tilebuffer2,vdpr_tmp1,#0 ' normal setnib vdpr_tilebuffer1,vdpr_tmp1,#6 ' mirror getnib vdpr_tmp1,vdpr_tiledata,#0 setnib vdpr_tilebuffer1,vdpr_tmp1,#6 ' normal setnib vdpr_tilebuffer2,vdpr_tmp1,#0 ' mirror getnib vdpr_tmp1,vdpr_tiledata,#1 setnib vdpr_tilebuffer1,vdpr_tmp1,#4 ' normal setnib vdpr_tilebuffer2,vdpr_tmp1,#2 ' mirror getnib vdpr_tmp1,vdpr_tiledata,#2 setnib vdpr_tilebuffer1,vdpr_tmp1,#2 ' normal setnib vdpr_tilebuffer2,vdpr_tmp1,#4 ' mirror getnib vdpr_tmp1,vdpr_tiledata,#3 setnib vdpr_tilebuffer1,vdpr_tmp1,#0 ' normal setnib vdpr_tilebuffer2,vdpr_tmp1,#6 ' mirror ' make transparent pixels go to zero test vdpr_tilebuffer1,vdpr_pixnibtest+0 wz if_z setbyte vdpr_tilebuffer1,#0,#0 test vdpr_tilebuffer1,vdpr_pixnibtest+1 wz if_z setbyte vdpr_tilebuffer1,#0,#1 test vdpr_tilebuffer1,vdpr_pixnibtest+2 wz if_z setbyte vdpr_tilebuffer1,#0,#2 test vdpr_tilebuffer1,vdpr_pixnibtest+3 wz if_z setbyte vdpr_tilebuffer1,#0,#3 test vdpr_tilebuffer2,vdpr_pixnibtest+0 wz if_z setbyte vdpr_tilebuffer2,#0,#0 test vdpr_tilebuffer2,vdpr_pixnibtest+1 wz if_z setbyte vdpr_tilebuffer2,#0,#1 test vdpr_tilebuffer2,vdpr_pixnibtest+2 wz if_z setbyte vdpr_tilebuffer2,#0,#2 test vdpr_tilebuffer2,vdpr_pixnibtest+3 wz if_z setbyte vdpr_tilebuffer2,#0,#3you can do this to save 6 instructions for each tile/sprite :
rdlong vdpr_tiledata,vdpr_tmp4 ' Prepare tilebuffer mov pa, vdpr_tile shr pa, #13 ' Just pal+priority shl pa, #4 testb vdpr_tile, #11 wc ' mirror if_nc splitb vdpr_tiledata ' reverse nibbles in tile if_nc rev vdpr_tiledata if_nc movbyts vdpr_tiledata, #%%0123 if_nc mergeb vdpr_tiledata getword vdpr_tilebuffer1, vdpr_tiledata, #1 ' first group movbyts vdpr_tilebuffer1, #%%3120 mergew vdpr_tilebuffer1 movbyts vdpr_tilebuffer1, #%%3120 splitw vdpr_tilebuffer1 getword vdpr_tilebuffer2, vdpr_tiledata, #0 ' second group movbyts vdpr_tilebuffer2, #%%3120 mergew vdpr_tilebuffer2 movbyts vdpr_tilebuffer2, #%%3120 splitw vdpr_tilebuffer2 ' make transparent pixels go to zero test vdpr_tilebuffer1,vdpr_pixnibtest+0 wz if_nz setnib vdpr_tilebuffer1,pa,#1 test vdpr_tilebuffer1,vdpr_pixnibtest+1 wz if_nz setnib vdpr_tilebuffer1,pa,#3 test vdpr_tilebuffer1,vdpr_pixnibtest+2 wz if_nz setnib vdpr_tilebuffer1,pa,#5 test vdpr_tilebuffer1,vdpr_pixnibtest+3 wz if_nz setnib vdpr_tilebuffer1,pa,#7 test vdpr_tilebuffer2,vdpr_pixnibtest+0 wz if_nz setnib vdpr_tilebuffer2,pa,#1 test vdpr_tilebuffer2,vdpr_pixnibtest+1 wz if_nz setnib vdpr_tilebuffer2,pa,#3 test vdpr_tilebuffer2,vdpr_pixnibtest+2 wz if_nz setnib vdpr_tilebuffer2,pa,#5 test vdpr_tilebuffer2,vdpr_pixnibtest+3 wz if_nz setnib vdpr_tilebuffer2,pa,#7It appears to still display tiles okay with this change but you might need to check its output carefully. I used "pa" as a temp variable, you might like it to be something else.
There's another similar unrolled loop in your vpdr_renderplane routine, which might be able to use the same technique to save about 4 instructions or so there too.
Update: yes it works there also and saves 3 instructions in that loop too. Just tried it. There might even be another shorter mergew/movbyts sequence that works better than what I stumbled upon, didn't dig further once I found one that worked.
Uhm, I think your code is giving sonic a pretty bad sunburn

Luckily, the solution is is simple, just remove the
shl pa,#4(also, I replaced the usage of pa withvdpr_tmp1), which was causing it to ignore sprite priority and palette. That's also another saved op in a hot loop!You see this? This is what my code does to flexspin.
Put
$20_20_20_20in a reg and use muxc to save four cycles.Have you tried MUXNIBS? It's in the instruction set specifically for VDP-style transparent pixels.
Yeah I wanted you to check it carefully as I'm not familiar with the regular colours to pick that up.
Good, I'm glad it is in loop that was tight that affects all tiles/sprites and you found yet another savings there too. Hopefully this frees up quite a bit with 40 tiles and 20 more sprites per line sharing the path. That's potentially 60x7 = 420 instructions, which is over a 2us per scan line @325MHz.
Yeah not sure why it fails on flexspin. It builds but doesn't run. Must be a difference somewhere, which is weird because it is mostly PASM2 code which should be identical. Perhaps it's memory layout related.
That's not how it works. On any line (in H40 mode), there are 2 planes of 40 or 41 tiles (the latter if scrolling partially through a tile). Then there can be up to 20 sprites, but each of them can be 1,2,3 or 4 tiles wide, though there is a limit of 40 sprite tiles total. So the plane tile loop actually runs up to 82 times and the sprite one up to 40 times.
Yeah done that. It's only per-line, but the compositor needs all the cycles it can, lol.
Only useful if you're actually drawing to a 4bpp buffer, whereas this is technically using 8bpp index buffers.
Here's all the optimizations integrated. I've also made vdpr_renderPlane use the FIFO to save some more cycles. The limiting factor is still the compositing. Good luck trying to understand what that code even does, lol.
Just tried to test on flexspin to see what is wrong and it doesn't even compile for me:
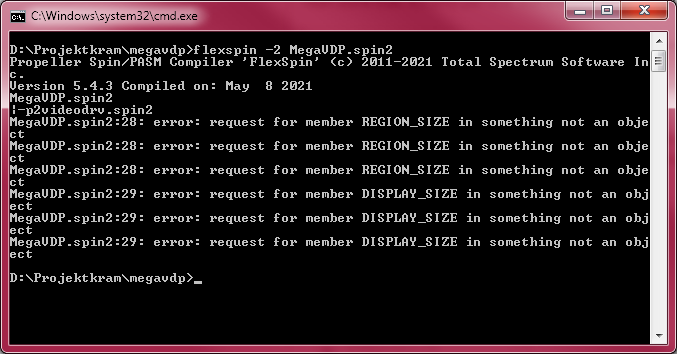
Reordering the OBJ above the VAR block makes it compile, but yes, black screen. However, the highlighted pixels from the Vectorman dump do show up, so it's probably the
updateCRAM32spin function that is gonked.Edit: no, for some reason the cog just loads zeroes regardless of what the cram32 array contains
Edit 2: no wait i'm stupid
Yeah I had to reorder the OBJ block too. That's due to some fairly recent change in Flexspin.
Gut feeling tells me it will probably be some type of addressing problem with how Flexspin lays out its memory vs PropTool and/or could be related to access of uninitialized data perhaps. I will be interested to hear what it is when you figure it out.
I figured it out, flexspin doesn't save its PTRA when going into inline ASM.
OMG, just reading through your compositor code figuring out what it is doing @Wuerfel_21 . That's one serious piece of code. Looks very optimized already. It would have taken quite a while to get that all figured out and working right.
Well done.
Yeah, as is, it's basically better than it needs to be (being that its load is mostly constant). It runs properly down to 302 MHz, whereas I think that around 325 is what the combined emulator should target. Could probably improve the OPN2 quality a bit, too, at that speed (improve EG and PSG update rates).
Then again, I'm thinking that having an additional plane for menus and such would be useful to have, and that code would go into the compositor.
Also, what do you think is the best method to affecting the video output based on register settings? (i.e. switch pixel clocks for H40 vs H32, set interlaced vs progressive on SDTV, make the screen bob on VGA to simulate interlace, etc)
Right now, to change the display resolution/timing or interlaced vs progressive SDTV I imagine you'll need something to trigger on whatever registers control this in your emulator to go and restart the video COG and give it the new startup parameters with the new PLL & display settings so it will make the necessary adjustments and output in the new manner. The interlaced mode output for a graphics region in VGA output mode will just source data from different frame buffers on alternate frames which may not help much in the end given your full screen sprite rendering is dynamic computed already and doesn't really rely on or use a static frame buffer in memory for its operation (unless you were planning to overlay some static regions perhaps as menus outside of gameplay or something).
Ah, so the timing and interlace flag can only be reloaded by restarting the video? Well, not too bad, because mode changes causes video glitches on HW, too.
I think the bobbing can be facilitated by messing with the "first rewrap" field before the next frame starts?
Wow, great work Wuerfel!
I wish I had this much time... Well I used to have that 10+ years ago when I made the PC Engine emulator and was single without kids. . The PC Engine emulator is still on my P2 ToDo list, but that list is quite big and I have got very little time for the P2 right now!
. The PC Engine emulator is still on my P2 ToDo list, but that list is quite big and I have got very little time for the P2 right now! 
@Wuerfel_21 , do you plan to add collision detection somewhere (in your VDPR component perhaps), and, if so, will that likely slow it down quite a bit? Did the Genesis/MD expect sprite collision to be handled by the main CPU only or was there some HW support for this? Hopefully adding any sprite collision detection would still remain below 325MHz...?
Update: if it is just basic non-zero pixel detection you might be able to do something like this, where a "collision" reg gets cleared at start of the sprite loop, and tested at the end to see if something collided (pa/pb are just used as temp regs in sample below). It might only add 16-23 clocks to the sprite loop, some of which were thankfully reclaimed by my earlier suggested optimization. You might even be able to position this code somewhere convenient in the overall loop to take advantage of the fixed hub cycle latency, given that you would be writing to the same address pair in hub memory soon after the read using that wmlong instruction. That might bring down the cycle overhead of the rdlong from its worst case number.
```
' Figure out where to draw mov vdpr_tmp1,ptra add vdpr_tmp1,vdpr_sprHpos setq #1 ' NEW CODE - read 2 longs for 8 pixels of sprite tile already at this address rdlong pa, vdpr_tmp1 ' NEW CODE or collision, pa ' NEW CODE or collision, pb ' NEW CODE setq #1 wmlong vdpr_tilebuffer1,vdpr_tmp1```
There is a simple hardware collision flag just like that, but apparently almost nothing uses it because it's basically pointless (it really just says "any two sprites collided"). Probably not worth it.
Sprites are superimposed onto background and won't your code detect collisions between sprites and background as well as sprite-sprite collisions?
No because the sprites are written to different a HUB RAM scan line pixel buffer to those used by the background tiles (A/B) before going to the compositor COG. The buffer is cleared before the sprites are drawn. The compositor COG then merges the A, B and S layers together taking account of the priority and background colour (at least that is how I understand it working, but I didn't write it so I might have missed some key parts there).
Thanks for the info. Reading data from a sprite-only buffer before writing to the same address is a good way of detecting sprite collision, however I don't see how OR in your code can work. If corresponding old and new bytes are both non-zero then collision has occurred, however TEST will not detect this all the time unless the same bit in both is always set. It would help to know what the sprite data bytes consist of.