

MULDIV64 implementation
 RossH
Posts: 5,780
RossH
Posts: 5,780
in Propeller 2
I am trying to understand the SPIN function MULDIV64 and implement it in PASM. It seems from the description that the following PASM should implement it, but it does not. Can someone tell me if my interpretation of MULDIV64 is incorrect, and/or provide some PASM source code for its correct implementation?
' r4 = mult1
' r3 = mult2
' r2 = divisor
qmul r3, r4 ' mult1 * mult2
getqx r0 ' get lower 32 bits of product
getqy r1 ' get upper 32 bits of product
setq r1 ' set upper 32 bits of product
qdiv r0, r2 ' divide product by divisor
getqx r0 ' get quotient of division
' r0 = quotient ???
Thanks!
Comments
Maybe this ? see BIG MULTIPLIER BIG DIVIDER
[deleted link, see #4]
Ross,
What you've written seems about right, for unsigned at least. I haven't actually used MULDIV64() though. I made my own with improved rounding here - https://forums.parallax.com/discussion/173567/muldiv64-appears-to-have-2-error and they've since held up well to a number of use cases, eg: https://forums.parallax.com/discussion/comment/1525977/#Comment_1525977
Oh, wow! What topic was that attachment from? The details are ancient. It must be prop2-hot.
Yes, MULDIV64 is unsigned. The code I posted looks right to me too - but it doesn't actually work. Hence my post
Here's Chip's source code:
muldiv64_ setq #2-1 'pop m1 and m2, open top of stack rdlong y,--ptra 'x=d, y=m1, z=m2 rep @.stall,#1 'use REP to stall interrupts to protect cordic operation qmul y,z 'multiply m1 * m2 getqx y 'product in {z,y} getqy z .stall skip #%11_11_1 'skip to rep getms_ pusha x 'push stack to open top of stack rdlong w,#@clkfreq_hub 'get clkfreq into w and x mov x,w getct z wc 'get 64-bit clock count into {z,y} getct y rep @.stall,#1 'use REP to stall interrupts to protect cordic operation setq z 'divide {z,y} by x qdiv y,x getqy y 'remainder in y (fractional seconds) getqx x 'quotient in x (seconds) .stall cmp pa,#bc_getms wz 'if not GETMS then done if_nz retYep, removing the skipped instructions, it's as you've guessed. Only thing extra is the IRQ shielding.
@RossH : your implementation looks correct to me. What makes you think there's an issue? Perhaps there's a problem with the surrounding code?
For reference, here's the implementation of muldiv64 in flexspin (from sys/p2_code.spin):
pri _muldiv64(mult1, mult2, divisor) : r asm qmul mult1, mult2 getqy mult1 getqx mult2 setq mult1 qdiv mult2, divisor getqx r endasmThis code (which looks to be the same as my code) gives the wrong answer on my Propeller - I just tried it. Worse, it gives the same answer even if you comment out the 'setq' instruction. However, I have retrieved the Q register after the setq and checked that it has the right value, but the result of the qdiv is just wrong. It is as if the instruction is not using the Q register at all, and is instead always using zero for the upper 32 bits.
I don't understand what's going on.
What revision Propeller are you using, and can you tell me what answer your code on your Propeller gives for a typical example that needs to use the Q register? - say _muldiv64(0x11111,0x22222,0x3333)?
rossh
#include <inttypes.h> #include <stdio.h> enum { _clkfreq = 20_000_000, }; static uint32_t muldiv65( uint32_t mult1, uint32_t mult2, uint32_t divisor ) { uint32_t x; __asm { qmul mult1, mult2 mov x, divisor shr x, #1 getqx mult1 getqy mult2 add mult1, x wc addx mult2, #0 setq mult2 qdiv mult1, divisor getqx x } return x; } static uint32_t muldiv64( uint32_t mult1, uint32_t mult2, uint32_t divisor ) { uint32_t r; __asm { qmul mult1, mult2 getqx mult1 getqy mult2 setq mult2 qdiv mult1, divisor getqx r } return r; } void main( void ) { uint32_t m1 = 0x1_1111, m2 = 0x2_2222, d1 = 0x3_3333; _waitms( 200 ); uint32_t r1 = muldiv65( m1, m2, d1 ); printf( " MULDIV65(): m1 = %x, m2 = %x, d1 = %x, r1 = %x\n", m1, m2, d1, r1 ); r1 = muldiv64( m1, m2, d1 ); printf( " MULDIV64(): m1 = %x, m2 = %x, d1 = %x, r1 = %x\n", m1, m2, d1, r1 ); while(1); }Same story with spin2. Flexspin and Pnut give same results as above.
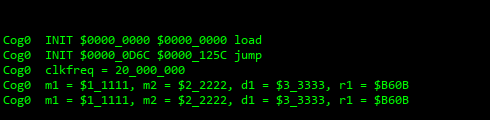
And that's using the built-in muldiv64() too. Eg:
r1 := muldiv64( m1,m2,d1 ) debug( uhex(m1),uhex(m2),uhex(d1),uhex(r1) )Everything looking good to me.
I'm using revB chips. RevC is no change. Even revA should be the same here.
D'oh! I had forgotten you cannot use the setq instruction in LMM or COMPACT mode. All versions of the code work fine in NATIVE mode. I'll have to rewrite the LMM and COMPACT versions of my implementation of MULDIV64!!!
It's clearly too long since I did any Propeller programming - I've forgotten all the Propeller 2 'gotchas'!")
Thanks to all those who helped!
rossh
Hmm, all those combos must be an issue in those modes. What about ##immediate ?
Yep, but the LMM and COMPACT code generator don't generate those (nor do they generate setq!). But I had forgotten this limitation when writing new library routines.
CMM is easy (I can use FCACHE) but the Catalina LMM Kernel never implemented FCACHE (the P1 had no room, and I decided no to bother on the P2 because LMM is not really useful once you have NATIVE execution!) but I had forgotten that this meant I have to custom code anything that requires instructions be executed strictly sequentially (never a problem on the P1, but on the P2 this means anything that requires setq, augs, augd etc).
Does it even make sense to use LMM on P2? Isn't it strictly worse than NATIVE, both in speed and code size? I'd be tempted to just drop that mode for the P2.
Perhaps not. But since it was fully implemented for the P1, it cost almost nothing to keep it implemented on the P2. Except, of course, when I forget the limitations of the LMM library code on the P2!")