@ersmith said:
You might have better luck with riscvp2, which is full GCC and already has support for putting code into flash memory. Although given the specs of LVGL it may not need external memory at all?
Ugh. Want to use native P2 code not RISCV instructions.
How much are you writing in assembly though? If you're worried about performance, riscvp2 does eventually compile the code to native P2, just at runtime rather than ahead of time. It's coremark score is around 52 iterations/sec at 180 MHz (when run from HUB or Flash; results are the same either way) vs around 37 iterations/sec for flexspin and 17 for an older Catalina.
Yeah I'll probably not try to use assembly, more a mix of C and SPIN2. But it's mainly the integration with other SPIN2 stuff like my memory driver and other stuff which flexspin handles so well and compels me to use that. Also if I do run into problems, I can debug PASM2 instructions easily as I'm very familiar with those, while I'm a complete newbie with respect to RISCV and don't really want to have to learn that just to fix code issues I may encounter on a P2.
I do actually have an application in mind for this if I can get this working, hence my appetite for fixing these issues. My car has a 9 inch LCD screen with a spare video input for reversing cameras which I don't use and it'd be cool to feed it a P2's video output with a nice GUI showing some automotive stuff like TPMS sensor data and any other CAN accessible data I might like to see. A P2 board with external RAM such as the Edge might be useful to control this all. It'd mostly just need my PSRAM driver for the external memory code and some other IO pins for accessing HW and a composite video output, so it's quite doable. A lot of HUB RAM would be freed up for a screen buffer if I can place this LVGL code into external RAM and LVGL is seemingly very capable for displaying fancy dials and other presentable GUI widgets in real time. I could use something else such as a Pico or ESP device but obviously prefer to use a P2. Now I'm still not sure about performance but for a high speed P2 I'm still optimistic (although maybe a little less so since I saw all that heap activity now in the disassembled code for some functions ).
I was remiss earlier in not mentioning Catalina, which already has external memory support too. Although I'd definitely be very happy to have you continue to work on an external memory solution for flexspin, which would be awesome but if you need something working sooner then Catalina may do the job.
True. I may look at that at some point, but again it's the features of flexspin like mixing SPIN2 and C objects which are compelling in this case.
The reason I still have hope is that with some changes I made that make flexspin happier (remove inline and const and rename some variables) I've been able to get the error list down to only the same type of incompatible assignment type error and if you do end up finding a general fix for that issue it might potentially resolve all of them (with any luck).
I'll continue looking into that. On that note, do you think you could re-post your current code? The all.zip that you posted up-thread was missing the actual lvgl directory .
I'll post the files I modified with a github link to the 9.5 tree of LVGL which IIRC forms that sub-directory. Probably much smaller that way otherwise it's ~700MB. Will edit this post here with the ZIP once I've sorted it out for you.
EDIT: Just added projchanges.zip and instructions within its included readme.txt file for getting the other files.
I do have one other strange error left though which is some internal error now reported in the C startup code added automatically at the end - not part of my project list but something flexspin is adding. Strangely it is reported on line 24 and the file only goes up to line 23. ./Users/roger/Applications/spin2cpp/include/libsys/c_startup.c:24: error: Internal error, unknown type 114 passed to IsArrayType
When the error comes at the end of the file like that it usually means it's some internal issue not really associated with any source code (and the source file name is probably bogus too). The particular error is complaining about trying to find the type, and 114 is an AST_USING, so it's probably upset about a struct __using statement somewhere. It might be related somehow to the other struct errors, hard to say.
Ok. That was the last one, so I'll wait until the other stuff is hopefully working before trying to address that. It only showed up recently.
So with some tweaks today I was able to get LVGL building on a P2 with n_ermosh's P2 LLVM compiler. For our reference this dummy build (basic LVGL code but no real application) consumes about 322kB of HUB for its code segment, and about 14kB of data, plus it would still need some space left for a (partial) frame buffer and a heap+stack. It would be pushing it to fit all this into HUB unless the frame buffer is of lower resolution (like 320x200). One possibility to improve this would be to try to keep the frame buffer(s) in external memory and just transfer portions to/from PSRAM as the screen is rendered into the partial frame buffer in HUBRAM. I read somewhere that LVGL needs at least a 10% sized local frame buffer to still work ok. So that might be a possibility for me if a flexspin build that is running LVGL from external RAM can't be achieved. It would allow higher bit depths too.
It'll be interesting to compare how much HUBRAM the flexspin code will be for this same build if we can fix the compile errors so it completes. I did compile with -Os option on LLVM so it's meant to be optimized for smaller size, and uncalled functions are meant to be removed. The full list of LVGL files in this particular build are attached so we can compare later. I also cut the internally allocated free memory area down to 32kB from 64kB, otherwise the BSS use would be an extra 32kB more and the default sized heap the collides with the default stack. Need to work out how to shrink those a bit, the default stack size is 48kB and probably way too big.
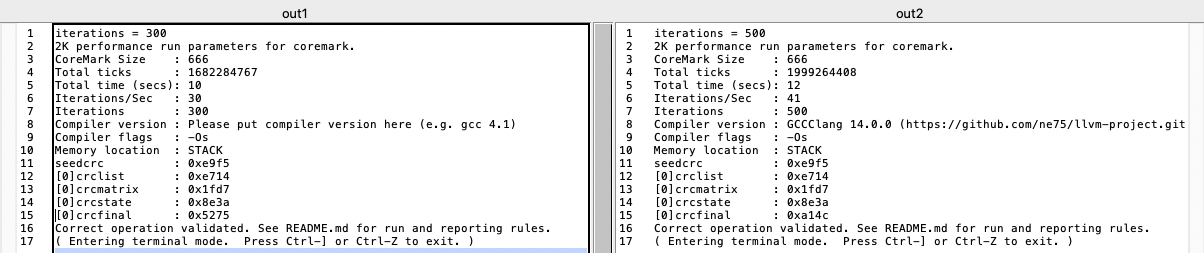
Another interesting data point below. LLVM compiled CoreMark code running on the P2 is certainly running faster than what we saw before (now 41 per second), although it seems to fail the benchmark's CRC test for some reason, so the actual code being generated may well be bad or certainly have a bug of some type somewhere.
We were seeing about 30 per second with optimizations enabled under flexspin before, and slower with my external RAM scheme (18 per second with safe? optimizations enabled). Same 160MHz P2 clock on each.
2K performance run parameters for coremark.
[0]ERROR! list crc 0x4af3 - should be 0xe714
[0]ERROR! matrix crc 0xcb74 - should be 0x1fd7
[0]ERROR! state crc 0xec26 - should be 0x8e3a
CoreMark Size : 666
Total ticks : 2022828112
Total time (secs): 12
Iterations/Sec : 41
Iterations : 500
Compiler version : GCCClang 14.0.0 (https://github.com/ne75/llvm-project.git 72a9bb1ef2656d9953d1f41a8196d425ff2ab0b1)
Compiler flags : -Os
Memory location : STACK
seedcrc : 0xe9f5
[0]crclist : 0x4af3
[0]crcmatrix : 0xcb74
[0]crcstate : 0xec26
[0]crcfinal : 0x0ebd
Errors detected
Another data point is that both toolchains create different total code/data segment sizes. Flexspin's generated code size is a bit smaller than LLVM's, 34052 vs 41852 bytes, but it also needs some extra data space used for its method tables etc (2900 vs 2372 bytes):
LLVM derived CoreMark application:
Sections:
Idx Name Size VMA Type
0 00000000 00000000
1 .text 0000a37c 00000000 TEXT -> $a37c = 41852 bytes
2 .rodata 000005d8 0000a380 DATA
3 .data 000000d0 0000a958 DATA -> $d0+$5d8 = 1496 bytes of preallocated data
4 .bss 0000036c 0000aa28 BSS -> $36c = 876 bytes of zeroed data (so total data = 2372)
5 .heap 0000bffc 0000ad94 BSS
6 .stack 0000c000 00070000 BSS
So I retested CoreMark with all optimizations disabled under LLVM and it didn't fail the CRC result check any more but the CoreMark rate fell back to 13 iterations/second. So the LLVM code generation bug must be because of some particular optimization breaking the code. This makes sense as I also found if I printed out some intermediate variable results it got further in a comparison I made between outputs after running from flexspin vs LLVM generated images before any differences were seen. So some important code seems to be getting broken under LLVM with the -0s option passed to the compiler. That's likely to be a big problem if I wanted to try use it for LVGL until that is figured out and resolved because compiling it under LLVM with optimizations off made the LVGL image size exceed the HUBRAM with a cache and heap allocated as well.
2K performance run parameters for coremark.
CoreMark Size : 666
Total ticks : 3577857752
Total time (secs): 22
Iterations/Sec : 13
Iterations : 300
Compiler version : GCCClang 14.0.0 (https://github.com/ne75/llvm-project.git 72a9bb1ef2656d9953d1f41a8196d425ff2ab0b1)
Compiler flags : -Os
Memory location : STACK
seedcrc : 0xe9f5
[0]crclist : 0xe714
[0]crcmatrix : 0x1fd7
[0]crcstate : 0x8e3a
[0]crcfinal : 0x5275
Correct operation validated. See README.md for run and reporting rules.
This bug will be in one of the differences in the code functions below (optimized code on left, unoptimized on right). Not sure which one unless code is examined thoroughly and I don't want to dig into it that much right now. I guess I could try to apply each optimization one at a time to find when it breaks, if that is possible with LLVM. I'd need to get the list of optimizations first.
UPDATE: The -O1 optmization level also causes the CRC error but boosted performance from 13 to 42 iterations per second (more than a 3x boost alone!).
2K performance run parameters for coremark.
[0]ERROR! list crc 0x2170 - should be 0xe714
[0]ERROR! matrix crc 0x4d15 - should be 0x1fd7
[0]ERROR! state crc 0x84d4 - should be 0x8e3a
CoreMark Size : 666
Total ticks : 1196990704
Total time (secs): 7
Iterations/Sec : 42
ERROR! Must execute for at least 10 secs for a valid result!
Iterations : 300
Compiler version : GCCClang 14.0.0 (https://github.com/ne75/llvm-project.git 72a9bb1ef2656d9953d1f41a8196d425ff2ab0b1)
Compiler flags : -Os
Memory location : STACK
seedcrc : 0xe9f5
[0]crclist : 0x2170
[0]crcmatrix : 0x4d15
[0]crcstate : 0x84d4
[0]crcfinal : 0x4511
Errors detected
I retested CoreMark with all optimizations disabled under LLVM and it didn't fail the CRC result check any more but the CoreMark rate fell back to 13 iterations/second.
Promising, but I don't think you can compare coremark results unless it validates correctly - one of the reasons for using coremark is that it self-validates so you know the results are an accurate representation. Also, coremark results are generally expressed as floating point - it is not clear from the output whether they are being truncated to integers during the calculation or during the printing, but either one will skew the results and also make it difficult to compare code sizes, since omitting floating point will generate smaller code.
I retested CoreMark with all optimizations disabled under LLVM and it didn't fail the CRC result check any more but the CoreMark rate fell back to 13 iterations/second.
Promising, but I don't think you can compare coremark results unless it validates correctly - one of the reasons for using coremark is that it self-validates so you know the results are an accurate representation.
Yes I would agree fully. I still want to fix this problem if I can as LLVM certainly does look promising as well but without optimizations enabled it's definitely not as fast as it could be. Its full linker is probably easily coaxed to place nominated code at upper RAM addresses. The code it generates does include tjz and tjnz however which would have to change to test then conditional branch as seperate instructions. The rest seems pretty clean. It uses the RETA CALLA syntax for function calls everywhere which is different to how flex does it.
Also, coremark results are generally expressed as floating point - it is not clear from the output whether they are being truncated to integers during the calculation or during the printing, but either one will skew the results and also make it difficult to compare code sizes, since omitting floating point will generate smaller code.
Ross.
Both were generated without floating point enabled in the command line args so it should be a reasonable comparison. Thatis why they are printing integers.
/* Configuration : HAS_FLOAT
Define to 1 if the platform supports floating point.
*/
#ifndef HAS_FLOAT
#define HAS_FLOAT 0
#endif
....
#if HAS_FLOAT
ee_printf("Total time (secs): %f\n", time_in_secs(total_time));
if (time_in_secs(total_time) > 0)
ee_printf("Iterations/Sec : %f\n",
default_num_contexts * results[0].iterations
/ time_in_secs(total_time));
#else
ee_printf("Total time (secs): %d\n", time_in_secs(total_time));
if (time_in_secs(total_time) > 0)
ee_printf("Iterations/Sec : %d\n",
default_num_contexts * results[0].iterations
/ time_in_secs(total_time));
#endif
Found one suspicious thing in the LLVM optimized code. This CoreMark bug may relate to the CORDIC QMUL. For some reason in this optimized code snippet, it is potentially executing a GETQX before a QMUL operation. This doesn't look right to me unless its trying to flush the CORDIC somehow first, but that is seemlingly not ever done in the unoptimized code which always puts the QMUL before the GETQX unless it needs to directly feed the next QMUL from a prior CORDIC result, which doesn't appear to be happening here in this case.
Perhaps LLVM code generator needs to be somehow told to not reorder CORDIC instruction pairs/groups like "QMUL" followed by "GETQX/Y" if that is not already done, as perhaps it's trying to pipeline it somehow and it's going awry. The CoreMark matrix multiply operation is definitely wrong when I print out the resulting matrix values and compare with flexspin's results, and its CRC obviously fails then too.
Tagging @n_ermosh as well in case it helps.
EDIT: I'm guessing this might be happening because if you do something like:
QMUL r1, r2
GETQX r3
then the compiler's optimizer thinks it could reorder the instruction affecting the r3 destination register independently because it doesn't know it actually (indirectly) still depends on r1 & r2 from the QMUL. Maybe that needs to be somehow specified in the instruction definitions if it's not already being done.
@rogloh said:
Found one suspicious thing in the LLVM optimized code. This CoreMark bug may relate to the CORDIC QMUL. For some reason in this optimized code snippet, it is potentially executing a GETQX before a QMUL operation. This doesn't look right to me unless its trying to flush the CORDIC somehow first, but that is seemlingly not ever done in the unoptimized code which always puts the QMUL before the GETQX unless it needs to directly feed the next QMUL from a prior CORDIC result, which doesn't appear to be happening here in this case.
Perhaps LLVM code generator needs to be somehow told to not reorder CORDIC instruction pairs/groups like "QMUL" followed by "GETQX/Y" if that is not already done, as perhaps it's trying to pipeline it somehow and it's going awry. The CoreMark matrix multiply operation is definitely wrong when I print out the resulting matrix values and compare with flexspin's results, and its CRC obviously fails then too.
On a general point, is it possible for compilers to be told about relative hub RAM timings? In the code above, the first write of wrlong r3, ptra++ takes 9 cycles with 6 waits after wrlong r0, ptra++ so mov r4, r1 and mov r5, r0 could be shifted up, saving four cycles. Also, the write in a read-modify-write is always the worst case of 10 cycles with 7 waits so add r8, #1 and cmp r8, r5 wcz could be moved above wrword r9, r10 saving four more cycles.
@TonyB_ said:
On a general point, is it possible for compilers to be told about relative hub RAM timings? In the code above, the first write of wrlong r3, ptra++ takes 9 cycles with 6 waits after wrlong r0, ptra++ so mov r4, r1 and mov r5, r0 could be shifted up, saving four cycles. Also, the write in a read-modify-write is always the worst case of 10 cycles with 7 waits so add r8, #1 and cmp r8, r5 wcz could be moved above wrword r9, r10 saving four more cycles.
That'd be really neat if it could be optimized to that level. When browsing the extensive LLVM code there are definitely some cost functions that are applied during optimizations so it wouldn't surprise me if that sort of thing was ultimately possible. It seems extremely powerful if you know how to drive it fully. Unfortunately it's also complex C++ code to try to get your head around.
What Nikita did with LLVM seems really good so far, just a shame there are these small problems remaining that limit its use right now. i.e No modulus operator working (compiler asserts whenever % is present in C source code) and optimizer inlining is potentially messing up CORDIC order. Maybe there are still some other broken things I don't know about yet..., but it seems so close to being fully usable!
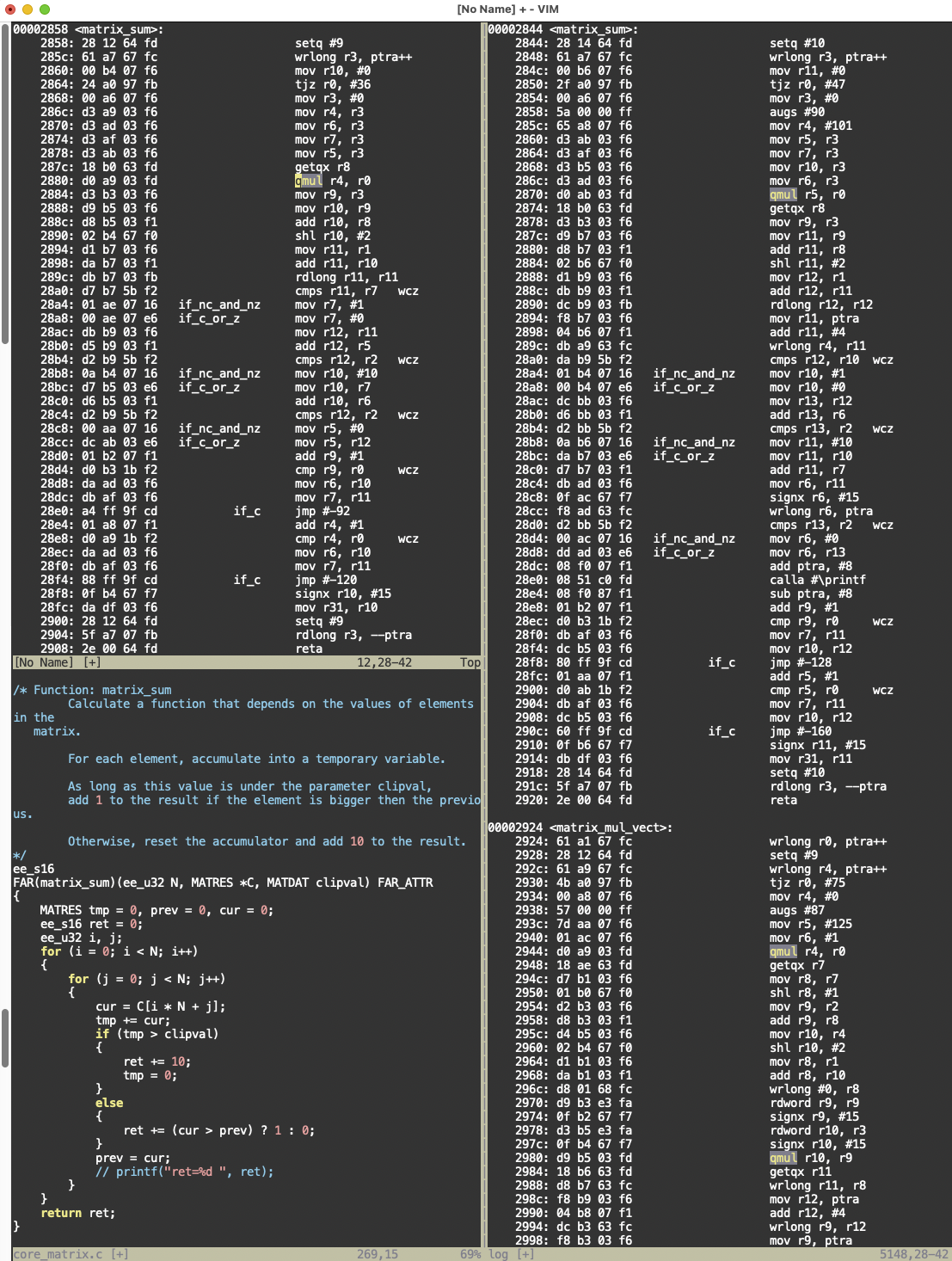
Sure enough, the last thing I found that stops the CoreMark benchmark program from matching the CRC seems to be another GETQX before QMUL instruction case. Once I include the (currently commented out) printf to the matrix_sum function it affects the optimizations for the code and the problem goes away.
Here's the code (left side is with the bad optimization, right side is with the printf restricting the optimizer from reordering, and thereby making it work). Look what it did to the QMUL & GETQX in each case. Its a complete order reversal in the failing case. Haven't proven it but the optimized code may potentially work if it didn't get that wrong.
EDIT: tried patching the CORDIC instruction order in the intermediate .s files generated after optimization and then sending those patched files into the assembler for relinking but it appears that P2LLVM doesn't like working with its own assembly file output format. Seeing lots of these errors on the patched files:
core_state.s:49:20: error: unexpected token in argument list - not an effect flag
wrlong r5, ptra[-1]
^
core_state.s:68:20: error: unexpected token in argument list - not an effect flag
rdlong r0, ptra[-1]
^
This is a problem given my SED conversion scripts would need to run on an intermediate ASM source file for my external memory solution to operate prior to a fully integrated solution in a compiler. EDIT2: another problem I just found is that QDIV is used for some divisions and the output is possibly wrong in the cases of negative inputs. Just can't get a win. Makes sense if CORDIC divide HW is meant to use unsigned only. Potentially some signed division needs more work in P2LLVM, although I'm still unsure if you only use 31 bit values with the sign bit as some values I tried seemed to still work. EDIT3: No, one division just failed for -4/2 and gave this output: x, y, x/y = -4, 2, 2147483646 , although to get this result it was a signed divided by unsigned and C has some of its own rules about that and I'm still not 100% sure on this.
Dug a little further into this signed/unsigned division thing and found that P2LLVM does seem to do the right thing with the CORDIC for signed numbers.
This test snippet works once you cast both inputs to signed if one is unsigned to begin with (which I read is what you are meant to do in C). Without that (signed) cast of y it previously printed the large number 2147483646 as the result.
In this case you can see the PASM2 that LLVM generated for this division implementation does use the sign bits and take the absolute value before using the CORDIC and reapplying the XOR of the two input sign bits as the new sign bit.
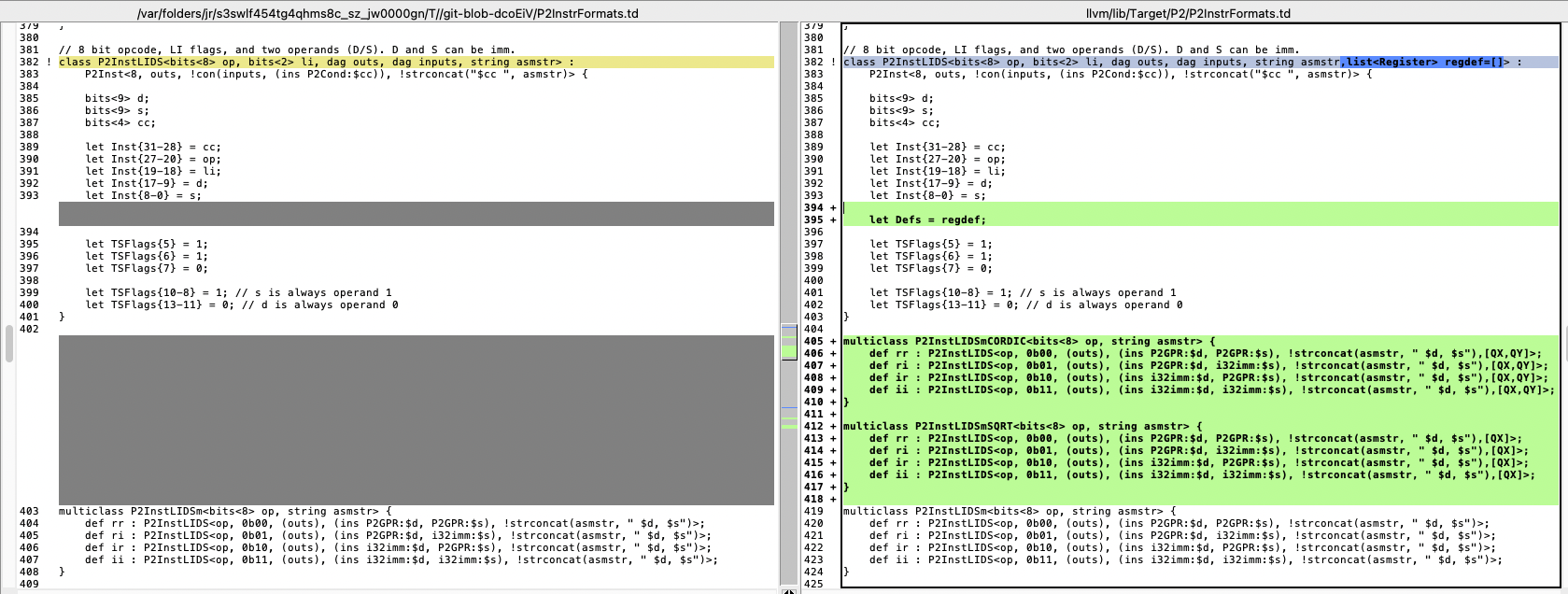
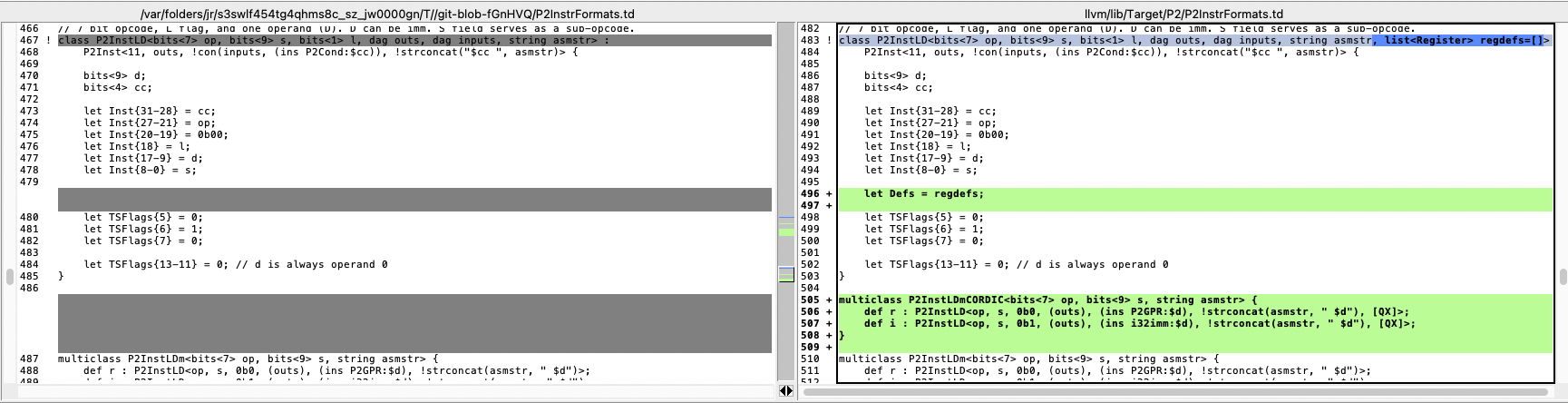
With some luck and a little effort I think I was able to modify the table definitions in the P2LLVM code to update the templates for CORDIC instructions that implicitly affect the QX/QY "registers" on a P2. It seems that now with -O1 optimizer setting applied when building CoreMark code all the GETQX and GETQY follow immediately after the QMUL or QDIV operations and are no longer being placed before them when I checked the disassembled output. This now lets CoreMark built with P2LLVM complete with the same good CRC results as when built by flexspin. I did notice that performance dropped a bit from before - probably because of the extra CORDIC wait time now after the multiplication or division until the result is ready before continuing. It now gets 41 CoreMark iterations/second under LLVM instead of 50. To hit close to 50 again it would probably need some really good CORDIC pipelining and the optimizer is not setup for that AFAIK.
Left is the flexspin built CoreMark result, right is LLVM built result
In case you want to review and/or apply them to your code @n_ermosh , here are the changes I put in for the CORDIC dependencies on QX/QY. It appears you just need to setup the "Defs" list to include any other unspecified registers that are affected by an instruction. I just passed QX and optionally QY as well for the CORDIC instructions that modify them.
Now that I have P2LLVM sort of working I was looking at the PASM2 instruction frequency distribution of the reasonably large (over 300kB) LVGL project I just built with it, to see the range of P2 instructions it generates.
With P2LLVM some of the CRT and C library code gets loaded into COG and LUT, and main starts at $a00 in HUBRAM which then includes the remainder of the C library that doesn't fit the LUT, so I've split the frequency distribution into two, one for COG/LUT use vs the other for HUBRAM use. Here's the breakdown of how many instances of each instruction are used in each memory.
What is interesting is that really the only "illegal" instructions my external memory caching scheme would not support from this HUBRAM group would be the "tjz" and "tjnz" cases which would break the caching, unless handled differently. If I can modify these to do a AND reg, reg wz followed by if_(n)z JMP #xx I may still be able to get my external memory solution working with this P2LLVM compiled code, assuming I can run my SED scripts on the resulting PASM2 output to convert the use of "CALLA" into "CALLPA ..." and do other branching cleanups etc.
Even if P2LLVM's built in assembler can't currently re-assemble its own code due to cases of unsupported "PTRA[expr]" etc I'm thinking I may still be able to use either flexspin's own assembler or possibly try out Dave Hein's one to get the final output code created that could work with my external memory scheme. Given flexspin still assembles at addresses above $100000 (despite a warning) I might be best to start with that.
Also I may be able to make use of LLVMs more capable linker scripts to reorder the code in memory so that I can place some functions in external memory and others into internal (HUB) memory via attributes or naming. This is potentially very handy and I now might have a way forward assuming P2LLVM code really runs okay. It certainly works with CoreMark but I probably should try to get some LVGL code running internally from HUB to prove that first. Will ultimately need to port my PSRAM driver API to use C as well, same for my video driver and use BLOBs for the PASM2 drivers unless I can integrate further with flexspin.
EDIT: far out, just realized this may let native P2 MicroPython finally shine on the P2 if it can be rebuilt with P2LLVM instead of all those messy and nasty p2gcc workarounds I came up with way back when, but that's a different story and a yet another distraction from what I want to do right now. Don't tell Lachlan, LOL.
@rogloh said:
Even if P2LLVM's built in assembler can't currently re-assemble its own code due to cases of unsupported "PTRA[expr]" etc I'm thinking I may still be able to use either flexspin's own assembler or possibly try out Dave Hein's one to get the final output code created that could work with my external memory scheme. Given flexspin still assembles at addresses above $100000 (despite a warning) I might be best to start with that.
Just tried out feeding PASM2 source generated by P2LLVM into flexspin. It needed a few file conversion mods but nothing that SED can't do from an "objdump -d" output of the LLVM elf file.
Now I just found out when flexspin is run as an assembler only that it does not let you name the source code labels from the builtin names and generates an error if you do. It'd be great if there was some way to eliminate this restriction (maybe a new command line switch) so that it is just a pure assembler and any label name is possible.
Unfortunately P2LLVM code also uses these same builtin names that flexspin seems to already have defined. How hard would it be to not populate these builtins into the flexspin internal symbol table if some new command line switch was enabled @ersmith ? That would allow flexspin to behave as a full generic assembler tool that doesn't care about what code it outputs.
Propeller Spin/PASM Compiler 'FlexSpin' (c) 2011-2026 Total Spectrum Software Inc. and contributors
Version 7.6.2 Compiled on: Mar 16 2026
main2.p2asm
main2.p2asm:7596: error: Changing hub value for symbol __addXf3__
main2.p2asm:8000: error: Changing hub value for symbol __leXf2__
main2.p2asm:8043: error: Changing hub value for symbol __geXf2__
main2.p2asm:8087: error: Changing hub value for symbol __unordXf2__
main2.p2asm:8743: error: Changing hub value for symbol normalize
main2.p2asm:8763: error: Changing hub value for symbol rep_clz
main2.p2asm:8785: error: Changing hub value for symbol __divXf3__
main2.p2asm:9171: error: Changing hub value for symbol __fixint
main2.p2asm:9242: error: Changing hub value for symbol __fixint
main2.p2asm:9343: error: Changing hub value for symbol __fixuint
main2.p2asm:9385: error: Changing hub value for symbol __fixuint
main2.p2asm:9432: error: Changing hub value for symbol __fixuint
main2.p2asm:10638: error: Changing hub value for symbol normalize
main2.p2asm:10658: error: Changing hub value for symbol rep_clz
main2.p2asm:10680: error: Changing hub value for symbol __mulXf3__
That's a problem with your file, none of those symbols are flexspin builtins. Generally the assembler doesn't have any builtins (except ASMCLK), every high level thing hass to pass through it normally.
(Posting this while waiting for a friend to use toilet at Leipzig book fair, don't expect further reply from me)
@Wuerfel_21 said:
That's a problem with your file, none of those symbols are flexspin builtins. Generally the assembler doesn't have any builtins (except ASMCLK), every high level thing hass to pass through it normally.
(Posting this while waiting for a friend to use toilet at Leipzig book fair, don't expect further reply from me)
LOL you are RIGHT! My file has multiple copies of some functions. Was certainly not expecting that. I have no idea why they are in there more than once. Makes no sense to copy a function into the file multiple times. Hopefully there is a Clang command line option to straighten that up. I was actually using the -ffunction-sections option for the compiler and --gc-sections for the linker but that seems to not be working for some reason.
This is getting rather messy trying to compile P2LLVM code with flexspin and I'm running into many issues. Some can be worked around.
multiple copies of some functions are present in the disassembled output - not sure why yet, for now I hacked them out manually by changing the labels of duplicates
some code labels sharing the same address (aliases?) are not output in the dump only a single label is printed at a given address, so it looks like some code is missing but it's just the label that is missing. The symbol table has the details but it requires patching the file further to capture these cases. E.g
00006cd4 g F .text 000000b4 atoi
00006cd4 g F .text 000000b4 atol
P2LLVM doesn't decode all PTRA indexing ops for HUB reads and writes and instead just prints large integers for #S like this: a14: e4 01 6c fc wrlong #0, #484
these are unrecognized by flexspin and need to be patched to just use the same opcode via a long $fc6c01e4 being inserted into the file to replace the instruction in this case
P2LLVM outputs a different address offset in its disassembly for relative jmp branches and tjz/djnz instructions, e.g.: 21c: 24 00 90 3d if_nc jmp #36
while flexspin needs to compute the relative value from a label, it won't take the constant presented as is and it needs to be divided by 4 and another offset added to get it to match the same LLVM generated 32 bit opcode when reassembled. If you try to use $+ and the value to generate the offset you get a bad value, in this case $8C instead of $24 in the S field of the JMP instruction: 0015c 21c 8C 00 90 3D | if_nc jmp #$+36
other minor formatting differences which can be cleaned up in scripts
Hoping data segment won't be messed with too much as all the addresses are hard coded into the program, but will need to be careful if the code moves around to keep data at same addresses. May need to keep data in lower memory below the code so code can be changed without affecting data addresses.
P2LLVM doesn't decode all PTRA indexing ops for HUB reads and writes and instead just prints large integers for #S like this: a14: e4 01 6c fc wrlong #0, #484
these are unrecognized by flexspin and need to be patched to just use the same opcode via a long $fc6c01e4 being inserted into the file to replace the instruction in this case
Just worked on this so that P2LLVM now disassembles PTRA indexing ops (except for the increased 20 bit range case using the ##). I printed them out for all cases of the #S value from 0-511 and it seems to match flexspin now.
What'd be even better was if P2LLVM could handle assembling with the proper indexing syntax with pointer ops but that's probably a whole lot more parsing work to do. Not so sure how easy that work is, my change was likely simple in comparison.
Here's the diff for P2LLVM P2InstPrinter.cpp in case anyone wants it and the output for all instruction #S values from 0-511.
--- a/llvm/lib/Target/P2/MCTargetDesc/P2InstPrinter.cpp
+++ b/llvm/lib/Target/P2/MCTargetDesc/P2InstPrinter.cpp
@@ -147,14 +147,33 @@ void P2InstPrinter::printOperand(const MCInst *MI, unsigned OpNum, raw_ostream &
// this is a D operand, so don't try to convert to a special immediate
bool OpIsD = P2::getDNum(MII.get(MI->getOpcode()).TSFlags) == OpNum;
- if (!OpIsD && (Op.getImm() & 0x1c0) == P2::PTRA_INDEX6) {
- int idx = Op.getImm() & 0x3f;
+ int imm = Op.getImm();
+ if (!OpIsD && (imm & 0x140) == P2::PTRA_INDEX6) {
+ int idx = imm & 0x3f;
if (idx > 31) idx -= 64;
- O << "ptra[" << idx << "]";
+ O << ((imm & 0x80) ? "ptrb" : "ptra");
+ if (idx)
+ O << "[" << idx << "]";
return;
}
+ // TODO: also handle any ## constants for ptra/ptrb indexing?
+ if (!OpIsD && (imm & 0x40) && (imm & 0x100))
+ {
+ int idx = imm & 0xf;
+ if (idx == 0) idx=16;
+ if ((imm & 0x20) == 0)
+ O << ((imm & 0x10) ? "--" : "++");
+ O << ((imm & 0x80) ? "ptrb" : "ptra");
+ if (imm & 0x20)
+ O << ((imm & 0x10) ? "--" : "++");
+ if (idx != 16 && imm & 0x10)
+ idx = 16-idx;
+ if (idx)
+ O << "[" << idx << "]";
+ return;
+ }
// this is a plain immediate, it'll print below
}


Comments
Yeah I'll probably not try to use assembly, more a mix of C and SPIN2. But it's mainly the integration with other SPIN2 stuff like my memory driver and other stuff which flexspin handles so well and compels me to use that. Also if I do run into problems, I can debug PASM2 instructions easily as I'm very familiar with those, while I'm a complete newbie with respect to RISCV and don't really want to have to learn that just to fix code issues I may encounter on a P2.
I do actually have an application in mind for this if I can get this working, hence my appetite for fixing these issues. My car has a 9 inch LCD screen with a spare video input for reversing cameras which I don't use and it'd be cool to feed it a P2's video output with a nice GUI showing some automotive stuff like TPMS sensor data and any other CAN accessible data I might like to see. A P2 board with external RAM such as the Edge might be useful to control this all. It'd mostly just need my PSRAM driver for the external memory code and some other IO pins for accessing HW and a composite video output, so it's quite doable. A lot of HUB RAM would be freed up for a screen buffer if I can place this LVGL code into external RAM and LVGL is seemingly very capable for displaying fancy dials and other presentable GUI widgets in real time. I could use something else such as a Pico or ESP device but obviously prefer to use a P2. Now I'm still not sure about performance but for a high speed P2 I'm still optimistic (although maybe a little less so since I saw all that heap activity now in the disassembled code for some functions ).
).
True. I may look at that at some point, but again it's the features of flexspin like mixing SPIN2 and C objects which are compelling in this case.
I'll post the files I modified with a github link to the 9.5 tree of LVGL which IIRC forms that sub-directory. Probably much smaller that way otherwise it's ~700MB. Will edit this post here with the ZIP once I've sorted it out for you.
EDIT: Just added projchanges.zip and instructions within its included readme.txt file for getting the other files.
Ok. That was the last one, so I'll wait until the other stuff is hopefully working before trying to address that. It only showed up recently.
I've just fixed this and pushed the fix to GitHub. p2asm now generates the same code as PNut and the Propeller Tool for the LOC instruction.
So with some tweaks today I was able to get LVGL building on a P2 with n_ermosh's P2 LLVM compiler. For our reference this dummy build (basic LVGL code but no real application) consumes about 322kB of HUB for its code segment, and about 14kB of data, plus it would still need some space left for a (partial) frame buffer and a heap+stack. It would be pushing it to fit all this into HUB unless the frame buffer is of lower resolution (like 320x200). One possibility to improve this would be to try to keep the frame buffer(s) in external memory and just transfer portions to/from PSRAM as the screen is rendered into the partial frame buffer in HUBRAM. I read somewhere that LVGL needs at least a 10% sized local frame buffer to still work ok. So that might be a possibility for me if a flexspin build that is running LVGL from external RAM can't be achieved. It would allow higher bit depths too.
It'll be interesting to compare how much HUBRAM the flexspin code will be for this same build if we can fix the compile errors so it completes. I did compile with -Os option on LLVM so it's meant to be optimized for smaller size, and uncalled functions are meant to be removed. The full list of LVGL files in this particular build are attached so we can compare later. I also cut the internally allocated free memory area down to 32kB from 64kB, otherwise the BSS use would be an extra 32kB more and the default sized heap the collides with the default stack. Need to work out how to shrink those a bit, the default stack size is 48kB and probably way too big.
Another interesting data point below. LLVM compiled CoreMark code running on the P2 is certainly running faster than what we saw before (now 41 per second), although it seems to fail the benchmark's CRC test for some reason, so the actual code being generated may well be bad or certainly have a bug of some type somewhere.
We were seeing about 30 per second with optimizations enabled under flexspin before, and slower with my external RAM scheme (18 per second with safe? optimizations enabled). Same 160MHz P2 clock on each.
Another data point is that both toolchains create different total code/data segment sizes. Flexspin's generated code size is a bit smaller than LLVM's, 34052 vs 41852 bytes, but it also needs some extra data space used for its method tables etc (2900 vs 2372 bytes):
LLVM derived CoreMark application:
Sections:
Idx Name Size VMA Type
0 00000000 00000000
1 .text 0000a37c 00000000 TEXT -> $a37c = 41852 bytes
2 .rodata 000005d8 0000a380 DATA
3 .data 000000d0 0000a958 DATA -> $d0+$5d8 = 1496 bytes of preallocated data
4 .bss 0000036c 0000aa28 BSS -> $36c = 876 bytes of zeroed data (so total data = 2372)
5 .heap 0000bffc 0000ad94 BSS
6 .stack 0000c000 00070000 BSS
Flexspin derived CoreMark application:
$0000 code begins
$8504 code ends (code len=34052 bytes)
$8508 data starts
$9058 data ends (data len=2900 bytes)
So I retested CoreMark with all optimizations disabled under LLVM and it didn't fail the CRC result check any more but the CoreMark rate fell back to 13 iterations/second. So the LLVM code generation bug must be because of some particular optimization breaking the code. This makes sense as I also found if I printed out some intermediate variable results it got further in a comparison I made between outputs after running from flexspin vs LLVM generated images before any differences were seen. So some important code seems to be getting broken under LLVM with the -0s option passed to the compiler. That's likely to be a big problem if I wanted to try use it for LVGL until that is figured out and resolved because compiling it under LLVM with optimizations off made the LVGL image size exceed the HUBRAM with a cache and heap allocated as well.
This bug will be in one of the differences in the code functions below (optimized code on left, unoptimized on right). Not sure which one unless code is examined thoroughly and I don't want to dig into it that much right now. I guess I could try to apply each optimization one at a time to find when it breaks, if that is possible with LLVM. I'd need to get the list of optimizations first.

UPDATE: The -O1 optmization level also causes the CRC error but boosted performance from 13 to 42 iterations per second (more than a 3x boost alone!).
@rogloh
Promising, but I don't think you can compare coremark results unless it validates correctly - one of the reasons for using coremark is that it self-validates so you know the results are an accurate representation. Also, coremark results are generally expressed as floating point - it is not clear from the output whether they are being truncated to integers during the calculation or during the printing, but either one will skew the results and also make it difficult to compare code sizes, since omitting floating point will generate smaller code.
Ross.
Yes I would agree fully. I still want to fix this problem if I can as LLVM certainly does look promising as well but without optimizations enabled it's definitely not as fast as it could be. Its full linker is probably easily coaxed to place nominated code at upper RAM addresses. The code it generates does include tjz and tjnz however which would have to change to test then conditional branch as seperate instructions. The rest seems pretty clean. It uses the RETA CALLA syntax for function calls everywhere which is different to how flex does it.
Both were generated without floating point enabled in the command line args so it should be a reasonable comparison. Thatis why they are printing integers.
/* Configuration : HAS_FLOAT Define to 1 if the platform supports floating point. */ #ifndef HAS_FLOAT #define HAS_FLOAT 0 #endif .... #if HAS_FLOAT ee_printf("Total time (secs): %f\n", time_in_secs(total_time)); if (time_in_secs(total_time) > 0) ee_printf("Iterations/Sec : %f\n", default_num_contexts * results[0].iterations / time_in_secs(total_time)); #else ee_printf("Total time (secs): %d\n", time_in_secs(total_time)); if (time_in_secs(total_time) > 0) ee_printf("Iterations/Sec : %d\n", default_num_contexts * results[0].iterations / time_in_secs(total_time)); #endifFound one suspicious thing in the LLVM optimized code. This CoreMark bug may relate to the CORDIC QMUL. For some reason in this optimized code snippet, it is potentially executing a GETQX before a QMUL operation. This doesn't look right to me unless its trying to flush the CORDIC somehow first, but that is seemlingly not ever done in the unoptimized code which always puts the QMUL before the GETQX unless it needs to directly feed the next QMUL from a prior CORDIC result, which doesn't appear to be happening here in this case.
Perhaps LLVM code generator needs to be somehow told to not reorder CORDIC instruction pairs/groups like "QMUL" followed by "GETQX/Y" if that is not already done, as perhaps it's trying to pipeline it somehow and it's going awry. The CoreMark matrix multiply operation is definitely wrong when I print out the resulting matrix values and compare with flexspin's results, and its CRC obviously fails then too.
Tagging @n_ermosh as well in case it helps.
EDIT: I'm guessing this might be happening because if you do something like:
then the compiler's optimizer thinks it could reorder the instruction affecting the r3 destination register independently because it doesn't know it actually (indirectly) still depends on r1 & r2 from the QMUL. Maybe that needs to be somehow specified in the instruction definitions if it's not already being done.
On a general point, is it possible for compilers to be told about relative hub RAM timings? In the code above, the first write of
wrlong r3, ptra++takes 9 cycles with 6 waits afterwrlong r0, ptra++somov r4, r1andmov r5, r0could be shifted up, saving four cycles. Also, the write in a read-modify-write is always the worst case of 10 cycles with 7 waits soadd r8, #1andcmp r8, r5 wczcould be moved abovewrword r9, r10saving four more cycles.That'd be really neat if it could be optimized to that level. When browsing the extensive LLVM code there are definitely some cost functions that are applied during optimizations so it wouldn't surprise me if that sort of thing was ultimately possible. It seems extremely powerful if you know how to drive it fully. Unfortunately it's also complex C++ code to try to get your head around.
What Nikita did with LLVM seems really good so far, just a shame there are these small problems remaining that limit its use right now. i.e No modulus operator working (compiler asserts whenever % is present in C source code) and optimizer inlining is potentially messing up CORDIC order. Maybe there are still some other broken things I don't know about yet..., but it seems so close to being fully usable!
Sure enough, the last thing I found that stops the CoreMark benchmark program from matching the CRC seems to be another GETQX before QMUL instruction case. Once I include the (currently commented out) printf to the matrix_sum function it affects the optimizations for the code and the problem goes away.
Here's the code (left side is with the bad optimization, right side is with the printf restricting the optimizer from reordering, and thereby making it work). Look what it did to the QMUL & GETQX in each case. Its a complete order reversal in the failing case. Haven't proven it but the optimized code may potentially work if it didn't get that wrong.
EDIT: tried patching the CORDIC instruction order in the intermediate .s files generated after optimization and then sending those patched files into the assembler for relinking but it appears that P2LLVM doesn't like working with its own assembly file output format. Seeing lots of these errors on the patched files:
core_state.s:49:20: error: unexpected token in argument list - not an effect flag wrlong r5, ptra[-1] ^ core_state.s:68:20: error: unexpected token in argument list - not an effect flag rdlong r0, ptra[-1] ^This is a problem given my SED conversion scripts would need to run on an intermediate ASM source file for my external memory solution to operate prior to a fully integrated solution in a compiler. EDIT2: another problem I just found is that QDIV is used for some divisions and the output is possibly wrong in the cases of negative inputs. Just can't get a win. Makes sense if CORDIC divide HW is meant to use unsigned only. Potentially some signed division needs more work in P2LLVM, although I'm still unsure if you only use 31 bit values with the sign bit as some values I tried seemed to still work. EDIT3: No, one division just failed for -4/2 and gave this output:
Makes sense if CORDIC divide HW is meant to use unsigned only. Potentially some signed division needs more work in P2LLVM, although I'm still unsure if you only use 31 bit values with the sign bit as some values I tried seemed to still work. EDIT3: No, one division just failed for -4/2 and gave this output:
x, y, x/y = -4, 2, 2147483646, although to get this result it was a signed divided by unsigned and C has some of its own rules about that and I'm still not 100% sure on this.Dug a little further into this signed/unsigned division thing and found that P2LLVM does seem to do the right thing with the CORDIC for signed numbers.
This test snippet works once you cast both inputs to signed if one is unsigned to begin with (which I read is what you are meant to do in C). Without that (signed) cast of y it previously printed the large number 2147483646 as the result.
#define P2_TARGET_MHZ 160 #include <stdint.h> #include <stdio.h> #include <sys/p2es_clock.h> #include <propeller.h> int main(int argc, char **argv) { int32_t x = -4; uint32_t y= 2; _clkset(_SETFREQ, _CLOCKFREQ); _uart_init(DBG_UART_RX_PIN, DBG_UART_TX_PIN, 2000000, 0); printf("x,y,x/y=%d, %d, %d\n", x ,y,x/(signed)y); return 0; }In this case you can see the PASM2 that LLVM generated for this division implementation does use the sign bits and take the absolute value before using the CORDIC and reapplying the XOR of the two input sign bits as the new sign bit.
000002fc <__divsi3>: 2fc: 28 04 64 fd setq #2 300: 61 a1 67 fc wrlong r0, ptra++ 304: d0 a5 03 f6 mov r2, r0 308: d1 a5 63 f5 xor r2, r1 30c: 1f a4 4f f0 shr r2, #31 wz 310: d0 a1 43 f6 abs r0, r0 314: d1 a3 43 f6 abs r1, r1 318: d1 a1 13 fd qdiv r0, r1 31c: 18 de 63 fd getqx r31 320: ef df 63 56 if_nz neg r31, r31 324: 28 04 64 fd setq #2 328: 5f a1 07 fb rdlong r0, --ptra 32c: 2e 00 64 fd reta ... 00000a00 <main>: a00: 28 08 64 fd setq #4 a04: 61 a1 67 fc wrlong r0, ptra++ a08: 1c f0 07 f1 add ptra, #28 a0c: 39 01 6c fc wrlong #0, ptra[-7] a10: 3a a1 67 fc wrlong r0, ptra[-6] a14: 3b a3 67 fc wrlong r1, ptra[-5] a18: ff ff ff ff augd #8388607 a1c: 3c f9 6f fc wrlong #508, ptra[-4] a20: 3d 05 6c fc wrlong #2, ptra[-3] a24: 03 80 00 ff augs #32771 a28: f8 a1 07 f6 mov r0, #504 a2c: b4 c4 04 ff augs #312500 a30: 00 a2 07 f6 mov r1, #0 a34: e0 42 c0 fd calla #\_clkset a38: 3f a0 07 f6 mov r0, #63 a3c: 3e a2 07 f6 mov r1, #62 a40: 42 0f 00 ff augs #3906 a44: 80 a4 07 f6 mov r2, #128 a48: 00 a6 07 f6 mov r3, #0 a4c: 3e a7 67 fc wrlong r3, ptra[-2] a50: 4c 43 c0 fd calla #\_uart_init a54: 3c a1 07 fb rdlong r0, ptra[-4] a58: 3f a1 67 fc wrlong r0, ptra[-1] a5c: 3d a7 07 fb rdlong r3, ptra[-3] a60: d3 a3 03 f6 mov r1, r3 a64: 3f 02 c0 fd calla #\__divsi3 a68: 3f a3 07 fb rdlong r1, ptra[-1] a6c: 3e a1 07 fb rdlong r0, ptra[-2] a70: ef a9 03 f6 mov r4, r31 a74: f8 a5 03 f6 mov r2, ptra a78: d2 a9 63 fc wrlong r4, r2 a7c: d2 a9 03 f6 mov r4, r2 a80: 04 a8 07 f1 add r4, #4 a84: d4 a7 63 fc wrlong r3, r4 a88: d2 a7 03 f6 mov r3, r2 a8c: 08 a6 07 f1 add r3, #8 a90: d3 a3 63 fc wrlong r1, r3 a94: 0c a4 07 f1 add r2, #12 a98: 3f 00 00 ff augs #63 a9c: a8 a2 07 f6 mov r1, #168 aa0: d2 a3 63 fc wrlong r1, r2 aa4: 10 f0 07 f1 add ptra, #16 aa8: 70 21 c0 fd calla #\printf aac: 10 f0 87 f1 sub ptra, #16 ab0: d0 df 03 f6 mov r31, r0 ab4: 1c f0 87 f1 sub ptra, #28 ab8: 28 08 64 fd setq #4 abc: 5f a1 07 fb rdlong r0, --ptra ac0: 2e 00 64 fd retaFeeling kinda pleased rn.
With some luck and a little effort I think I was able to modify the table definitions in the P2LLVM code to update the templates for CORDIC instructions that implicitly affect the QX/QY "registers" on a P2. It seems that now with -O1 optimizer setting applied when building CoreMark code all the GETQX and GETQY follow immediately after the QMUL or QDIV operations and are no longer being placed before them when I checked the disassembled output. This now lets CoreMark built with P2LLVM complete with the same good CRC results as when built by flexspin. I did notice that performance dropped a bit from before - probably because of the extra CORDIC wait time now after the multiplication or division until the result is ready before continuing. It now gets 41 CoreMark iterations/second under LLVM instead of 50. To hit close to 50 again it would probably need some really good CORDIC pipelining and the optimizer is not setup for that AFAIK.
Left is the flexspin built CoreMark result, right is LLVM built result
In case you want to review and/or apply them to your code @n_ermosh , here are the changes I put in for the CORDIC dependencies on QX/QY. It appears you just need to setup the "Defs" list to include any other unspecified registers that are affected by an instruction. I just passed QX and optionally QY as well for the CORDIC instructions that modify them.
Now that I have P2LLVM sort of working I was looking at the PASM2 instruction frequency distribution of the reasonably large (over 300kB) LVGL project I just built with it, to see the range of P2 instructions it generates.
With P2LLVM some of the CRT and C library code gets loaded into COG and LUT, and main starts at $a00 in HUBRAM which then includes the remainder of the C library that doesn't fit the LUT, so I've split the frequency distribution into two, one for COG/LUT use vs the other for HUBRAM use. Here's the breakdown of how many instances of each instruction are used in each memory.
COG/LUT PASM2 COUNT HUB PASM2 COUNT abs 5 abs 0 add 21 add 11749 addx 4 addx 41 and 4 and 2358 augd 2 augd 22 augs 16 augs 2186 calla 43 calla 2512 cmp 15 cmp 1484 cmps 1 cmps 3981 cmpsx 0 cmpsx 77 cmpx 2 cmpx 27 cogid 1 cogid 0 coginit 1 coginit 0 dirh 0 dirh 2 dirl 0 dirl 2 djnz 4 djnz 0 encod 2 encod 21 getqx 7 getqx 1896 getqy 3 getqy 38 hubset 1 hubset 3 jmp 27 jmp 6695 locknew 0 locknew 1 lockrel 0 lockrel 2 locktry 0 locktry 2 mov 85 mov 20682 neg 2 neg 194 not 8 not 128 ones 0 ones 2 or 4 or 1058 qdiv 4 qdiv 100 qmul 3 qmul 1834 rdbyte 2 rdbyte 3197 rdfast 1 rdfast 0 rdlong 27 rdlong 4495 rdpin 0 rdpin 1 rdword 0 rdword 443 rep 1 rep 0 reta 46 reta 496 rfbyte 1 rfbyte 0 rol 0 rol 40 ror 0 ror 1 sar 4 sar 315 setq 29 setq 1210 setq2 1 setq2 0 shl 8 shl 1296 shr 12 shr 2305 signx 0 signx 97 sub 18 sub 3405 subr 1 subr 21 subx 0 subx 10 testp 0 testp 2 tjnz 1 tjnz 691 tjz 10 tjz 1007 waitx 0 waitx 2 wfbyte 1 wfbyte 0 wrbyte 4 wrbyte 2383 wrc 0 wrc 2 wrfast 1 wrfast 0 wrlong 21 wrlong 2663 wrpin 0 wrpin 2 wrword 0 wrword 316 wxpin 0 wxpin 2 wypin 0 wypin 1 xor 9 xor 361 --- ----- 464 81861What is interesting is that really the only "illegal" instructions my external memory caching scheme would not support from this HUBRAM group would be the "tjz" and "tjnz" cases which would break the caching, unless handled differently. If I can modify these to do a
AND reg, reg wzfollowed byif_(n)z JMP #xxI may still be able to get my external memory solution working with this P2LLVM compiled code, assuming I can run my SED scripts on the resulting PASM2 output to convert the use of "CALLA" into "CALLPA ..." and do other branching cleanups etc.Even if P2LLVM's built in assembler can't currently re-assemble its own code due to cases of unsupported "PTRA[expr]" etc I'm thinking I may still be able to use either flexspin's own assembler or possibly try out Dave Hein's one to get the final output code created that could work with my external memory scheme. Given flexspin still assembles at addresses above $100000 (despite a warning) I might be best to start with that.
Also I may be able to make use of LLVMs more capable linker scripts to reorder the code in memory so that I can place some functions in external memory and others into internal (HUB) memory via attributes or naming. This is potentially very handy and I now might have a way forward assuming P2LLVM code really runs okay. It certainly works with CoreMark but I probably should try to get some LVGL code running internally from HUB to prove that first. Will ultimately need to port my PSRAM driver API to use C as well, same for my video driver and use BLOBs for the PASM2 drivers unless I can integrate further with flexspin.
EDIT: far out, just realized this may let native P2 MicroPython finally shine on the P2 if it can be rebuilt with P2LLVM instead of all those messy and nasty p2gcc workarounds I came up with way back when, but that's a different story and a yet another distraction from what I want to do right now. Don't tell Lachlan, LOL.
Just tried out feeding PASM2 source generated by P2LLVM into flexspin. It needed a few file conversion mods but nothing that SED can't do from an "objdump -d" output of the LLVM elf file.
Now I just found out when flexspin is run as an assembler only that it does not let you name the source code labels from the builtin names and generates an error if you do. It'd be great if there was some way to eliminate this restriction (maybe a new command line switch) so that it is just a pure assembler and any label name is possible.
Unfortunately P2LLVM code also uses these same builtin names that flexspin seems to already have defined. How hard would it be to not populate these builtins into the flexspin internal symbol table if some new command line switch was enabled @ersmith ? That would allow flexspin to behave as a full generic assembler tool that doesn't care about what code it outputs.
That's a problem with your file, none of those symbols are flexspin builtins. Generally the assembler doesn't have any builtins (except ASMCLK), every high level thing hass to pass through it normally.
(Posting this while waiting for a friend to use toilet at Leipzig book fair, don't expect further reply from me)
LOL you are RIGHT! My file has multiple copies of some functions. Was certainly not expecting that. I have no idea why they are in there more than once. Makes no sense to copy a function into the file multiple times. Hopefully there is a Clang command line option to straighten that up. I was actually using the -ffunction-sections option for the compiler and --gc-sections for the linker but that seems to not be working for some reason.
This is getting rather messy trying to compile P2LLVM code with flexspin and I'm running into many issues. Some can be worked around.
P2LLVM had atol defined, but no atoi
00006cd4 <atol>: 6cd4: 28 0e 64 fd setq #7 6cd8: 61 a1 67 fc wrlong r0, ptra++ 6cdc: 58 00 00 ff augs #88so I needed to put the extra label into the file for flexspin to use when referenced
P2LLVM doesn't decode all PTRA indexing ops for HUB reads and writes and instead just prints large integers for #S like this:
a14: e4 01 6c fc wrlong #0, #484these are unrecognized by flexspin and need to be patched to just use the same opcode via a
long $fc6c01e4being inserted into the file to replace the instruction in this caseP2LLVM outputs a different address offset in its disassembly for relative jmp branches and tjz/djnz instructions, e.g.:
21c: 24 00 90 3d if_nc jmp #36while flexspin needs to compute the relative value from a label, it won't take the constant presented as is and it needs to be divided by 4 and another offset added to get it to match the same LLVM generated 32 bit opcode when reassembled. If you try to use $+ and the value to generate the offset you get a bad value, in this case $8C instead of $24 in the S field of the JMP instruction:
0015c 21c 8C 00 90 3D | if_nc jmp #$+36other minor formatting differences which can be cleaned up in scripts
Hoping data segment won't be messed with too much as all the addresses are hard coded into the program, but will need to be careful if the code moves around to keep data at same addresses. May need to keep data in lower memory below the code so code can be changed without affecting data addresses.
Just worked on this so that P2LLVM now disassembles PTRA indexing ops (except for the increased 20 bit range case using the ##). I printed them out for all cases of the #S value from 0-511 and it seems to match flexspin now.
What'd be even better was if P2LLVM could handle assembling with the proper indexing syntax with pointer ops but that's probably a whole lot more parsing work to do. Not so sure how easy that work is, my change was likely simple in comparison.
Here's the diff for P2LLVM P2InstPrinter.cpp in case anyone wants it and the output for all instruction #S values from 0-511.
--- a/llvm/lib/Target/P2/MCTargetDesc/P2InstPrinter.cpp +++ b/llvm/lib/Target/P2/MCTargetDesc/P2InstPrinter.cpp @@ -147,14 +147,33 @@ void P2InstPrinter::printOperand(const MCInst *MI, unsigned OpNum, raw_ostream & // this is a D operand, so don't try to convert to a special immediate bool OpIsD = P2::getDNum(MII.get(MI->getOpcode()).TSFlags) == OpNum; - if (!OpIsD && (Op.getImm() & 0x1c0) == P2::PTRA_INDEX6) { - int idx = Op.getImm() & 0x3f; + int imm = Op.getImm(); + if (!OpIsD && (imm & 0x140) == P2::PTRA_INDEX6) { + int idx = imm & 0x3f; if (idx > 31) idx -= 64; - O << "ptra[" << idx << "]"; + O << ((imm & 0x80) ? "ptrb" : "ptra"); + if (idx) + O << "[" << idx << "]"; return; } + // TODO: also handle any ## constants for ptra/ptrb indexing? + if (!OpIsD && (imm & 0x40) && (imm & 0x100)) + { + int idx = imm & 0xf; + if (idx == 0) idx=16; + if ((imm & 0x20) == 0) + O << ((imm & 0x10) ? "--" : "++"); + O << ((imm & 0x80) ? "ptrb" : "ptra"); + if (imm & 0x20) + O << ((imm & 0x10) ? "--" : "++"); + if (idx != 16 && imm & 0x10) + idx = 16-idx; + if (idx) + O << "[" << idx << "]"; + return; + } // this is a plain immediate, it'll print below }