

"Out on a Limb" - Some P2 (radical?) thoughts...
 Cluso99
Posts: 18,071
Cluso99
Posts: 18,071
in Propeller 2
For a little while I have wondered what maximum speed we are going to be able to run the P2 at.
Originally I had hopes for 200MHz although nowadays I seem to think 160MHz may be it.
Hence I asked Chip what the OnSemi RAM can run at - the answer ~350MHz.
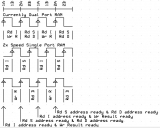
My reasoning behind this question was, "Do we need Dual Port Cog RAM ?".
http://forums.parallax.com/utility/thumbnail/115347/FileUpload/ce/72e184cc9febdacf81e0558efeb520.jpg
Using my understanding from the P1V, makes me believe that the I & R information is ready at the beginning of one cog clock, and the S & D information is ready at the beginning of the next clock.
That means that if the Cog RAM was clocked at 2x Cog clock, then...
"I" could be read on the first half of the I&R clock and "R" written on the second half of the I&R clock
"S" could be read on the first half of the S&D clock and "D" read on the second half of the S&D clock.
This would mean that standard single port RAM cells could be used for the COG RAM.
This saves reasonable die space, and perhaps complexity.
What do we get for this ???
Now LUT RAM is identical to COG RAM. So what?
Well, now with an added instruction "LUTDS D/#,S/#" where each # is 11-bits (possibly replacing the AUGDS instruction), that could precede any normal mov/add/etc instruction, all normal instructions could not only address the whole LUT, but we have expanded the registers to the full COG/LUT space (admittedly using an extra instruction).
Now we no longer require the RDLUT/WRLUT instruction.
Originally I had hopes for 200MHz although nowadays I seem to think 160MHz may be it.
Hence I asked Chip what the OnSemi RAM can run at - the answer ~350MHz.
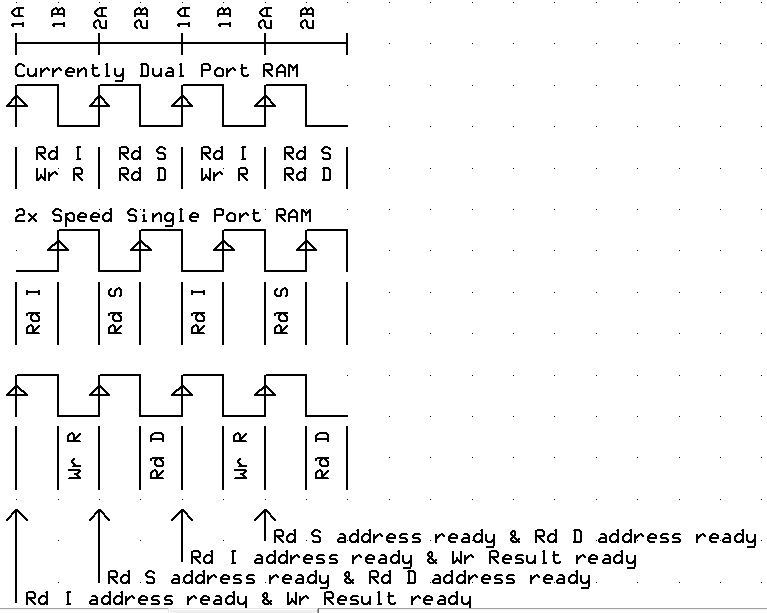
My reasoning behind this question was, "Do we need Dual Port Cog RAM ?".
http://forums.parallax.com/utility/thumbnail/115347/FileUpload/ce/72e184cc9febdacf81e0558efeb520.jpg
{kind=link}
Using my understanding from the P1V, makes me believe that the I & R information is ready at the beginning of one cog clock, and the S & D information is ready at the beginning of the next clock.
That means that if the Cog RAM was clocked at 2x Cog clock, then...
"I" could be read on the first half of the I&R clock and "R" written on the second half of the I&R clock
"S" could be read on the first half of the S&D clock and "D" read on the second half of the S&D clock.
This would mean that standard single port RAM cells could be used for the COG RAM.
This saves reasonable die space, and perhaps complexity.
What do we get for this ???
Now LUT RAM is identical to COG RAM. So what?
Well, now with an added instruction "LUTDS D/#,S/#" where each # is 11-bits (possibly replacing the AUGDS instruction), that could precede any normal mov/add/etc instruction, all normal instructions could not only address the whole LUT, but we have expanded the registers to the full COG/LUT space (admittedly using an extra instruction).
Now we no longer require the RDLUT/WRLUT instruction.
767 x 613 - 90K
Comments
That is because RAM never exists alone, it needs address decode, multiplexers and routing paths, and what it feeds, needs a setup time.
I had a similar thought a while ago about counters, which are simpler than RAM.
The question was could counters run at 2x the CPU speed, to give better timing resolutions ?
IIRC outcome was Counters are faster than opcode decode, but opcode decode is already quite well optimised ( P2 is a mature design, in that area) and that means a 32 bit counter is not greater than 2x the opcode decode path. ie you could not get 'x2 for free', even on a Counter.
Interesting idea.
Mike
It's probably theoretically possible to have a 320MHz clock for the register-set while using 160MHz for the rest of the core. It won't happen though. The synthesis system just won't have the features to handle it. Chip already mentioned how the dual-cycle execute phase couldn't be timing simulated, or something to that effect, so he has added extra pipeline flops to satisfy that limitation.
That's probably the biggest sacrifice of using so many levels of automated tools. You are bound by the limits of them all combined. It's a logical AND operation.
Note: That 300MHz limit is just a "heartbeat oscillator" limit.... it is based on the parasitic capacitance of the smallest transistor oscillator capable of sustaining adequate drive strength and the S/D leakage (resistance) to the substrate as well as any parasitic inductance forming a simple parasitic RLC filter by the result of component layout. To achieve those frequencies at NSC the quad-phased "heartbeat oscillator(s)" required strict layout requirements positioned in isolated NWELLs as far away from the substrate and other active circuitry as possible.
Another concern I have that is directly related to the frequency bandwidth is clock propagation through proper fanout and delay insertion techniques. This can have a significant impact on the number of cells calculated for the overall size design. This fanout also apples to sensitive signal multiple lines such as the COG to COG, COG to MEMORY, or COG to I/O communication.
More cells = more propagation delay = better fanout timing = slower clock speeds
Less cells = less propagation delay = poor fanout timing = faster clock speeds
There is a fine balance between the two and the automated P&R tool (Avanti! software - Now Synopsys is the leading industry software to accomplish this) this software tool will programmatically accept whatever latency delays you provide on any selected signal, and it will attempt to meet the timing requirements you provide after several thousand/million iterations. I became very familiar with this tool at NSC and know it's limitations quite well. It's the proper tool to use in my opinion.
But, I don't think the FPGA will test this out anyway. I think it's an OnSemi/Treehouse question about the possibility.
If it worked, there would be many positive benefits that I thought it was worth the question.