

TMS9918 Renderer Example
 macca
Posts: 1,064
macca
Posts: 1,064
Hello,
I made a porting of the TMS9918 emulation rederer I'm using in other projects for the P2.
Since I'm still learning, the code uses both a composite video driver on pin 53 and the debug bitmap output so it doesn't require special hardware or setup, just Propeller Tool.
Some images:
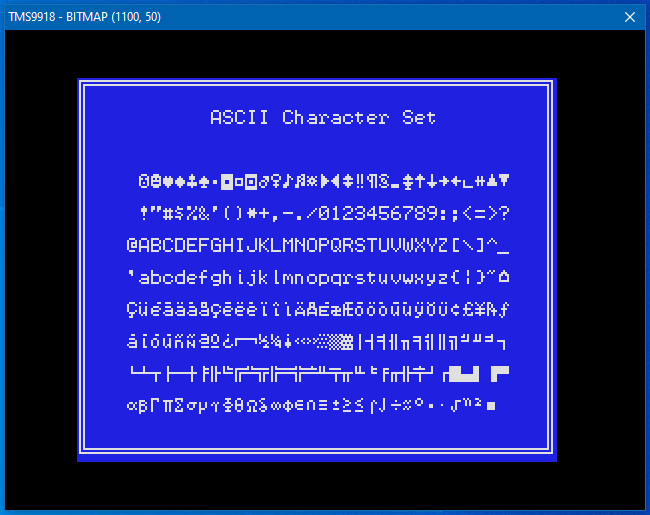
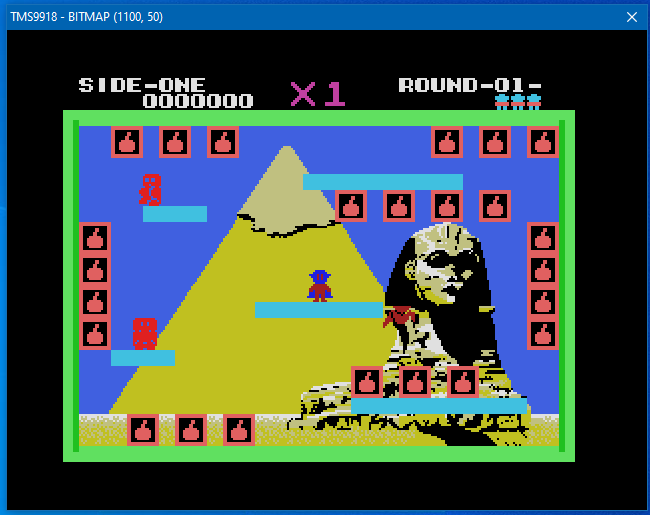
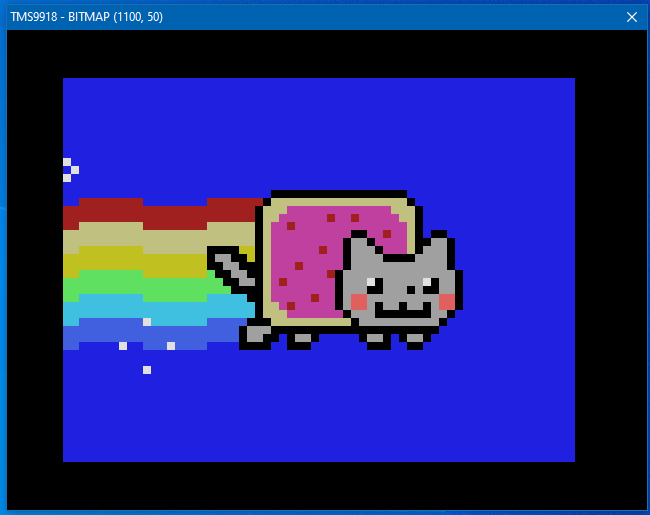
The code is a more or less a straight porting from the P1 code with very little P2 enhancements, it renders the TMS9918 vram in a 320x240 256x192 bytes bitmap that is sent to the debug output (the actual resolution is 256x192, I have added the border to simulate the real thing, but the border color is not yet rendererd). I'm sure there are a lot of things that can be done better, but for something written in a day, I'm happy with it.
The renderer itself is fairly complete, supports all graphics modes and sprites.It still doesn't support the sprite collision flag, I hope to finally find a way to do it with P2.
There is a small glitch that I wasn't able to fix: the bitmap pointer seems 4 bytes off, if you look at the debug output you'll see that there is an extra long sent at the end. I can't understand what I'm doing wrong, the bitmap demos from the propeller tools package all works well, i tried various settings but I wasn't able to fix that. I'll be grateful if someone will look at it and tell me what's wrong.
In addition, I had to add a 1ms delay in the bitmap update loop because otherwise some data get lost in the transfer, my laptop should be fairly fast, nevertheless it looses data without the delay.
Update: Added simple animation demo, with composite output.
Update: Unified the archive with all demo projects. tms9918_demo display the Nyan Cat animation, tms9918_sprite display a simple sprite animation, tms9918_debug display a static vram/vregs configuration to both composite and the debut bitmap output.
Update: added experimental single-cog version.
Update: implemented sprite collision check and vga driver
Update: fixed sprite draw
Update: added vsync, 5th sprite and blank.
Enjoy!

Comments
Looking good!
Don't have my P2 hooked up to try yet, but here's some optimization I see:
test a, #%10000000 wz if_nz wrbyte c1, ptra++ if_z wrbyte c0, ptra++ test a, #%01000000 wz if_nz wrbyte c1, ptra++ if_z wrbyte c0, ptra++ test a, #%00100000 wz if_nz wrbyte c1, ptra++ if_z wrbyte c0, ptra++ test a, #%00010000 wz if_nz wrbyte c1, ptra++ if_z wrbyte c0, ptra++ test a, #%00001000 wz if_nz wrbyte c1, ptra++ if_z wrbyte c0, ptra++ test a, #%00000100 wz if_nz wrbyte c1, ptra++ if_z wrbyte c0, ptra++ test a, #%00000010 wz if_nz wrbyte c1, ptra++ if_z wrbyte c0, ptra++ test a, #%00000001 wz if_nz wrbyte c1, ptra++ if_z wrbyte c0, ptra++I'd rewrite this as such:
shl a,#24 wrfast ptra rep @.pxlp,#8 rol a,#1 wc if_c wfbyte c1 if_nc wfbyte c0 .pxlp add ptra,#8The obvious upgrade path would of course be V9938/V9958 emulation. Handling the hires modes could be tricky. In my JET compatibility thing, I have rogloh's video driver running 544x240 (512x224 with borders!) and handle doubling up 256 wide modes by writing the flags of a bunch of regions linked in a circle, corresponding to the line buffers. Then the video driver just takes care of it. If you ask I can get together a functioning example
Now, if only we had an HDMI version of this we could move into the 21st century.
Mike
There is a problem with how each pixel is written for all VDP modes, both in the original and this optimised version. If c1/c0 = 0000 then pixel is transparent and backdrop/border colour should show through.
Pros and cons of using 4 bits/pixel vs. 8 bits/pixel need to be considered. If the latter, then WMLONG could be used to write sprites and patterns. Alternative way to render is to compose each line in cog reg RAM, then write to hub RAM when line is finished.
Move the WRFAST to an earlier line, outside the loop.
There's a bit of code above what I clipped that handles that.
Yep, can do that for additional speedup.
I timed the Bombjack frame rendering (the only with some sprites), it uses 1_151_594 clocks, at 160MHz means about 138 fps, at this stage I'm not much concerned about speed optimizations, aside from the obvious exercise to learn the P2 features. I would like to see if the sprites can be optimized.
It is right that block reads works only with rdlong ? I tried setq / rdbyte to block-read the registers but doesn't work.
Making a rendering for the V9938 is on my whish list since ages, maybe this time I can do something for it.
My initial implementation used 4 bits per pixels. There is no problem with the background rendering, however at the sprites redering it still needs to flip bits to adjust for odd horizontal positions, and I had enough headaches with P1 to repeat the story for P2, so I changed to 8bpp, there is enough memory and speed for it. Unless of course there aren't facilities for that.
Yes, block access only works with RDLONG, WRLONG and WMLONG.
That sprite loop doesn't look very optimized as-is. All the edge case handling inside the loop...
I think there's an even faster way of doing the 1bpp decoding. It assembles into cog ram and then uses block writes, so it'd also work for sprites with WMLONG.
setbyte c0,c1,#1 ' we need a long with c0 in byte 0 and c1 in byte 1 rev a shr a,#24 mergew a ' turn %abcdefgh into %0a0b0c0d0e0f0g0h mov tilebuf+0,c0 movbyts tilebuf+0,a shr a,#8 mov tilebuf+1,c0 movbyts tilebuf+1,a setq #1 wrlong tilebuf,ptra++Whoa... that's brilliant! Tried and that alone saved about 280k cycles. Thanks!
I don't know if it can be used with sprites, they not only can be 8 or 16 pixels wide but also "magnified" so each pixel needs to be doubled.
About the bitmap glitch I mentioned in the first post, here is the result, highlighted by drawing the visible bitmap at the beginning of the frame:
Note that the bitmap "wraps" on the right, and the extra long in the debug output.
If you want to reproduce, comment the add ptrb, ... at the beginning of the code, it will center the tms frame into the bitmap.
I have pixel doubling in JET engine. The P2 port decodes the sprite into a buffer first, like normal, and then just doubles it up into another buffer like this (
pixel_itershould be 4 to double 16 pixels...)setd a0,tilebufstart setr a0,#fatbuffer rep @.xpand,pixel_iter alti a0,#%111_101_000 movbyts 0-0,#%%1100 alti a0,#%111_111_000 movbyts 0-0,#%%3322 .xpandIf you want to see it in context, a relatively recent JETp2compat_rendering.spin2 can be found attached here:
https://forums.parallax.com/discussion/comment/1519835/#Comment_1519835
8bpp seems to be the way to go. Lots of optimizations still possible. Moving one instruction should save cycles in Graphics 2 mode.
Replace this
graphics_mode '... rdbyte a, ptrd ' colors mov c0, a and c0, #$0F wz if_z setnib c0, regs+7, #0 mov c1, a shr c1, #4 wz if_z setnib c1, regs+7, #0 shl ptrc, #3 ' 8 bytes per tile add ptrc, regs+4 rdbyte a, ptrc ' pixels, 1 bit per pixel, from msbwith this
graphics_mode '... rdbyte a, ptrd ' colors mov c0, a and c0, #$0F wz if_z setnib c0, regs+7, #0 mov c1, a shr c1, #4 wz shl ptrc, #3 ' 8 bytes per tile add ptrc, regs+4 rdbyte a, ptrc ' pixels, 1 bit per pixel, from msb if_z setnib c1, regs+7, #0 '** moved down **I'm a tad vague on the circumstances. You're saying it is working and not working in the same paragraph. I'm guessing there is two scenarios but it's not clear what they are.
I have added a screenshot in comment #10 showing the problem, the code is the same that produced the images on the first post only the rendered bitmap is at the top-left corner to show that there is an offset somewhere that I can't explain.
How come you have both with a visual problem and without a visual problem?
EDIT: Oh, you're editing the offset to compensate, right? And the edit amount is unexplained?
To my knowledge, the offset is always there, but with the black border you can't see it.
Hmm, yeah, not a useful answer. I reworded the question a couple times since. I'm trying to work out how you are getting two differing screen shots.
I see, not a good idea editing a post...
Anyway, yes, if I start to render the bitmap at the beginning of the buffer (top-left corner) it shows that unaxplainable offset. It should be alwyas there because if you run the code you can see on the debug output window an extra data $108A that should not be there. Seems like when with P1 the hub address is wrong because there is the object offset (sorry, can't remeber exactly when using @ or @@ generates the wrong address with P1).
Prop2 isn't it? Are some of those images from the Prop1? I wouldn't have a clue about Spin use of @ and @@. My knowledge is mostly Pasm2 and the Prop2 hardware.
PS: You'll notice I edit and reedit and reedit some more nearly all my 10,000 posts. Best not to try answering too quickly.
Ok, I'm an idiot:
bmpa := @bitmap repeat 60 repeat 320 debug(`TMS9918 `UHEX_(long[bmpa += 4])) ^^^^^ waitms(1)That increases the pointer before getting the data from it!
I swear I had moved it on its own line!
bmpa := @bitmap repeat 60 repeat 320 debug(`TMS9918 `UHEX_(long[bmpa])) bmpa += 4 waitms(1)That works!
Sorry for the noise.
I'll work on the optimizations a bit and post an updated version later.
Glad it solved.")
More optimizations/suggestions:
Use ptra & ptrb as hub RAM line buffer & Name Table ptrs.
Use 320-pixel line buffer (80 longs) in hub RAM, with 32/40-pixel borders either end of 256/240-pixel display for graphics/text. This simplifies video output as can use RDFAST -> LUT -> Pins/DACs mode for borders and display. It also means more time per line for rendering before needing to feed the streamer.
Read four bytes together from Name Table using RDLONG, saving 24/30 random reads (see also new point 9).
SHL & SHR opcodes differ by only one bit and a single shl/shr ptrd,#3 instruction could be patched once outside of main loop.
Text mode could use Wuerfel_21's bit-to-byte code with sub ptra,#2 added after wrlong tilebuf,ptra++. (Text mode is much simpler with 8bpp compared to 4bpp.)
Read entire Sprite Attribute Table (32 longs) into LUT RAM using fast block read, then use RDLUT with ptrb++ to test each sprite in turn. Do this after rendering pattern and colour planes.
Use WMLONG for sprite rendering. Magnification should be simple, sprite coincidence checking less so.
Graphics 2 mode could be speeded up by mapping VRAM differently. If address rotated so that high VRAM bit = low hub RAM bit then pattern row byte and corresponding colour row byte could be read together using RDWORD. This saves 32 random reads but will increase reads elsewhere (see points 3, 6 & 9) although by not as much, unless a split-mapping could be used.
Read all 32/40 Name Table bytes for each line into part of the Sprite Attribute Table buffer in LUT RAM using fast block read, then use RDLUT with ptrb++ to read each group of four bytes in turn.
Use MUXNIBS to handle transparent colours 1 and 0.
First post updated with the new rendering example. I applied some of the suggested optimizations, not everything because I need to understand few other things.
To compensate, I have added the composite video output!
I took the PAL / NTSC driver, simplified a bit and tweaked to display the rendered bitmap. This is the first version of the driver, without the later tweaks and adjustments. The output doesn't seems very good to me, at least compared to the mario bitmap (same resolution), hope to not have made other stupid mistakes. I need to get my MSX computer and do a visual comparison...
Enjoy!
New points 10 here:
http://forums.parallax.com/discussion/comment/1521376/#Comment_1521376
Re point 10 above, replace this
graphics_mode '... mov cbuf+0, a and cbuf+0, #$0F wz if_z setnib cbuf+0, regs+7, #0 mov cbuf+1, a shr cbuf+1, #4 wz if_z setnib cbuf+1, regs+7, #0 setbyte cbuf+0, cbuf+1, #1 mov cbuf+1, cbuf+0with this
mov cbuf,back2 muxnibs cbuf,a rolnib cbuf,cbuf,#0 setnib cbuf,#0,#1 mov cbuf+1,cbuf '... 'do the following once only when VDP reg 7 is written 'back2 = %bbbb_bbbb where bbbb = backdrop = reg7[3:0] getnib back2,regs+7,#0 rolnib back2,back2,#0 back2 res 1Time saving is 6*32 = 192 cycles per line in graphics mode.
Added the Nyan Cat animation demo to first post. Composite-only because it is the only video output I can test.
The frame syncronization uses cogatn instructions from the video driver to signal the start of vertical blanking to the TMS9918 renderer, then the renderer signals the animation loop cog when the rendering is complete, still via cogatn, so it can draw the next frame. Works pretty well, in my opinion. Of course a real emulation + video output needs a more sophisticated synchronization mechanism, but looks good for a demo.
I'm not ignoring the optimizations, will look at them.
Some more updates: I have unified the code archive on the first post with all demo projects. tms9918_demo display the Nyan Cat animation, tms9918_sprite display a simple sprite animation, tms9918_debug display a static vram/vregs configuration to both composite and the debug bitmap output.
About the optimizations, I have done some things: moved the registers update at the start of frame (not sure how the real chip works on that matter), used rdfast to read from the nametable and sprite control table, wrapped loops with rep to save the decrement and jump, used movbyts where appropriate, and some other adjustments. With these optimizations the cycle count is now 648_673 cycles for the Bombjack frame, about 240 fps at 160MHz. I think it is more than enough for now.
The video driver and rendering cogs are better synchronized now: the video driver wakes the renderer two lines before starting to display the active video (that is the 256x192 portion, not the whole screen), then at the vertical sync it signals the main cog (fixed as cog0 for now) so it can update the registers and vram for the next frame. This should give both a good synchronization and time to render the frame. The border is handled directly by the video driver by reading register 7 at the beginning of each line, so the rendered bitmap is now 256x192.
Using rdfast to read name table bytes and sprite longs.
Now it renders the active 256x192 bitmap, borders are handled by the video driver.
I'm not sure if there are more dedicated instructions but this will require a loop to iterate through the bytes, I'm using rdfast / rfbyte now, seems much more efficent, if I have understood how the fifo works.
Done.
Not sure to understand. Text mode fonts are 6 pixels wide, I'm using one wrlong followed by a wrword (thanks for removing the long-alignment requirement!), with the ptr increment seems more efficent.
Using rdfast / rflong now, again seems more efficent.
About the sprites, seems that there is one thing missing: sprites can be placed outside the visible screen, not only top and bottom but also left and right. Sprite pixels can't be simply written, some clipping must be done, either by masking the outside bits or checking if the x position is outside the screen (using that now). Not sure what may be more efficent.
I am writing a VDP emulator that use only one cog for line renderer and VGA 640x480 video driver. So far it can do text and graphics 1 & 2 modes. Sprites still to do. Pixel clock is half normal VGA frequency and each line is repeated. There is no need for more than one cog to emulate the TI VDP, which is a rather trivial task for the P2.
Re points 3 and 6, FIFO is used by streamer to output video therefore RDFAST/RFLONG are not available to renderer in single-cog implementation. I recommend that you use fast block moves, as also suggested by Wuerfel_21, see point 5.
WRLONG + WRLONG/WRWORD is considerably slower than SETQ + WRLONG. The WRLONG/WRWORD takes 8 or 9 cycles, compared to 1 for second long with SETQ. (There are 2 extra cycles for long crossings in text mode every other loop.)
Well, I was thinking about it but wasn't sure how to do it, you gave me the boost to do more researches and found a thread with an NTSC driver with interrupts, a bit of testing later and here it is, an experimental single-cog version attached to the first post.
Not only rdfast but also rep seems incompatible with the interrupts so I had to revert to the "old" counter loops. The only other optimization I did was to read all sprite control table into memory. Definitely needs to do more.
Out of curiosity, I have added pin0 toggle to see for how much time the rendering code is "active", this image from the scope shows it (high == active rendering):
About 5ms. to render the Bombjack screen with sprites.
@macca, there are several optimizations that you have not done yet.
I've thought some more about sprite collision. I think best way is to test whether two sprites overlap and if so use TEST to compare their bit patterns. Skip test if collision already detected or fewer than two active sprites. Worst-case is six tests: sprites A and B/C/D; sprites B and C/D; sprites C and D.
Yes, optimizations are still a bit problematic for me. I have synchronized the rendering with the video, now the border is perfectly in sync, and done some timings. With a "worst case scenario" where all sprites are active and configured as 16x16 with magnification (so 32x32) with all pixels active and displayed so they overlap, it takes about 7_124 cycles for each line, a lot but well below the 10_240 cycles needed for the video. I think it can work with VGA, with duplicated lines it should take 10_168 cycles (I'm experimenting a bit with it).
I tought of using 10 longs as a bit representation of the displayed sprites (256 + 32 at each side for off-screen sprites), with some shift and alignment it should allow to detect collisions, the problem is still the magnification! Don't we have an instruction to duplicate bits (0101 -> 00110011), don't we ?