

GCC resurrection
 rogloh
Posts: 6,414
rogloh
Posts: 6,414
To even mention this is possibly heresy I know, given the history GCC had with the P2-hot debacle and the grief that all caused its prior developers, however I'm tired of not having GCC for the P2 so I started to take a look at the existing code and made some changes to GNU binutils in the last few days to target the real P2. I've now changed enough of the code to actually run the GNU assembler and disassembler and linker and reached the point where I can get some real native PASM2 code running on a P2 using only these modified GNU bintools and loadp2.
What I've done so far for the P2:
- added all the new P2 instruction names and opcodes and got rid of the P2-hot instructions
- made changes to the disassembler (OBJDUMP) and assembler (GAS) and linker (LD) in binutils for targeting the real P2 revB/C chip, instead of P2-hot
- replaced the old P2 registers with new P2 registers
- got rid of all the INDA, INDB indirect handling and legacy REPS, REPD stuff in the code
- updated the PTRx indexing immediate encoding formats
- handled the new conditional execution bit position for P2 opcodes and added all new P2 conditional execution names and aliases, such as _ ret _ and if_00 etc
- handled new I,C,Z,L flag positions for P2 opcodes
- include special instruction operand format parsing for P2 MODCZ, AUG n, and #{/}nnnnnnnnnnnnnnnnnnnn address formats plus 3 operand instructions
- added all new P2 effects flags, such as ANDC/XORZ/WCZ etc, and limited them to a single flag only (P1 had multiple flags)
- enforced flag effects rules per P2 instruction
- added some more warning and error cases
- added new instruction class flags to track the instruction aliases
- fixed LOC and REP instruction collisions with GAS directives by disabling NO_PSEUDO_DOT - (this might affect P1 code gen, so it's still TBD if this "fix" remains)
- created the MODCZ operand aliases for a new hash table lookup when non-numeric data is specified
- created several new relocation types for the P2 including 9 bit relative, 20 bit absolute and 20 bit relative, and removed outdated ones for the old P2-hot
- automatically generate the AUGD and/or AUGS prefix instructions when ## is specified (this works in several places though not yet all)
- used the new P2 address relocations for DJNZ, TJNZ style relative branches and for the other absolute/relative JUMP/CALL/CALLD branches
- enabled "@symbol" use when computing the REP instruction counts
- reversed display endianness to make 32 bit opcodes more readable in disassembled output
Attached is a log with a build example showing what it can do now. It does a two object file assemble, link and download into the P2 to run a simple hello world program using the serial port. The disassembly listing output can still look a bit weird with its mix of 4 byte addresses and some constants printing in decimal and some in hex, and I'm still need to tidy that up more where I can, I hate seeing hex without $ or 0x prefixes, if decimal is also present. This is only using the existing default P2 linker script which is as yet unmodified, and it runs in COG RAM mode. With a little more work and a proper memory section layout and suitable C runtime initialization file (crt0.s) it should be able to run in a hub exec mode.
To make this toolchain operate perfectly obviously requires more testing, and assuming this effort continues on to success, these things are still needed:
- check whether all the existing relocations still work properly on a P2 for various cases
- find some way to nominate COG RAM mode code vs HUB RAM mode code so we can use this with the different relative/absolute branch addressing rules required when branching between COG and HUB exec mode, according to the table in the P2 document. Maybe based on section names?
- see if any of the current P2 FIT/ORGH/ORG/RES directives can be used in any way or could be translated, or can't really work with GNU assembler
- see if an overlay model is required to allow muliple sections assembled using the same addresses to be present in the final output file. I think for the P1 port they were called cogc files or something, and the build mucked around with the section names in the .o files to avoid duplicate address conflicts before final linking etc. That allows them to be loaded into the same COGRAM address range? This is TBD, I am still figuring things out there.
- see if the PASM "@" symbol has any use or meaning anymore with the GNU assembler and linker's capabilities
- try to generate symbols from the CON section including enumerations for convenience in porting code in the "PASM compatibility" mode
- add a "long" pseudo instruction to encode long data since NO_PSEUDO_DOT was disabled and using .long gets unwieldy (or we could translate dynamically into ".long" when we see "long" in the line after an optional label)
- eventually support the "##" constant format for all 9 bit immediates
- figure out how the extra 2k-4k LUTRAM addressing range fits into things, or changes in the linker script
- write a test program to automatically verify that every single one of the 407 valid P2 instructions/aliases are being encoded/decoded correctly and can detect errors when invalid flags or syntax get applied to an instruction
- do whatever else may be needed as I figure things out....eg. support any special startup sections, symbol names, floating point library, etc
- check it into a Github repo
The CMM and LMM models have not been adjusted for the P2, but should hopefully still work for P1. I've tried to keep all the P1 code intact and only make P2 specific changes wherever possible. I don't think CMM or LMM is really applicable anymore for the P2 given we have native HUB exec, although XMM[C] is a future possibility to consider now I know how to get externally sourced executable code running in an i-cache. Maybe a special P2 VM suitable to enable CMM on P2 could make sense down the track to help compress the code but it needs more work.
If this toolchain can be made to work reliably for the P2, then we can potentially also adjust the GCC C/C++ compiler to generate native P2 instructions. In the meantime Dave Hein's s2pasm tool could be used to create P2 assembly code from P1 PASM output which could then be assembled and linked with binutils tools outputting real ELF32/binary format object code for the P2. If GCC can be customized for the P2 I'd really like to use a PTR reg as the stack pointer and use its indexed addressing modes to access stack parameters, as well as adding more general purpose registers, increasing it from 16 to 32 registers for example. These things could speed up C quite a lot more on the P2 I would imagine as well as reduce the size of generated code.
I do know that the GCC codebase has moved on and this is still all based on the older version, but you have to start somewhere. Maybe if it works, someone could try to port it later to the newer GCC but that needs to be a separate effort once if/when this works.

Comments
I also had to deal with the instruction aliases on the P2 which can be a PITA to handle, and there were basically 5 different alias classes types needed:
rdword D,{#}S/P {WC/WZ/WCZ} 1010111CZIDDDDDDDDDSSSSSSSSS alias0 popa D {WC/WZ/WCZ} 1011000CZ1DDDDDDDDD101011111 alias0bmask D,{#}S 100111001IDDDDDDDDDSSSSSSSSS alias1 bmask D 1001110010DDDDDDDDDDDDDDDDDD alias1alti D 1001101001DDDDDDDDD101100100 alias2 alti D,{#}S 100110100IDDDDDDDDDSSSSSSSSS alias2 getrnd D {WC/WZ/WCZ} 1101011CZ0DDDDDDDDD000011011 alias2 getrnd WC/WZ/WCZ 1101011CZ1000000000000011011 alias2 calld D,{#}S {WC/WZ/WCZ} 1011001CZIDDDDDDDDDSSSSSSSSS alias2 calld PA/PB/PTRA/PTRB,#{\}A 11100WWRAAAAAAAAAAAAAAAAAAAA alias2 jmp D {WC/WZ/WCZ} 1101011CZ0DDDDDDDDD000101100 alias2 jmp #{\}A 1101100RAAAAAAAAAAAAAAAAAAAA alias2 call D {WC/WZ/WCZ} 1101011CZ0DDDDDDDDD000101101 alias2 call #{\}A 1101101RAAAAAAAAAAAAAAAAAAAA alias2 calla D {WC/WZ/WCZ} 1101011CZ0DDDDDDDDD000101110 alias2 calla #{\}A 1101110RAAAAAAAAAAAAAAAAAAAA alias2 callb D {WC/WZ/WCZ} 1101011CZ0DDDDDDDDD000101111 alias2 callb #{\}A 1101111RAAAAAAAAAAAAAAAAAAAA alias2setnib D,{#}S,#N 100000NNNIDDDDDDDDDSSSSSSSSS alias3 setnib {#}S 100000000I000000000SSSSSSSSS alias3getnib D,{#}S,#N 100001NNNIDDDDDDDDDSSSSSSSSS alias4 getnib D 1000010000DDDDDDDDD000000000 alias4Cool,
As far as I remember someone modified the linker script to do real overlays to get around the memory issue on the P1 and GCC still supports this somehow.
Made for the time where 640KB where enough and external memory was everything over 640KB.
So external memory was - sort of - paged in thru overlay sections and linker support for that.
This allowed programs larger then 640KB. (Remember, the a20 gate?)
So if that is still doable with overlay-sections that would be a nice way to use your external memory driver or even SPI Flash or SD.
Just saying...
Mike
Yes that is right. I'm hoping to get something working there eventually and was the main reason to look at GCC again for the P2. I've got this cool i-cache scheme for HyperRAM and PSRAM all working now but nothing to make executable code really use it. While Dave Hein's p2gcc translation tools have been great to get me to this point they still keep the text and data sections together and this is a problem from keeping us running MicroPython entirely from external memory for example. Having bintools natively working for P2 lets me control text and data sections according to a proper linker script. Once that all works nicely, we can probably look at external memory models again.
That's great! With all due respect to @RossH and his Catalina for P1 and P2, it is great to have GCC in the workings. Looking forward to test it.
You mean this ?
https://forums.parallax.com/discussion/163970/overlay-code-with-gcc
yes, you found it, that was what I remembered,
cool. Maybe it still works with GCC
Enjoy!
Mike
O wow, I am kind of slow today, you not just found it, you are the guy who DID it.
Absolutely cool.
Don't you think using this on the P2 with Flash/SD/external RAM would be wonderful on a P2?
Mike
Absolutely, although with 512k of ram you can already make quite large programs (I don't say that 512k is enough for anyone... because.. you know...), it would allow to have high resolution screens in hub memory, maybe with double buffering, or process large amount of data, etc. without sacrificing program functionalities.
So there is hope for an updated GCC even for P1?
Is it worth dividing effort between GCC and LLVM for the P2 when LLVM is already so close to being ready?
No reason we shouldn't have both.
Well, that'd be 4 C compilers: GCC, Clang/LLVM, FlexC and Catalina
Haven't tried the LLVM yet (I have heard harrowing stories about the build process - waiting for release binaries...), but FlexC and Catalina both have unique features up their sleeves.
The solution here is clearly to invest into gene-editing to cross-breed all of them into one super-compiler that will then go and destroy local ecosystems.
5 or even more:
Yet another C compiler
https://forums.parallax.com/discussion/164494
I changed my sample code to be situated at 0x1000 in hub and with a few tweaks I was able to get it to run using hub-exec and address hub ram longs using the ## symbol, like
mov ptra, ##msg, where msg is a buffer in HUB RAM containing the string to be printed.I've also updated the P2 linker script to have some LUT ram at $800 for 512 longs and added the P2 register names as symbols if not already specified. I also defined the clkfreq and clkmode variables at 0x14 and 0x18.
Still more to fix/test, but it's cool to see this toolchain sort of working for P2. I need to look into this overlay thing so we can put different COGs and LUT overlay sources into COGRAM and LUTRAM. I think we will also need a way to reference the original address in HUBRAM of a symbol like the P2 SPIN2 compiler does with '@' even when the symbol was created in a section to be loaded into a lower COGRAM or LUTRAM address.
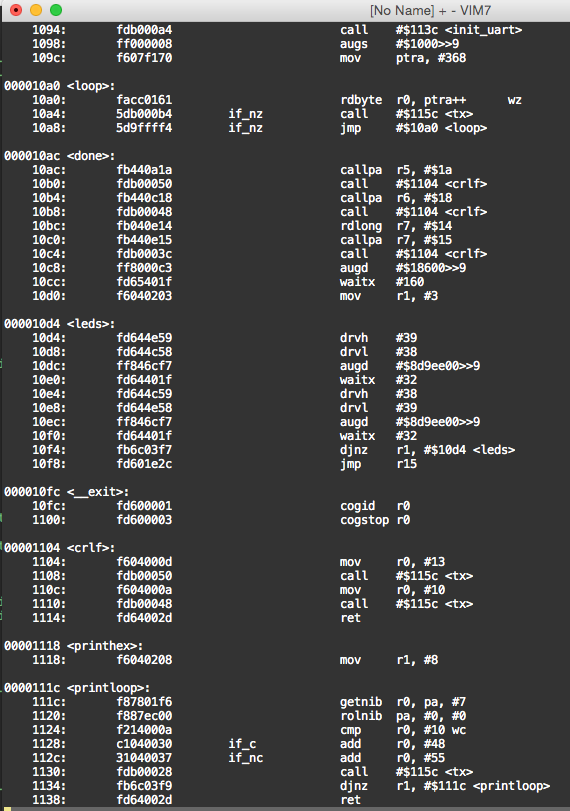
I also want to fix the items below where the symbol to address mapping in the disassembled output is showing an address that is off by 4. <init_uart+0x1c> should print as < tx > for example. It's not accounting for the offset. Similarly need to fix djnz target printing to match the real label.
000010dc <crlf>: 10dc: f604000d mov r0, #13 10e0: fdb00050 call #$1130 <init_uart+0x1c> 10e4: f604000a mov r0, #10 10e8: fdb00048 call #$1130 <init_uart+0x1c> 10ec: fd64002d ret 000010f0 <printhex>: 10f0: f6040208 mov r1, #8 000010f4 <printloop>: 10f4: f87801f6 getnib r0, pa, #7 10f8: f887ec00 rolnib pa, #$0, #0 10fc: f214000a cmp r0, #10 wc 1100: c1040030 if_c add r0, #48 1104: 31040037 if_nc add r0, #55 1108: fdb00028 call #$1130 <init_uart+0x1c> 110c: fb6c03f9 djnz r1, #$7e4 <_p2bitcycles+0x2db> 1110: fd64002d ret 00001114 <init_uart>: 1114: fd647c51 flth #$3e 1118: fc0cf83e wrpin #$7c, #$f8 <_start+0xb0> 111c: ff000002 augs #$400>>9 1120: f6040109 mov r0, #265 1124: f0640010 shl r0, #16 1128: f5440007 or r0, #7 112c: fc14003e wxpin r0, #$f8 <_start+0xb0> 1130: 0d647c59 _ret_ drvh #$3e 00001134 <tx>: 1134: fa97fe3e rqpin inb, #62 wc 1138: fd6c7c40 testp #$3e wz 113c: bc24003e if_nc_or_z wypin r0, #$f8 <_start+0xb0> 1140: 4d9ffff0 if_c_and_nz jmp #$1130 <init_uart+0x1c> 1144: fd7c002d ret wczHere's the latest linker script info after I've updated it...it allows 512kB of HUB RAM (up from 128kB before).
RLs-MacBook-Pro:test roger$ ../../ld/ld-new -m propeller2 --verbose GNU ld (propellergcc-alpha_v1_9_0_propellergcc-alpha_v1_9_1-6-gb280e7a77) 2.23.1 Supported emulations: propeller propeller2 propeller_cog propeller_xmm propeller_xmm_single propeller_xmm_split propeller_xmmc propeller2_xmm propeller2_xmmc propeller2_xmm_single propeller2_xmm_split opened script file /Users/roger/Documents/Code/build/binutils/ld//ldscripts/propeller2.x using external linker script: ================================================== /* Default linker script, for normal executables */ OUTPUT_FORMAT("elf32-propeller","elf32-propeller","elf32-propeller") OUTPUT_ARCH(propeller) MEMORY { hub : ORIGIN = 0, LENGTH = 512K cog : ORIGIN = 0, LENGTH = 1984 /* 496*4 */ /* coguser is just an alias for cog, but for overlays */ coguser : ORIGIN = 0, LENGTH = 1984 /* 496*4 */ /* lut is the LUT RAM area for P2 */ lut : ORIGIN = 0x800, LENGTH = 2048 /* kernel memory is where the .lmm or .xmm kernel goes */ kermem : ORIGIN = 0, LENGTH = 0x6C0 kerextmem : ORIGIN = 0x6C0, LENGTH = 0x100 /* bootpasm is an alias for kernel */ bootpasm : ORIGIN = 0, LENGTH = 0x6C0 ram : ORIGIN = 0x20000000, LENGTH = 256M rom : ORIGIN = 0x30000000, LENGTH = 256M /* some sections (like the .xmm kernel) are handled specially by the loader */ drivers : ORIGIN = 0xc0000000, LENGTH = 1M dummy : ORIGIN = 0xe0000000, LENGTH = 1M } SECTIONS { /* if we are not relocating (-r flag given) then discard the boot and bootpasm sections; otherwise keep them */ /* the initial spin boot code, if any */ .boot : { KEEP(*(.boot)) } >hub .bootpasm : { KEEP(*(.bootpasm)) } >bootpasm AT>hub /* the initial startup code (including constructors) */ .init : { KEEP(*(.init*)) } >hub AT>hub /* Internal text space or external memory. */ .text : { *(.text*) _etext = . ; } >hub AT>hub /* the final cleanup code (including destructors) */ .fini : { *(.fini*) } >hub AT>hub .hub : { *(.hubstart) *(.hubtext*) *(.hubdata*) *(.hub) *(.data) *(.data*) *(.rodata) /* We need to include .rodata here if gcc is used */ *(.rodata*) /* with -fdata-sections. */ *(.gnu.linkonce.d*) PROVIDE(__C_LOCK = .); LONG(0); } >hub AT>hub .ctors : { KEEP(*(.ctors*)) } >hub AT>hub .dtors : { KEEP(*(.dtors*)) } >hub AT>hub .data : { . = ALIGN(4); } >hub AT>hub /* the LMM kernel that is loaded into the cog */ .lmmkernel : { *(.lmmkernel) *(.kernel) } >kermem AT>hub .bss : { PROVIDE (__bss_start = .) ; *(.bss) *(.bss*) *(COMMON) PROVIDE (__bss_end = .) ; } >hub AT>hub .hub_heap : { . += 4; } >hub AT>hub ___hub_heap_start = ADDR(.hub_heap) ; .drivers : { *(.drivers) /* the linker will place .ecog sections after this section */ } AT>drivers __load_start_kernel = LOADADDR (.lmmkernel) ; ___CTOR_LIST__ = ADDR(.ctors) ; ___DTOR_LIST__ = ADDR(.dtors) ; .hash : { *(.hash) } .dynsym : { *(.dynsym) } .dynstr : { *(.dynstr) } .gnu.version : { *(.gnu.version) } .gnu.version_d : { *(.gnu.version_d) } .gnu.version_r : { *(.gnu.version_r) } .rel.init : { *(.rel.init) } .rela.init : { *(.rela.init) } .rel.text : { *(.rel.text) *(.rel.text.*) *(.rel.gnu.linkonce.t*) } .rela.text : { *(.rela.text) *(.rela.text.*) *(.rela.gnu.linkonce.t*) } .rel.fini : { *(.rel.fini) } .rela.fini : { *(.rela.fini) } .rel.rodata : { *(.rel.rodata) *(.rel.rodata.*) *(.rel.gnu.linkonce.r*) } .rela.rodata : { *(.rela.rodata) *(.rela.rodata.*) *(.rela.gnu.linkonce.r*) } .rel.data : { *(.rel.data) *(.rel.data.*) *(.rel.gnu.linkonce.d*) } .rela.data : { *(.rela.data) *(.rela.data.*) *(.rela.gnu.linkonce.d*) } .rel.ctors : { *(.rel.ctors) } .rela.ctors : { *(.rela.ctors) } .rel.dtors : { *(.rel.dtors) } .rela.dtors : { *(.rela.dtors) } .rel.got : { *(.rel.got) } .rela.got : { *(.rela.got) } .rel.bss : { *(.rel.bss) } .rela.bss : { *(.rela.bss) } .rel.plt : { *(.rel.plt) } .rela.plt : { *(.rela.plt) } /* Stabs debugging sections. */ .stab 0 : { *(.stab) } .stabstr 0 : { *(.stabstr) } .stab.excl 0 : { *(.stab.excl) } .stab.exclstr 0 : { *(.stab.exclstr) } .stab.index 0 : { *(.stab.index) } .stab.indexstr 0 : { *(.stab.indexstr) } .comment 0 : { *(.comment) } /* DWARF debug sections. Symbols in the DWARF debugging sections are relative to the beginning of the section so we begin them at 0. */ /* DWARF 1 */ .debug 0 : { *(.debug) } .line 0 : { *(.line) } /* GNU DWARF 1 extensions */ .debug_srcinfo 0 : { *(.debug_srcinfo .zdebug_srcinfo) } .debug_sfnames 0 : { *(.debug_sfnames .zdebug_sfnames) } /* DWARF 1.1 and DWARF 2 */ .debug_aranges 0 : { *(.debug_aranges .zdebug_aranges) } .debug_pubnames 0 : { *(.debug_pubnames .zdebug_pubnames) } /* DWARF 2 */ .debug_info 0 : { *(.debug_info .gnu.linkonce.wi.* .zdebug_info) } .debug_abbrev 0 : { *(.debug_abbrev .zdebug_abbrev) } .debug_line 0 : { *(.debug_line .zdebug_line) } .debug_frame 0 : { *(.debug_frame .zdebug_frame) } .debug_str 0 : { *(.debug_str .zdebug_str) } .debug_loc 0 : { *(.debug_loc .zdebug_loc) } .debug_macinfo 0 : { *(.debug_macinfo .zdebug_macinfo) } /* global variables */ PROVIDE(__clkfreq = 0x14) ; PROVIDE(__clkmode = 0x18) ; /* provide some register definitions - propeller 1 */ /* provide some case-sensitive aliases - propeller 1 */ /* provide some register definitions - propeller 2 */ PROVIDE(IJMP3 = 0x7C0) ; PROVIDE(IRET3 = 0x7C4) ; PROVIDE(IJMP2 = 0x7C8) ; PROVIDE(IRET2 = 0x7CC) ; PROVIDE(IJMP1 = 0x7D0) ; PROVIDE(IRET1 = 0x7D4) ; PROVIDE(PA = 0x7D8) ; PROVIDE(PB = 0x7DC) ; PROVIDE(PTRA = 0x7E0) ; PROVIDE(PTRB = 0x7E4) ; PROVIDE(DIRA = 0x7E8) ; PROVIDE(DIRB = 0x7EC) ; PROVIDE(OUTA = 0x7F0) ; PROVIDE(OUTB = 0x7F4) ; PROVIDE(INA = 0x7F8) ; PROVIDE(INB = 0x7FC) ; /* provide some case-sensitive aliases - propeller 2 */ PROVIDE(ijmp3 = IJMP3) ; PROVIDE(iret3 = IRET3) ; PROVIDE(ijmp2 = IJMP2) ; PROVIDE(iret2 = IRET2) ; PROVIDE(ijmp1 = IJMP1) ; PROVIDE(iret1 = IRET1) ; PROVIDE(pa = PA) ; PROVIDE(pb = PB) ; PROVIDE(ptra = PTRA) ; PROVIDE(ptrb = PTRB) ; PROVIDE(dira = DIRA) ; PROVIDE(dirb = DIRB) ; PROVIDE(outa = OUTA) ; PROVIDE(outb = OUTB) ; PROVIDE(ina = INA) ; PROVIDE(inb = INB) ; /* this symbol is used to tell the spin boot code where the spin stack can go */ PROVIDE(__hub_end = ADDR(.hub_heap) + 16) ; /* default initial stack pointer */ PROVIDE(__stack_end = 0x80000) ; } ==================================================This might be a stupid question, but how would this fit into SimpleIDE, for the P1 portion, and then maybe make it functional for the P2 side, of SimpleIDE, if available?
Ray
Ideally if it mostly follows the existing framework, it might be possible one day to have Simple IDE select either a P1 or a P2 build target and that could re-target a C application for P1 to run on a P2. But that is still a while away and there'd be a lot left to do to hit such a goal, including getting GCC to emit native P2 PASM instead of P1 PASM.
I'm just getting my head around linker scripts right now so we can control where compiled code goes. I'm reasonably happy with the assembler and disassembler parts - there may still be a few bugs left there but once found I think they'd be reasonably easy to fix. The @ symbol thing is still a slight concern as is branching between COG and HUB exec modes with relative jumps possibly needing to be disabled in that case.
I just found where these .cog overlay sections get setup with __load__start prefix symbols in HUB so they can be identified when spawning COGs. I think we can do the same with .lut sections for the P2, so COG code can then pull snippets into LUT RAM when needed. I may need a "lutuser" memory alias like we have for "coguser", something like this.
MEMORY { hub : ORIGIN = 0, LENGTH = 512K cog : ORIGIN = 0, LENGTH = 1984 /* 496*4 */ /* coguser is just an alias for cog, but for overlays */ coguser : ORIGIN = 0, LENGTH = 1984 /* 496*4 */ /* lut is the LUT RAM area for P2 */ lut : ORIGIN = 0x800, LENGTH = 2048 /* lutuser is just an alias for lut, but for overlays */ lutuser : ORIGIN = 0x800, LENGTH = 2048 /* kernel memory is where the .lmm or .xmm kernel goes */ kermem : ORIGIN = 0, LENGTH = 0x6C0 kerextmem : ORIGIN = 0x6C0, LENGTH = 0x100 /* bootpasm is an alias for kernel */ bootpasm : ORIGIN = 0, LENGTH = 0x6C0 ram : ORIGIN = 0x20000000, LENGTH = 256M rom : ORIGIN = 0x30000000, LENGTH = 256M /* some sections (like the .xmm kernel) are handled specially by the loader */ drivers : ORIGIN = 0xc0000000, LENGTH = 1M dummy : ORIGIN = 0xe0000000, LENGTH = 1M }Just got this lutuser thing working and the addresses seem good. It also creates the symbols that identify the start and end addresses of the ".lut" sections in HUB RAM like it does for the ".cog" sections.
0x0000000000001180 PROVIDE (__load_start_lut, LOADADDR (.lut)) 0x000000000000118c PROVIDE (__load_stop_lut, (LOADADDR (.lut) + SIZEOF (.lut))) 0x000000000000118c PROVIDE (__load_start_cog, LOADADDR (.cog)) 0x000000000000119c PROVIDE (__load_stop_cog, (LOADADDR (.cog) + SIZEOF (.cog)))Here was a snippet of code with a ".lut" section in it, linked to another ".cog" section as well.
... tx rqpin inb, #txpin wc 'transmitting? (C high == yes) Needed to initiate tx"); testp #txpin wz 'buffer free? (IN high == yes)"); if_nc_or_z wypin r0, #txpin 'write new byte to Y buffer"); if_c_and_nz jmp #tx ret wcz msg .asciz "Hello World!\r\n" .section .lut,"ax" da mov r0, #233 pb3 mov r0, #233 da2 jmp #\daIt disassembled to this which is good as the abosolute jmp seems to branch to (byte) address $800 which is $200 in longs so the addressing seems correct.
0000115c <tx>: 115c: fa97fe3e rqpin inb, #62 wc 1160: fd6c7c40 testp #62 wz 1164: bc24003e if_nc_or_z wypin r0, #$f8 <_start+0xb0> 1168: 4d9ffff0 if_c_and_nz jmp #$115c <tx> 116c: fd7c002d ret wcz 00001170 <msg>: 1170: 6c6c6548 if_c_ne_z wrlong #$32, ++ptra[8] 1174: 6f57206f if_c_ne_z augs #$ae40de00>>9 1178: 21646c72 if_nc_and_z addsx $36, #114 117c: 00000a0d _ret_ ror r5, r13 Disassembly of section .lut: 00000800 <da>: 800: f60400e9 mov r0, #233 00000804 <pb3>: 804: f60400e9 mov r0, #233 00000808 <da2>: 808: fd800800 jmp #\$800 <da> Disassembly of section .cog: 00000000 <newplace>: 0: f6000001 mov r0, r1 4: fd900022 jmp #$2a <r10+0x2> 8: fb6c01fd djnz r0, #$0 <newplace> c: fd64002d ret Disassembly of section .hub: 0000119c <__C_LOCK>: 119c: 00000000 nop Disassembly of section .hub_heap: 000011a0 <___CTOR_LIST__>: 11a0: 00000000 nopI've also fixed the addressing of symbols in branch targets (except for the callpa/callpb - EDIT: still to do that now done), making the disassembly of branching code much easier to read now and it works more like other CPUs. I may also want to show the real encoded relative offset value as well as the matched symbol address and name in the listing.
@rogloh Did you update "your" GCC not to need an ancient GCC and Texinfo at build time?
Nope. Still the same requirements AFAIK. I'm on a Mac which probably makes is even trickier to setup which I did some years ago using brew tools etc. Although I know I have also set it up before on another Ubuntu machine so hopefully it's still doable these days.
Great progress so far!
I'm obviously biased, but I'll echo the question: what benefit does having GCC give us if clang is pretty much working? (obviously there's still cleanup to do and not every instructions is implemented, but thats a very simple task that I'm just too lazy/don't have time to do). It would be much better if we combined our efforts to get one complete, fully featured set of tools, rather than work independently on two different ones.
If we will have two different tools, I think it should be a requirement that they conform to the same ABI--so code compiled with one system can be used in the other one. This mainly is necessary around calling conventions.
Tangential point: @Wuerfel_21 you can download prebuilt clang/LLVM binaries for macOS and linux from https://ci.zemon.name/project.html?projectId=P2llvm&tab=projectOverview (just click "log in as guest"). I haven't had time to write up a complete Getting Started guide and post it but I'll get to it soon. If you have issues, let me know in a different thread so we don't hijack this one.
Sorry, but I need it Bill-Gates-flavoured.
Arguably not. There isn't really one obvious way to use P2 resources for high-level code, different approaches have pros and cons.
Thanks @n_ermosh . I've not really done a huge amount of work as a lot of stuff was already in place and it mainly just needed updating with the newer P2 instructions and and handful of formats from the assembler and linker side. It's probably 75% done now I think. Still needs some work on this @ symbol in jumps, as well as AUGS with indexed PTR ops.
Please don't concern yourself too much about this work and make sure to keep doing what you are doing with LLVM. I really have no idea if my own efforts would even continue after this assembler and linker change, and if it gets really difficult after that I might just stop it there. I'm just going to plug away at it at my leisure potentially until I get tired of it. So there is no guarantee it would even result in anything. But I'm still hopeful of getting a useful working P2 assembler out of it and I'm reasonably confident that part will work out okay. If we happen to ultimately end up with multiple C compilers for the P2 like FlexC, GCC, LLVM, Catalina so be it, and I think it will be very useful as they all will have their own uses.
Well I'm sort of trying to get GCC working for several personal reasons...
1) to be able to experiment with my external memory execution schemes. Using p2gcc translation only with Dave Hein's linker got me to a point but it can't separate data and code segments, so I'm sort of stuck without a proper linker when doing my experiments.
2) to hopefully build Micropython natively to improve its performance. MP is currently setup to build on GCC only, and apparently is a real challenge or problem to get it to work with LLVM when people have requested it. Too much mucking about there, while GCC "just works".
3) to try to complete the work that was already started but just abandoned part way through after the P2-hot debacle. It looks like a lot of good work was put in some time back by others, and it seems a shame to just drop it all just because the instruction set changed and it's an older version. If this GCC compiler is fixed for the real P2 it might be possible to have SimpleIDE eventually target the P2, but I'm not sure if/when that would ever happen as mentioned above.
4) for my own education in how it works - until now GCC and its linker toolchain was mostly just a black box to me that I just used but I've started to now learn how it works under the covers and it's sort of interesting, albeit quite complicated.
5) it's the only toolchain I can actually currently even build in my setup here. I'm still running an older Mac OS X version for other reasons and I can at least build GCC but I can't build LLVM (I've already tried, it has major problems with older header files in my MAC OS X). I'd need a newer setup to build it and my only other Linux box is in disarray right now and randomly crashes minutes after boot. I know it's now worth me upgrading to new HW and I've got my eye on the new Studio Mac boxes (although that having a new M1 Max CPU is yet another unknown as to if/how it works with normal UNIX toolchains).
Ok. I've not actually reached that point yet, as the calling convention is basically going to be controlled by the C compiler and I've only been working on the assembler/dissassemble and linker stuff to date, but it could make sense to at least try to do this in case object files can be shared between toolchains. I do intend to keep either PA or PB free for external cache use though because that is the only instruction that can both branch and pass a parameter at the same time and it needs to be either
callpaorcallpb. It would make sense to use the same stack pointer argument too, either PTRA or PTRB, whatever you are already using. The link register could then be the other PA or PB register when making calls to leaf functions.For sharing object files, if this is even possible (does LLVM use the ELF32 linker file format and BFD etc or it's own one?), I guess the various relocation type numbers and functionality would also need to be agreed to but I'm not even sure the tools will be compatible at that level if LLVM has moved on a lot since the assembler and linker tool version I'm messsing about with, which is v2.23.1 of binutils for GAS/LD tools.
A suggestion for you and others, if you allow me: publish your sources online on Github or where you want, so other may not only help you now but also take over if needed.
As pointed out in other threads, the main problem with these user-driven projects is that when the interest from the original author fades away, or the priorities of life changes, the project will be abandoned, and without the sources it will not be possibile to take over and continue the development. So please, publish your work, even if not finished or "ugly" to see.
Yeah I do intend to push it to a github branch when things are suitably working, so even if I ultimately abandon the GCC effort later at least the source is captured somewhere. When that exactly will be in time will be my decision however.
@rogloh Those are great points. By no means would I want you to not work on it, my main concerns always surround new Propeller users being confused and overwhelmed. I know when I picked up the P2 when the rev B engineering samples first came out, I was overwhelmed and it took me days to realize I couldn't even compile C++ with existing tools")
P2LLVM uses ELF32 files, so if the calling and stack conventions are maintained across the implementations (there are probably a few other things that need to be consistent too), then sharing object files and linking them together should work. LLVM gave me free rein to define the ABI, and since P2 is so flexible is how it can be used, I pretty much had to make my own up. I wrote it up here: https://github.com/ne75/p2llvm/blob/master/docs/Propeller 2 ABI.md. The gist though is that I keep track of an upwards growing stack with PTRA, use CALLA for function calls, pass arguments via registers first and then the stack, and define pseudo registers of even/odd pairs to handle 64 bit numbers. I still use PA as a scratch variable for loading stack offsets, but I want to get rid of this dependance, since it can always be done with PTRA offsets. For simplicity, I don't keep a separate link register or frame pointer, everything is always handled through PTRA offsets. Maybe there's a performance improvement to be made there, but likely would have a minimal impact. Whenever you get to relocation and ELF generation, I can point you to where I've defined the relocation types.
Also, I've had basically no problems with working on an ARM Mac, pretty much all unix things still work exactly the same, and Rosetta makes it even more seamless, so don't let that hold you back from upgrading")
@Wuerfel_21 see here: http://www.rayslogic.com/Propeller2/Clang.htm. The p2 and c libraries might be a bit out of date in that build, so I would pull those out of any zip from the CI server I posted above.
Will probably check that out... at some point.
Re: calling conventions
No worries.
Thanks, I took a look at your LLVM ABI. I think the current P1 port of GCC uses a downward growing stack for compiled C code, but a new P2 version could probably differ from that and have it grow upwards. The only issue I can imagine with a upward stack pointer is that either the stack or the heap needs to be given a default size unless the heap can be made to grow downwards perhaps like a (typical) stack can. This type of default size setting doesn't have to occur if the stack grows down and the heap grows up. Although in a multi-cog setup there are potentially multiple stacks anyway so it's probably good practice to need to provide a stack a particular maximum size at build time so you can plan for it all up front. The main benefit with upward stack is that P2 aliases like PUSHA and POPA are going to be a lot more understandable than seeing
wrlong data,--PTRArdlong data,PTRA++all over the place in the disassembled listings, and it also might give more hope to having C and SPIN2 functions call each other in the same system, sharing the same stack for return values. (Yes I know - there is a lot more to it for that to even have any chance of working.)My intended use of either PA or PB for external memory is also just as a temporary variable to pass the intended branch address to a special handler routine in COG/LUTRAM so it could probably even interoperate with your own current use of PA because these far function calls or far branches are unlikely to clash with the current use of this register.
I still don't really yet know what the best use of PTRB is. Using it for a separate frame pointer or argument pointer as I'd originally considered ages ago isn't all that useful, especially given that the range of indexes for PTRA can be extended with a single AUGS anyway. Maybe just keep it available as a special register with indexing capabilities the compiler could use for accessing struct members, and/or for the this pointer use with C++, or for single register variable pointers that can auto-increment etc. There should be something compelling found to make really good use of it if it is going to be dedicated to a single purpose and maybe we are not yet there to make that decision.
PB could still be a link register if we find we like one. Although I do quite like @Wuerfel_21's idea for using the internal HW stack as the leaf function stack because it is quite fast to access and it only ever burns one level of extra depth so it's not too onerous. Might confuse the debug tools a little however if they expect return addresses to be present on the stack. How would they know how to display that return value unless they are aware it is a leaf function that was called?
In my own external memory scheme a fair chunk of the spare LUTRAM is used for making external requests and managing the cache. Despite that I think there is still a reasonable amount of space left for FCACHE use in either COG or LUTRAM depending on where the caching code is situated. But the total runtime library code space wouldn't be able to be very large and would be limited to small regularly used functions. Probably there are around 256 longs available for these purposes or thereabouts.
Even though it might be a good idea for compatibility/reuse of object files I'm still a little apprehensive of whether or not the ABI can be made identical for both GCC & LLVM if the register allocation schemes differs between compilers. It looks like your callee saved registers are not exactly fixed going by the description provided. Also all the relocations would have to be indexed the same and do the same thing. That's potentially doable if they are fully defined and don't collide but the P1 GCC code port has already defined some of them so if yours are quite different and do collide then there might be a problem there. I don't want to break the existing P1 stuff in any way.
Excellent - thanks for letting me know, that gives me a little more confidence in trying to move forward on the change sooner.
On a P2 system, yes. In other systems, stacks go the other way.
It could be, given accessing the object's member data can be made using offsets from PTRB.
Yes useful idea. POP and PUSH are much faster than POPA and PUSHA, although a dedicated LR register such as PB is faster still, especially if you just use
CALLD PB, ##functionandJMP PBto return. Otherwise it's 4 extra clock cycles per leaf function call.I think for the call-used registers, yes having more registers could be useful, up to a point. But for maximum benefit they really have to be contiguous so you don't need to break apart the burst writes to save them off when another function gets called and read them back when it returns. No point in using R3 R5 R7 and having to break apart the burst transfer, it needs to use R3, R4, R5 etc. It would even be worth saving those register gaps, R4 and R6, instead of breaking the burst apart, given it is only one clock per saved register.
Yes a separate register file for leafs is handy, but if the function already knows it's a leaf at compile time it wouldn't need to be a caller so wouldn't need to save the used registers anyway. The compiler has no need to save these registers in this situation.
One thing that I keep striking, in Spin as well as C, is having to copy the variables, containing pin numbers, from their preset static storage into local registers for I/O handling routines to have quick access to the assigned pin numbers. It would be cool to have some sort of generic solution to somehow auto-map-and-generate for that sort of case, where there is a sequential data block that the function copies into registers as its first step.
Kind of like a static-register qualifier ... but visible across the source file/structure/object.
Dunno about setting of such though. I guess, to make it universal, there needs to be a similar block write back to hubRAM as well. The trick then will be to optimise that away if there is no alterations of the static content.