I tried the simple triangle drawing. The time depends on the size: the bigger the triangle, the better the time for one pixel - as expected. For a triangle 100 pixels high and 200 pixels wide at the bottom, I got 7 clocks per pixel for execList call (that I made PUB to call from the test program)
The biggest test triangle I tried was 512 px high, 1024 px wide and it took about 5 ms to draw, about 6 clocks per pixel.
Now I need a fast procedure to prepare the list for any given triangle and that procedurew should be as fast as possible (=asm)
The program on the attached video displays some test texts to check if the driver works OK, waits 5 seconds and then draws 256 triangles to test if drawing in a loop can corrupt the driver (that didn't happen yet)
sub testtriangle
var pixels=0
for j=0 to 255
for i=0 to 511
list(4*i)=$C000_0000+v.buf_ptr+1024*i+(511-i)
list(4*i+1)=j
list(4*i+2)=2*(i+1)
list(4*i+3)=varptr(list(4*i+4))
pixels+=2*(i+1)
next i
list(2399)=0
i=getct()
psram.execlist(mbox,varptr(list),0)
'i=getct()-i: print i: print i/337 : print i/pixels
next j
end sub
@Wuerfel_21 said: Finally made it work. I only wrote the converter tool and changed the Spin code to match, but that's already enough to push it to 30 FPS (2 vsync per rendered frame).
Neat. I wonder if higher resolutions beyond 320x240 could work if the final image is stored in PSRAM where there is plenty of space. Does the entire frame buffer need to be rendered into HUB first or could each scan line or smaller portion of the frame be copied into PSRAM as it loads the frame in PSRAM, reducing the HUB RAM requirements? Would you envisage bandwidth issues for that?
You could have it write the individual spans to the PSRAM, but that has big overhead and won't work with any sort of masking/transparency. Another option is to render 320x240 quarter screens and combine them into a final 640x480 frame. Will need additional bucket memory for that. Either way filling 4x the pixels + extra overhead -> very slow -> dubiously useful.
@pik33 said:
Now I need a fast procedure to prepare the list for any given triangle and that procedurew should be as fast as possible (=asm)
Doing this correctly (i.e. such that adjacent triangles meet their edges exactly, without gaps or overdrawn pixels) is actually not easy, especially when you add sub-pixel precision into the mix (which is needed to avoid jittery animation). For single triangles the correct rasterization tends to look weird.
Nugget of useful code: Triangle area calculation without rounding.
The canonical formula is 0.5 * abs( (x2 - x3) * (y1 - y3) - (x1 - x3) * (y2 - y3) ).
We also want the sign before taking the absolute - this is the triangle winding (clockwise or counter-clockwise) which is needed for backface culling!
Latest version I posted has this straightforward code, with rounding of the product terms (bad):
abs tmp1,x23 wc ' X differences are 16 bit safe
mul tmp1,y13 ' Y differences always positive due to sorting
shr tmp1,#1
negc dxy,tmp1
abs tmp1,x13 wc
mul tmp1,y23
shr tmp1,#1
sumnc dxy,tmp1
abs dxy wc ' This has the area
bitc flags,#31 ' This has the sign
(I've omitted the part that calculates the XY differences for brevity - as commented, this (currently) happens after vertex Y sorting (not really a good idea) so the Y differences are all positive)
My notes:
For geometrically obvious reasons, a triangle with vertices at 16-bit 2D coordinates can not have an area larger than 0x7fff0000. In practice we want the double area, since it's easier to compute and won't round the smallest possible triangle (half-unit area) to zero. The upper bound for that is 0xfffe0001 (?).
Depending on signs, the final area is either the sum or difference of the two absolute products. The sum at first appears like it could overflow, but the constraints of the operands make this impossible.
Cracked version without rounding:
abs tmp1,x23 wc
mul tmp1,y13
bitc flags,#31
modz _c wz
abs tmp2,x13 wc
mul tmp2,y23
modcz _clr,_c_ne_z wcz ' do ADD if signs were different, SUB otherwise
if_z add tmp1,tmp2 ' looks like it could overflow, but actually can't with correctly constrained differences
if_nz sub tmp1,tmp2 wc ' C set if tmp2 was larger than tmp1
negc dxy,tmp1 ' (negate in that case)
if_c bitnot flags,#31
(sadly one additional instruction...)
Might look slightly different if it had to take sign of Y differences into account - in that case it'd be better to write some more bits of flags and use the parity flag from TEST to great effect.
Nice, Ada! Programming like this is fun for me, because it's all about how much functionality can be squeezed out of the smallest number of instructions.
@cgracey said:
Nice, Ada! Programming like this is fun for me, because it's all about how much functionality can be squeezed out of the smallest number of instructions.
Yes, I like that, too.
Unrelatedly, first results from implementing geometry in PASM:
Geo time may increase to more like 3000µs when I add texturing back in. Gradient calculation is awful ;3 But vertex projection already deals with texture coordinates and also happens to not yet be optimized (unpipelined QDIVs). There's also optimization potential elsewhere. (OTOH a lot of things are just missing/hardcoded)
Raster should be 3000 to 4000 (same as current posted version). It's faster now because it's just solid filling (but backface culling is off, eating most of the benefit).
Also take note of the 2000 µs mystery time that's in E2E but doesn't come from actual GEO or RAS work time. I think that's mostly waiting on the PSRAM screen upload (slow-ish because this is @MXX board with 8 bit RAM bus, would be faster on P2EDGE). That's where audio processing could happen on the same 4 graphics worker cogs.
So the 60 FPS goal I set earlier is within reach now (that's at ~16600µs per frame for those playing along at home)
I also figured out a neat way to calculate the 1/Z-related values as "floating point" by normalizing Z before dividing. More on that when I get it working.
Can you save an additional instruction by combing the add/sub in this code:
abs tmp1,x23 wc
mul tmp1,y13
bitc flags,#31
modz _c wz
abs tmp2,x13 wc
mul tmp2,y23
modcz _clr,_c_ne_z wcz ' do ADD if signs were different, SUB otherwise
if_z add tmp1,tmp2 ' looks like it could overflow, but actually can't with correctly constrained differences
if_nz sub tmp1,tmp2 wc ' C set if tmp2 was larger than tmp1
negc dxy,tmp1 ' (negate in that case)
if_c bitnot flags,#31
into sumnz in this:
abs tmp1,x23 wc
mul tmp1,y13
bitc flags,#31
modz _c wz
abs tmp2,x13 wc
mul tmp2,y23
modcz _clr,_c_ne_z wcz ' do ADD if signs were different, SUB otherwise
sumnz tmp1,tmp2 wc ' looks like it could overflow during add, but actually can't with correctly constrained differences, for subtract C=1 if tmp2 was larger than tmp1
negc dxy,tmp1 ' (negate in that case)
if_c bitnot flags,#31
The modcz seems to be clearing C previously anyway so the sumz operation in the add case writing C=0 won't change that, and as you mentioned that the C flag can only overflow in the subtract case with correctly constrained differences but maybe I am missing something important from your explanation.
So for the earlier demo I always just set 1/Z to a constant (essentially doing affine shading / texture mapping). Now that I'm trying to do it properly the headaches are starting:
This is with "fog" shading towards white for clarity. Each vertex of these buggy triangles has L = $FF_FF (this is an 8.8 fixed point value). When L/Z and 1/Z are calculated for the vertex, they're scaled such that (L/Z) / (1/Z) = $FF.
The problem is that due to rounding error in the gradients, (L/Z)' / (1/Z)' = $100 for some pixels in the triangle (since the original fixed-point value was almost $1_00_00 to begin with) and this overflows the 8 bit PIV register.
I could clamp L to $FF_7F or something to mostly ignore this problem, but I feel like there's a deeper insight wrt. rounding here that would fix it properly.
EDIT because forgor 💀 : There's another problem related to small triangles overflowing the gradients, which required me to chop 4 bits of precision off everything (I think in the screenshot I have it at 8 because that makes the PIV overflow problem more visible - it really only needs SUB_PREC (which is sufficient at 4) bits of headroom). That might also be solvable.
Though the hackneyed clamp solution does work for this particular demo, so I'm shipping it. Here you go, 60 FPS spinning teapot (full of unfinished code)
This consistently gets frametimes under 10000µs, so it's ~3 times faster overall than teapot_demo2. (This is with major pain sites in vt_project and tri_setup_texlit)
Very nice and seems silky smooth on my LCD monitor with VGA. 👏
Would love to see it in a higher resolution although the 320x240 res gives it that retro demo scene vibe. Just needs some crazy dynamic resizing and scrolling credits to go along with it plus some wicked music and you'll be there.
@rogloh 320x240 is the target because it fits in RAM and is viable for drawing actual scenes (i.e. not just one object floating on a solid fill background) at good speed. You can get some metrics printed by enabling -gbrk. (note that the 3 solid triangles in the background count towards this, comment them out for accuracy). ras_pixels is total pixels drawn by that cog. For texture+light+dither, this costs 56 cycles a pop (limited by CORDIC pipeline). ras_scanlines is scanlines rasterized (some may not have actual pixels to draw), maybe 50 cycles for raster + another 80 for setup to actually draw (guesstimate) ras_prims is total triangles processed, I'd guess this is at ~250 (note that each cog has to load every primitive command...)
If you were go to 640x480, you'd have twice the ras_scanlines and four times the ras_pixels. You'd also run out of RAM for framebuffer.
In teapot-related news, here's a "3.1" version of the demo, collecting a few low-hanging improvement fruits:
Aforementioned vt_project optimization (still some cycles on the table there)
Saved another ~200µs in gradient calculation
Tweaked PSRAM driver settings for better performance (apparently the burst length setting is half the actual burst length??)
So this is 521µs faster GEO (2750 -> 2229), ~100µs faster screen upload (really?). RAS currently unchanged.
(All measurements with teapot at zero angles, which is a quite quick to begin with)
Other fun fact: vertex processing is really cheap! Disabling calls to tran_nrm and do_envmap only shaves off 100µs, so there's some headroom for features like dynamic lighting.
Other interesting development: Despite failing at this earlier, I have devised a faster variant of the texture mapping routine. This one is 48 cycles instead of 56 (15% faster?), with the constraint that L (the PIV register value) is constant. However, that required rearranging the loop such that it's more pipelined, which increases startup overhead somewhat (single pixel may be slightly slower, need to measure).
This saves rather little time (~148µs) on the teapot demo (it's very overhead-heavy) and gets rid of the nice AO, so in that sense it doesn't look so hot. Where this would come in real useful is drawing something like a sky texture, which fills most of the screen and doesn't need shading to begin with. This could also be opportunistically selected instead of the 56 cycle routine when L just happens to be constant. Check for that would require some shuffling of the triangle setup code that'll likely make it slightly slower though, as that decision needs to be made before allocating memory (since the const-L command would be 11 bytes shorter).
A 40 cycle routine wherein I'd get rid of the MIXPIX (and the BITNOT that modifies it - 9cy total) may be possible, too, but would cause problems for both of the aformentioned usecases because the colors are then no longer dithered.
Also, I used to (in earlier testing before I took a detour into investigating Quake-style subdivision that didn't turn out in the end) have a routine that did the opposite, in a sense (texture replaced with constant color, L gradient shading on top) that ran 24 cycles. If I added that one and changed the current solid routine to do dithering (instead of taking a literal 16bpp color), I think that'd be an orthogonal set, wouldn't it?
I've finally run the demo. Had to slow the default rotation rates to stop it making me dizzy. Smooth as.
else
yaw += 1<<22
roll += 1<<20
Question: Does it actually need extra RAM? I note the default config is for Rayman's 96 MB memory expansion, but the binary isn't huge and it doesn't load anything extra. I'm guessing the demo is more an experiment at using external RAM for doing texturing.
On that note, I've always wondered what can be done, looks wise, with just fancy shading and no textures.
@evanh said:
Question: Does it actually need extra RAM? I note the default config is for Rayman's 96 MB memory expansion, but the binary isn't huge and it doesn't load anything extra. I'm guessing the demo is more an experiment at using external RAM for doing texturing.
External RAM is only currently used to buffer the final frames. I want to eventually have pretty much everything going through the PSRAM, so you can have at least 256K of RAM for your actual application (should also figure out how to get flexspin to compile overlays to further improve hub RAM utilization)
On that note, I've always wondered what can be done, looks wise, with just fancy shading and no textures.
In modernTM graphics, the textures are often just an exercise in pre-computation (it's a lot easier to generate matching high-res diffuse/normal/rough/metallic maps procedurally than attempting to create them from photos or drawing them by hand).
Textures also have free/automatic LOD and anti-aliasing that you don't get when creating details with actual geometry or shader math (you can see this in certain newer games - wherein someone gets the idea to e.g. fully model a grating, which then proceeds to horribly flicker, because antialiasing geometry is hard)
Back to the P2 and it's amazing "shaders", the texture lookup (given the already calculated UV) is fairly cheap on a per-pixel basis. Not sure how it'll work out when I add caching in the textures from PSRAM. Certainly will have trouble with these huge 256x256 ones, but 64x64 is probably a good size (esp. since you can tile them). Any more interesting shading would take just as long.
@Wuerfel_21 said:
Back to the P2 and it's amazing "shaders", the texture lookup (given the already calculated UV) is fairly cheap on a per-pixel basis. Not sure how it'll work out when I add caching in the textures from PSRAM. Certainly will have trouble with these huge 256x256 ones, but 64x64 is probably a good size (esp. since you can tile them). Any more interesting shading would take just as long.
It'd be good if you could overlap the work (ie. work with one texture while requesting the next needed one from PSRAM). Then latency and copy time is hidden. A request list of multiple textures to read to HUB may be useful, and you can poll the current list position to see if the texture is ready. Caching will obviously help there too.
@rogloh said:
It'd be good if you could overlap the work (ie. work with one texture while requesting the next needed one from PSRAM). Then latency and copy time is hidden. A request list of multiple textures to read to HUB may be useful, and you can poll the current list position to see if the texture is ready. Caching will obviously help there too.
The idea is to build a custom RAM driver that can skim through the raster commands, load upcoming textures into the cache region and patch the cache pointer back into the raster commands.
One issue is that storing the raster commands in PSRAM could itself become a bottleneck on slower setups. One realized triangle command with UVLZ is 79 80 bytes, so on a slow board that does 1 byte / 3 cycles, that's over 480 cycles on the PSRAM bus for a round trip. So loading textures on top of that could lead to lots of stalling.
It has to do two at once because otherwise you'd waste a cycle due to MIXPIX being 7 cycles (odd number!). Also saves the dither toggling instruction.
Though now that I look at it again, I think the second rasL/rasZ update can move after the DJZ... Also need to move the second GETQX after MIXPIX. This really only saves a few cycles of overhead when span_length is odd...
If you mean the whole BSP/column/span thing, no, that's a whole different approach (that happens to be a lot simpler to compute but far more limited in capability)
If you mean rendering a room, some baddies and a gun from 1st person perspective, that'll work once I figure out clipping.
Interesting observation: When dithering, if the Red/Blue component of the dither matrix is offset such that the R/B maximum coincides with the G minimum, the "gritty" appearance is reduced as the noise is moved from luma to chroma. Wether that's desirable depends on application and taste.
As implemented in the teapot demo (view at 100% scale):
I discovered this while making a PC program for threshold dithering truecolor images to RGB565 with correct gamma etc. I think none of the usual suspects offer this sort of offset matrix dithering. They're also not gamma-corrected, either (you can notice this if you dither to just 2 levels (black/white or 8 color RGB) - ends up way to bright).
Is your monitor set to 16 bit mode :P ? Though this sort of thing really shows better with plain colors than textures.
Note how the dark bottom of the pot exhibits severe banding in the "No dither" version.
The three squares show a magnified section: the middle one is using the non-shifted dithering matrix and has a lot of luminance "grit". The bottom is using the offset dither matrix and the dither pattern instead exhibits an alternating red/green tint.


Comments
I tried the simple triangle drawing. The time depends on the size: the bigger the triangle, the better the time for one pixel - as expected. For a triangle 100 pixels high and 200 pixels wide at the bottom, I got 7 clocks per pixel for execList call (that I made PUB to call from the test program)
The biggest test triangle I tried was 512 px high, 1024 px wide and it took about 5 ms to draw, about 6 clocks per pixel.
Now I need a fast procedure to prepare the list for any given triangle and that procedurew should be as fast as possible (=asm)
The program on the attached video displays some test texts to check if the driver works OK, waits 5 seconds and then draws 256 triangles to test if drawing in a loop can corrupt the driver (that didn't happen yet)
sub testtriangle var pixels=0 for j=0 to 255 for i=0 to 511 list(4*i)=$C000_0000+v.buf_ptr+1024*i+(511-i) list(4*i+1)=j list(4*i+2)=2*(i+1) list(4*i+3)=varptr(list(4*i+4)) pixels+=2*(i+1) next i list(2399)=0 i=getct() psram.execlist(mbox,varptr(list),0) 'i=getct()-i: print i: print i/337 : print i/pixels next j end subYou could have it write the individual spans to the PSRAM, but that has big overhead and won't work with any sort of masking/transparency. Another option is to render 320x240 quarter screens and combine them into a final 640x480 frame. Will need additional bucket memory for that. Either way filling 4x the pixels + extra overhead -> very slow -> dubiously useful.
Doing this correctly (i.e. such that adjacent triangles meet their edges exactly, without gaps or overdrawn pixels) is actually not easy, especially when you add sub-pixel precision into the mix (which is needed to avoid jittery animation). For single triangles the correct rasterization tends to look weird.
Nugget of useful code: Triangle area calculation without rounding.
The canonical formula is
0.5 * abs( (x2 - x3) * (y1 - y3) - (x1 - x3) * (y2 - y3) ).We also want the sign before taking the absolute - this is the triangle winding (clockwise or counter-clockwise) which is needed for backface culling!
Latest version I posted has this straightforward code, with rounding of the product terms (bad):
abs tmp1,x23 wc ' X differences are 16 bit safe mul tmp1,y13 ' Y differences always positive due to sorting shr tmp1,#1 negc dxy,tmp1 abs tmp1,x13 wc mul tmp1,y23 shr tmp1,#1 sumnc dxy,tmp1 abs dxy wc ' This has the area bitc flags,#31 ' This has the sign(I've omitted the part that calculates the XY differences for brevity - as commented, this (currently) happens after vertex Y sorting (not really a good idea) so the Y differences are all positive)
My notes:
Cracked version without rounding:
abs tmp1,x23 wc mul tmp1,y13 bitc flags,#31 modz _c wz abs tmp2,x13 wc mul tmp2,y23 modcz _clr,_c_ne_z wcz ' do ADD if signs were different, SUB otherwise if_z add tmp1,tmp2 ' looks like it could overflow, but actually can't with correctly constrained differences if_nz sub tmp1,tmp2 wc ' C set if tmp2 was larger than tmp1 negc dxy,tmp1 ' (negate in that case) if_c bitnot flags,#31(sadly one additional instruction...)
Might look slightly different if it had to take sign of Y differences into account - in that case it'd be better to write some more bits of flags and use the parity flag from TEST to great effect.
Nice, Ada! Programming like this is fun for me, because it's all about how much functionality can be squeezed out of the smallest number of instructions.
Yes, I like that, too.
Unrelatedly, first results from implementing geometry in PASM:
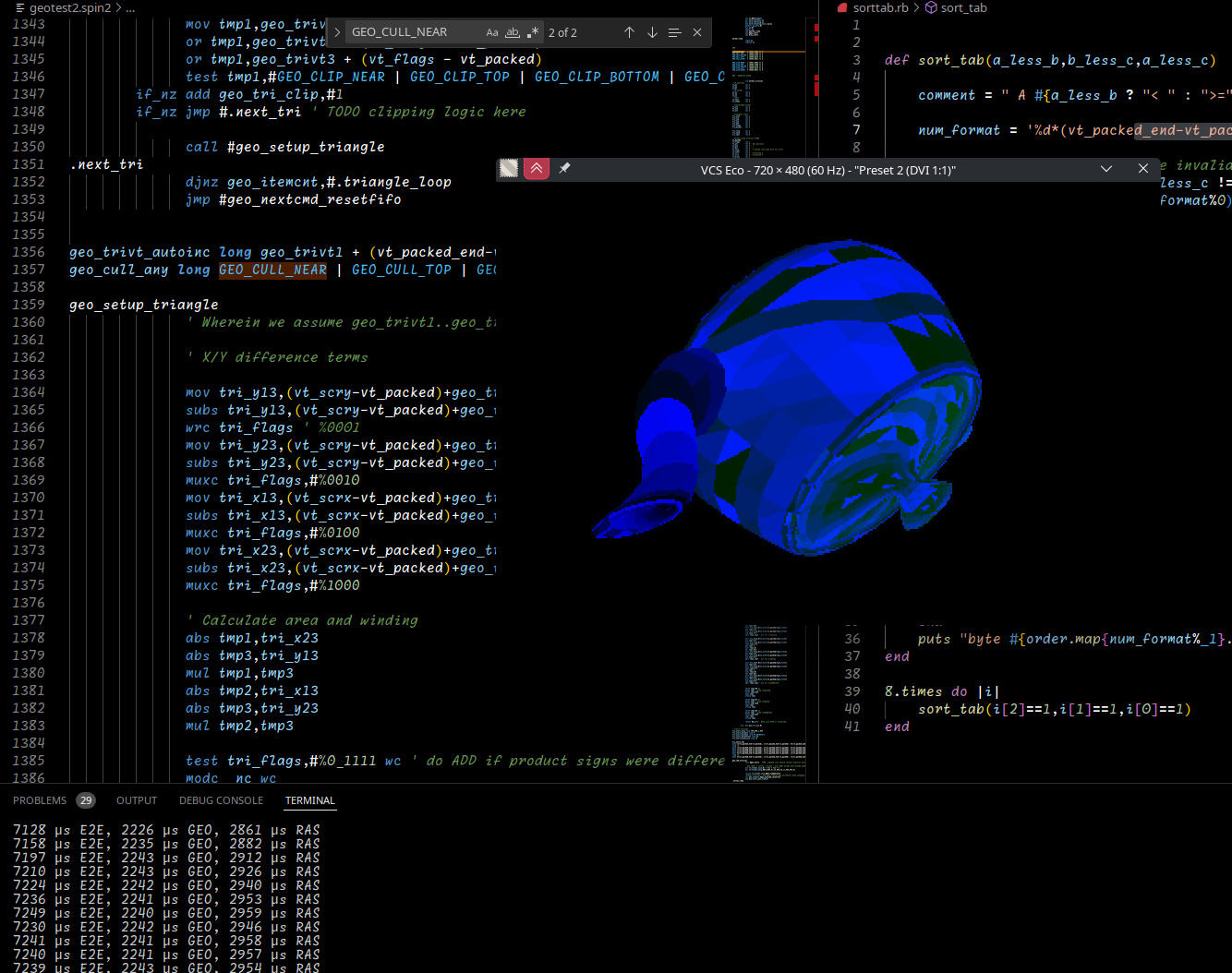
Geo time may increase to more like 3000µs when I add texturing back in. Gradient calculation is awful ;3 But vertex projection already deals with texture coordinates and also happens to not yet be optimized (unpipelined QDIVs). There's also optimization potential elsewhere. (OTOH a lot of things are just missing/hardcoded)
Raster should be 3000 to 4000 (same as current posted version). It's faster now because it's just solid filling (but backface culling is off, eating most of the benefit).
Also take note of the 2000 µs mystery time that's in E2E but doesn't come from actual GEO or RAS work time. I think that's mostly waiting on the PSRAM screen upload (slow-ish because this is @MXX board with 8 bit RAM bus, would be faster on P2EDGE). That's where audio processing could happen on the same 4 graphics worker cogs.
So the 60 FPS goal I set earlier is within reach now (that's at ~16600µs per frame for those playing along at home)
I also figured out a neat way to calculate the 1/Z-related values as "floating point" by normalizing Z before dividing. More on that when I get it working.
Can you save an additional instruction by combing the add/sub in this code:
abs tmp1,x23 wc mul tmp1,y13 bitc flags,#31 modz _c wz abs tmp2,x13 wc mul tmp2,y23 modcz _clr,_c_ne_z wcz ' do ADD if signs were different, SUB otherwise if_z add tmp1,tmp2 ' looks like it could overflow, but actually can't with correctly constrained differences if_nz sub tmp1,tmp2 wc ' C set if tmp2 was larger than tmp1 negc dxy,tmp1 ' (negate in that case) if_c bitnot flags,#31into sumnz in this:
abs tmp1,x23 wc mul tmp1,y13 bitc flags,#31 modz _c wz abs tmp2,x13 wc mul tmp2,y23 modcz _clr,_c_ne_z wcz ' do ADD if signs were different, SUB otherwise sumnz tmp1,tmp2 wc ' looks like it could overflow during add, but actually can't with correctly constrained differences, for subtract C=1 if tmp2 was larger than tmp1 negc dxy,tmp1 ' (negate in that case) if_c bitnot flags,#31The modcz seems to be clearing C previously anyway so the sumz operation in the add case writing C=0 won't change that, and as you mentioned that the C flag can only overflow in the subtract case with correctly constrained differences but maybe I am missing something important from your explanation.
@rogloh the carry out from SUMxx isn't correct for this (need unsigned carry)
Ok I see. Yeah that's a problem. A pity.
So for the earlier demo I always just set 1/Z to a constant (essentially doing affine shading / texture mapping). Now that I'm trying to do it properly the headaches are starting:
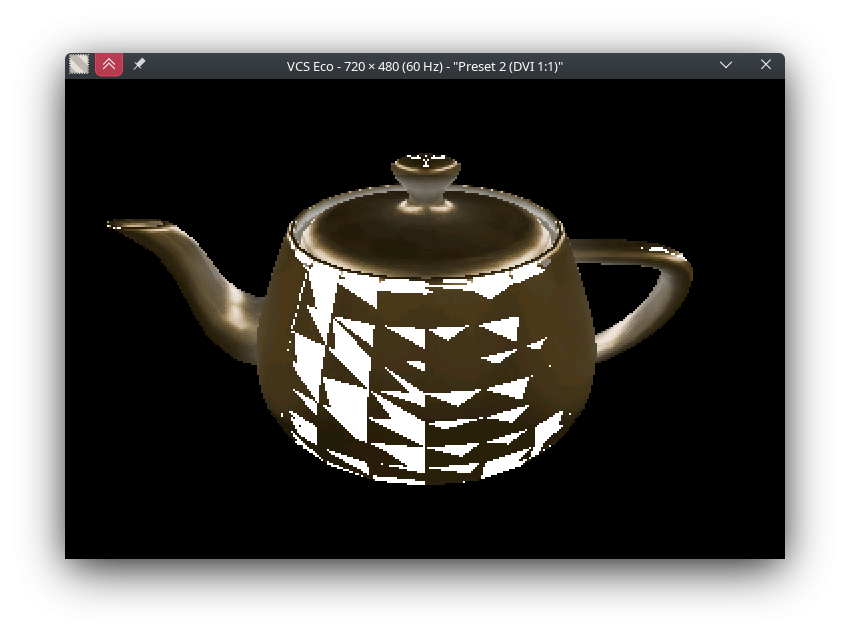
This is with "fog" shading towards white for clarity. Each vertex of these buggy triangles has L = $FF_FF (this is an 8.8 fixed point value). When L/Z and 1/Z are calculated for the vertex, they're scaled such that
(L/Z) / (1/Z) = $FF.The problem is that due to rounding error in the gradients,
(L/Z)' / (1/Z)' = $100for some pixels in the triangle (since the original fixed-point value was almost $1_00_00 to begin with) and this overflows the 8 bit PIV register.I could clamp L to $FF_7F or something to mostly ignore this problem, but I feel like there's a deeper insight wrt. rounding here that would fix it properly.
EDIT because forgor 💀 : There's another problem related to small triangles overflowing the gradients, which required me to chop 4 bits of precision off everything (I think in the screenshot I have it at 8 because that makes the PIV overflow problem more visible - it really only needs
SUB_PREC(which is sufficient at 4) bits of headroom). That might also be solvable.Though the hackneyed clamp solution does work for this particular demo, so I'm shipping it. Here you go, 60 FPS spinning teapot (full of unfinished code)
This consistently gets frametimes under 10000µs, so it's ~3 times faster overall than teapot_demo2. (This is with major pain sites in
vt_projectandtri_setup_texlit)As it were, slightly un-awful-ing
vt_project('slightly' in that it's still readable) saves ~300µsVery nice and seems silky smooth on my LCD monitor with VGA. 👏
Would love to see it in a higher resolution although the 320x240 res gives it that retro demo scene vibe. Just needs some crazy dynamic resizing and scrolling credits to go along with it plus some wicked music and you'll be there.
@rogloh 320x240 is the target because it fits in RAM and is viable for drawing actual scenes (i.e. not just one object floating on a solid fill background) at good speed. You can get some metrics printed by enabling -gbrk. (note that the 3 solid triangles in the background count towards this, comment them out for accuracy).
ras_pixelsis total pixels drawn by that cog. For texture+light+dither, this costs 56 cycles a pop (limited by CORDIC pipeline).ras_scanlinesis scanlines rasterized (some may not have actual pixels to draw), maybe 50 cycles for raster + another 80 for setup to actually draw (guesstimate)ras_primsis total triangles processed, I'd guess this is at ~250 (note that each cog has to load every primitive command...)If you were go to 640x480, you'd have twice the
ras_scanlinesand four times theras_pixels. You'd also run out of RAM for framebuffer.one object floating on background is perfect for 9DOF sensor visualization.
But, 320x240 3D scenes would be something.
In teapot-related news, here's a "3.1" version of the demo, collecting a few low-hanging improvement fruits:
So this is 521µs faster GEO (2750 -> 2229), ~100µs faster screen upload (really?). RAS currently unchanged.
(All measurements with teapot at zero angles, which is a quite quick to begin with)
Other fun fact: vertex processing is really cheap! Disabling calls to tran_nrm and do_envmap only shaves off 100µs, so there's some headroom for features like dynamic lighting.
Other interesting development: Despite failing at this earlier, I have devised a faster variant of the texture mapping routine. This one is 48 cycles instead of 56 (15% faster?), with the constraint that L (the PIV register value) is constant. However, that required rearranging the loop such that it's more pipelined, which increases startup overhead somewhat (single pixel may be slightly slower, need to measure).
This saves rather little time (~148µs) on the teapot demo (it's very overhead-heavy) and gets rid of the nice AO, so in that sense it doesn't look so hot. Where this would come in real useful is drawing something like a sky texture, which fills most of the screen and doesn't need shading to begin with. This could also be opportunistically selected instead of the 56 cycle routine when L just happens to be constant. Check for that would require some shuffling of the triangle setup code that'll likely make it slightly slower though, as that decision needs to be made before allocating memory (since the const-L command would be 11 bytes shorter).
'' inner loop only, preheat omitted for brevity '' notice how tmpU,tmpV need to already have valid texcoords rep @.pipetex,span_length zerox tmpV,tex_wrapv ' tiling mul tmpV,tex_stride zerox tmpU,tex_wrapu ' ^^ add tmpV,tmpU add tmpV,texturebase rdfast bit31,tmpV qdiv rasV,rasZ add rasV,slopeVX bitnot .ditherptch,#0 add ptrb,#2 qdiv rasU,rasZ getqx tmpV add rasZ,slopeZX add rasU,slopeUX rfbyte pixel wz getqx tmpU ' 16cy block rdlut pixel,pixel .ditherptch mixpix pixel,dither_even rgbsqz pixel wrfast bit31,ptrb {if_nz} wfword pixel ' <- conditional write for transparency .pipetexA 40 cycle routine wherein I'd get rid of the MIXPIX (and the BITNOT that modifies it - 9cy total) may be possible, too, but would cause problems for both of the aformentioned usecases because the colors are then no longer dithered.
Also, I used to (in earlier testing before I took a detour into investigating Quake-style subdivision that didn't turn out in the end) have a routine that did the opposite, in a sense (texture replaced with constant color, L gradient shading on top) that ran 24 cycles. If I added that one and changed the current solid routine to do dithering (instead of taking a literal 16bpp color), I think that'd be an orthogonal set, wouldn't it?
I've finally run the demo. Had to slow the default rotation rates to stop it making me dizzy. Smooth as.")
else yaw += 1<<22 roll += 1<<20Question: Does it actually need extra RAM? I note the default config is for Rayman's 96 MB memory expansion, but the binary isn't huge and it doesn't load anything extra. I'm guessing the demo is more an experiment at using external RAM for doing texturing.
On that note, I've always wondered what can be done, looks wise, with just fancy shading and no textures.
External RAM is only currently used to buffer the final frames. I want to eventually have pretty much everything going through the PSRAM, so you can have at least 256K of RAM for your actual application (should also figure out how to get flexspin to compile overlays to further improve hub RAM utilization)
In modernTM graphics, the textures are often just an exercise in pre-computation (it's a lot easier to generate matching high-res diffuse/normal/rough/metallic maps procedurally than attempting to create them from photos or drawing them by hand).
Textures also have free/automatic LOD and anti-aliasing that you don't get when creating details with actual geometry or shader math (you can see this in certain newer games - wherein someone gets the idea to e.g. fully model a grating, which then proceeds to horribly flicker, because antialiasing geometry is hard)
Back to the P2 and it's amazing "shaders", the texture lookup (given the already calculated UV) is fairly cheap on a per-pixel basis. Not sure how it'll work out when I add caching in the textures from PSRAM. Certainly will have trouble with these huge 256x256 ones, but 64x64 is probably a good size (esp. since you can tile them). Any more interesting shading would take just as long.
It'd be good if you could overlap the work (ie. work with one texture while requesting the next needed one from PSRAM). Then latency and copy time is hidden. A request list of multiple textures to read to HUB may be useful, and you can poll the current list position to see if the texture is ready. Caching will obviously help there too.
What I meant by fancy shaders is this sort of thing - https://en.wikipedia.org/wiki/Gouraud_shading

The idea is to build a custom RAM driver that can skim through the raster commands, load upcoming textures into the cache region and patch the cache pointer back into the raster commands.
One issue is that storing the raster commands in PSRAM could itself become a bottleneck on slower setups. One realized triangle command with UVLZ is 79 80 bytes, so on a slow board that does 1 byte / 3 cycles, that's over 480 cycles on the PSRAM bus for a round trip. So loading textures on top of that could lead to lots of stalling.
We have that at home
(with the aforementioned 24 cycle flat color shader patched in)
The inner loop for that looks like:
mov pa,span_length shr pa,#1 wc addx pa,#0 rep @.gouraud_done,pa qdiv rasL,rasZ mov pixel,basecolor add rasZ,slopeZX add rasL,slopeLX qdiv rasL,rasZ getqx tmpL add rasZ,slopeZX add rasL,slopeLX ' 15 cycles setpiv tmpL getqx tmpL .ditherptch1 mixpix pixel,dither_even rgbsqz pixel wfword pixel ' 2 if_c djz pa,#.gouraud_done ' 15 setpiv tmpL mov pixel,basecolor .ditherptch2 mixpix pixel,dither_even rgbsqz pixel wfword pixel .gouraud_doneIt has to do two at once because otherwise you'd waste a cycle due to MIXPIX being 7 cycles (odd number!). Also saves the dither toggling instruction.
Though now that I look at it again, I think the second rasL/rasZ update can move after the DJZ... Also need to move the second GETQX after MIXPIX. This really only saves a few cycles of overhead when span_length is odd...
Could this do doom type rendering?
If you mean the whole BSP/column/span thing, no, that's a whole different approach (that happens to be a lot simpler to compute but far more limited in capability)
If you mean rendering a room, some baddies and a gun from 1st person perspective, that'll work once I figure out clipping.
Nice work Ada!
Interesting observation: When dithering, if the Red/Blue component of the dither matrix is offset such that the R/B maximum coincides with the G minimum, the "gritty" appearance is reduced as the noise is moved from luma to chroma. Wether that's desirable depends on application and taste.
As implemented in the teapot demo (view at 100% scale):

I discovered this while making a PC program for threshold dithering truecolor images to RGB565 with correct gamma etc. I think none of the usual suspects offer this sort of offset matrix dithering. They're also not gamma-corrected, either (you can notice this if you dither to just 2 levels (black/white or 8 color RGB) - ends up way to bright).
I can't see a difference")
Is your monitor set to 16 bit mode :P ? Though this sort of thing really shows better with plain colors than textures.
Note how the dark bottom of the pot exhibits severe banding in the "No dither" version.
The three squares show a magnified section: the middle one is using the non-shifted dithering matrix and has a lot of luminance "grit". The bottom is using the offset dither matrix and the dither pattern instead exhibits an alternating red/green tint.