

SUMCX challange
 ManAtWork
Posts: 2,369
ManAtWork
Posts: 2,369
in Propeller 2
I have a signed 64 bit value A and have to add or subtract a signed 32 bit value B to/from it depending on the state of the carry flag. SUMC works very elegant for 32 bit values but my solution for a 64 bit version looks somewhat clumsy.
negc B wc
mov Bhi,#0
if_c neg Bhi,#1 ' negx substitute
add Alo,B wc
addsx Ahi,Bhi
Not that it's absolutely necessary to optimize it further... But there is no single instruction to fill Bhi with all 1s or all 0s depending on C, is it. There is WRC but it sets only bit0. Or could the first ADD be replaced by a SUMC? I guess it doesn't set the C bit correctly as needed in all cases.
Comments
subx Bhi, BhiYou could use MUXC if you had a register with $FFFFFFFF in it:
EDIT: Wait, never mind. Wuerfel has a better solution.
so now that we got a 4 op solution
negc B wc subx Bhi,Bhi add Alo,B wc addsx Ahi,Bhi... is there a 3 op one?
If you can start with the condition in Z you can
if_z sub Alo,B wc if_nz add Alo,B wc if_c sumz Ahi,#1but that's not really a solution to the stated problem")
deleted
Deleted
Except that doesn't work and also isn't fast. You never use ADDS with ADDSX, that results in nonsense. In case of C=1, the program will take 8 cycles, but in case of C=0 it will take 10 cycles due to SKIPF pipeline delay (avoid skipping over the first instr after SKIPF)
Deleted
Stealing time from 4 people just to save one instruction is overkill, I know, but it's fun to program assembler not in the way a compiler does but really elegantly and efficiently.")
Learned something, again. Unfortunatelly, I can't use Z because C is the result of another signed operation.
Thanks Wuerfel, Chip and Tony for the solutions.
BTW, I'm still looking forward to a full featured P2 assembler instruction and hardware manual. I had to look up the ADDX/ADDSX things in the P1 manual. That manual is really exceptionally valuable. It not only provides a short description of what an instruction does but also gives examples and explains the purpose.
deleted
Who said "premature optimization is the root of all evil", recently? The above code doesn't work when B is negative and Z=1 meaning "subtract it". The sub instruction correctly adds the negated negative (= positive) value but the carry is not handled in the correct way for signed arithmetic. C is set and the sumz subtracts #1 from Ahi even though Alo got greater.
negc Blo wc subx Bhi,Bhi add Alo,Blo wc addsx Ahi,Bhiseems to work, so far.")
Oh yes I noticed that too (a while after posting it), but I didn't think you'd have a negative B. I usually don't use SUMxx like that, so maybe bias. Though I guess that means the other method doesn't work if B is meant to be a large unsigned value.
Though I think "premature optimization is the root of all evil" is a badly formulated idiom that is part of why computers now are getting slower over time rather than faster. It of course holds true in terms of "don't do all the tricky instruction-level micro-optimizations right away if you're not entirely sure they're really needed" kind of way, but the mentality grows and oops now your shitty javascript/python/etc minimum viable product has morphed into something too big to refactor into not wasting 90% of the resources it consumes. Or rather too expensive, given that the waste is externalized onto your users for client applications. Or maybe you did it on your server program and now have to hire crack developers to write new JIT interpreters to make your slow-script-language web server software run 20% faster. This sort of thing was okay when computers were getting better quickly, but now they're basically stagnant. A mid-range computer in 2013 would have had 8GB of RAM. A low-end computer today still has 8GB of RAM. Infact, the current gen of macbooks, overpriced shitboxes they are, still ship with 8GB of RAM for all but the large-sized Pro models (so actually less total RAM than my 2012 mid-range laptop, which had 1GB of dedicated video RAM....).
Okay, rant over.
I totally agree. This is one of the reasons I use the propeller instead of doing "lego brick programming" on other platforms which means you don't really know what you are doing but just call functions of extremely bloated libraries. I really enjoy having control of every single cycle of execution timing.
But as with everything you can overdo it. Except for the special case when it's the innermost loop and you have to squeeze every nanosecond out of it we shouldn't waste too much time just to save one instruction.
Good example: Raspberry Pi. Raspberry Pi 1 , with its ARM6 architecture, but also VC4 graphics with H264 decoder onboard can display perfectly fluent fullHD movie with also perfectly synchronized sound. RPi4, having 20x faster CPU and 50% faster GPU with H265 decoder onboard, theoretically capable of decoding 4k at the real time, struggles with displaying anything over 720p.
That's because of using general purpose linux written for much bigger machines instead of a proper dedicated OS and tools for a smaller machine. The Linux libraries introduce a lot of memory copy operation between a decoder and a frame buffer, and then it struggles, as the memory bus is 32-bit only.
There are several advanced hardware mechanisms in RPi that are now totally wasted. The GPU address space, at least in RPis up to #3, was shared with CPU. When using OpenGLES, you need to send textures to GPU. That can be done simply: got a pointer, fast blit the data. But no, who needs that pointer? It was available in the earlier versions, but then they removed it from the report field where it was, and marked it as "not used". (and yes, no valid pointer there... ) Use a library instead... that introduces 2 or 3 more memory copy operations, and the memory subsystem is the weakest point of the RPi.
That was several years ago and I solved or rather worked around the problem by using the function once, to push the texture with known "hand made signature", then search the GPU RAM and find it. That of course worked.
The ultimate solution is go, use a Propeller instead.")
It's not like it doesn't matter on the bigger machines, it's just that the threshold for "good enough" is lower. If the Pi struggles at 720p the PC struggles at 8K. VAAPI in general is so broken... Had to futz a significant amount to get Vivaldi to play youtube videos on the hardware decoder in my Thinkpad. And now it sometimes hangs the X Server when I close Vivaldi Though GLES copying the texture once in the driver seems like a reasonable-ish thing. Normally the GPU texture is not a normal bitmap (shuffled around to optimize cache lines), so the driver shuffling it during the copy probably makes sense. Well, except if you already have a texture in the right format... Fun fact: Nintendo 3DS handheld has worse specs than the original Pi model A (GPU may have higher fillrate? idk, but VC4 has pixel shaders and PICA200 doesn't) But the software is optimized and thus it runs smooth 3D games (but still takes forever to boot the OS).
Though GLES copying the texture once in the driver seems like a reasonable-ish thing. Normally the GPU texture is not a normal bitmap (shuffled around to optimize cache lines), so the driver shuffling it during the copy probably makes sense. Well, except if you already have a texture in the right format... Fun fact: Nintendo 3DS handheld has worse specs than the original Pi model A (GPU may have higher fillrate? idk, but VC4 has pixel shaders and PICA200 doesn't) But the software is optimized and thus it runs smooth 3D games (but still takes forever to boot the OS).
Oh, yes, i had to decode a format and make a shuffler too, but then the thing refreshes at a proper 60 Hz instead of 20.
Dunno if you guys have any clues here, this is something I've just lived with - Benchmarking using GravityMark with sync disabled, both in OGL and Vulkan, I see it reporting between 100 and 200 FPS at 4k resolution and can be quite steady above 120 FPS much of the time but yet only rarely does the screen observantly exceed 30 FPS. In fact sometimes it feels like it's down at 15 FPS. It's quite obvious when it does jump to 60+ FPS, not only does it suddenly feel smooth but frame tearing becomes apparent then too. I've tried with a 1920x1200 DVI monitor and 3840x2160 DisplayPort monitor, with and without OpenGL desktop effects.
OS is Kubuntu 20.04 with Hardware Enablement updates
Kernel is 5.15.0-82-lowlatency
KDE Plasma 5.18.8 Frameworks 5.68.0, Qt 5.12.8
Mesa is 23.1.6, XOrg AMDGPU 19.1.0-1, libdrm 2.4.110-1
CPU is Ryzen 1700X at 4 GHz all-cores, GPU is Radeon RX 6800
I'm on Kubuntu 23.04 with X11 and whatever the latest NVidia driver is and I have no particular frame pacing issues with light loads. All perfectly smooth and no obvious dropped frames unless the software itself is scuffed (ever play minecraft without performance mods lately?). Though maybe I should try that benchmark you use. Meanwhile on my thinkpad with skylake integrated graphics the desktop effects aren't even consistently smooth.Though I always run in power save mode, I think it's smooth if I go for performance mode.
https://tellusim.com/download/GravityMark_1.82.run
Yea, it's perfectly fine for me (though I had to lower the asteroid count for it to run fast enough....). Of course mailboxing 80 to 100 FPS onto a 60Hz screen isn't really smooth, either. No Vsync option in this.

That's what I mean. Why not? If it's above 60 consistently then it should always be totally smooth. Just with some tearing.
Hmm, maybe I need to test with a CRT monitor then ...
If it's running on the composited desktop it gets mailboxing where the compositor takes the latest whole frame available at the time where it starts preparing a frame. So the time increment between the 60Hz frames you see is inconsistent and it's not smooth. I can't seem to get it to tear in uncomposited mode right now, so idk. Tearing is sorta smoother, but uh, tearing. Vsync is the only way for truly smooth graphics.
(Also, I have no idea why I decided to take the screenshot in GL mode, Vulkan is much better)
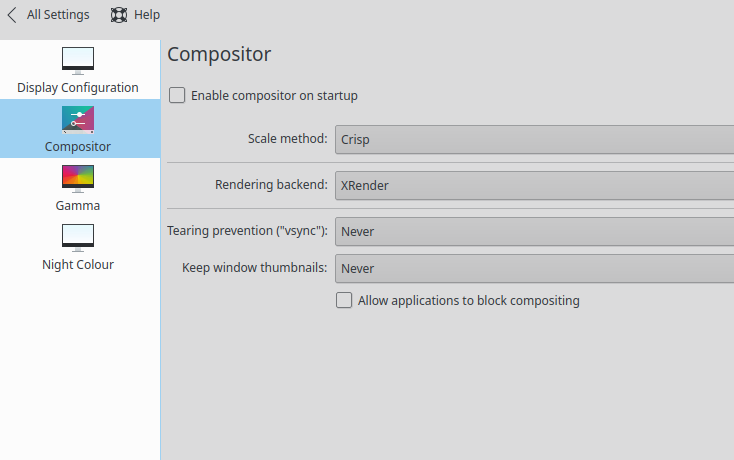
I've already tried turning the compositing off as well as just using xrender for the desktop. The idea being that the program using Vulkan or OGL in fullscreen mode gets full control.
There are also cheating monitors. I have one at the university. It always refreshes at 60 Hz. Give it 50, or 75, it will drop and insert frames itself and keep going 60 Hz. I discovered it by using Atari emulator that displays non-fluent scrolls in demos while the graphic card was set at 50 Hz... so I started experimenting. IIyama 1920x1200, 24"
Damn, me Radeon doesn't have a DVI nor VGA port. Have to dig out the old GPU as well to match up with the CRT monitor ... Geforce 960 ... nvidia blob installed - uh-oh, with reduced asteroid count, it's looking fine on both the CRT via VGA and LCD via DVI. Might be a Mesa or driver level issue when using the Radeon then.
Now I want to compare them side by side. I wonder if me ancient dual-core box can keep up. It might because GravityMark is all about the GPU. But I'll have to spend some time kitting it out. It's been collecting dust since I put this box together in 2017.
PS: I did try the Mesa Geforce driver but GravityMark just crashes during init phase so can't compare that.
Exacltly. The propeller is not the best solution to every problem. For watching videos on a 4k screen I'd take something else. But for anything that has to do with interfacing of "non-PC" signals/protocols, hardware hacks, realtime control, analogue stuff etc. the Propeller is perfectly suited. And if you need both, a big GUI, filesystem AND custom signals you can also combine both and connect the P2 to a PC over ethernet or USB.
Don't pretend like I didn't get 1024x768 video playback going :P That's almost HD. Main bottleneck there is actually external memory bandwidth (for 30FPS playback, whole picture needs 3 reads and 1 write over the PSRAM bus per frame). Could possibly be improved a lot by doing YUV 4:2:0 to RGB conversion during scanout instead of during decoding. The YUV buffers would only need 12 bits per pixel (and no banding, unlike 16bpp RGB)... Anyways, all off topic.
Grr, it is fine on 4k display when I drop the asteroid count down to 20k. FPS is then up between 300 and 600.
EDIT: Well, extending the tests with less asteroids: The compositor definitely makes a difference, it adds semi-regular stuttering, but doesn't account for it all. At lower framerates, GL performs better than Vulkan. Sad-face.
But, on the whole, the reported FPS still doesn't explain behaviour. The asteroid count seems to be a better indicator. Which kind of ruins any comparison with the Geforce 960 since it can't do high numbers at a decent framerate.