@evanh said:
... And funny thing is, on reads I'm seeing all zeros when clocking beyond 1024 bytes. It seems the APS6404L's internal state machine just stops fetching/sending after one page until a new command is issued.
I've solved why I was fooled with this. Turns out my Spin code for buffer filling/checking had a bug. The first longword was always z zero. So the start of the next page always contained eight zero nibbles from prior block writes containing those leading zeros.
PRI randfill( dest, size )
repeat size>>2
long[dest += 4] := getrnd()
PRI compare( src1, src2, size ) : good
good := 0
repeat size>>2
if long[src1 += 4] == long[src2 += 4]
good += 4
As I understood them, all the last five LA screenshots (three from post #419, and two from post #456) are showing only write operations at different CLK dutyratescycles leading edge-positionings (as related to the start of corresponding data bit cycle); there's none that shows are there any showing a read operation?
That's interesting: After empirically thrashing out all the timing maths I've found one distinct feature. The numbers centre around the first clock edge. Of course that sounds a little duh-of-course but that fact means it results in a more difficult equation for SPI clock mode 0 (CPOL=0,CPHA=0) compared to mode 3 (CPOL=1,CPHA=1) because the first data bit then has a computed negative offset to the first clock.
I'd fortuitously started with SPI mode 3 and only just now had to build this little monster: CLKDATPHASE = CLK_REGD - DAT_REGD - (1 ^ SPI_CLKMODE3) & CLK_DIV - (1 ^ SPI_CLKMODE3) * CLK_DIV>>1
As I understood them, all the last five LA screenshots (three from post #419, and two from post #456) are showing only write operations at different CLK dutyratescycles leading edge-positionings (as related to the start of corresponding data bit cycle); there's none that shows are there any showing a read operation?
Nope, there are none of those. This was not even attached to real PSRAM, but just intended for me to align clock timing with data in the address phase and for all writes.
Ha! Check this one out: M_NCO = $8000_0000 +/ CLK_DIV + ($8000_0000 +// CLK_DIV > 0 ? 1 : 0) ' round up
PS: Always rounding up of that value eliminates all the +1 sysclocks that appear on the first streamer period between first and second data transfer. It occurs with clock dividers of 3, 5, 6, 7, 9 and so on. The 6 case can be confusing because it's the only even divider, of the low divider values at least.
Improving this equation now allows arbitrary divider choice. Limited only by related offsets like the SPI clock mode0 cutting into the timing slack between issued streamer ops and the clock starting DIRH.
To make that particular slack a little bigger I've moved a couple of the earlier instructions (CE and DATA activation) in between:
xinit ##M_LEADIN, #0 ' lead-in timing, at sysclock/1
setq ##M_NCO ' streamer transfer rate
xcont ##M_CA4, paddr ' tx Command and Address (byte granular address)
drvl #PSRAM_DATA_PINS ' active for tx CA phase
drvl #PSRAM_CE_PIN
dirh #PSRAM_CLK_PIN ' start SPI clock pulses, PWM smartpin
Nice! This morning I've refined the above a little better. It's getting real clean now. I've now moved the (1 ^ SPI_CLKMODE3) & CLK_DIV out from the tx/rx routines and placed it in the init() routine only. I'd missed inverting of the PWM duty to fit the inverted logic polarity, and this calculation is exactly right for that inversion.
wxpin( PSRAM_CLK_PIN, 1 | CLK_DIV<<16 ) ' set PWM period
wypin( PSRAM_CLK_PIN, CLK_DIV>>1 + (1 ^ SPI_CLKMODE3) & CLK_DIV ) ' set PWM duty
If/when you do an 8 or 16 bit version of a sample PSRAM write function from SPIN2, you will find you have to use the LUT RAM (with 16 longs aligned on 32 long boundary). I wonder if there is any common LUTRAM address block of at least this size available from SPIN2 in both Flex and Pnut/PropTool?
Huh, with all that worked out, even using the Pulse mode smartpin for clock gen is working cleanly now. I've reverted back to that and got rid of the PWM smartpin mode.
An unexpected bit of luck helped. Turns out it's easy to ensure only one period of the smartpin's internal period timer occurs before pulse output starts. Just have to place the DIRH right in front of the WYPIN:
dirh #PSRAM_CLK_PIN ' start SPI clock pulses
wypin len, #PSRAM_CLK_PIN ' QPI clocks for CA phase and data phase
This allows for easy extension to the calculation of the clock-data phase relationship. Simply add one SPI clock period: CLKDATPHASE = CLK_REGD - DAT_REGD + CLK_DIV - (1 ^ SPI_CLKMODE3) * CLK_DIV>>1
@rogloh said:
If/when you do an 8 or 16 bit version of a sample PSRAM write function from SPIN2, you will find you have to use the LUT RAM (with 16 longs aligned on 32 long boundary). I wonder if there is any common LUTRAM address block of at least this size available from SPIN2 in both Flex and Pnut/PropTool?
Eric leaves the first half of lutRAM free I believe. Chip has a small amount free at the start too ... ah it's changed a little over time - Currently 16 longwords are free at start of lutRAM.
'***************************
'* Interpreter - cog LUT *
'***************************
'
org $210 'leave $20x open for 16 streamer imm->LUT->DAC/pin values
lut_code
@rogloh said:
If/when you do an 8 or 16 bit version of a sample PSRAM write function from SPIN2, you will find you have to use the LUT RAM (with 16 longs aligned on 32 long boundary). I wonder if there is any common LUTRAM address block of at least this size available from SPIN2 in both Flex and Pnut/PropTool?
Eric leaves the bottom half of lutRAM free I believe. Chip has a small amount free at the bottom too ...
Are you sure? Okay, I read this in the flexspin doc:
The question will be how to (safely) use a specific portion of it.
COG
Most of COG RAM is used by the compiler, except that $1e0-$1ef is left free for application use.
LUT
The first part of LUT memory (from $200 to $300) is used for any functions explicitly placed into LUT. The LUT memory from $300 to $400 (the second half of LUT) is used for internal purposes.
The first part of LUT memory (from $200 to $300) is used for any functions explicitly placed into LUT. The LUT memory from $300 to $400 (the second half of LUT) is used for internal purposes.
"... any functions explicitly placed into LUT" to me means user defined, ie: whatever you want.
Fcache uses start of cogRAM. There is actually a large space there.
The small cogRAM range listed ($1e0-$1ef) will be good for persistent register storage. I must give that a try ...
ah it's changed a little over time - Currently 16 longwords are free at start of lutRAM.
'***************************
'* Interpreter - cog LUT *
'***************************
'
org $210 'leave $20x open for 16 streamer imm->LUT->DAC/pin values
lut_code
That is (just) enough.
From reading Eric's flexspin docs it looks like if you don't specifically enable it then it won't put methods into LUT so in theory it should be free. It would be nice if he added a compiler switch to reserve some amount LUT RAM memory free before he uses it for this purpose.
Maybe it's faster to simply load up the LUT directly from a pre-configured table in HUBRAM instead of generating the pattern each time. However if the LUT data table persists it's moot.
As for the WRLUT operation, can't you use a PTR with autoincrement, and toss one instruction from your REP-loop?
P.S. my eyes are really messing me up; I couldn't read the last part of top line, which says just that....
Crossing page boundaries is crappy with these chips. I'm getting errors as low as 70 MHz SPI clock when doing larger than 1024 byte bursts. Smaller length page crossings can actually achieve 133 MHz, just. Whereas staying within a page works right up to Prop2's limits, ~200 MHz SPI clock when chilled. Definitely a good rule to split them up.
@evanh said:
Crossing page boundaries is crappy with these chips. I'm getting errors as low as 70 MHz SPI clock when doing larger than 1024 byte bursts. Smaller length page crossings can actually achieve 133 MHz, just. Whereas staying within a page works right up to Prop2's limits, ~200 MHz SPI clock when chilled. Definitely a good rule to split them up.
Are you using PSRam_CLK = P2_Sysclk/4, or other divider nearby (5,6)?
Here's as high as the EC32MB will go before the egg beater (hubRAM) crashes the program without chilled cooling. As you can see, the PSRAM is still going strong at 370 MHz sysclock (185 MHz SPI clock).
And Rayman's 96 MB add-on he donated to me, plugged into an Eval Board. The Eval Board has larger heat-sinking so can run a little faster before crashing, so it reaches 390 MHz sysclock (195 MHz SPI clock). Of note there is it begins achieving 100% scores at the very end.
Ha, I see a small typo in the reports. It's no longer 400 x blocksize tested, it's only 100 x blocksize now. I lowered it so Pnut compiled programs didn't take too long. That's something else to improve - Make the randfill() and compare() routines faster.
Here's as high as the EC32MB will go before the egg beater (hubRAM) crashes the program without chilled cooling. As you can see, the PSRAM is still going strong at 370 MHz sysclock (185 MHz SPI clock).
```
Chip ID is: 0d 5d 52 d5 b5 57 25 8b usb-Parallax_Inc_PropPlug_P7ehkogg-if00-port0
DATA_PINS = 232 CE_PIN = 57 CLK_PIN = 56
SPI cmode=3 CLK_REGD = 1 TX_REGD = 1 RX_REGD = 1
SPI clock ratio: 2 (sysclock/2)
Test data length: 400 x 1024 = 409600 bytes
If I'm understanding it right, all of DATA_PINS, CE_PIN and CLK_PINs are being used with their registered-functionalities activated. Is this true?


Comments
Slower? I doubt it. Sysclock/4 is solidly reliable. Though, I must admit I have considered exploring bigger dividers just to test the my coded maths.
Yep. ORG/END always places the code in cogRAM. So not actually inline at all.
8 uS / 5.5555555...nS = 1440 nibbles during 8uS @180MHz (Sysclk = 360MHz)...
I've solved why I was fooled with this. Turns out my Spin code for buffer filling/checking had a bug. The first longword was always z zero. So the start of the next page always contained eight zero nibbles from prior block writes containing those leading zeros.
PRI randfill( dest, size ) repeat size>>2 long[dest += 4] := getrnd() PRI compare( src1, src2, size ) : good good := 0 repeat size>>2 if long[src1 += 4] == long[src2 += 4] good += 4Yay! My code compiles in Pnut.") Boy, it runs slower though, might have to reduce the amount of RAM tested.
Boy, it runs slower though, might have to reduce the amount of RAM tested.
Sysclk/5 also works with my code and the rising edge is 3/5 into the bit... Surely no slower is needed.
Surely no slower is needed.
Technically sysclk/6 also works but it's nasty. I wouldn't use it. The clock edge is 5/6 into the bit.
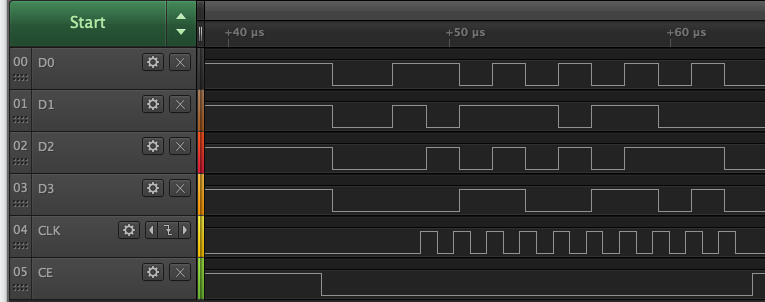
I can place the clock edge in any position ... ah, that's a configurable feature I should add in fact ...
Hi @rogloh
As I understood them, all the last five LA screenshots (three from post #419, and two from post #456) are showing only write operations at different CLK duty rates cycles leading edge-positionings (as related to the start of corresponding data bit cycle); there's none that shows are there any showing a read operation?
That's interesting: After empirically thrashing out all the timing maths I've found one distinct feature. The numbers centre around the first clock edge. Of course that sounds a little duh-of-course but that fact means it results in a more difficult equation for SPI clock mode 0 (CPOL=0,CPHA=0) compared to mode 3 (CPOL=1,CPHA=1) because the first data bit then has a computed negative offset to the first clock.
I'd fortuitously started with SPI mode 3 and only just now had to build this little monster:
CLKDATPHASE = CLK_REGD - DAT_REGD - (1 ^ SPI_CLKMODE3) & CLK_DIV - (1 ^ SPI_CLKMODE3) * CLK_DIV>>1Nope, there are none of those. This was not even attached to real PSRAM, but just intended for me to align clock timing with data in the address phase and for all writes.
Ha! Check this one out:
M_NCO = $8000_0000 +/ CLK_DIV + ($8000_0000 +// CLK_DIV > 0 ? 1 : 0) ' round upPS: Always rounding up of that value eliminates all the +1 sysclocks that appear on the first streamer period between first and second data transfer. It occurs with clock dividers of 3, 5, 6, 7, 9 and so on. The 6 case can be confusing because it's the only even divider, of the low divider values at least.
Improving this equation now allows arbitrary divider choice. Limited only by related offsets like the SPI clock mode0 cutting into the timing slack between issued streamer ops and the clock starting DIRH.
To make that particular slack a little bigger I've moved a couple of the earlier instructions (CE and DATA activation) in between:
xinit ##M_LEADIN, #0 ' lead-in timing, at sysclock/1 setq ##M_NCO ' streamer transfer rate xcont ##M_CA4, paddr ' tx Command and Address (byte granular address) drvl #PSRAM_DATA_PINS ' active for tx CA phase drvl #PSRAM_CE_PIN dirh #PSRAM_CLK_PIN ' start SPI clock pulses, PWM smartpinNice! This morning I've refined the above a little better. It's getting real clean now. I've now moved the
(1 ^ SPI_CLKMODE3) & CLK_DIVout from the tx/rx routines and placed it in the init() routine only. I'd missed inverting of the PWM duty to fit the inverted logic polarity, and this calculation is exactly right for that inversion.wxpin( PSRAM_CLK_PIN, 1 | CLK_DIV<<16 ) ' set PWM period wypin( PSRAM_CLK_PIN, CLK_DIV>>1 + (1 ^ SPI_CLKMODE3) & CLK_DIV ) ' set PWM dutyIf/when you do an 8 or 16 bit version of a sample PSRAM write function from SPIN2, you will find you have to use the LUT RAM (with 16 longs aligned on 32 long boundary). I wonder if there is any common LUTRAM address block of at least this size available from SPIN2 in both Flex and Pnut/PropTool?
Huh, with all that worked out, even using the Pulse mode smartpin for clock gen is working cleanly now. I've reverted back to that and got rid of the PWM smartpin mode.
An unexpected bit of luck helped. Turns out it's easy to ensure only one period of the smartpin's internal period timer occurs before pulse output starts. Just have to place the DIRH right in front of the WYPIN:
dirh #PSRAM_CLK_PIN ' start SPI clock pulses wypin len, #PSRAM_CLK_PIN ' QPI clocks for CA phase and data phaseThis allows for easy extension to the calculation of the clock-data phase relationship. Simply add one SPI clock period:
CLKDATPHASE = CLK_REGD - DAT_REGD + CLK_DIV - (1 ^ SPI_CLKMODE3) * CLK_DIV>>1Eric leaves the first half of lutRAM free I believe. Chip has a small amount free at the start too ... ah it's changed a little over time - Currently 16 longwords are free at start of lutRAM.
'*************************** '* Interpreter - cog LUT * '*************************** ' org $210 'leave $20x open for 16 streamer imm->LUT->DAC/pin values lut_codeAre you sure? Okay, I read this in the flexspin doc:
The question will be how to (safely) use a specific portion of it.
COG
Most of COG RAM is used by the compiler, except that $1e0-$1ef is left free for application use.
LUT
The first part of LUT memory (from $200 to $300) is used for any functions explicitly placed into LUT. The LUT memory from $300 to $400 (the second half of LUT) is used for internal purposes.
"... any functions explicitly placed into LUT" to me means user defined, ie: whatever you want.
Fcache uses start of cogRAM. There is actually a large space there.
The small cogRAM range listed ($1e0-$1ef) will be good for persistent register storage. I must give that a try ...
ah it's changed a little over time - Currently 16 longwords are free at start of lutRAM.
That is (just) enough.
From reading Eric's flexspin docs it looks like if you don't specifically enable it then it won't put methods into LUT so in theory it should be free. It would be nice if he added a compiler switch to reserve some amount LUT RAM memory free before he uses it for this purpose.
We just need this loop to set up the table in LUTRAM. Or use an auto-incrementing ptr if it is free.
Ah, I know what flexspin needs: The PR0..PR7 symbols. Maybe even assign them to those $1e0 locations.
Maybe it's faster to simply load up the LUT directly from a pre-configured table in HUBRAM instead of generating the pattern each time. However if the LUT data table persists it's moot.
As for the WRLUT operation, can't you use a PTR with autoincrement, and toss one instruction from your REP-loop?
P.S. my eyes are really messing me up; I couldn't read the last part of top line, which says just that....
Crossing page boundaries is crappy with these chips. I'm getting errors as low as 70 MHz SPI clock when doing larger than 1024 byte bursts. Smaller length page crossings can actually achieve 133 MHz, just. Whereas staying within a page works right up to Prop2's limits, ~200 MHz SPI clock when chilled. Definitely a good rule to split them up.
Are you using PSRam_CLK = P2_Sysclk/4, or other divider nearby (5,6)?
sysclock/2 in those tests. Can't get 200 MHz SPI without that.
Are you clocking the plain QSPI-APS6404L-3SQR up to this rate, or are you talking about the Xccela OPI-ones?
Just the plain ones.
Here's as high as the EC32MB will go before the egg beater (hubRAM) crashes the program without chilled cooling. As you can see, the PSRAM is still going strong at 370 MHz sysclock (185 MHz SPI clock).
Chip ID is: 0d 5d 52 d5 b5 57 25 8b usb-Parallax_Inc_PropPlug_P7ehkogg-if00-port0 DATA_PINS = 232 CE_PIN = 57 CLK_PIN = 56 SPI cmode=3 CLK_REGD = 1 TX_REGD = 1 RX_REGD = 1 SPI clock ratio: 2 (sysclock/2) Test data length: 400 x 1024 = 409600 bytes Frequency dependent lag compensation 0 1 2 3 4 5 60 MHz 100% 100% 0% 0% 0% 0% 62 MHz 100% 100% 0% 0% 0% 0% 64 MHz 100% 100% 0% 0% 0% 0% 66 MHz 100% 100% 0% 0% 0% 0% 68 MHz 100% 100% 0% 0% 0% 0% 70 MHz 100% 100% 0% 0% 0% 0% 72 MHz 100% 100% 0% 0% 0% 0% 74 MHz 100% 100% 0% 0% 0% 0% 76 MHz 100% 100% 0% 0% 0% 0% 78 MHz 100% 100% 0% 0% 0% 0% 80 MHz 100% 100% 0% 0% 0% 0% 82 MHz 100% 100% 0% 0% 0% 0% 84 MHz 100% 100% 0% 0% 0% 0% 86 MHz 100% 100% 0% 0% 0% 0% 88 MHz 100% 100% 0% 0% 0% 0% 90 MHz 100% 100% 0% 0% 0% 0% 92 MHz 100% 100% 0% 0% 0% 0% 94 MHz 100% 100% 0% 0% 0% 0% 96 MHz 100% 100% 0% 0% 0% 0% 98 MHz 100% 100% 0% 0% 0% 0% 100 MHz 100% 100% 0% 0% 0% 0% 102 MHz 100% 100% 0% 0% 0% 0% 104 MHz 100% 100% 0% 0% 0% 0% 106 MHz 100% 100% 0% 0% 0% 0% 108 MHz 100% 100% 0% 0% 0% 0% 110 MHz 100% 100% 0% 0% 0% 0% 112 MHz 100% 100% 0% 0% 0% 0% 114 MHz 100% 100% 0% 0% 0% 0% 116 MHz 100% 100% 0% 0% 0% 0% 118 MHz 100% 100% 0% 0% 0% 0% 120 MHz 100% 100% 0% 0% 0% 0% 122 MHz 100% 100% 0% 0% 0% 0% 124 MHz 100% 100% 0% 0% 0% 0% 126 MHz 100% 100% 0% 0% 0% 0% 128 MHz 100% 100% 0% 0% 0% 0% 130 MHz 100% 100% 0% 0% 0% 0% 132 MHz 100% 100% 0% 0% 0% 0% 134 MHz 100% 100% 0% 0% 0% 0% 136 MHz 99% 100% 0% 0% 0% 0% 138 MHz 95% 100% 0% 0% 0% 0% 140 MHz 60% 100% 0% 0% 0% 0% 142 MHz 10% 100% 0% 0% 0% 0% 144 MHz 0% 100% 0% 0% 0% 0% 146 MHz 0% 100% 0% 0% 0% 0% 148 MHz 0% 100% 0% 0% 0% 0% 150 MHz 0% 100% 0% 0% 0% 0% 152 MHz 0% 100% 0% 0% 0% 0% 154 MHz 0% 100% 11% 0% 0% 0% 156 MHz 0% 100% 93% 0% 0% 0% 158 MHz 0% 100% 100% 0% 0% 0% 160 MHz 0% 100% 100% 0% 0% 0% 162 MHz 0% 100% 100% 0% 0% 0% 164 MHz 0% 100% 100% 0% 0% 0% 166 MHz 0% 100% 100% 0% 0% 0% 168 MHz 0% 100% 100% 0% 0% 0% 170 MHz 0% 100% 100% 0% 0% 0% 172 MHz 0% 100% 100% 0% 0% 0% 174 MHz 0% 100% 100% 0% 0% 0% 176 MHz 0% 100% 100% 0% 0% 0% 178 MHz 0% 100% 100% 0% 0% 0% 180 MHz 0% 100% 100% 0% 0% 0% 182 MHz 0% 100% 100% 0% 0% 0% 184 MHz 0% 100% 100% 0% 0% 0% 186 MHz 0% 100% 100% 0% 0% 0% 188 MHz 0% 100% 100% 0% 0% 0% 190 MHz 0% 100% 100% 0% 0% 0% 192 MHz 0% 100% 100% 0% 0% 0% 194 MHz 0% 100% 100% 0% 0% 0% 196 MHz 0% 100% 100% 0% 0% 0% 198 MHz 0% 100% 100% 0% 0% 0% 200 MHz 0% 100% 100% 0% 0% 0% 202 MHz 0% 100% 100% 0% 0% 0% 204 MHz 0% 100% 100% 0% 0% 0% 206 MHz 0% 100% 100% 0% 0% 0% 208 MHz 0% 100% 100% 0% 0% 0% 210 MHz 0% 100% 100% 0% 0% 0% 212 MHz 0% 100% 100% 0% 0% 0% 214 MHz 0% 100% 100% 0% 0% 0% 216 MHz 0% 100% 100% 0% 0% 0% 218 MHz 0% 100% 100% 0% 0% 0% 220 MHz 0% 100% 100% 0% 0% 0% 222 MHz 0% 100% 100% 0% 0% 0% 224 MHz 0% 100% 100% 0% 0% 0% 226 MHz 0% 100% 100% 0% 0% 0% 228 MHz 0% 100% 100% 0% 0% 0% 230 MHz 0% 100% 100% 0% 0% 0% 232 MHz 0% 100% 100% 0% 0% 0% 234 MHz 0% 100% 100% 0% 0% 0% 236 MHz 0% 100% 100% 0% 0% 0% 238 MHz 0% 100% 100% 0% 0% 0% 240 MHz 0% 100% 100% 0% 0% 0% 242 MHz 0% 100% 100% 0% 0% 0% 244 MHz 0% 100% 100% 0% 0% 0% 246 MHz 0% 100% 100% 0% 0% 0% 248 MHz 0% 100% 100% 0% 0% 0% 250 MHz 0% 100% 100% 0% 0% 0% 252 MHz 0% 100% 100% 0% 0% 0% 254 MHz 0% 100% 100% 0% 0% 0% 256 MHz 0% 100% 100% 0% 0% 0% 258 MHz 0% 100% 100% 0% 0% 0% 260 MHz 0% 100% 100% 0% 0% 0% 262 MHz 0% 100% 100% 0% 0% 0% 264 MHz 0% 100% 100% 0% 0% 0% 266 MHz 0% 100% 100% 0% 0% 0% 268 MHz 0% 99% 100% 0% 0% 0% 270 MHz 0% 99% 100% 0% 0% 0% 272 MHz 0% 99% 100% 0% 0% 0% 274 MHz 0% 98% 100% 0% 0% 0% 276 MHz 0% 91% 100% 0% 0% 0% 278 MHz 0% 68% 100% 0% 0% 0% 280 MHz 0% 30% 100% 0% 0% 0% 282 MHz 0% 10% 100% 0% 0% 0% 284 MHz 0% 3% 100% 0% 0% 0% 286 MHz 0% 0% 100% 0% 0% 0% 288 MHz 0% 0% 100% 0% 0% 0% 290 MHz 0% 0% 100% 0% 0% 0% 292 MHz 0% 0% 100% 0% 0% 0% 294 MHz 0% 0% 100% 0% 0% 0% 296 MHz 0% 0% 100% 0% 0% 0% 298 MHz 0% 0% 100% 0% 0% 0% 300 MHz 0% 0% 100% 0% 0% 0% 302 MHz 0% 0% 100% 0% 0% 0% 304 MHz 0% 0% 100% 13% 0% 0% 306 MHz 0% 0% 100% 63% 0% 0% 308 MHz 0% 0% 100% 99% 0% 0% 310 MHz 0% 0% 100% 100% 0% 0% 312 MHz 0% 0% 100% 100% 0% 0% 314 MHz 0% 0% 100% 100% 0% 0% 316 MHz 0% 0% 100% 100% 0% 0% 318 MHz 0% 0% 100% 100% 0% 0% 320 MHz 0% 0% 100% 100% 0% 0% 322 MHz 0% 0% 100% 100% 0% 0% 324 MHz 0% 0% 100% 100% 0% 0% 326 MHz 0% 0% 100% 100% 0% 0% 328 MHz 0% 0% 100% 100% 0% 0% 330 MHz 0% 0% 100% 100% 0% 0% 332 MHz 0% 0% 100% 100% 0% 0% 334 MHz 0% 0% 100% 100% 0% 0% 336 MHz 0% 0% 100% 100% 0% 0% 338 MHz 0% 0% 100% 100% 0% 0% 340 MHz 0% 0% 100% 100% 0% 0% 342 MHz 0% 0% 100% 100% 0% 0% 344 MHz 0% 0% 100% 100% 0% 0% 346 MHz 0% 0% 100% 100% 0% 0% 348 MHz 0% 0% 100% 100% 0% 0% 350 MHz 0% 0% 100% 100% 0% 0% 352 MHz 0% 0% 100% 100% 0% 0% 354 MHz 0% 0% 100% 100% 0% 0% 356 MHz 0% 0% 99% 100% 0% 0% 358 MHz 0% 0% 99% 100% 0% 0% 360 MHz 0% 0% 70% 100% 0% 0% 362 MHz 0% 0% 1% 100% 0% 0% 364 MHz 0% 0% 0% 100% 0% 0% 366 MHz 0% 0% 0% 100% 3% 0% 368 MHz 0% 0% 0% 100% 48% 0% 370 MHz 0% 0% 0% 100% 98% 0% DoneAnd Rayman's 96 MB add-on he donated to me, plugged into an Eval Board. The Eval Board has larger heat-sinking so can run a little faster before crashing, so it reaches 390 MHz sysclock (195 MHz SPI clock). Of note there is it begins achieving 100% scores at the very end.")
Chip ID is: 0d 5d 52 f6 08 37 ca 46 usb-Parallax_Inc_Propeller_P2-ES_EVAL_P23YOO42-if00-port0 DATA_PINS = 224 CE_PIN = 43 CLK_PIN = 40 SPI cmode=3 CLK_REGD = 1 TX_REGD = 1 RX_REGD = 1 SPI clock ratio: 2 (sysclock/2) Test data length: 400 x 1024 = 409600 bytes Frequency dependent lag compensation 0 1 2 3 4 5 60 MHz 100% 100% 0% 0% 0% 0% 62 MHz 100% 100% 0% 0% 0% 0% 64 MHz 100% 100% 0% 0% 0% 0% 66 MHz 100% 100% 0% 0% 0% 0% 68 MHz 100% 100% 0% 0% 0% 0% 70 MHz 100% 100% 0% 0% 0% 0% 72 MHz 100% 100% 0% 0% 0% 0% 74 MHz 100% 100% 0% 0% 0% 0% 76 MHz 100% 100% 0% 0% 0% 0% 78 MHz 100% 100% 0% 0% 0% 0% 80 MHz 99% 100% 0% 0% 0% 0% 82 MHz 98% 100% 0% 0% 0% 0% 84 MHz 90% 100% 0% 0% 0% 0% 86 MHz 76% 100% 0% 0% 0% 0% 88 MHz 58% 100% 0% 0% 0% 0% 90 MHz 55% 100% 0% 0% 0% 0% 92 MHz 56% 100% 0% 0% 0% 0% 94 MHz 57% 100% 0% 0% 0% 0% 96 MHz 57% 100% 0% 0% 0% 0% 98 MHz 56% 100% 0% 0% 0% 0% 100 MHz 55% 100% 0% 0% 0% 0% 102 MHz 51% 100% 0% 0% 0% 0% 104 MHz 41% 100% 0% 0% 0% 0% 106 MHz 13% 100% 0% 0% 0% 0% 108 MHz 0% 100% 0% 0% 0% 0% 110 MHz 0% 100% 0% 0% 0% 0% 112 MHz 0% 100% 0% 0% 0% 0% 114 MHz 0% 100% 0% 0% 0% 0% 116 MHz 0% 100% 3% 0% 0% 0% 118 MHz 0% 100% 32% 0% 0% 0% 120 MHz 0% 100% 90% 0% 0% 0% 122 MHz 0% 100% 100% 0% 0% 0% 124 MHz 0% 100% 100% 0% 0% 0% 126 MHz 0% 100% 100% 0% 0% 0% 128 MHz 0% 100% 100% 0% 0% 0% 130 MHz 0% 100% 100% 0% 0% 0% 132 MHz 0% 100% 100% 0% 0% 0% 134 MHz 0% 100% 100% 0% 0% 0% 136 MHz 0% 100% 100% 0% 0% 0% 138 MHz 0% 100% 100% 0% 0% 0% 140 MHz 0% 100% 100% 0% 0% 0% 142 MHz 0% 100% 100% 0% 0% 0% 144 MHz 0% 100% 100% 0% 0% 0% 146 MHz 0% 100% 100% 0% 0% 0% 148 MHz 0% 100% 100% 0% 0% 0% 150 MHz 0% 100% 100% 0% 0% 0% 152 MHz 0% 100% 100% 0% 0% 0% 154 MHz 0% 100% 100% 0% 0% 0% 156 MHz 0% 100% 100% 0% 0% 0% 158 MHz 0% 100% 100% 0% 0% 0% 160 MHz 0% 99% 100% 0% 0% 0% 162 MHz 0% 99% 100% 0% 0% 0% 164 MHz 0% 94% 100% 0% 0% 0% 166 MHz 0% 91% 100% 0% 0% 0% 168 MHz 0% 87% 100% 0% 0% 0% 170 MHz 0% 78% 100% 0% 0% 0% 172 MHz 0% 63% 100% 0% 0% 0% 174 MHz 0% 55% 100% 0% 0% 0% 176 MHz 0% 50% 100% 0% 0% 0% 178 MHz 0% 42% 100% 0% 0% 0% 180 MHz 0% 39% 100% 0% 0% 0% 182 MHz 0% 38% 100% 0% 0% 0% 184 MHz 0% 38% 100% 0% 0% 0% 186 MHz 0% 38% 100% 0% 0% 0% 188 MHz 0% 38% 100% 0% 0% 0% 190 MHz 0% 37% 100% 0% 0% 0% 192 MHz 0% 36% 100% 0% 0% 0% 194 MHz 0% 34% 100% 0% 0% 0% 196 MHz 0% 33% 100% 0% 0% 0% 198 MHz 0% 30% 100% 0% 0% 0% 200 MHz 0% 28% 100% 0% 0% 0% 202 MHz 0% 25% 100% 0% 0% 0% 204 MHz 0% 20% 100% 0% 0% 0% 206 MHz 0% 15% 100% 0% 0% 0% 208 MHz 0% 9% 100% 0% 0% 0% 210 MHz 0% 5% 100% 0% 0% 0% 212 MHz 0% 2% 100% 0% 0% 0% 214 MHz 0% 0% 100% 0% 0% 0% 216 MHz 0% 0% 100% 0% 0% 0% 218 MHz 0% 0% 100% 0% 0% 0% 220 MHz 0% 0% 100% 0% 0% 0% 222 MHz 0% 0% 100% 0% 0% 0% 224 MHz 0% 0% 100% 0% 0% 0% 226 MHz 0% 0% 100% 0% 0% 0% 228 MHz 0% 0% 100% 0% 0% 0% 230 MHz 0% 0% 100% 0% 0% 0% 232 MHz 0% 0% 100% 3% 0% 0% 234 MHz 0% 0% 100% 12% 0% 0% 236 MHz 0% 0% 100% 34% 0% 0% 238 MHz 0% 0% 99% 63% 0% 0% 240 MHz 0% 0% 99% 89% 0% 0% 242 MHz 0% 0% 99% 98% 0% 0% 244 MHz 0% 0% 97% 99% 0% 0% 246 MHz 0% 0% 95% 100% 0% 0% 248 MHz 0% 0% 92% 100% 0% 0% 250 MHz 0% 0% 87% 100% 0% 0% 252 MHz 0% 0% 81% 100% 0% 0% 254 MHz 0% 0% 73% 100% 0% 0% 256 MHz 0% 0% 64% 100% 0% 0% 258 MHz 0% 0% 55% 100% 0% 0% 260 MHz 0% 0% 48% 100% 0% 0% 262 MHz 0% 0% 42% 100% 0% 0% 264 MHz 0% 0% 40% 100% 0% 0% 266 MHz 0% 0% 39% 100% 0% 0% 268 MHz 0% 0% 40% 100% 0% 0% 270 MHz 0% 0% 41% 100% 0% 0% 272 MHz 0% 0% 41% 100% 0% 0% 274 MHz 0% 0% 42% 100% 0% 0% 276 MHz 0% 0% 44% 100% 0% 0% 278 MHz 0% 0% 45% 100% 0% 0% 280 MHz 0% 0% 47% 100% 0% 0% 282 MHz 0% 0% 48% 100% 0% 0% 284 MHz 0% 0% 49% 100% 0% 0% 286 MHz 0% 0% 50% 100% 0% 0% 288 MHz 0% 0% 51% 100% 0% 0% 290 MHz 0% 0% 53% 100% 0% 0% 292 MHz 0% 0% 53% 100% 0% 0% 294 MHz 0% 0% 55% 100% 0% 0% 296 MHz 0% 0% 56% 100% 0% 0% 298 MHz 0% 0% 58% 100% 0% 0% 300 MHz 0% 0% 60% 100% 0% 0% 302 MHz 0% 0% 61% 100% 0% 0% 304 MHz 0% 0% 61% 100% 0% 0% 306 MHz 0% 0% 60% 100% 0% 0% 308 MHz 0% 0% 58% 100% 0% 0% 310 MHz 0% 0% 52% 100% 0% 0% 312 MHz 0% 0% 42% 100% 0% 0% 314 MHz 0% 0% 31% 100% 0% 0% 316 MHz 0% 0% 21% 100% 0% 0% 318 MHz 0% 0% 13% 99% 0% 0% 320 MHz 0% 0% 6% 99% 0% 0% 322 MHz 0% 0% 2% 99% 0% 0% 324 MHz 0% 0% 1% 98% 0% 0% 326 MHz 0% 0% 0% 97% 0% 0% 328 MHz 0% 0% 0% 95% 0% 0% 330 MHz 0% 0% 0% 94% 0% 0% 332 MHz 0% 0% 0% 93% 0% 0% 334 MHz 0% 0% 0% 92% 0% 0% 336 MHz 0% 0% 0% 92% 0% 0% 338 MHz 0% 0% 0% 91% 0% 0% 340 MHz 0% 0% 0% 90% 0% 0% 342 MHz 0% 0% 0% 89% 0% 0% 344 MHz 0% 0% 0% 87% 1% 0% 346 MHz 0% 0% 0% 44% 6% 0% 348 MHz 0% 0% 0% 18% 14% 0% 350 MHz 0% 0% 0% 6% 26% 0% 352 MHz 0% 0% 0% 1% 39% 0% 354 MHz 0% 0% 0% 0% 52% 0% 356 MHz 0% 0% 0% 0% 65% 0% 358 MHz 0% 0% 0% 0% 75% 0% 360 MHz 0% 0% 0% 0% 81% 0% 362 MHz 0% 0% 0% 0% 85% 0% 364 MHz 0% 0% 0% 0% 87% 0% 366 MHz 0% 0% 0% 0% 88% 0% 368 MHz 0% 0% 0% 0% 87% 0% 370 MHz 0% 0% 0% 0% 82% 10% 372 MHz 0% 0% 0% 0% 82% 91% 374 MHz 0% 0% 0% 0% 82% 99% 376 MHz 0% 0% 0% 0% 82% 99% 378 MHz 0% 0% 0% 0% 82% 99% 380 MHz 0% 0% 0% 0% 82% 100% 382 MHz 0% 0% 0% 0% 81% 100% 384 MHz 0% 0% 0% 0% 81% 100% 386 MHz 0% 0% 0% 0% 80% 100% 388 MHz 0% 0% 0% 0% 79% 100% 390 MHz 0% 0% 0% 0% 78% 100% DoneHa, I see a small typo in the reports. It's no longer 400 x blocksize tested, it's only 100 x blocksize now. I lowered it so Pnut compiled programs didn't take too long. That's something else to improve - Make the randfill() and compare() routines faster.
If I'm understanding it right, all of DATA_PINS, CE_PIN and CLK_PINs are being used with their registered-functionalities activated. Is this true?