

Spin2 vs. C (proposal: struct)
 ManAtWork
Posts: 2,369
ManAtWork
Posts: 2,369
Because Spin2 has much better debug support than C I recently translated some C source to Spin2. Both languages are quite similar. So by replacing "void" by "PUB", "//" by "'", "=" by ":=" and so on this can be done quite fast. (as long as you don't make extensive use of macros and other evil features of C, of course) The resulting code is a bit smaller and a lot more readable, IMHO.
The only big disadvantage of Spin is that it doesn't have data types. It only knows byte, word and long as differently sized memory units. So each time we use a long as floating point variable we have to tell the compiler which operator to use, + vs. .+ and so on. This introduces some possibilities for careless mistakes, but no big deal, C has lot's of pitfalls on its own ("=" vs "==" and all those... check why I hate C).
Adding full data type support to Spin2 would be a lot of work and would probably ruin the simplicity of the language. But structs are really handy to give a chunk of memory a defined layout. Almost every driver written in Spin uses the concept of a mailbox, a sequence of variables defined in the VAR section which is also accessed from the assembler part with offsets calculated manually.
So lets assume I want this
typedef struct {
uint8_t* data; // pointer to pixel data
uint32_t width, height; // total X/Y dimensions in pixel
uint32_t depth; // currently only 4bpp or 1bpp are supported
uint32_t modulus; // address step from one line to next
uint16_t subx, suby; // start X/Y of current sub-window
uint16_t subw, subh; // width and height of sub-window
} Bitmap;
If I have only one instance of this data type there is no problem. I could simply put the data into a DAT section and access it via labels.
DAT Bitmap data long 0 width long 320 height long 240 depth long 4 modulus long 160 subx word 0 suby word 0 subw word 8 subh word 8
But if I need more than one instance or a container/array full of them I need to do pointer calculations. To access target->height where target is a pointer to a Bitmap I could write long[target][bm_height] where bm_height is the offset defined as (@height-@Bitmap)/4.
This could be simplified by a mechanism that helps to calculate the offsets. We have ORG for assembler which essentially means "start counting addresses from here". We could define a new keyword, say "STRUCT"(*), which is basically the same as "DAT" but defines a "virtual" data section, e.g. it doesn't reserve real memory for it but only counts the offsets (similar to what RES does in assembler).
Then bitmapPtr->height could be a shortcut for long[bitmapPtr+offset_height] with offset_height calculated automatically.
(*) if we stick to the three letter keywords then "TYP" would probably be better. Suggestions welcome.
Comments
I was just thinking about this for a project at work! Not that it'd be ideal, but i think you can almost do this with Flexspin. I'm not at a computer right now to verify, but you can create a child object with a bunch of VARs in it, and iirc, flexspin will allow you to read them from the parent. The obj symbol could then be the struct name. So then you could drop something like:
If we had r/w access to those VARs, maybe that could be a solution. Not as dynamic as C probably, but something
I think stucts/records are the #1 requested spin feature. I think i told @cgracey multiple times. I don't think anyone has been able to come up with a non-terrible way to add them into the language.
I guess I would do something more like a VAR section
and then you'd do, mirroring object array syntax
Would also need
sizeofand some non-terrible way of declaring them in DAT.Also, a, perhaps obvious, trick that will save you many pains: if you have to specify the width of a variable on every use, include the width in the identifier. i.e.
(some of these really don't need to be 32 bit...)
It sure helps when you have structs that start to not fit on a single page. Note that I just define constants and calculate the offsets as I go. (This example is in my very cool and not-at-all janky macro assembler, so I could just define a macro to auto-deduce the offsets for an array of symbols, but uhhhhhhhhhhhhhhhhhh yeah I should do that one of those days)
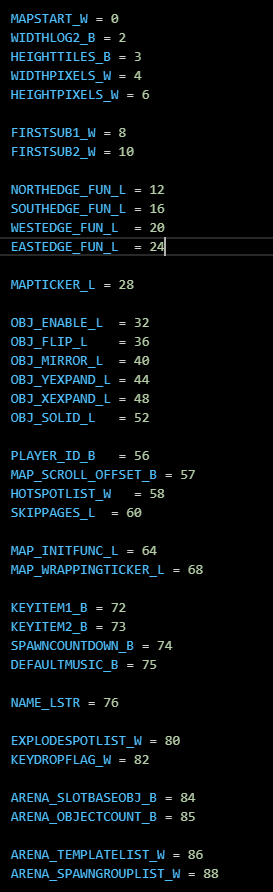
Parallax has good documentation on implementing abstract data structures in spin. It requires you do a lot of book keeping. I researched this awhile back. I like what you are saying. This would be a nice notation and shortcut. The next ask would be the ability to do an index of structs as well with a notation something like
bitmapPtr[3]->heightObviously, the size of the index would need to be defined with the struct. Removes a lot of book keeping.Additional reading for those interested:
https://www.parallax.com/package/an003-implementing-abstract-data-structures-with-spin-objects/
Spin has structs, they just have to go in separate files, and they're called "objects"")
At one point there was a proposal for abstract object pointers; I'm not sure if they made it into official Spin2, but they're in FlexSpin, e.g.:
OBJ Foo = "foo" ' declares abstract object, no actual storage allocated PUB useAbstract(p, x) Foo[p].method(x)So is the
[p]an instance in this case? Kind of like if you had declared more than one at build-time (likeobj foo[1] = "foo"), but it's done at runtime instead?Fun thing about abstract objects: You can include them in pure-PASM files to use their constants
No, it's more like a pointer cast:
pis a pointer to some memory, andFoo[p]treats that memory as an instance of objectFoo. It's kind of likeword[p]in that respect.In fact, a lot of things can be done with the standard object mechanism in Spin. Objects are a bit like classes. You can define member data fields (VAR, per instance) and static data (DAT, global) and they can have methods (member functions). But compared to the C or C++ structs and classes the concept is rather limited.
So the concept of abstract objects would solve this issue. However I don't like the foo[pointer] notation. [] should be dedicated to array-like operations, only, to avoid confusion. I think the C-style pointer derefere operator "->" is still free in Spin2. In Spin1 it means "rotate right" though.
Good point. The question is, how much memory is saved by declaring them as word or byte? Some RISC processors have such a large overhead for byte and word operations that I totally gave up using them. The compiler inserts so many masking and shifting instructions that your code ends up getting bigger instead of smaller when you use bytes, unless you really have a lot of data.
The propeller on the other hand is quite good at accessing <32 bit units and even misaligned longs. But using longs all the time has the advantage that you can do quick block transfers (SETQ + RDLONG) to cog memory and have each variable in a seperate register immediately.
Lack of structs was a primary reason for me to try and push into Rust (ok, and learning Rust). Because writing a FAT-driver w/o them becomes very cumbersome. I wasn't aware of the abstract pointer concept. They are already somewhat helpful, will make use in the future.
I used Objects with just CON section to define Data structures in a attempt to build some ISAM based Database years ago for P1.
Did kind of work nicely having a Person Object and a Customer Object and so on.
The record (or structure) was just a byte Array the offsets hidden in the CON objects.
Nice thing about objects just containing a CON Section is you can include them as often as you wish in any sub object without any memory penalty.
worked quite nice.
Mike
Actually, with the stock PropTool compiler, I think even a CON-only object will consume i-want-to-say 4 bytes? per object and another 4 per instance.
In a typical real time application you normally don't need dynamical memory allocation. Because of CPU load restrictions you have a maximum number of objects you can handle simultanously, anyway. If you have a GUI and a list where the user can add and remove objects it's sometimes easier to handle that with a dynamical (variable size) container. But for a scope, for example, it is completely OK to have a maximum of 10 trigger conditions.
But if you have a file system with user generated data things become less predictable. For example a CNC G-code program might contain only 4 lines and takes one minute to run, but another file with a high resolution 3D shape may require 100 line segments per second or even a lot more. In my CNC software I therefore have reserved a lookahead buffer with 10000 entities which are organized as two linked lists, one for the empty/free ones and one for the full. (a fixed ring buffer doesn't work because some commands are executed out of order)
You couldn't do that with Spin objects, not because it's tecnically impossible but because it would bust the object tree display of the propeller tool.