

Efficiently processing continuous signals
 bob_g4bby
Posts: 591
bob_g4bby
Posts: 591
Applications involving continuous signals such as music or software radios generally operate on buffers of data. All calculations must complete on average faster than the sample rate, else signal dropouts occur. Also it is desirable to minimise the delay between signal in and signal out.
To make an application as powerful as possible in a P2, maybe all 8 cogs need to be kept as near 100% loaded with tasks consistent with the above. Desirable 'features' are legion.
What algorithm for cog management have folks found works for them to achieve the above?
I'm familiar with Labview which operates on a dataflow principle, but wonder if that is o.t.t. for P2?
I guess this has been discussed long ago with P1? I've searched but not found it?
Cheers, Bob
Comments
I would like to use the HD audio add-on at maybe 48 ksample/s to give the user a decent chunk of radio spectrum on the display.
Processing would seem to split into two categories - signal path (fast) and user control (much less fast)
Hi @bob_g4bby ,
there is a a conflict of goals here, with audio processing no overrun is allowed. On the other hand you want the cogs to be loaded 100%. As far as I can see, you need something which is adjustable, for example if the quality of a result could be lowered. Or you could put cogs in a low power mode, if there is excess of work force. So you can adapt power consumption. Edit: You have 2 categories of tasks. You could do the user control in a variable pace to fill up to 100%.
I did some experiments which might be interesting here. Idea was that you have lots of small jobs to do. Put them onto a list, as soon as they are doable. There are "worker cogs" which grab the jobs from the list and mark them done. So there is no fixed mapping of tasks to cores.
https://forums.parallax.com/discussion/175422/p2-taqoz-v2-8-simple-automatic-multiprocessing#latest
I think the main advantage of the dataflow principle is, that it allows a meaningful graphical way of programming which allows scaling of the "map". Puredata / Plugdata https://plugdata.org/ use this principle too. (They are great!)
Daisy Seed and their library uses small buffers or single samples, Teensy Audio Library uses small buffers. The longer the buffer the better computer efficiency, because of the overhead of calling subroutines. They both use timer interrupts to pace audio tasks.
I have been thinking, that a compiler of Puredata patches to/in Forth must be possible as they use text files. :-)
I must say, that if you want to process one stream of data, than one single very powerful core like ARM M7 will be more suitable than to have 8 Cogs with limited Hub access. (Sorry)
Christof
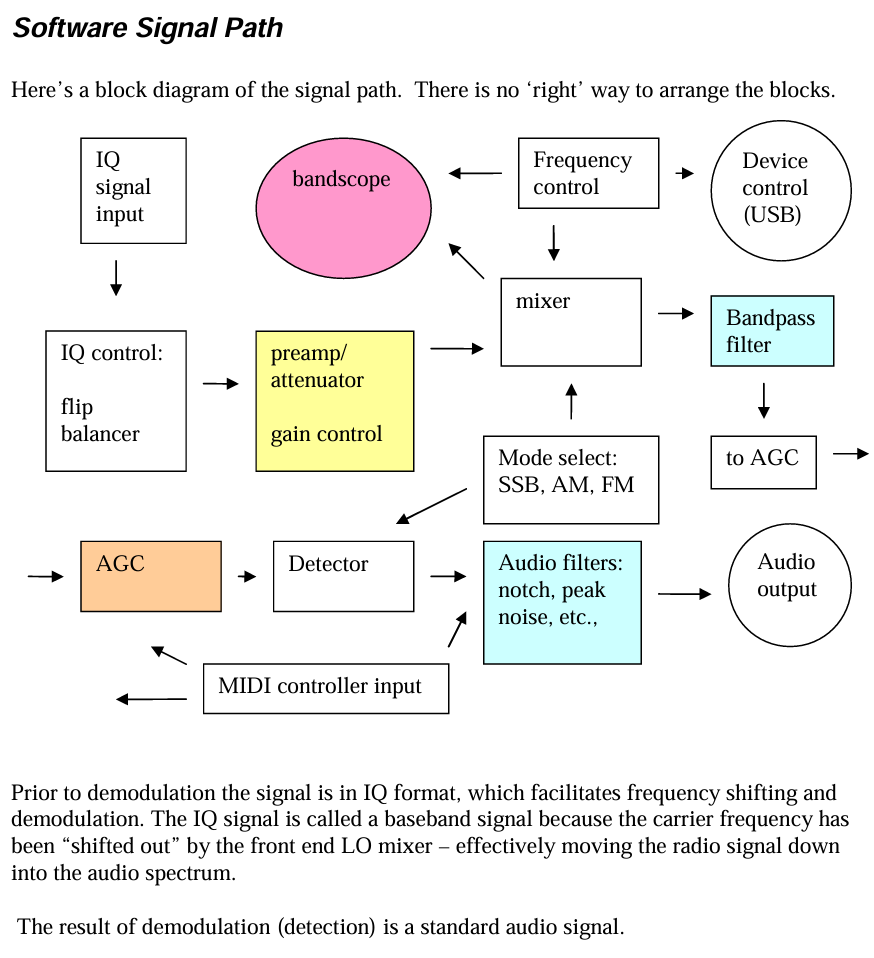
Thanks for the comments, @""Christof Eb." I'm thinking about software radio again as my application:-
The signal path needs to guarantee completion before the end of every timeframe. The time, in clock ticks, for each stage of the signal processing can be measured. Each stage is packed into a specific cog in a set (say cog 0-N). It's a bit like packing your suitcase - it's an art to get everything in + have the required signals ready for each stage. If the application uses a vga, hdmi or similar display, then that is controlled here too. Probably all code here is PASM2.
The rest of the application, such as the UI, makes use of cog N+1 to 8. Cog hierarchy to achieve that might be "Conductor and orchestra", "Dedicated cog per hardware peripheral" etc. Many different hierarchies to be considered. In the main, if no cogs are currently available, that part of the program can stall until a cog comes free. This is not noticed by the user. Code here could be SPIN2 or PASM 2 or a mixture of both.
The above is new ground for me - the software radios I've tinkered with up to now have been Windows based. Here, the programmer relies on the scheduler built into the operating system to manage the various parallel processes going on. Such software radios load the processors very lightly, so that when Windows takes a large chunk of processor for a while, no loss of signal occurs.
I've been doing a bit of research and notice a number of papers relating to realtime multiprocessor scheduling. They are heavy reading!
For now, I'm going to proceed in a bottom-up fashion - writing the dsp objects required to do a basic radio, grounded on Gerald Youngblood's Powersdr application, which I still have VB6 source code for. I successfully converted that to Labview code many years ago.
Cheers, Bob
I'm a bit surprised this topic didn't receive much comment. I guess it's early days for P2 still - there aren't that many dsp applications written for it yet that would need fancy cog management.
All existing solutions tend to be focused on one cog for one job. And since there is no pre-emptive OS or kernel involved there is limited task management tools available.
Maybe Catalina has something, I've not delved enough into Ross's packages to know what's what there.
If your system has two lists for small jobs. One high priority dsp a list and one low priority ui b - list, then each worker cog can after competion of a job first look, if there is a a-job to do and then look for a b-job. Near the input and the output you will need a ring buffer to handle varying delays.
That sounds like a more simple idea worth experimenting with, @"Christof Eb." and, for sure, buffers play a big part in all of this.
You've got to ask yourself - why use a P2 in my design? 8 processors in one chip sounds a very good idea, but how to use them all effectively to justify choosing this chip, where (say) a software defined radio might be pushing it's capabilities?
Anyway - having lot's of spare time as a retiree I scribbled this out:-
(a) Realtime schedule - all rt tasks in this schedule will complete within the specified rt period
(b) Non-realtime schedule - all non-rt tasks will complete as soon as possible
(a) 1 - 7 rt tasks can be launched immediately, one task per cog. No further rt tasks are launched until all current rt tasks complete. This is to ensure any results calculated are complete before later rt tasks which
need these as inputs are started. It's a crude dataflow implementation
(b) A number of non-rt tasks may be launched as soon as free cogs are available. No further non-rt tasks will be launched until the current ones complete, again for dataflow reasons. The number of non-rt tasks
takes account of the number of rt-tasks currently running and the number of rt-tasks about to run next, so as not to leave rt tasks short of cogs - ever.
(a) The rt period is drawn as a tall rectangle - it's width is set to represent the rt period
(b) Each rt task is a short rectangle whose width is set to represent the rt task worst case duration
(c) The rt tasks are fitted inside the rt period rectangle
(d) The rt tasks are arranged horizontally in the order they need to be processed in. Where rt tasks are not dependent on each other for data, then these can be arranged vertically to run simultaneously in several cogs
(e) Labelled lines can be fitted to show dataflow dependencies to check all data is calculated before it is needed as an input later
Waddayathink?
Hi Bob,
some thoughts here:
With P2 there is the special case that it has very limited fast cog and lut rams and access to hub is hampered by the other cogs. Execution of code from LUT or COG is at least twice as fast as execution from hub ram. Access to data is fastest from cog ram, followed by lut and then by hub access. RDLONG needs 9...27 cycles, while RDLUT needs 3 cycles.
So if you have to go to the limits of P2, you will probable have to dedicate tasks to cogs to avoid loading cogs with code before execution. And even more critical is the question what data must be held in LUT or even COG.
When I wrote my editor for Taqoz I tried to split up the work for several cogs. - I did not succeed. Instead I found other ways to have sufficient speed. Problem was, that nearly everything has fast effect to the screen. You would need a lot of synchronising of activities. So sometimes it makes sense to split tasks depending of their need to handle periphericals. A block diagram would be helpful. My impression is, that splitting of tasks is only good, if a big chunk of work can really be done independently from the others. In my projects the number of such tasks has been smaller than 8, so it was possible to dedicate cogs to tasks. For slow things I have additionally used POLLS.
I would probably try to reuse code of others with the FLEX compiler and I would start with a simple radio setup or part of it and try to learn. So you can test the dual priority setup. Code in assembler only if necessary.
....and you don't want to do it with Taqoz?....
Good points, @"Christof Eb." , so especialliy with fft and ifft, you want that code to run from the fastest location - it might make sense to turn a cog permanently into an fft / ifft coprocessor and maybe other big functions too - e.g. the main filter is based on frequency domain convolution and is the most compute intensive part of the radio. As more coprocessors are added, you get to the point where one cog can cope with the rest of the main signal path in the time required.
"I would probably try to reuse code of others with the FLEX compiler and I would start with a simple radio setup or part of it and try to learn." - Agreed there, up to now all I've done is program in Taqoz and a little ASM2 as forth words. I'd like to encourage other radio ham constructors to adopt and expand the project. There are many who would write stuff in C, some might use Basic and a quite a few that would be bothered to learn Spin2 (me included), but very few that would adopt forth.
I thought about doing this project in Taqoz, but don't favour it for the following reasons:-
1. Taqoz does take up quite a bit of hubram permanently - would that be more than the Spin2 interpreter? The radio needs every kilobyte that can be saved for buffers - a 1024 sample I-Q buffer takes up 1024 samples x 4 bytes each x 2 in phase / quadr phase channels = 8192 bytes. In many ways, forth is a good basis for tying PASM2 forth words together. From the point of view of encouraging others - sadly, forget it. I also wouldn't be able to adopt others work already done on audio i/o.
2. The debug feature in P/NUT is now really useful, especially where graphing of buffers is concerned, so writing some of the non-realtime stuff in SPIN2 ( smallest footprint) and all of the DSP in ASM2 (fastest) seems the best way to go.
3. If interpreted SPIN2 is too slow, then there's the user provided compilers to try as a speed up. I bet the footprint goes quite a bit up though.
Please, forgive my intentionally provocative questions but since you do not intend to use TAQOZ, at least at this particular moment, why bother with the P2 in the first place ? What's specially so advantageous that a P2 has and that could be superior to the other architectures ? Or is it intended purely as a feasibility study at this stage (that one reason I understand perfectly) ?
Edit:
I'm after the ultimate and affordable CW only (or CW centric), multiband transceiver myself so it is easy to understand my motivation for these questions.
Well, while I am fascinated by Forth, I do understand, that there are reasons not to use it...
( I think, that Taqoz is very storage efficient using 16 bit wordcodes though! And I doubt, that there are so many people who want to learn that special language SPIN2.
Perhaps you have seen my post how to call Forth words from assembler. I have not done it, but a main application for this could be debugging. )
=============
Do you really want to use 32 bit data? P2 has fast 16x16 multiply and my experience with ADC is, that 16bit S/N is rather difficult to achieve.
=============
Did you have a look into Puredata?
Modules receive data streams and send data streams.
They use blocks of data in the data streams, for example 64 samples of audio. This data is accompanied by a BANG, which signalles, that fresh data is available. A scheduler can then evoke all modules, which are defined as receivers of that data stream. You can also send a BANG to a module, which will activate it with the last data.
So in this case the scheduler works with BANGS.
Edit: Read a little bit about it, it is more complicated, scheduler has two parts. One works with audio streams and the other with messages like bangs.
It would be very cool to use the Puredata graphical editor (or Plugdata) and then have Forth compile the "patch" into "something" for Forth. Something like the HEAVY compiler from Puredata to C for DaisySeed. The patch language seems to be very limited and simple, so writing a compiler for a subset must be doable. Of course we would use integers (scaled?) instead of floats with P2.
I think, that the graphical way of programming can be good to communicate in a forum too. Puredata allows submodules, which make zooming possible to switch between overview and detail.
You can also use Puredata on the PC as a realtime graphical interface to external hardware.
@Maciek, good questions - it is a feasability study at the moment.
I have a soft spot for Parallax.
A friend runs an hf transceiver on a dual core 70MHz DSPIC, so some kind of SDR should be doable on the more powerful P2. I think it deserves one, don't you? ;-)
That cordic engine is begging to be used
Good to hear from you
@""Christof Eb."
I agree, SPIN2 will be unfamiliar to newcomers, just like Taqoz. The friend mentioned above only became slightly more interested when I said C was supported by 3rd party compilers
The first Windows based PowerSDR used 16 bit soundcards at the time and sounded pretty well, so no, 32 bit samples aren't a must have. 32 bit intermediate results might be useful to handle overflows? 512kbyte is a small place when it comes to the signal buffers needed, so 16 bit samples might be crucial to making the project possible. (Let's not mention external RAM?)
I did have a look over Puredata, but didn't spot the BANG feature - so dataflow is timed by the programmer rather than being fully automatic - interesting
I do very much like the graphical language LabView (I wrote a software defined receiver in it which performed) Have a look - the community edition is completely free - an amazing gift to amateurs of all kinds.
"I would probably try to reuse code of others with the FLEX compiler and I would start with a simple radio setup or part of it" - that's good advice, I will be doing that. Each dsp object needs debugging with it's own test harness to check it's really (not nearly) doing what it should. From experience with Labview, these bugs otherwise remain hidden until you hear the glitches in the audio output! Even if the project never completes, some useful dsp objects can go in the OBEX.
A static deployment of code to individual cogs would be more straightforward to debug than the "scheduler" idea, where an arbitrary cog number is selected on each cycle of the program - ouch!
I hope that this is not annoying, I have searched for a SDR in Puredata and voila: https://lists.iem.at/hyperkitty/list/pd-list@lists.iem.at/message/65NAS23QZZCIVX2EUOHN24QTFPGRGUE3/
And a description in MSP: http://www.zerokidz.com/radio/docs/maxsdr5.pdf
From this:
I do not understand, why you would need so many large buffers?
What kind of hardware do you plan to use for the IQ source?
@"Christof Eb."
An SDR written in Puredata was unexpected - well done finding that. This software is designed to work with a PC soundcard as the I/O port to the radio hardware. This four part series of articles explains a lot about the hardware and software involved Part 1 Part2 Part3 Part4
I'm proposing to use a low noise stereo codec either from ebay or this one from Parallax, feeding the P2 as the radio backend instead of the PC.
"I do not understand, why you would need so many large buffers?" Well, let's count a few buffers up:-
1. Codec input - 2 buffers INP1 and INP2. Whilst INP1 is being filled from the codec, we can read INP2 as the input to the DSP. When INP1 is full, INP2 is filled from the codec and INP1 is read by the DSP
2. Audio output - 2 buffers OUT1 and OUT2. Whilst OUT1 is being filled from the DSP, OUT2 is being played by the D/A to the loudspeaker and vice versa
3. The DSP can be thought of as a series of 1 input - 1 output and 2 input - 1 output functions. If we define BUFFA, BUFFB and BUFFC, we can reuse these repeatedly to store the required inputs and the output as we execute each stage of DSP in turn
OK - 2 + 2 +3 = 7 buffers if all is handled by a single cog. If we need to employ more cogs in the signal path, then probably that number needs to go up a bit. Let's not consider that here for now.
If we use 1024 sample buffers with 32 bit samples, each I-Q buffer is 1024 samples, 2 channels = 8182 bytes. Thus 7 buffers would take up 57,344 bytes
If we use 1024 sample buffers with 16 bit samples, each I-Q buffer is 1024 samples, 2 channels = 4096 bytes. Thus 7 buffers would occupy 28,672 bytes
If we used 4096 sample buffers like in the SDR papers above our figures would go up by x4 e.g.
7 off 32 bit sample buffers would take up 229,376 bytes
7 off 16 bit sample buffers would occupy 114,688 bytes
So you're right - it's maybe not such a big deal as I had made out. Even worst case, just over half the hub ram is available for the program, not forgetting 8 LUT memories that would be very useful to hold many of the DSP functions.
"What kind of hardware do you plan to use for the IQ source?"

The receiver hardware (for example) is quite simple. In order from antenna to Propeller P2:-
1. Bandswitched bandpass filters to cover the range 1-30MHz
2. An SI5351 local oscillator tuning 4-120MHz feeding a divide by 4 counter to provide I-Q local oscillator signal 1-30MHz
3. The above two signals are mixed in a Tayloe detector which outputs the difference signal. Typically a 50kHz portion of 1-30MHz gets converted down to 0-50kHz baseband
4. This I-Q baseband signal is amplified by two low noise opamps
5. The I-Q baseband signal is converted to a 48 ksample/s I-Q digital stream in a low noise stereo codec and this is read into the P2
The Multus Proficio I included as a picture is designed to connect to a PC via USB. The USB link handles both control and signals. I include it just to get some idea of the hardware needed. You can see the 5W power amplifier transistor on it's heatsink that is part of the transmitter
What's attractive about large buffers? (if you'll excuse the expression!)
1. Less computation per sample as we perform the glue elements of the program between dsp functions less frequently. Gives the P2 an easier time if you can afford the memory.
2. Larger buffer sizes in the receiver main filter (using frequency domain convolution) means sharper filter walls. Adjacent interference is cut off more effectively. This makes the sdr a very good performer, up there with the best.
I see someone has produced the receiver hardware needed between the antenna and the stereo codec as a small kit
@bob_g4bby
Thank you for the informations! Very inspiring and interesting!
I think, that you can use small buffers, if you preserve states of filters between them.
Thinking about usage of cordic: Actually this is rather slow, if you have to wait for the result. So with that, you cannot efficiently work through a buffer in one. But there are lots of cordics, which have to be loaded and unloaded with time between it. So perhaps with them it is better to have one big loop doing very different things, probably with circular buffers?
Side story: your thread inspired me to try a DCF77 receiver with the smart pin "Goertzel mode" directly coupled to the RF input. So far it does not work. I will try to build a selective antenna amplifier, 77,5kHz is nearly low frequency, so my knowledge might suffice. :-)
Bob,
In your write-ups, please use ADC in place of codec. The term "codec" means a device containing both an ADC and a DAC with either or both being used at any one time, so it takes some reading to work out you are meaning ADC when you say codec.
@evanh, ADC it is from now on!
@"Christof Eb."
"Thinking about usage of cordic: Actually this is rather slow, if you have to wait for the result. So with that, you cannot efficiently work through a buffer in one. But there are lots of cordics, which have to be loaded and unloaded with time between it."
It is slower, but we can do a couple of things to make the best of it:-
1. Preload a number of inputs before waiting for outputs to start appearing
2. If the dsp processing is identical on each sample, set four cogs to process 1/4 of the buffer each
The really useful cordic functions, Rotation, Cartesian to Polar and Polar to Cartesian would (I'm guessing) take longer if calculated in PASM2 without the cordic engine. Rotation in the FFT was a big speeder upper, I believe Chip found.
So I finally got round to writing some code. I've chosen to make 'inline pasm' for SPIN2, because it neatly supports calling the dsp functions with parameter and local variables. Whether a practical dsp application could be written with Spin gluing everything together like that remains to be seen. Whether compiling the SPIN to machine code would be useful is something else to try.
It's certainly a very pleasant test bed for debugging dsp functions - the 'scope' displays are invaluable. Pnut is slow to display, Spin Tools is a lot faster. Both are quite usable.
Directions:
1. Unzip the code to it's own directory
2. Load mix and modulate.spin2 into your ide of choice (tested on Pnut and Spin Tools)
3. Run with ctrl- F10
Scope 1 is a 100 Hz iq sinewave generator
Scope2 is a 150 Hz iq sinewave generator
Scope3 is the result of modulating these two signals
Scope4 is the result of mixing the two signals
Whilst coding, I display two pdfs I made of 'Propeller 2 Assembly Language' and 'Spin 2 Language Documentation' which adds a clickable contents strip on the left hand side. I also open @Wuerfel_21 's 'Propeller 2 Docs' with it's 'hyperjump'. You can usually find what you're after pretty quickly, with those.
So - it's the beginning of an array based dsp library, which I'm hoping will be useful for software radio. I think next is to adapt the HDaudio driver to input and output to my signal buffers so I can feed in real signals and hear the results. I bought the HDaudio add-on set before Chistmas. I'll also make some measurements on the time spent in SPIN versus the time spent in PASM code, to see if that ratio is at all tolerable. With the PASM functions working on 1024 samples at a time (rather than a single sample at a time) I'm hopeful.
Cheers, Bob
Here are the two pdfs I made from the google docs current versions for SPIN and PASM. I used Libreoffice Write to convert
Interesting! With the oscilloscope, I measured the time taken to do this SPIN loop:-
repeat dsp.sine(@BUFFA, frequency, 0)With the processor clocked at 320MHz, I toggled pin 56 as output to go low during the PASM inline code and high during SPIN code. Running without debug (of course), writing the 1024 samples of sinewave took about 58uS. The SPIN 'code' only took 2.2uS! When compiled with Flexprop, that came down to 703nS - excellent! So it looks like an array based dsp application could be written with strings of 'inline code' methods glued together with SPIN.
The two other methods 'Modulate' took about 212uS and 'Mix' took about 160uS.
Multiple cogs will eventually be employed, each running these 'inline code' dsp methods in minimalist 'repeat' loops to keep the total signal processing time under 21.33mS mandated by 48k sample rate and 1024 sample buffers. DSP sections could have SpIn compiled to machine code, whereas controls and GUI would be fast enough in interpreted SPIN to save space.
Here is an updated demo of my buffer based AK5704 driver (aka the HDaudio add-on set). It is a straight-through test from "mic in" to "line-out". The sample rate is 48ks/s and the buffer size is 1024 iq samples.
A helper cog runs method "signalpump" which manages the double buffered input from the mic input and the same for output on line out. It also sends an ATN to the calling cog to signal that fresh buffers are ready.
In the top level code, method "main" waits for the ATN and then transfers the full mic buffer to the empty lineout buffer. In a real application, it would also perform all the intermediate dsp needed in between. This has to take place in 21.333mS - the time taken to fill one buffer from the mic in.
To run the demo, unzip the four files to an empty directory. Using the "Spin Tools" ide, run "test 1 for ak5704 buffer based driver.spin2" in debug mode, having plugged an electret mic into the mic in socket and headphones or a pair of PC speakers into line out. The program displays a single SCOPE window with the mic input signal displayed in real time. Pnut runs too slowly to display properly. You should also hear the signal on your headphones or speaker.
Why go to all this trouble of using buffers? DSP code runs faster when handling buffers of samples than when handling single samples at a time. e.g. The cordic engine requires a 54 cycle delay when running sample by sample. This can be reduced to around a 9 cycle delay when processing a complete buffer of samples. The FFT code that @SaucySoliton is producing for the Obex works on buffers of iq samples too.
Cheers, Bob
I haven't really come to terms with all the subtleties of p2 addressing yet. From within an inline assembly method, I'm setting up to use the FIFO to read an array of words in a DAT block. Here's the code:-
' Apply a window array of words to cartesian buffin, result is cartesian buffout. Buffout may be the same as buffin pub window(buffin, buffout) | counter, outbuff, winsample org ' debug window1 push ptra rdfast #0, #BHwindow mov ptra, buffin mov outbuff, buffout mov counter, #(sigbuffsize/16) window2 setq #31 rdlong array, ptra++ rfword winsample qmul winsample, array qmul winsample, array+1 rfword winsample qmul winsample, array+2 qmul winsample, array+3 rfword winsample qmul winsample, array+4 qmul winsample, array+5 rfword winsample qmul winsample, array+6 qmul winsample, array+7 getqx array getqx array+1 rfword winsample qmul winsample, array+9 qmul winsample, array+9 getqx array+2 getqx array+3 rfword winsample qmul winsample, array+10 qmul winsample, array+11 getqx array+4 getqx array+5 rfword winsample qmul winsample, array+12 qmul winsample, array+13 getqx array+6 getqx array+7 rfword winsample qmul winsample, array+14 qmul winsample, array+15 getqx array+8 getqx array+9 rfword winsample qmul winsample, array+16 qmul winsample, array+17 getqx array+10 getqx array+11 rfword winsample qmul winsample, array+18 qmul winsample, array+19 getqx array+12 getqx array+13 rfword winsample qmul winsample, array+20 qmul winsample, array+21 getqx array+14 getqx array+15 rfword winsample qmul winsample, array+22 qmul winsample, array+23 getqx array+16 getqx array+17 rfword winsample qmul winsample, array+24 qmul winsample, array+25 getqx array+18 getqx array+19 rfword winsample qmul winsample, array+26 qmul winsample, array+27 getqx array+20 getqx array+21 rfword winsample qmul winsample, array+28 qmul winsample, array+29 getqx array+22 getqx array+23 rfword winsample qmul winsample, array+30 qmul winsample, array+31 getqx array+24 getqx array+25 getqx array+26 getqx array+27 getqx array+28 getqx array+29 getqx array+30 getqx array+31 setq #31 wrlong array, outbuff add outbuff, #(32*4) djnz counter, #window2 pop ptra ret array res 32 fit end DAT {Symbols and Data} BHwindow word 0 word 0 word 1 word 1 word 1 word 1 word 1 word 1 word 1 word 1 word 1 word 2 word 2 word 2 word 2 word 2 word 3 word 3 word 3 word 4 word 4 word 4 word 5 word 5 word 6 word 6 word 7 word 7 word 8 word 8 word 9 word 10 word 10 word 11 word 12 word 12 word 13 word 14 etc. (1024 words in total)rdfast #0, #BHwindow isn't right. What does it need to be, please?
Hi,
perhaps this is again my not-knowing...
As far as I know, you can only use the streamer for data movement, if your code is executing from cog or lut memory. I don't think, that inline asm is loaded into cog memory?
Christof
In pure Pasm2
rdfast #0, ##BHwindow(with double #) would work. Spin2 DAT sections may be just as simple. If not then just do:pub window(buffin, buffout) | counter, outbuff, winsample counter = @BHwindow org ' debug window1 push ptra rdfast #0, counter ...EDIT: Corrected")
&syntax to@. I'm more of a C coder.