@evanh said:
One thing that I keep striking, in Spin as well as C, is having to copy the variables, containing pin numbers, from their preset static storage into local registers for I/O handling routines to have quick access to the assigned pin numbers. It would be cool to have some sort of generic solution to somehow auto-map-and-generate for that sort of case, where there is a sequential data block that the function copies into registers as its first step.
Kind of like a static-register qualifier ... but visible across the source file/structure/object.
So you are trying to auto-initialize some subset of register variables with data at some given hub address in specifically nominated functions? This is to avoid loading a bunch of variables with pin numbers that don't change? Seems like a candidate for inline assembly in places where speed matters.
@evanh said:
One thing that I keep striking, in Spin as well as C, is having to copy the variables, containing pin numbers, from their preset static storage into local registers for I/O handling routines to have quick access to the assigned pin numbers. It would be cool to have some sort of generic solution to somehow auto-map-and-generate for that sort of case, where there is a sequential data block that the function copies into registers as its first step.
With GCC, the only problem is that assembly sources needs .equ while C sources needs #define, and AFAIK there isn't an easy way to have a single definition, aside from using some ifdef condition to have an include file readable from both C and assembly (I don't remember exactly what but GCC defines something to detect assembly sources).
@rogloh said:
So you are trying to auto-initialize some subset of register variables with data at some given hub address in specifically nominated functions? This is to avoid loading a bunch of variables with pin numbers that don't change? Seems like a candidate for inline assembly in places where speed matters.
Yes, for hand optimised I/O loops. But I can see it'll benefit performance even at the regular optimiser level just by having fast access to static declared variables.
Chip has sort of gone full custom on this in Spin with REGLOAD() and REGEXEC() but I'm wanting something more automated and compatible with regular compilers.
@evanh said:
Ah, no. Need them to be runtime adjustable so that an init() can setup the pin numbers on a per-instance basis.
In Spin inline PASM maps the methods parameters to registers pr0-pr7 so you can just use them (and I believe you can use the same name as the parameter), with cog code started with coginit you can do the same with setq/rdlong with ptra pointing to the first parameter. If that's what you mean.
I don't remember if GCC (for P1) supports inline assembly but, if the P2 variant supports it, I guess it can do the same.
Chip has sort of gone full custom on this in Spin with REGLOAD() and REGEXEC() but I'm wanting something more automated and compatible with regular compilers.
Maybe I don't understand the problem, but seems that raises the question: how the compiler/runtime can know what you want to do ?
Parameter passing is most commonly how it's done at the moment. It gets unwieldy though.
@macca said:
@evanh said:
Chip has sort of gone full custom on this in Spin with REGLOAD() and REGEXEC() but I'm wanting something more automated and compatible with regular compilers.
Actually, thinking more about it, regload() isn't a good solution because it doesn't do instancing. Chip most likely added that feature just for embedding interrupt handlers. The Pnut/Proptool VM is interrupt safe.
Maybe I don't understand the problem, but seems that raises the question: how the compiler/runtime can know what you want to do ?
Well, adding that ability, to tell the compiler, is what I'm wanting.
I added some more assembler and disassembler code to handle the pointers and the ## symbol in indexes... still checking but it is showing some signs of working, and this stuff it gets a little tricky. Some alias decoding happens for POPA/POPB cases.
The ## use in the disassembler can currently confuse the decode for the rdlong after AUGS's because the remaining 9 bits in the S field after the AUGS use a different immediate format. I guess to fix that I should remember if the last instruction was AUGS and print it as a raw # constant instead of trying to decode independently as if there was no prior AUGS. It gets a little confusing though because the AUGS could have happened several instructions prior, or even in another section that jumped here, so it wouldn't be a perfect way to do things.
Yeah I'd prefer to explicitly see the AUGS+AUGD instructions in the listing to know they are there. The tracking of AUGS/AUGD over multiple instructions disassembled and decoding back to ## gets too complicated to manage. I think I could just print the 9 bit immediate for the pointer index ops if they follow either an AUGS or AUGS+AUGD sequence, instead of decoding fully, and just leave it at that, which should cover most cases the compiler would generate I suspect and be good enough.
I was finally able to get the relocations done for the @ symbol in CALL/JMP/LOC etc. I already had @ working for the REP syntax. This was rather messy but I think it works now and covers these cases in the P2 document:
Here's the disassembled code output after I've linked the code. It seems to match the expected values. Even though the .cog section is shown at address 0 in the listing it is actually placed at $1000 in the image. OBJDUMP just displays it at its VMA not LMA.
I don't really like how the assembler+linker just forcibly overrides the opcodes automatically for the user with these @ relocations. It would be probably nicer to have a warning generated in the linker if you try to branch between COG/LUT and HUB RAM regions using relative branches and if the linker has to change it. But that could potentially generate a lot of warnings if relative branching is used everywhere by default.
Added ALIGNW and ALIGNL directives to pad to nearest boundary
extended BYTE/WORD/LONG directives to enable arrays of data instead of individual elements
e.g. data long 0[100], 1[10] is now supported
the assembler will allow P2 specific FIT/RES/ORGH/ORGF directives to be present in the input file but they are still ignored - still not sure if they will be possible to implement correctly for the P2 with GAS. I read something about that it can't ORG backwards, plus this memory layout stuff typically is controlled by the linker script anyway.
"Fixed the "REP", "LOC", and "SKIP" instructions so they don't collide with GAS directives. This is done dynamically using text translation. When used as directives, these will still need the dot symbol prepended.
Wrote a simple test harness to exercise different combinations of argument formats to test against the assembler and disassembler and compare results. Exercised all 407 P2 instruction types and 13 format combinations. This tests against the expected case and looks specifically for instructions which incorrectly match other formats, and ensures the opcode is both generated and disassembled correctly with the expected value. After some fixes in my code it now all seems to work. It did uncover another colliding P2 instruction (SKIP), that I didn't know about, which is also used as a directive, like REP and LOC were and needing fixing. So far everything else looked ok.
This harness could be extended to exercise all flag combinations if I want, although that handling is mostly common and doesn't really need to be tested for every single instruction. It could also be extended to detect other particular syntax errors and values out of range, etc, but again that is handled in a non-instruction specific manner so it's probably overkill to test that way. I'll think about it, as it's a diminishing return now the main test is complete.
I'm now looking at those constants being added to register names/symbols. The addressing then needs to be handed in a different way when the symbol is in COG/LUT RAM vs HUB RAM. It's a little tricky to figure out the best way to deal with that, especially if AUGS/AUGD is used as well and I'm still getting my head around it.
Once that is sorted that might be enough to have a completed functioning P2 GNU assembler and I should try to check it into a Github repo.
By the way. Does anyone know why there are all these control-L (^L) characters in the GCC source files? I have know idea why there are there. I don't always keep them around with my file changes.
@rogloh said:
By the way. Does anyone know why there are all these control-L (^L) characters in the GCC source files? I have know idea why there are there. I don't always keep them around with my file changes.
Funny, I never noticed them before... CTRL-L is the printer's formfeed, maybe ages ago, someone printed the sources and cared to insert FF at proper locations (when editors allowed to enter raw control characters...), then nobody cared to remove or update, and guess nobody tried to print...


Comments
So you are trying to auto-initialize some subset of register variables with data at some given hub address in specifically nominated functions? This is to avoid loading a bunch of variables with pin numbers that don't change? Seems like a candidate for inline assembly in places where speed matters.
Like this ?
.equ LPIN, 15 .equ RPIN, 14 ... r1 long ((1 << LPIN) | (1 << RPIN)) & $FFFFFFFEWith GCC, the only problem is that assembly sources needs .equ while C sources needs #define, and AFAIK there isn't an easy way to have a single definition, aside from using some ifdef condition to have an include file readable from both C and assembly (I don't remember exactly what but GCC defines something to detect assembly sources).
Ah, no. Need them to be runtime adjustable so that an init() can setup the pin numbers on a per-instance basis.
Yes, for hand optimised I/O loops. But I can see it'll benefit performance even at the regular optimiser level just by having fast access to static declared variables.
Chip has sort of gone full custom on this in Spin with REGLOAD() and REGEXEC() but I'm wanting something more automated and compatible with regular compilers.
In Spin inline PASM maps the methods parameters to registers pr0-pr7 so you can just use them (and I believe you can use the same name as the parameter), with cog code started with coginit you can do the same with setq/rdlong with ptra pointing to the first parameter. If that's what you mean.
I don't remember if GCC (for P1) supports inline assembly but, if the P2 variant supports it, I guess it can do the same.
Maybe I don't understand the problem, but seems that raises the question: how the compiler/runtime can know what you want to do ?
Parameter passing is most commonly how it's done at the moment. It gets unwieldy though.
Actually, thinking more about it, regload() isn't a good solution because it doesn't do instancing. Chip most likely added that feature just for embedding interrupt handlers. The Pnut/Proptool VM is interrupt safe.
Well, adding that ability, to tell the compiler, is what I'm wanting.
I added some more assembler and disassembler code to handle the pointers and the ## symbol in indexes... still checking but it is showing some signs of working, and this stuff it gets a little tricky. Some alias decoding happens for POPA/POPB cases.
The ## use in the disassembler can currently confuse the decode for the rdlong after AUGS's because the remaining 9 bits in the S field after the AUGS use a different immediate format. I guess to fix that I should remember if the last instruction was AUGS and print it as a raw # constant instead of trying to decode independently as if there was no prior AUGS. It gets a little confusing though because the AUGS could have happened several instructions prior, or even in another section that jumped here, so it wouldn't be a perfect way to do things.
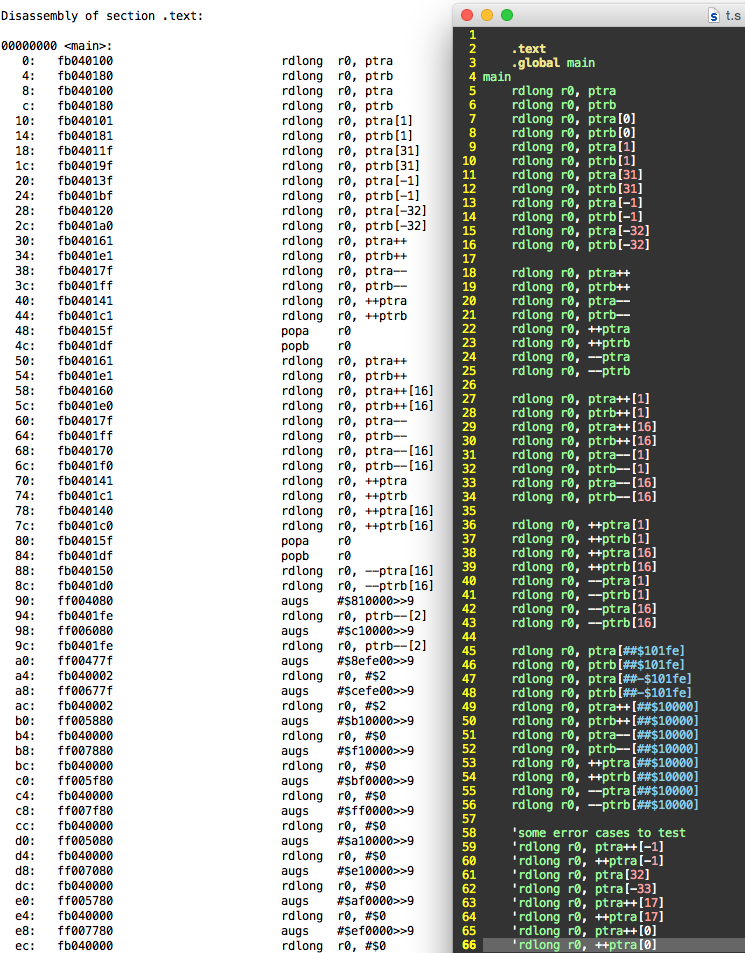
I've also handled some of the error cases..

Maybe don't represent ## at all. It's not actually an encoding of one instruction and, as you say, there's no assurance where the AUGS is located.
The other approach is to support only pairings of what compilers will produce. That'll cover 99.9% of uses and those at least do have placement rules.
Yeah I'd prefer to explicitly see the AUGS+AUGD instructions in the listing to know they are there. The tracking of AUGS/AUGD over multiple instructions disassembled and decoding back to ## gets too complicated to manage. I think I could just print the 9 bit immediate for the pointer index ops if they follow either an AUGS or AUGS+AUGD sequence, instead of decoding fully, and just leave it at that, which should cover most cases the compiler would generate I suspect and be good enough.
I was finally able to get the relocations done for the @ symbol in CALL/JMP/LOC etc. I already had @ working for the REP syntax. This was rather messy but I think it works now and covers these cases in the P2 document:
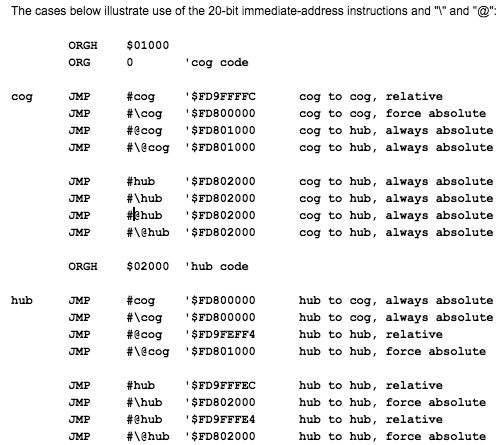
Here's the disassembled code output after I've linked the code. It seems to match the expected values. Even though the .cog section is shown at address 0 in the listing it is actually placed at $1000 in the image. OBJDUMP just displays it at its VMA not LMA.
I don't really like how the assembler+linker just forcibly overrides the opcodes automatically for the user with these @ relocations. It would be probably nicer to have a warning generated in the linker if you try to branch between COG/LUT and HUB RAM regions using relative branches and if the linker has to change it. But that could potentially generate a lot of warnings if relative branching is used everywhere by default.
Did a bit more work on the GNU binutils for P2...
extended BYTE/WORD/LONG directives to enable arrays of data instead of individual elements
e.g.
data long 0[100], 1[10]is now supportedthe assembler will allow P2 specific FIT/RES/ORGH/ORGF directives to be present in the input file but they are still ignored - still not sure if they will be possible to implement correctly for the P2 with GAS. I read something about that it can't ORG backwards, plus this memory layout stuff typically is controlled by the linker script anyway.
I'm now looking at those constants being added to register names/symbols. The addressing then needs to be handed in a different way when the symbol is in COG/LUT RAM vs HUB RAM. It's a little tricky to figure out the best way to deal with that, especially if AUGS/AUGD is used as well and I'm still getting my head around it.
Once that is sorted that might be enough to have a completed functioning P2 GNU assembler and I should try to check it into a Github repo.
By the way. Does anyone know why there are all these control-L (^L) characters in the GCC source files? I have know idea why there are there. I don't always keep them around with my file changes.
Funny, I never noticed them before... CTRL-L is the printer's formfeed, maybe ages ago, someone printed the sources and cared to insert FF at proper locations (when editors allowed to enter raw control characters...), then nobody cared to remove or update, and guess nobody tried to print...