

Turbo Bytecode Blowout - Interpret hub bytes in 8+ clocks!
 cgracey
Posts: 14,297
cgracey
Posts: 14,297
I had an idea over the weekend. No, there is not some new instruction. It's more devious than that. And it's already implemented and tested.
We can now interpret bytecodes from hub with only 6 clocks of overhead, including the _RET_ at the end of the bytecode routine. This means that minimal bytecode routines, which consist of only one 2-clock instruction with a _RET_, can execute at the pace of 8 clocks per bytecode, with bytecodes being fetched from hub and the bytecode routines located in the cog and LUT.
Here's how it works:
If a RET/_RET_ occurs when the stack holds $001F8 or $001F9 (that's PTRA or PTRB, which you'd never want to actually RETurn to), the stack is not popped and a special sequence begins that does a hidden RFBYTE to fetch the next bytecode, a hidden RDLUT to look up its table entry, and a hidden EXECF to branch to its routine with a SKIPF pattern initiated.
Here is the sequence, starting from the last clock of the last instruction in the current bytecode routine (or the instruction that kicks off the process):
If you look at this program for 30 seconds, you'll see how it's working:
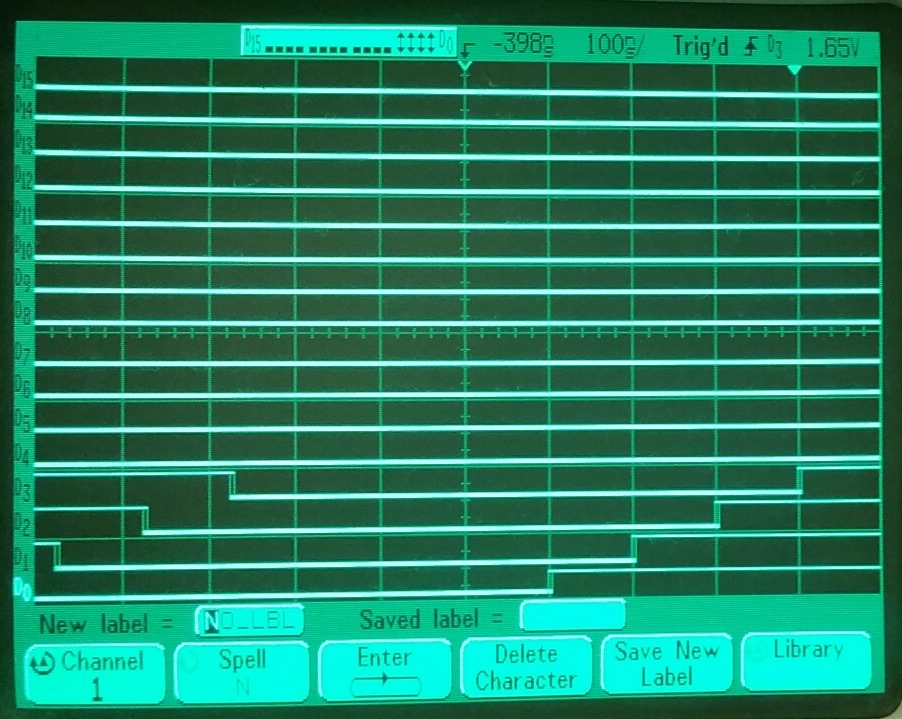
And here is a scope picture of it executing. You can see that those pin toggles are occurring every 100ns, or 8 clocks at 80MHz. The branch takes longer, since it must reinitialize the FIFO read:
If you use $1F8 as the RETurn address, the first half of the LUT will be used as the EXECF table. If you use $1F9, the second half of the LUT will be used. This means you can shift gears any time by doing either a '_RET_ PUSH #$1F8' or a '_RET_ PUSH #$1F9' to switch between two different tables.
This XBYTE mechanism is going to make Spin2 really fast.
We can now interpret bytecodes from hub with only 6 clocks of overhead, including the _RET_ at the end of the bytecode routine. This means that minimal bytecode routines, which consist of only one 2-clock instruction with a _RET_, can execute at the pace of 8 clocks per bytecode, with bytecodes being fetched from hub and the bytecode routines located in the cog and LUT.
Here's how it works:
If a RET/_RET_ occurs when the stack holds $001F8 or $001F9 (that's PTRA or PTRB, which you'd never want to actually RETurn to), the stack is not popped and a special sequence begins that does a hidden RFBYTE to fetch the next bytecode, a hidden RDLUT to look up its table entry, and a hidden EXECF to branch to its routine with a SKIPF pattern initiated.
Here is the sequence, starting from the last clock of the last instruction in the current bytecode routine (or the instruction that kicks off the process):
clock phase hidden description ------------------------------------------------------------------------------------------------------- 1 go RFBYTE last clock of instruction which is executing a RET/_RET_ to $1F8/$1F9 2 get RDLUT 1st clock of 1st cancelled instruction 3 go LUT --> D 2nd clock of 1st cancelled instruction 4 get EXECF (D = LUT) 1st clock of 2nd cancelled instruction 5 go EXECF branch 2nd clock of 2nd cancelled instruction 6 get flush pipe 1st clock of 3rd cancelled instruction 7 go flush pipe 2nd clock of 3rd cancelled instruction 8 get 1st clock of 1st instruction of bytecode routine, clock 1 next if _RET_
If you look at this program for 30 seconds, you'll see how it's working:
' ' ** XBYTE Demo ** ' Automatically executes bytecodes via RET/_RET_ to $1F8. ' Overhead is 6 clocks, including _RET_ at end of routines. ' dat org setq2 #$FF 'load bytecode table into lut $000..$0FF rdlong 0,#bytetable rdfast #0,#bytecodes 'init fifo read at start of bytecodes _ret_ push #$1F8 'start xbyte, no stack pop if $1F8/$1F9 ' ' Bytecode routines ' r0 _ret_ drvn #0 'toggle pin 0 r1 _ret_ drvn #1 'toggle pin 1 r2 _ret_ drvn #2 'toggle pin 2 r3 _ret_ drvn #3 'toggle pin 3 r4 getptr x 'get current rdfast address rfbyte y 'get byte offset | rfword y 'get word offset | one of these three rflong y 'get long offset | add x,y 'add offset | one of these two sub x,y 'sub offset | _ret_ rdfast #0,x 'init fifo read at new address ' ' Variables ' x res 1 y res 1 orgh ' ' Bytecodes that form program ' bytecodes byte 0 'toggle pin 0 byte 1 'toggle pin 1 byte 2 'toggle pin 2 byte 3 'toggle pin 3 byte 7, $-bytecodes 'reverse byte branch, loop to bytecodes ' ' Bytecode EXECF table gets moved into lut ' bytetable long r0 '#0 toggle pin 0 long r1 '#1 toggle pin 1 long r2 '#2 toggle pin 2 long r3 '#3 toggle pin 3 long r4 | %0_10_110_0 << 10 '#4 forward byte branch long r4 | %0_10_101_0 << 10 '#5 forward word branch long r4 | %0_10_011_0 << 10 '#6 forward long branch long r4 | %0_01_110_0 << 10 '#7 reverse byte branch long r4 | %0_01_101_0 << 10 '#8 reverse word branch long r4 | %0_01_011_0 << 10 '#9 reverse long branch
And here is a scope picture of it executing. You can see that those pin toggles are occurring every 100ns, or 8 clocks at 80MHz. The branch takes longer, since it must reinitialize the FIFO read:
If you use $1F8 as the RETurn address, the first half of the LUT will be used as the EXECF table. If you use $1F9, the second half of the LUT will be used. This means you can shift gears any time by doing either a '_RET_ PUSH #$1F8' or a '_RET_ PUSH #$1F9' to switch between two different tables.
This XBYTE mechanism is going to make Spin2 really fast.
Comments
You are on a roll, with these clever things to make bytecode execution super fast. It's almost to the point of having a bytecode engine in hardware, except better because it's fully customizable to whatever bytecode you want.
Yes, this is going to make it really easy to build bytecode interpreters. It automates the bare-bones behavior and you just write snippets to give bytes their personalities. For all those guys that like to make Z-80 and 6502 emulators...
But, what?!
"...those pin toggles are occurring every 100ns, or 8 clocks at 80MHz."
The RISC V core I'm playing with takes 4 clocks to execute just one of it's native code instructions. Loads and stores are a bit more.
This XBYTE mechanism can read a byte from hub, lookup that byte's routine address and skip pattern in the LUT, and start executing it, all with a 6-clock overhead. For routines which are just a 2-clock instruction with a _RET_, the whole affair takes 8 clocks per byte. You get to write the routines for each byte. Very simple.
Did you look at CIL bytecodes using this engine yet ?
https://en.wikipedia.org/wiki/List_of_CIL_instructions
Was this a hardware change, or pure software optimizing ?
That FIFO phase looks to be ~ 375ns or appx 30 SysCLKs ?
HyperRAM or even QuadSPI.DDR could deliver high byte-code feeding speeds, in a straight line.
80MHz DDR would be able to do up to 160MBytes/sec, burst.
I can see how nice it is to be able to define quickly a meaning for an "I/O list" (actually an "I/O program") = a custom mini-language.
But to compensate for the level of "magic" in this
maybe it would be useful to block actual attempts to execute *any* address in the 1F8--1FF range.
And in general, to trap (halt cog?) any attempt to execute illegal instructions.
Example: RETA with DDDDDDDDD != 000000000.
This could be important for extensibility:
what you don't forbid/reject from the beginning can *not* be reinterpreted later,
people will rely on it doing nothing, or,
in the above example, the DDDDDDDDD value being ignored.
The Linux kernel developers learnt the lesson the hard way: the unused/reserved flags could not be used/re-purposed later if they were not rejected from the beginning.
They had to define new system calls, even if the old syscall would have been perfectly fine (had all needed parameters, no addition necessary).
User programs started to rely on having the kernel ignore "junk" values in the unused/reserved flags,
so it became unsafe to give a meaning to an unused flag since the new meaning/effect might be triggered by unsuspecting user programs.
Rejecting illegal instructions seems important for any attempt to discuss IEC60730
(I don't know what it actually requires, but intuitively detecting and rejecting illegal instructions should be part of it).
Is there a way for the executing routine to access the original byte that was automatically fetched? Bytecodes sometimes have data encoded in them, and it would be more space efficient to read that data right out of the bytecode rather than having to encode different versions of the instruction for each variant of data.
Also; loath as I am to suggest anything that would delay the chip, it seems like it would be prudent to implement at least one bytecode interpreter whose instruction set was not designed with this mechanism in mind, just to see what (if any) gotchas arise. The JVM or CIL are probably way to complicated for that, but perhaps you could try out the ZPU bytecode? @Heater had that running on P1, and it has a GCC port (so it would be a quick way to get C up on the P2).
You could conceivably embed data in the bytecode stream itself. Since he's using RFxxx, you could simply call RFBYTE (etc.). In the the case where the embedded data is optional, no problem: you have two different byte codes that jump to the same routine, but with two different skip tables (one that calls RFBYTE, and the other that doesn't).
Actually, I think he's doing exactly that in the "r4" routine above.
What? You want to wake up Zog again?
Sure, if you define the bytecode format yourself you could do that. But if you're trying to emulate an existing CPU or virtual machine you don't get to define the bytecodes. Moreover, for some really common operations (like pushing small constants) you can get much better code density by putting the data into the bytecode.
Why not? It's a pretty simple bytecode, seems like a good fit for this.
Did you ever get the little-endian version of zpu-gcc working? Byte swapping seems like it could be a significant bottleneck in a P2 ZPU interpreter.
Eric
I might give it a look. Thing is I already started day dreaming about a RISC V emulator for the P2. That has a pretty small instruction set. Although it has some funky instruction formats to deal with. What better way to get acquainted with the P2 instruction set than write an emulator? Also the RISC-V is always going to have well supported and up to date GCC and LLVM compilers.
Actually I don't recall anything about ZPU endianness now.
The RISC-V ISA is nice, but the instruction layout seems to be optimized for hardware decode rather than software. Might be a bit tricky. Of course, that's never stopped you
The ZPU is big-endian by default, and so in ZOG you byte-swapped all the longs and then had to apply some hackery to the instruction fetch to get the correct bytes. Near the end of the ZOG thread I think you said you had a little-endian version of the compiler that would avoid that unpleasantness, but then the thread kind of drifted off to sleep and it never got posted (I guess that was when PropGCC was becoming a useful thing). I've googled a bit but the only mention I see of a little-endian zpu gcc is a comment in the gcc commit log that little endian was being disabled because it required a library rebuild.
Eric
Or, maybe just a new alias name for that...
But, can't we use the new funky SKIP mechanism to selectively execute the required codes that extract the fields from the different instruction types? Thus saving a lot of decisions and jumps.
I have not looked at the details, just speculating...
Is this new feature going to help with real time emulation of that?
If I understand correctly, it's *any* RETurn to one of the special addresses #$1F8 or #$1F9 that triggers the "magic".
"_ret_ push #$1F8" just primes the pump, so to speak.
This is why I think it would be useful to block actual attempts to execute *any* address (register, more correctly?) in the 1F8--1FF range.
These may contain a code address, but not an instruction.
The idea is to detect obvious "junk" values in the internal call stack.
A 6502 should fly using this.
Making this into an instruction would actually slow it down. I realized that to cut the cycles down, it needed to be overlapping pipeline cancellation cycles. It's as fast as I can make it now.
Chip, an interesting variant of this would be a case where you could get it to read the bytecode, and mask it before doing the LUT lookup. So that the, for example, lower 4 bits of the bytecode did the lookup, but then the upper 4 bits could be read as data in the routine (from the PA/PB registers). Then you don't have to fill the LUT with a bunch of the same values to get the same result. Perhaps the mask could be something preloaded with a setq or similar?
P2 does have two oscillators, but I think no hardware watchdog & no oscillator fail detection.
It may require a complete COG, dedicated to COP tasks, to give some IEC60730 tick-boxes.
Of the two, 6502 should be the simplest and fastest. Z80 has a few pretty complicated instructions. Well, maybe. There is decimal mode on 6502, which may take some thinking.
When we get this, I may do part of a 6502. I think it will be over 2Mhz, and that's roughly a 4Mhz Z80.
Below are the CIL ones, with constant groups, these do not seem to fit a simple mask step, but they are sequential, so look to need an add/subtract somewhere, along with the mask ?
The function calls to get full working systems are a different story, but just the core-engines could be tested ?
As mentioned above, the final timing of bytecodes will vary upwards from the base of 8 clocks.
I used PropGCC also, but never really programmed in C professional. After the Mainframe-time with COBOL I went quite abruptly into C# so I really would like to see a CIL bytecode interpreter, but sadly I am not (yet?) able to write one.
David and Eric seem to be a little frustrated, on one side because of the constant nagging about C here in the forums, but also because of constant op-code changes. What I think is needed (besides financial support from Parallax) is some cheering on to get those two highly qualified persons to start working on it again.
C on the P1 was a stepping stone to have C running on the P2 from the beginning, and even if I have a hard time with C by myself, supporting C on the P2 is a main goal for the money making education support Parallax does.
Dave mentioned a couple of times that the CMM memory model could benefit from some decode instruction to expand CMM-Byte-Codes to PASM instructions. I just loosely followed the PropGCC discussions at that time, but CMM on the P1 is usually faster as Spin on the P1 and has a comparable small memory footprint.
Since I never wrote a compiler by myself, and am not versatile in C, I have just to guess how much work is needed to support C on the P2.
But slowly I get the feeling that Chip is finalizing the op-code changes, so it might be REALLY important to explain to him what changes would be helpful to support the code generator of GCC. One thing I remember was the LINK register, and that is done. But besides the CMM decode instruction there might be other things able to be streamlined in Verilog to support GCC code generation better.
So writing SPIN2 showed some new needed instructions/shortcuts to really speed up things. For that reason I think it is quite important, needed and necessary to work on GCC before any Verilog code freeze.
There might be a equivalent speed gain possible for GCC, and nobody knows it now because nobody is working on it.
just my 2 cents.
MIke
Of course that does not exclude also doing some other code generation for C.
Alternatively, if P2 is able to run CIL bytecodes, it will pick up a shipload of languages right there.