@chintan_joshi said:
But what fix you have added to adjust LEADIN to get correct signal? If i can remove NOP with this fix then it can help a lot.
Change the 5 to a 4 or 3.Actually, 5 or 6 is good, Oops, checking it, 9 or 10 is good - since you've got that extra DRVL in there. That's just a quick hack, it doesn't compute cycle length. Just a bit cleaner than adding instructions.
@chintan_joshi said:
But what fix you have added to adjust LEADIN to get correct signal? If i can remove NOP with this fix then it can help a lot.
Change the 5 to a 4 or 3.Actually, 5 or 6 is good, Oops, checking it, 9 or 10 is good - since you've got that extra DRVL in there. That's just a quick hack, it doesn't compute cycle length. Just a bit cleaner than adding instructions.
@evanh changing it to 9 or 10 didn't work for me . Also can i use WAITX #1 in place of NOP?
Also how can i remove drvl ? because currently if i remove drvl i am not able to get any data signal.
Maybe I've missed something. Try every LEADIN compensation from 3 to 10. This is where a good scope really makes a difference. Being able to see what's really happening at the pins can clear up a lot of confusion.
In this case, it doesn't even need to be connected to the printhead because all you're wanting to see is how the timing changes between different configs - To get the same effect by different means.
@evanh said:
The DRVL is fine, and a NOP beside it would be fine also.
When I say fine here, I mean an update to the LEADIN compensation counters any extra instructions. Each extra instruction incurs an additional two sysclock ticks. So with the DRVL added all that's needed is to change the 5 to a 7.
But you seem to need a different timing for that printhead. At this stage, given the lack of timing details (incomplete datasheet), I'm happy to just have you hand adjust the compensation to suit.
Hello @evanh and @ersmith
Please check this output from 2 flexprop IDE.
Here we can see clear difference between 2. And its not a speed issue.
in 5.9.23 IDE 40 CLK pulses finished in 2.472 us
while in 5.9.26 IDE 40 CLK pulses finished in 2.507 us. though CLOCK signal staying LOW for whole 40 pulses. and this is the issue.
Please note i run same code which i attached as sample code on both the IDE.
Still i am not getting proper clock signal on 5.9.26 IDE. Looks like Some update causing issue in assembly code execution. Hope you can understand issue here.
Err, hang-on, the pre-built Windoze edition of Flexspin is compiling your program differently (no such issue under Linux) ...
6.0.2 is fixed again ... Windoze Flexspin 6.0.0 is also fine. So versions 5.9.26 and 5.9.28 are the borked ones!
Short answer is don't use either of those.
As for what is going wrong: I see three diffs, all immediate values, in the p2asm output files. The notable one is the setting of the clock smartpin. WXPIN needs to set a lower 16 bits and an upper 16-bits, but in the borked compile it is only setting the lower 16-bits.
_wxpin( CLK_PIN, CLK_DIV | (CLK_DIV>>1 + (CPOL & CLK_DIV))<<16 ); // set period and duty
produces wxpin ##524304, #15 in the working compile
and wxpin #16, #15 in the borked compile.
@evanh and @chintan_joshi : it turns out that there was a bug in 32 bit builds of flexspin that was fixed just before the 6.0.0 release, and I think that's what was causing the problems seen under Windows. Uprgrading to 6.0.0 or later should fix that.
@evanh said:
Thanks Eric. Maybe that bug was intruding in the past as well? I'm guessing it was a trap all along.
I think there was a trap all along, but it only became manifest after I made some other changes to do 64 bit calculations on constants -- older versions of flexspin only had 32 bit constants. But after the expansion to 64 bits some shift operations were broken on 32 bit builds.
@ersmith said:
@evanh and @chintan_joshi : it turns out that there was a bug in 32 bit builds of flexspin that was fixed just before the 6.0.0 release, and I think that's what was causing the problems seen under Windows. Uprgrading to 6.0.0 or later should fix that.
Hello @evanh and @ersmith yes, 6.0.2 IDE fixed the bug. Able to get proper signals.
I am working on to fill Array data. In my sample code(attached updated demo_IDE.cpp), i am filling array as below. But this instructions taking around 1 us .
I am measuring timing by GPIO pin led2 signals(Generating 100ns pulse for every Px increment). so there is 1 us between 2 pulses of LED2 pin. Is there anyway in P2 that we can decrease this 1 us to nanoseconds? Because this 1 us if i consider for high data, then it reaches to 600 us just for filling data in array.
Here's the compiled assembly. It's a little bloated on the reloading for indexing but otherwise seems straightforward enough.
Notably, BOOL type is using byte sized memory (WRBYTE). That's a good thing because it eliminates an otherwise cumbersome read-modify-write of hubRAM each time.
@evanh said:
Here's the compiled assembly. It's a little bloated on the reloading for indexing but otherwise seems straightforward enough.
Notably, BOOL type is using byte sized memory (WRBYTE). That's a good thing because it eliminates an otherwise cumbersome read-modify-write of hubRAM each time.
It should execute in maybe 64 ticks. I can see you're measuring the loop time of the surrounding code too ...
Yes i need to speed up the data filling, Because how fast i can fill data print will become faster. i have checked further and found that in for loop, time till Px increment is 1 us, i am measuring time for every px increment, 1us timing is for every increment in Px, Px is going from 0 to 40 and reset to 0 and incrementing Ax . Initially i was using 2d array, i changed it to 1D array to speed up the things. Still this 1us Px increment time is slowing down the overall process.
Hmm, you probably need to explain the data generation then. Can there be pre-built "fonts" of a sort? That just need block copied into the print buffer.
@evanh said:
Hmm, you probably need to explain the data generation then. Can there be pre-built "fonts" of a sort? That just need block copied into the print buffer.
Let me add some detail here.
Here
Data generation is done using below two lines, so image data will be in buf_t.
memset(temp_buf_t,0,bufs);
memcpy(temp_buf_t,buf_t,data_count);
//sending attenuation to filldata()
_cogatn((1<<cogid3));
Here in Print_Data() , i am copying print data from buf_t to temp_buf_t() and sending attenuation to the cog where it can start fill data in buf_t again, so this is parallel processing. An this is not causing speed issue, because till i finish 19200 bits data, i will have buf_t ready with next data.
i am using temp_buf_t in Print_data() which is copy of buf_t, this is how i am getting 3 bytes from temp_buf_t as below
for (int j=0; j <= ret; j += 3) {
int percent_c = (int)(temp_buf_t[j]);
int percent_m = (int)(temp_buf_t[j + 1]);
int percent_y = (int)(temp_buf_t[j + 2]);
now what causing speed issue is to fill this percent_c,m,y to another 1 d array as below
But this taking around 1 us, and i want to decrease this fill time. Because data generation not affecting time in code execution because its running on another cog.
When Px reached 40 i am sending attenuation to cog to use this temp_Pdata to decrease time, copying temp_Pdata to temp_mov_Pdata so i can use temp_mov_Pdata in another cog and temp_Pdata will start filling data parallely.
This additional cog function fillarray_fast(), not included in demo_IDE.cpp file, i can share demo_IDE.cpp with this change if required.
This is the latest update till now
px = 0 to px = 40-> taking around 50 us in Print_data()
And after that when i send attenuation to process this 40 px, this processing takes 60 us, so fillarray_fast() taking 60 us till fillHexdataasm(Ax_temp-1).
So i think need to speed up both the process to make it fast.
@evanh and @iseries i have created sample code just to check performance on Normal GCC compiler and Flexprop with P2 for array manipulation. And there is lot more difference found.
On Linux machine and C++ compiler i run array.cpp file(attached) and its taking only 45 us total.
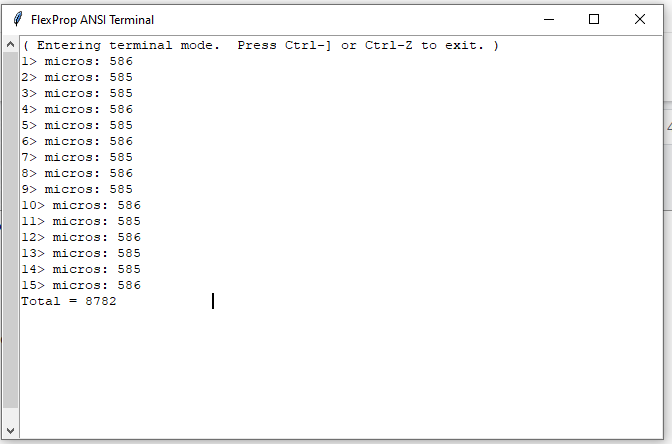
And same code with flexprop supported code arraytest.cpp i run on flexprop for P2 and its taking 8782 us. Not able to understand why this much of difference between 2 codes.
@chintan_joshi : You don't mention what platform you ran the tests on, but typical desktop PCs have clocks that are 10x - 20x times faster than a P2's clock, and are able to execute multiple instructions per clock cycle (whereas the P2 can execute only 1 instruction every other cycle). Moreover PCs have sophisticated memory caches to hide memory latency, and branch prediction units to hide branch latency, none of which the P2 have. So in general one should expect a PC to be hundreds of times faster than a P2.
@iseries said:
You're saying that your desktop computer that is running at say 2Ghz and the P2 which is running at 160Mhz aren't close in performance?
Mike
@iseries and @ersmith , Thank you for the clarification, i missed that part. You are right both will have performance difference. But how much difference that i wanted to know. I am trying to find a way to speed up array manipulation in P2. And this test i just did to see how fast array is filled when we use normal Desktop system and what can we do in P2 to improve array manpulation speed.
I have tried to use pointers as suggested by @iseries in fillarray_fast() and that improved the speed, i have applied similar solution here for another array fill and that did not help. Do i need to code in PASM2 to make this operation fast?
Or can we add external clock in P2? RIght now i am using 256 MHZ clock frequency.


Comments
Change the 5 to a 4 or 3. Actually, 5 or 6 is good, Oops, checking it, 9 or 10 is good - since you've got that extra DRVL in there. That's just a quick hack, it doesn't compute cycle length. Just a bit cleaner than adding instructions.
@evanh changing it to 9 or 10 didn't work for me . Also can i use WAITX #1 in place of NOP?
Also how can i remove drvl ? because currently if i remove drvl i am not able to get any data signal.
The DRVL is fine, and a NOP beside it would be fine also. The NOP position, between the two clkpin ops: DIRH and WYPIN, is the naughty one.
Maybe I've missed something. Try every LEADIN compensation from 3 to 10. This is where a good scope really makes a difference. Being able to see what's really happening at the pins can clear up a lot of confusion.
In this case, it doesn't even need to be connected to the printhead because all you're wanting to see is how the timing changes between different configs - To get the same effect by different means.
When I say fine here, I mean an update to the LEADIN compensation counters any extra instructions. Each extra instruction incurs an additional two sysclock ticks. So with the DRVL added all that's needed is to change the 5 to a 7.
But you seem to need a different timing for that printhead. At this stage, given the lack of timing details (incomplete datasheet), I'm happy to just have you hand adjust the compensation to suit.
Hello @evanh and @ersmith
Please check this output from 2 flexprop IDE.
Here we can see clear difference between 2. And its not a speed issue.
in 5.9.23 IDE 40 CLK pulses finished in 2.472 us
while in 5.9.26 IDE 40 CLK pulses finished in 2.507 us. though CLOCK signal staying LOW for whole 40 pulses. and this is the issue.
Please note i run same code which i attached as sample code on both the IDE.
Still i am not getting proper clock signal on 5.9.26 IDE. Looks like Some update causing issue in assembly code execution. Hope you can understand issue here.
That sample code produced the same clock for all versions of the compiler. I had no issue - https://forums.parallax.com/discussion/comment/1548893/#Comment_1548893
Err, hang-on, the pre-built Windoze edition of Flexspin is compiling your program differently (no such issue under Linux) ...
6.0.2 is fixed again ... Windoze Flexspin 6.0.0 is also fine. So versions 5.9.26 and 5.9.28 are the borked ones!
Short answer is don't use either of those.
As for what is going wrong: I see three diffs, all immediate values, in the p2asm output files. The notable one is the setting of the clock smartpin. WXPIN needs to set a lower 16 bits and an upper 16-bits, but in the borked compile it is only setting the lower 16-bits.
produces
wxpin ##524304, #15in the working compileand
wxpin #16, #15in the borked compile.Apologies Chintan, it looks like I was too quick to blame that logic analyser. Maybe it does work after all.")
No issues @evanh , You found the root issue that's important.")
@evanh and @chintan_joshi : it turns out that there was a bug in 32 bit builds of flexspin that was fixed just before the 6.0.0 release, and I think that's what was causing the problems seen under Windows. Uprgrading to 6.0.0 or later should fix that.
Thanks Eric. Maybe that bug was intruding in the past as well? I'm guessing it was a trap all along.
I think there was a trap all along, but it only became manifest after I made some other changes to do 64 bit calculations on constants -- older versions of flexspin only had 32 bit constants. But after the expansion to 64 bits some shift operations were broken on 32 bit builds.
Hello @evanh and @ersmith yes, 6.0.2 IDE fixed the bug. Able to get proper signals.
Also changed M_LEADIN to
This is generating proper signals without using NOP in DMA code.
Thank you very much.
Excellent news.
So it was upsetting multi-part constant building all along. Possibly when bit-shifts were included.
Looking at the two remaining diffs above, funnily, they are the two cases where the M_LEADIN constant gets used.
So for
TX_REGD = 1, CLK_REGD = 0, CPOL = 1, CPHA = 0, CLK_DIV = 16, M_NCO = 0x8000_0000UL / CLK_DIV + (0x8000_0000UL % CLK_DIV > 0UL ? 1UL : 0UL), // round up M_LEADIN = X_IMM_32X1_1DAC1 | 7 + CLK_DIV + CLK_REGD - TX_REGD - (1 ^ CPHA) * (CLK_DIV>>1)the working compile produces a numerical value of
1073741838or 0x4000_000Ethe borked compile produces a numerical value of
1073741846or 0x4000_0016That's a +8 to the compensation - an extra half CLK_DIV. It seems the CPHA=0 subtraction didn't happen.
Hello @evanh
I am working on to fill Array data. In my sample code(attached updated demo_IDE.cpp), i am filling array as below. But this instructions taking around 1 us .
'''
temp_Pdata[index] = percent_c ? 1: 0;
temp_Pdata[index + 1] = percent_m? 1: 0;
temp_Pdata[index + 2] = percent_y ? 1: 0;
'''
I am measuring timing by GPIO pin led2 signals(Generating 100ns pulse for every Px increment). so there is 1 us between 2 pulses of LED2 pin. Is there anyway in P2 that we can decrease this 1 us to nanoseconds? Because this 1 us if i consider for high data, then it reaches to 600 us just for filling data in array.
Here's the compiled assembly. It's a little bloated on the reloading for indexing but otherwise seems straightforward enough.
Notably, BOOL type is using byte sized memory (WRBYTE). That's a good thing because it eliminates an otherwise cumbersome read-modify-write of hubRAM each time.
mov result1, local16 add ptr__dat__, ##93640 add result1, ptr__dat__ cmp local12, #0 wz if_ne mov local09, #1 if_e mov local09, #0 wrbyte local09, result1 mov local09, local16 add local09, #1 add local09, ptr__dat__ cmp local13, #0 wz if_ne mov local14, #1 if_e mov local14, #0 wrbyte local14, local09 mov local17, local16 add local17, #2 mov local09, ptr__dat__ add local17, ptr__dat__ cmp local15, #0 wz sub ptr__dat__, ##93640 if_ne mov local14, #1 if_e mov local14, #0 wrbyte local14, local17It should execute in maybe 64 ticks. I can see you're measuring the loop time of the surrounding code too ...
Yes i need to speed up the data filling, Because how fast i can fill data print will become faster. i have checked further and found that in for loop, time till Px increment is 1 us, i am measuring time for every px increment, 1us timing is for every increment in Px, Px is going from 0 to 40 and reset to 0 and incrementing Ax . Initially i was using 2d array, i changed it to 1D array to speed up the things. Still this 1us Px increment time is slowing down the overall process.
Hmm, you probably need to explain the data generation then. Can there be pre-built "fonts" of a sort? That just need block copied into the print buffer.
Hmm, Today's printers do 1200dpi so that would be 150bytes times 8.5X11 or 93.5 square inches would need 14k bytes to store one page.
Thats if it were only black and white. Now each dot is 32 bit color and you would need 450K of memory for one page.
The days of sending HPCL are gone. Windows renders the page in memory and sends the hole page down to be printed.
Mike
Let me add some detail here.
Here
Data generation is done using below two lines, so image data will be in buf_t.
Here in Print_Data() , i am copying print data from buf_t to temp_buf_t() and sending attenuation to the cog where it can start fill data in buf_t again, so this is parallel processing. An this is not causing speed issue, because till i finish 19200 bits data, i will have buf_t ready with next data.
i am using temp_buf_t in Print_data() which is copy of buf_t, this is how i am getting 3 bytes from temp_buf_t as below
for (int j=0; j <= ret; j += 3) { int percent_c = (int)(temp_buf_t[j]); int percent_m = (int)(temp_buf_t[j + 1]); int percent_y = (int)(temp_buf_t[j + 2]);now what causing speed issue is to fill this percent_c,m,y to another 1 d array as below
if (temp_px < 2) { index = Prev *3; temp_Pdata[index] = percent_c ? 1: 0; temp_Pdata[index + 1] = percent_m? 1: 0; temp_Pdata[index + 2] = percent_y ? 1: 0; //printf("Filling Prev %d\n",Prev); Prev--; temp_px++; if (Prev == 19) { Prev = 39; } } else { index = Pfd *3; temp_Pdata[index] = percent_c ? 1: 0; temp_Pdata[index + 1] = percent_m ? 1:0; temp_Pdata[index + 2] = percent_y ? 1:0; //printf("Filling Pfd %d\n",Pfd); Pfd--; temp_px++; if (temp_px == 4) { temp_px = 0; Pfd += 4; } if (Pfd == 21) { Pfd = 1; } } px++There is if else condition so at a time only one will be true, but in both condition filling of 1D array temp_Pdata is common with different index.
But this taking around 1 us, and i want to decrease this fill time. Because data generation not affecting time in code execution because its running on another cog.
When Px reached 40 i am sending attenuation to cog to use this temp_Pdata to decrease time, copying temp_Pdata to temp_mov_Pdata so i can use temp_mov_Pdata in another cog and temp_Pdata will start filling data parallely.
if (px == 40) { memcpy(temp_mov_Pdata, temp_Pdata, 120); memset(temp_Pdata, 0, sizeof(temp_Pdata)); _waitus(2); Ax++; _cogatn((1 << cogid5));//sending attenuation px = 0; } if (Ax == 10) { //memcpy(temp_hex_t,hex_t,sizeof(hex_t)); //_waitus(150); Ax = 0; px = 0; }And this is the cog function which will get attenuation when Px becomes 40,
void fillarray_fast() { int temp_px =0 ; int Ax_temp = 0; while(true) { while (_pollatn() == 0); //printf("\nAx_temp = %d\n",Ax_temp); for(int i=0,j = 0;i<120;i+=3,j++) { Pdatac[Ax_temp][j] = temp_mov_Pdata[i];//cyan Pdatam[Ax_temp][j] = temp_mov_Pdata[i+1];//Magenta Pdatay[Ax_temp][j] = temp_mov_Pdata[i+2];//Yellow } Ax_temp += 1; FillADATARegister(0); fillHexdataasm(Ax_temp-1); if(Ax_temp==10) { _pinw(led,1); _waitx(10); _pinw(led,0); Ax_temp = 0; memcpy(temp_hex_t,hex_t,sizeof(hex_t)); _cogatn((1 << cogid1)); memset(hex_t, 0, sizeof(hex_t)); } } }This additional cog function fillarray_fast(), not included in demo_IDE.cpp file, i can share demo_IDE.cpp with this change if required.
This is the latest update till now
px = 0 to px = 40-> taking around 50 us in Print_data()
And after that when i send attenuation to process this 40 px, this processing takes 60 us, so fillarray_fast() taking 60 us till fillHexdataasm(Ax_temp-1).
So i think need to speed up both the process to make it fast.
In fillarray_fast:
Is it faster to use pointers:
char *c, *m, *y; char *t; int i; while(true) { while (_pollatn() == 0); //printf("\nAx_temp = %d\n",Ax_temp); c = Pdatac[Ax_temp]; m = Pdatam[Ax_temp]; y = Pdatay[Ax_temp]; t = temp_mov_Pdata; i = 0; for(int j = 0;j<40;j++) { *c++ = *t++; *m++ = *t++; *y++ = *t++; // Pdatac[Ax_temp][j] = temp_mov_Pdata[i];//cyan // Pdatam[Ax_temp][j] = temp_mov_Pdata[i+1];//Magenta // Pdatay[Ax_temp][j] = temp_mov_Pdata[i+2];//Yellow }Assembly Code:
call #FCACHE_LOAD_ LR__0013 cmps local06, #40 wc if_ae jmp #LR__0015 rdbyte arg03, local05 wrbyte arg03, local02 add local05, #1 rdbyte arg03, local05 wrbyte arg03, local03 add local05, #1 rdbyte arg03, local05 add local05, #1 wrbyte arg03, local04 add local06, #1 add local02, #1 add local03, #1 add local04, #1 jmp #LR__0013 LR__0014 LR__0015Mike
@iseries , wow great. now fillarray_fast() for loop taking 12us with pointers, previously it was taking 24 us. Thank you very much @iseries .
Thanks for helping Mike.
@evanh and @iseries i have created sample code just to check performance on Normal GCC compiler and Flexprop with P2 for array manipulation. And there is lot more difference found.
On Linux machine and C++ compiler i run array.cpp file(attached) and its taking only 45 us total.
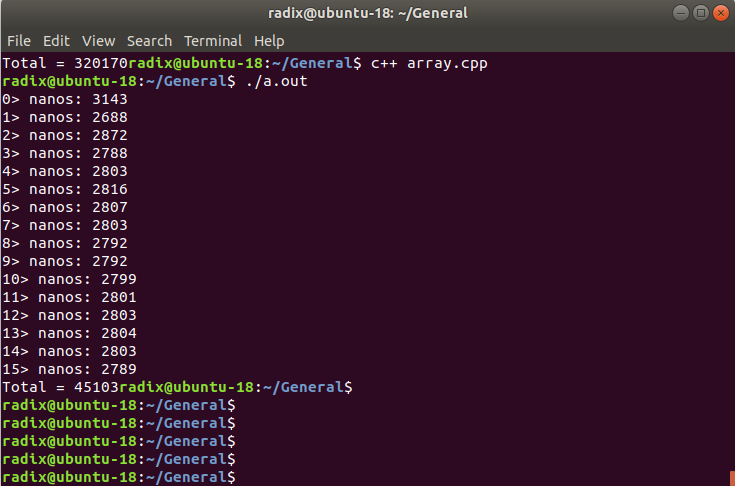
And same code with flexprop supported code arraytest.cpp i run on flexprop for P2 and its taking 8782 us. Not able to understand why this much of difference between 2 codes.
You're saying that your desktop computer that is running at say 2Ghz and the P2 which is running at 160Mhz aren't close in performance?
Mike
@chintan_joshi : You don't mention what platform you ran the tests on, but typical desktop PCs have clocks that are 10x - 20x times faster than a P2's clock, and are able to execute multiple instructions per clock cycle (whereas the P2 can execute only 1 instruction every other cycle). Moreover PCs have sophisticated memory caches to hide memory latency, and branch prediction units to hide branch latency, none of which the P2 have. So in general one should expect a PC to be hundreds of times faster than a P2.
@iseries and @ersmith , Thank you for the clarification, i missed that part. You are right both will have performance difference. But how much difference that i wanted to know. I am trying to find a way to speed up array manipulation in P2. And this test i just did to see how fast array is filled when we use normal Desktop system and what can we do in P2 to improve array manpulation speed.
I have tried to use pointers as suggested by @iseries in fillarray_fast() and that improved the speed, i have applied similar solution here for another array fill and that did not help. Do i need to code in PASM2 to make this operation fast?
Or can we add external clock in P2? RIght now i am using 256 MHZ clock frequency.
When you compile your program a p2asm file is generated that shows all the assembly code with labels to each and every function.
Mike
You can just set the clock frequency higher, no external components needed. You should be able to go up to 320 MHz with no issues at all.