You have B350 vs the A320 mentioned, correct?
Now I'm confused about 5000 CPU support, as the A320 notice is recent, so wouldn't B350 have been first?
Not sure about TPM 2.0, so hope it is present.
Motherboards without support will require a TPM add-in card for W11... unless you disable the TPM requirement, which I have seen discussed.
Two things:
1: I don't think there is any B350 motherboards yet supporting the Ryzen 5000 series CPUs. Only A320 motherboards so far.
2: However, I also found there is a recent updated BIOS for my B350 board when I looked on the website. But of course that's primarily just a defaults change so as to smooth the installation of Win11 by enabling TPM by default.
Then, what I discovered about TPM support is it seems to be fully functional - which I hadn't expected to find given the TPM slot in the motherboard is unpopulated. My conclusion is the required hardware is present in the Ryzen 1700X - has been there all along.
But, finally, the updated BIOS clearly contains more than just a default setting flipped. The menus haven't changed between the two BIOS versions but the compressed size has.
PS: Speculation online, for why only the A320 is getting this support, seems to be that the cheapest end of the market aren't likely to upgrade the whole kit to move from Zen/Zen+ to Zen3. Therefore the reasoning goes that AMD, and the board makers, are strategically providing this to get more CPUs, and RAM, sold without cutting into the newer motherboard sales.
The argument about a board's power capacity limit seems a little bogus to me. I can understand AMD having not verified all combinations of CPU and chipset on the simple basis of not bothering ... but to generally lump X370 and B350 boards as whimper than A320 boards does seem just a tad on the nose.
Pondering IC supplies ... My Geforce 960 is getting long in the tooth and I have been getting more interested in trying out a Radeon GPU on Linux. But haven't acted yet. I was eyeing up the 5600XT when they vanished due to covid19 supply shortages, then the 5700XT soon followed. I wasn't much interested in the 5500XT but sure enough even it went out of stock. The 6000 series is just too expensive and at any rate the 6500XT is only 4-channel PCIe, which is a problem when my mobo is limited to PCIe 3.0.
None of the 5000 series has reappeared since. As if production was stopped completely ... or at least not worth continuing at the old prices.
Lately, I've drawn up a PCB design with stepper motor ICs on board. Getting there wasn't as smooth sailing as usual ... The reference part I started with didn't have current limiting feature so I went a looking for something better ... every part I looked up was out of stock and not to be restocked for over a year. I knew that meant covid19 supply shortages and that even a year was a wild guess on their part.
What I ended up with, to get current limiting feature built in, is a part that also required a minimum of 20 volts supply. An awkwardly high minimum. Which told me it was a part that couldn't easily be exchanged into an existing board design ... therefore it hadn't been snatched up in the frenzy to ensure on-going parts supply.
Conclusion: The only ICs not out of stock are either a pricey narrow selection, or old stock that had virtually no turn-over.
It's a little surprising to me just how wide the IC shortages are. There doesn't seem to be anything unaffected. The early excuse about the auto-industry not up-dating is looking more and more bogus. A deflection from something else.
Comparing the 7950X in its default power config (Max power raised compared to the 5950X) it is driven to a notably higher clock frequency. This results in the 7950X being less efficient than the 5950X - Seemingly contrary to AMD's claim but the fine print is likely when compared at the same power or clock frequency.
Blender run comparison:
5950X used 105.4 kJ (477 seconds at 221 Watts)
7950X used 119.3 kJ (336 seconds at 355 Watts)
12900K used 198.9 kJ (536 seconds at 371 Watts)
13900K used 187.8 kJ (381 seconds at 493 Watts)
Interestingly, the doubling of the number of E-cores in the 13900K would appear to have improved Intel's position. Maybe Intel should ditch the P-cores altogether.
No HT, but increase the clocks?
While initially it sounds like a step backwards to me, I wonder what the actual impact would be?
“According to Intel, the space occupied by one P-Core is enough to fit in a cluster of 4 E-Cores plus a 4Mb L2 Cache.” https://techedged.com/intel-p-core-and-e-core/
I plan to resume my PRNG work next year after a lengthy hiatus. The code is locked, but constants and research paper need work.
In my day job, our group lead is retiring after 50 years, so I expect to at least partially fill the void.
No HT, but increase the clocks?
While initially it sounds like a step backwards to me, I wonder what the actual impact would be?
“According to Intel, the space occupied by one P-Core is enough to fit in a cluster of 4 E-Cores plus a 4Mb L2 Cache.” https://techedged.com/intel-p-core-and-e-core/
I'd heard that too, but eye-balling the die image says the E-cores ain't quite that compact. EDIT: Maybe the older 12 series E-core was smaller and fitted that description better.
I wonder how 2P+32E would go for gaming. It should work nicely for everything else and would be a little smaller in die area than the existing 8+16.
I plan to resume my PRNG work next year after a lengthy hiatus. The code is locked, but constants and research paper need work.
Gonna stick your neck out then.
In my day job, our group lead is retiring after 50 years, so I expect to at least partially fill the void.
That sure is a long time in one job. Work's not related to the above PRNG stuff, right?
@evanh said:
That sure is a long time in one job. Work's not related to the above PRNG stuff, right?
I just had my 30th anniversary this year, but I’ll likely retire well before my 50th. No relation to PRNGs. The related assembly language programming is just a hobby I picked up from the electronics engineer that designed the speech module prototypes for the Corvette in the early 1980s.
Evan,
A few pages back (in post #2682), I mentioned a drinking game, which I have implemented in VB6 for up to 32-bit PRNG outputs, but have yet to translate it to C/C++ (for 64-bit outputs).
It works very well for auto-correlation testing, negating the need for output rotations during initial vetting.
I will let you know when I finish the translation to C.
I have the preliminary results files for xoroshiro32pp_13_5_10_9, XORO32, and XOROACC32_modified, if you are interested (which I am still double-checking, and working on adding a T-score to P-Value conversion).
@evanh said:
The game itself sounded mind numbing, but then I've never seen any fun in tricking colleagues. Needless to say I don't frequent parties.
I haven't played it, but I recognized its potential for statistical analysis of PRNGs, substituting 4 sequential bits from a single bit position for each player. Currently, I have 12 mostly non-correlated statistical tests, each with 3 sub-statistics (so 36 stats total), which takes about 10 hours to analyze 1TB of 16-bit PRNG output (and 4 times as long for 32-bit output) when running 16 (or 32) processes.
@evanh said:
The game itself sounded mind numbing, but then I've never seen any fun in tricking colleagues. Needless to say I don't frequent parties.
I haven't played it, but I recognized its potential for statistical analysis of PRNGs, substituting 4 sequential bits from a single bit position for each player. Currently, I have 12 mostly non-correlated statistical tests, each with 3 sub-statistics (so 36 stats total), which takes about 10 hours to analyze 1TB of 16-bit PRNG output (and 4 times as long for 32-bit output) when running 16 (or 32) processes.
Evan,
I did finish the translation to C about a year ago (which works great for PRNG analysis), first using fork for threading, then mastering pthread, but for performance reasons I intend to go back to fork and implement shm_open/mmap, somehow back-porting other code improvements faithfully.
My renewed interest in taking this project off hold soon coincides with the release of the new Threadrippers.
Cheers!
Chris
Regarding XORO32 analysis, I've forgotten most of what I worked on sorry. I relied a lot on directions from Tony. I was very green to it and have zero stats background so some of the terminology went straight over my head.
@evanh said:
Regarding XORO32 analysis, I've forgotten most of what I worked on sorry. I relied a lot on directions from Tony. I was very green to it and have zero stats background so some of the terminology went straight over my head.
A quick recap of XORO32 for recent forum joiners. The XORO32 instruction has a 32-bit state and returns two consecutive 16-bit PRNs in the low then high words. The 16-bit period is 2^32-1 and each possible value occurs 2^16 times, except zero which occurs one time less. Any smaller group of bits within each word also has this equidistribution property.
The XORO32 output can be treated as single 32-bit PRN and the period is 2^32-2. (The low and high words switch halfway through and the full 16-bit period is iterated twice.) A 32-bit PRN and ~2^32 period means some outputs never occur and others occur more than once. Ideally, the number of non-occurring outputs should be exactly the same as the number that occur once only, equal to 2^32/e.
A lot of testing by Evan was done to find the 16-bit PRN for which two concatenated outputs best approximated an ideal 32-bit PRN with 32-bit state and performed very well in 16-bit tests. XORO32 is an artificial 32-bit PRNG and comes close but cannot match the 32-bit state & output PRNG below by Chris Doty-Humphrey, the writer of the PractRand PRN test suite.
unsigned int state = 1;
unsigned int get_rng_output() {
unsigned int tmp = state;
state ^= state << 13;
state ^= state >> 17;
state ^= state << 5;
tmp += (tmp << 18) | (tmp >> 14);//barrel shift and add
tmp += ((tmp << 7) | (tmp >> 25)) ^ ((tmp << 11) | (tmp >> 21));//two barrel shifts, an xor, and an add
return tmp ^ state;
}
@evanh said:
I take it you've completed something? That linked webpage doesn't function for me.
If you want to puruse 𝕏(formerly twitter) dot com , the everything app that will in the future supplant 50% of banking and also is the most accurate source of news and also the funniest...
@Wuerfel_21 said:
... the everything app that will in the future supplant 50% of banking and also is the most accurate source of news and also the funniest...
LOL, I take it that's quoting someone's marketing statement.
As for xcancel.com, it is working better than x.com. I can see 6 posts now. The "Load more" and "^" buttons don't do anything though.
@evanh said:
I take it you've completed something? That linked webpage doesn't function for me.
Yes, I have hit most of my required milestones for the stand-alone PRNG based on the discussions here, including a benchmark suite, and the niche statistical auto-correlation analyzer we discussed that simultaneously compares all bits against each other positionally and temporally. E.g., no rotation of PRNG outputs is required, and the optional vectorized AVX2 code was a beast to get right.
I edited the link above slightly so that individual post should be visible to anyone.
@Wuerfel_21 said:
If you want to puruse 𝕏(formerly twitter) dot com , the everything app that will in the future supplant 50% of banking and also is the most accurate source of news and also the funniest...
@evanh said:
I take it you've completed something? That linked webpage doesn't function for me.
Yes, I have hit most of my required milestones for the stand-alone PRNG based on the discussions here, including a benchmark suite, and the niche statistical auto-correlation analyzer we discussed that simultaneously compares all bits against each other positionally and temporally. E.g., no rotation of PRNG outputs is required, and the optional vectorized AVX2 code was a beast to get right.
I've tested xoroshiro32aox with 32-bit state and 16-bit PRNG output in x86 code. Although the software algorithm needs more instructions than xoroshiro32++ (the basis of the P2 XORO32 instruction), in hardware AOX is much smaller and quicker. However, the output values do not occur equally, unlike with the + or ++ scrambler (except all zeroes) but most of them occur close to 65336 times each. My tests show that groups of four outputs $0000-0003, $0004-0007, ..., $FFFC-FFFF occur a total of 65536 * 4 times, except $0000-0003 for which the total is 65536 * 4 - 1 (due to period being 2^32 - 1, not 2^32). I think this averaging over such a small number of outputs is remarkable.


Comments
You have B350 vs the A320 mentioned, correct?
Now I'm confused about 5000 CPU support, as the A320 notice is recent, so wouldn't B350 have been first?
Not sure about TPM 2.0, so hope it is present.
Motherboards without support will require a TPM add-in card for W11... unless you disable the TPM requirement, which I have seen discussed.
Two things:
1: I don't think there is any B350 motherboards yet supporting the Ryzen 5000 series CPUs. Only A320 motherboards so far.
2: However, I also found there is a recent updated BIOS for my B350 board when I looked on the website. But of course that's primarily just a defaults change so as to smooth the installation of Win11 by enabling TPM by default.
Then, what I discovered about TPM support is it seems to be fully functional - which I hadn't expected to find given the TPM slot in the motherboard is unpopulated. My conclusion is the required hardware is present in the Ryzen 1700X - has been there all along.
But, finally, the updated BIOS clearly contains more than just a default setting flipped. The menus haven't changed between the two BIOS versions but the compressed size has.
PS: Speculation online, for why only the A320 is getting this support, seems to be that the cheapest end of the market aren't likely to upgrade the whole kit to move from Zen/Zen+ to Zen3. Therefore the reasoning goes that AMD, and the board makers, are strategically providing this to get more CPUs, and RAM, sold without cutting into the newer motherboard sales.
Happy New Year!
Yep, Happy New Year to all. 13:00 here already.")
More 5000 on 300 series support banter: Here
Thanks.
The argument about a board's power capacity limit seems a little bogus to me. I can understand AMD having not verified all combinations of CPU and chipset on the simple basis of not bothering ... but to generally lump X370 and B350 boards as whimper than A320 boards does seem just a tad on the nose.
Pondering IC supplies ... My Geforce 960 is getting long in the tooth and I have been getting more interested in trying out a Radeon GPU on Linux. But haven't acted yet. I was eyeing up the 5600XT when they vanished due to covid19 supply shortages, then the 5700XT soon followed. I wasn't much interested in the 5500XT but sure enough even it went out of stock. The 6000 series is just too expensive and at any rate the 6500XT is only 4-channel PCIe, which is a problem when my mobo is limited to PCIe 3.0.
None of the 5000 series has reappeared since. As if production was stopped completely ... or at least not worth continuing at the old prices.
Lately, I've drawn up a PCB design with stepper motor ICs on board. Getting there wasn't as smooth sailing as usual ... The reference part I started with didn't have current limiting feature so I went a looking for something better ... every part I looked up was out of stock and not to be restocked for over a year. I knew that meant covid19 supply shortages and that even a year was a wild guess on their part.
What I ended up with, to get current limiting feature built in, is a part that also required a minimum of 20 volts supply. An awkwardly high minimum. Which told me it was a part that couldn't easily be exchanged into an existing board design ... therefore it hadn't been snatched up in the frenzy to ensure on-going parts supply.
Conclusion: The only ICs not out of stock are either a pricey narrow selection, or old stock that had virtually no turn-over.
It's a little surprising to me just how wide the IC shortages are. There doesn't seem to be anything unaffected. The early excuse about the auto-industry not up-dating is looking more and more bogus. A deflection from something else.
The 5950X is still an efficient CPU. Just been reading TechSpot's latest review - https://www.techspot.com/review/2552-intel-core-i9-13900k/
Comparing the 7950X in its default power config (Max power raised compared to the 5950X) it is driven to a notably higher clock frequency. This results in the 7950X being less efficient than the 5950X - Seemingly contrary to AMD's claim but the fine print is likely when compared at the same power or clock frequency.
Blender run comparison:
5950X used 105.4 kJ (477 seconds at 221 Watts)
7950X used 119.3 kJ (336 seconds at 355 Watts)
12900K used 198.9 kJ (536 seconds at 371 Watts)
13900K used 187.8 kJ (381 seconds at 493 Watts)
Interestingly, the doubling of the number of E-cores in the 13900K would appear to have improved Intel's position. Maybe Intel should ditch the P-cores altogether.
Maybe Intel should ditch the P-cores altogether.
No HT, but increase the clocks?
While initially it sounds like a step backwards to me, I wonder what the actual impact would be?
“According to Intel, the space occupied by one P-Core is enough to fit in a cluster of 4 E-Cores plus a 4Mb L2 Cache.”
https://techedged.com/intel-p-core-and-e-core/
I plan to resume my PRNG work next year after a lengthy hiatus. The code is locked, but constants and research paper need work.
In my day job, our group lead is retiring after 50 years, so I expect to at least partially fill the void.
Happy Holidays!
I'd heard that too, but eye-balling the die image says the E-cores ain't quite that compact. EDIT: Maybe the older 12 series E-core was smaller and fitted that description better.

I wonder how 2P+32E would go for gaming. It should work nicely for everything else and would be a little smaller in die area than the existing 8+16.
Gonna stick your neck out then.
That sure is a long time in one job. Work's not related to the above PRNG stuff, right?
I just had my 30th anniversary this year, but I’ll likely retire well before my 50th. No relation to PRNGs. The related assembly language programming is just a hobby I picked up from the electronics engineer that designed the speech module prototypes for the Corvette in the early 1980s.
You called it, but this efficient core beast will not be ready till next year:
https://tomshardware.com/news/intel-massive-lga7529-socket-pictured
Damn, that's a lot of pins!
Evan,
A few pages back (in post #2682), I mentioned a drinking game, which I have implemented in VB6 for up to 32-bit PRNG outputs, but have yet to translate it to C/C++ (for 64-bit outputs).
It works very well for auto-correlation testing, negating the need for output rotations during initial vetting.
I will let you know when I finish the translation to C.
I have the preliminary results files for xoroshiro32pp_13_5_10_9, XORO32, and XOROACC32_modified, if you are interested (which I am still double-checking, and working on adding a T-score to P-Value conversion).
The game itself sounded mind numbing, but then I've never seen any fun in tricking colleagues. Needless to say I don't frequent parties.
I haven't played it, but I recognized its potential for statistical analysis of PRNGs, substituting 4 sequential bits from a single bit position for each player. Currently, I have 12 mostly non-correlated statistical tests, each with 3 sub-statistics (so 36 stats total), which takes about 10 hours to analyze 1TB of 16-bit PRNG output (and 4 times as long for 32-bit output) when running 16 (or 32) processes.
Evan,")
I did finish the translation to C about a year ago (which works great for PRNG analysis), first using fork for threading, then mastering pthread, but for performance reasons I intend to go back to fork and implement shm_open/mmap, somehow back-porting other code improvements faithfully.
My renewed interest in taking this project off hold soon coincides with the release of the new Threadrippers.
Cheers!
Chris
Welcome back. Long time no hear.
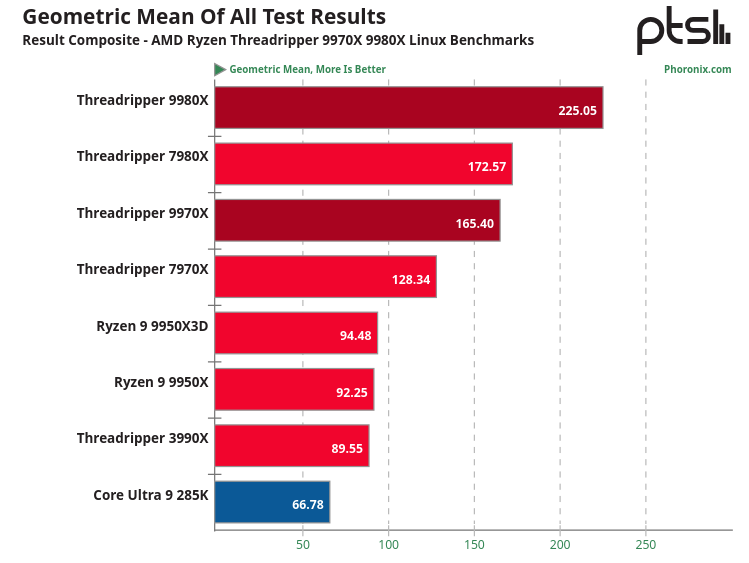
Drool! Michael @ Phoronix.com certainly demonstrated the uplift. Zen 5 has matured well. https://www.phoronix.com/review/amd-threadripper-9970x-9980x-linux/
A new build sounds expensive though. This XORO32 instruction work is the only compute I've ever done, so it would be totally wasted on me.
Regarding XORO32 analysis, I've forgotten most of what I worked on sorry. I relied a lot on directions from Tony. I was very green to it and have zero stats background so some of the terminology went straight over my head.
A quick recap of XORO32 for recent forum joiners. The XORO32 instruction has a 32-bit state and returns two consecutive 16-bit PRNs in the low then high words. The 16-bit period is 2^32-1 and each possible value occurs 2^16 times, except zero which occurs one time less. Any smaller group of bits within each word also has this equidistribution property.
The XORO32 output can be treated as single 32-bit PRN and the period is 2^32-2. (The low and high words switch halfway through and the full 16-bit period is iterated twice.) A 32-bit PRN and ~2^32 period means some outputs never occur and others occur more than once. Ideally, the number of non-occurring outputs should be exactly the same as the number that occur once only, equal to 2^32/e.
A lot of testing by Evan was done to find the 16-bit PRN for which two concatenated outputs best approximated an ideal 32-bit PRN with 32-bit state and performed very well in 16-bit tests. XORO32 is an artificial 32-bit PRNG and comes close but cannot match the 32-bit state & output PRNG below by Chris Doty-Humphrey, the writer of the PractRand PRN test suite.
unsigned int state = 1; unsigned int get_rng_output() { unsigned int tmp = state; state ^= state << 13; state ^= state >> 17; state ^= state << 5; tmp += (tmp << 18) | (tmp >> 14);//barrel shift and add tmp += ((tmp << 7) | (tmp >> 25)) ^ ((tmp << 11) | (tmp >> 21));//two barrel shifts, an xor, and an add return tmp ^ state; }Public thank you Evan and Tony for your assistance: Here")
Yes, I work at a snail's pace.
I take it you've completed something? That linked webpage doesn't function for me.
If you want to puruse 𝕏(formerly twitter) dot com , the everything app that will in the future supplant 50% of banking and also is the most accurate source of news and also the funniest...
... without creating an account, you can change the URL to xcancel.com : such as https://xcancel.com/CerianKnight/status/1996768555019239868?s=20
LOL, I take it that's quoting someone's marketing statement.
As for xcancel.com, it is working better than x.com. I can see 6 posts now. The "Load more" and "^" buttons don't do anything though.
Yes, I have hit most of my required milestones for the stand-alone PRNG based on the discussions here, including a benchmark suite, and the niche statistical auto-correlation analyzer we discussed that simultaneously compares all bits against each other positionally and temporally. E.g., no rotation of PRNG outputs is required, and the optional vectorized AVX2 code was a beast to get right.
I edited the link above slightly so that individual post should be visible to anyone.
Hey, that is pretty handy.
Cheers!
Please post your final results here, thanks.
I've just found out that the xoroshiro algorithm as used in the P2 has been implemented in hardware with a novel scrambler that uses AND, OR and XOR instead of addition or multiplication. For details of xoroshiro128aox please see
https://www.jameswhanlon.com/the-hardware-pseudorandom-number-generator-of-the-graphcore-ipu.html or https://arxiv.org/pdf/2203.04058 (PDF)
I've tested xoroshiro32aox with 32-bit state and 16-bit PRNG output in x86 code. Although the software algorithm needs more instructions than xoroshiro32++ (the basis of the P2 XORO32 instruction), in hardware AOX is much smaller and quicker. However, the output values do not occur equally, unlike with the + or ++ scrambler (except all zeroes) but most of them occur close to 65336 times each. My tests show that groups of four outputs $0000-0003, $0004-0007, ..., $FFFC-FFFF occur a total of 65536 * 4 times, except $0000-0003 for which the total is 65536 * 4 - 1 (due to period being 2^32 - 1, not 2^32). I think this averaging over such a small number of outputs is remarkable.