

SPI shift_in and shift_out are slow in Propeller C on a Propeller1
 CJR
Posts: 6
CJR
Posts: 6
I am using a FLIP module (propellor1) and the PropellerC "shift_in" and "shift_out" functions to communicate with a MCP3008 ADC chip. The code first sends a 5-bit command to the MCP3008 to sample via "shift_out" then immediately uses "shift_in" to receive an 11-bit result (the chip sends a null as the 1st data bit). This process takes about 1.24 msec to complete resulting a maximum sampling rate of about 800 Hz. This is surprisingly slow for a MCP3008 that has a specification of 75 kips at 2.7v supply. Does anyone know how to speed up SPI communication on the propeller? The interface on the propeller is 100 time slower than the chip specification. Is this expected? The code looks like ...
int mcp3008_read(char c)
{
int i; // 32 bit Propeller integer and float have 32 bits
i = 0x18 | c; // Assembles ADC input command
low(mcpCS); // mcpCS set low to select ADC
// shift_out with MSBPOST stands for most significant bit first & data valid after pulse
shift_out(mcpDIN, mcpCLK, MSBPOST, 5, i); //Sends "i" as "1,1,x,x,x"
// so each bit is read when clock level goes high to low, "null" bit plus 10 data bits
i = shift_in(mcpDOUT, mcpCLK, MSBPOST, 11); // get ADC result in MSBPOST format
high(mcpCS); // Deselects ADC
return i; // Returns ADC count value
}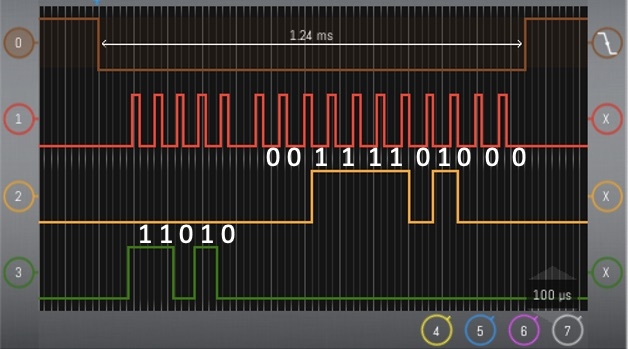
Data Signal (2) reads “00111101000” = 48810 = 1569mv @ vref = 3290mv and agrees with my voltmeter.
Comments
Sure. Write an assembly driver that runs in its own cog. Note that the SPI speed may be impacted by the memory model you're using.
Jon, as usual, hit the nail on the head -- the memory model (LMM, CMM, etc.) has a big impact on performance of C code. Another factor is that the simpletools library (which contains shift_in and shift_out) was written to be clear and readable, rather than especially performant. Even in C you could write faster routines for doing SPI, although ultimately for the best in performance using PASM in a COG can't be beat (it might almost be equalled by some carefully crafted C code though).
If you're comfortable with C++ it's definitely worth looking at @DavidZemon 's PropWare library ( https://github.com/parallaxinc/PropWare ). He uses inline assembly and some other tricks to get very good performance.
Thanks for the call out.
@CJR, you'll need to copy a few supporting files to go with it (spi.h, being a key one), at which point I don't know if it's worth it for you or not, but PropWare does have an object dedicated to the MCP3000 series of chips: https://github.com/parallaxinc/PropWare/blob/develop/PropWare/sensor/analog/mcp3xxx.h
You'll find the SPI code under the "serial" directory.
The MCP3008 holds a special place in my heart. It was, I think, the first ever peripheral I communicated with from a microcontroller... It took me a long time to realize it's simplicity was nothing special... But I still love it 😁
Thank You for your suggestions. I will take a look. Can you point me to a tutorial and ot instruction for using PASM or Spin in a cog with the retest of the code written in C?
I have libraries already built for MCP3000.
#include "simpletools.h" #include "mcp3000.h" #define CS 5 #define CLK 4 #define DOUT 3 #define DIN 2 #define REFV 5 int main() { int i, j; mcp3000_open(CS, CLK, DOUT, DIN); while (1) { i = mcp3202_read(0); j = mcp3202_volts(REFV, 0); printi("Port 0: %d, (%d)mv", i, j); i = mcp3202_read(1); j = mcp3202_volts(REFV, 1); printi(" Port 1: %d, (%d)mv\n", i, j); pause(1000); } }The default SPI driver is built to allow different order of the data which in turn can slow the data down but allows it to work with many different devices.
I need to speed up the out going data as I need to update a display with data. Here is a sample of that code which only works with the display.
void __attribute__((fcache))spi_out(int bits, int value) { unsigned long b; int i; b = 1 << (bits - 1); for(i = 0; i < bits; i++) { if ((value & b) != 0) OUTA |= _DMask; else OUTA &= _Dmask; OUTA &= _Cmask; OUTA |= _CMask; OUTA &= _Cmask; b = b >> 1; } }I have not built a fast SPI driver for the MCP3000 as it seemed unnecessary for this device.
If you need help finding a driver for your process let me know.
Mike
This philosophy of "to get speed, I must run it in a different cog" is a carry over from the Spin world, where a cog must choose between "fast" (PASM) or "easy" (Spin). In the PropGCC world, we are not held down by such limitations. We can run both fast (assembly) and easy (C/C++) code in the same cog.
The fcache is a great way to get native execution performance (PASM performance) with minimal effort (see @iseries examples above). If and only if you find yourself needing even higher performance, or more compact code, you can make the jump to fache and inline assembly, as demonstrated by PropWare's SPI object. Combining these two is an ugly beast, but very powerful (see PropWare::SPI for fcache/inline assembly example).
That all being said, if you want to use the same model as Spin, where a separate cog runs your fast (PASM) code, you can do so with a ".cogc" file. I wasn't actually able to find any simple and straight forward examples of this... I know they're out there, but my Google fu failed me. Hopefully someone else can chime in and provide a link to the appropriate docs. In the meantime, here's the in-depth documentation: https://github.com/parallaxinc/propgcc-docs/blob/master/doc/InDepth.md