@RossH said:
Neither the offset nor the data looks right to me. Can you post the actual commands you used to compile and load both programs?
Sure, but to verify there's no funny business going on with the EEPROM, this time I used Tachyon to zero out every location within it:
$0000 $FFFF $00 EFILL
Then I examined all locations within memory. Except for these locations everything was zero:
$0000 $FFFF EE DUMP -->
0000.FF80: 47 8A BC A0 10 8A FC D0 49 8A BC D0 45 8A BC 08 G.......I...E...
0000.FF90: 47 92 BC D0 49 92 BC 08 49 8A 3C C2 13 00 7C 5C G...I...I.<...|\
0000.FFA0: 14 80 00 00 04 00 7C 5C D8 01 00 00 2E 92 BC A0 ......|\........
0000.FFB0: 4A 8E BC A0 02 8E FC 2C 49 8A BC A0 10 8A FC D0 J......,I.......
0000.FFC0: 45 8E BC D0 49 8A BC A0 C0 8A FC D0 4A 8A BC D0 E...I.......J...
0000.FFD0: 45 8A BC 00 4D 8A BC 60 47 86 BC 08 4A 82 BC A0 E...M..`G...J...
0000.FFE0: 04 82 FC 2C 02 82 FC 2C 44 93 FC D0 41 92 BC D0 ...,...,D...A...
0000.FFF0: 43 92 BC D0 49 92 BC 00 4D 92 BC 60 45 92 BC 6C C...I...M..`E..l ok
Then I used this compile command for the loadmenus.c program:
catalina loadmenus.c -C FLIP -C SMALL -D MENU_ADDR=16384 -y
and uploaded it using
payload eeprom loadmenus.binary
Here's the EEPROM Hex Dump for the portion containing the menu items:
Same problem as before. I then cleared the EEPROM again. Like before, all of the locations were zero except for these:
$0000 $FFFF EE DUMP -->
0000.FF80: 47 8A BC A0 10 8A FC D0 49 8A BC D0 45 8A BC 08 G.......I...E...
0000.FF90: 47 92 BC D0 49 92 BC 08 49 8A 3C C2 13 00 7C 5C G...I...I.<...|\
0000.FFA0: 14 80 00 00 04 00 7C 5C D8 01 00 00 2E 92 BC A0 ......|\........
0000.FFB0: 4A 8E BC A0 02 8E FC 2C 49 8A BC A0 10 8A FC D0 J......,I.......
0000.FFC0: 45 8E BC D0 49 8A BC A0 C0 8A FC D0 4A 8A BC D0 E...I.......J...
0000.FFD0: 45 8A BC 00 4D 8A BC 60 47 86 BC 08 4A 82 BC A0 E...M..`G...J...
0000.FFE0: 04 82 FC 2C 02 82 FC 2C 44 93 FC D0 41 92 BC D0 ...,...,D...A...
0000.FFF0: 43 92 BC D0 49 92 BC 00 4D 92 BC 60 45 92 BC 6C C...I...M..`E..l ok
This time I compiled the loadmenus.c program for the C3 like you did:
catalina loadmenus.c -C C3 -C SMALL -D MENU_ADDR=16384 -y
And uploaded it like before:
payload eeprom loadmenus.binary
Here's the resulting EEPROM memory dump for the locations containing the menu items:
It looks like the same problem. I've enclosed the list files and the binary files for both the C3 and the FLiP and the loadmenus.c source file just to make sure.
Maybe theres some clues there but I can't tell the difference.
@RossH said:
Ok. I can confirm it doesn't seem to work with Catalina 5.9.2.
Not yet sure why, but I'll find out.
Ross.
I can confirm your confirmation.
I loaded Catalina 6.1 onto a secondary Windows 10 PC, but for some odd reason and for the first time ever with Catalina, I had to manually go into the System Environment Variables and add Catalina to the PATH. Never seen that before and don't know why it happened.
Anyway, after I modified the PATH I was able to compile the loadmenus.c file. It looks completely different from the previous ones I sent you in the sense that the menu strings look like they are correctly offset.
But, I had to compile using the -C C3 designation because using the -C FLIP designation yielded a XMM not supported on this platform error.
I would attach the .lst file but for some reason the secondary computer I installed Catalina 6.1 on will not let me copy and paste the file to this internet computer I'm using right now.
Tomorrow I can upgrade my software development PC from Catalina 5.9.2 to Catalina 6.1 to get around this problem. Hopefully I won't encounter the problems on it that I'm encountering on the secondary machine I just installed it on.
Somewhere between Catalina 5.9.2 and 6.1 I modified the PASM function to stop it adding a leading space to its string parameter. Doing so was ok if the first line was a normal PASM statement, but caused problems if the first line was a signal to the binder (such as ' Catalina Init, which tells the binder to place what follows into the initialized data segment until the next signal).
I had forgotten about this. Adding an initial blank line to each PASM string also fixed the problem, so the following replacement for loadmenus.c will work in all versions of Catalina, including 5.9.2 and 6.1:
/*
* loadmenus.c - load menu data into EEPROM
*
* Compile with a command like:
* catalina loadmenus.c -C C3 -C SMALL -C XEPROM -C CACHED_1K -D MENU_ADDR=16384
*
* Note that MENU_ADDR must be specified as a decimal number. This program
* does nothing - it is simply used to store the menu data into EEPROM. The
* menu data is stored as an array of addresses starting at MENU_ADDR, followed
* by the data of each menu. If the number of menus is not known in advance,
* terminate the array by adding a known end marker value such as a zero.
*
* Load with a command like:
* payload EEPROM loadmenus.binary
*/
// stringizing functions (required to process MENU_ADDR):
#define STRING_VALUE(x) STRING_VALUE__(x)
#define STRING_VALUE__(x) #x
// start menus by padding to the address:
#define START_MENUS(addr) \
PASM( \
"\n" \
"' Catalina Init\n" \
" alignl\n" \
"Menu_Pad\n" \
" byte $00["STRING_VALUE(addr) " - @Menu_Pad]\n" \
);
// declare a menu - the name must be unique and the value must be a string:
#define DECLARE_MENU(name, value) \
PASM( \
"\n" \
"' Catalina Init\n" \
" alignl\n" \
""#name" long @"#name"_val\n" \
"' end\n" \
"' Catalina Data\n" \
" alignl\n" \
""#name"_val byte "#value"\n" \
" byte 0\n" \
"' end\n" \
);
// add an optional end marker (this allows for a variable number of menus)
#define END_MENUS(marker) \
PASM( \
"\n" \
"' Catalina Init\n" \
" alignl\n" \
" long "#marker"\n" \
);
void main(void) {
START_MENUS(MENU_ADDR); // the menu addresses will be stored here
DECLARE_MENU(HELLO, "HELLO AND WELCOME!!!");
DECLARE_MENU(M0I0, "\x1b[1m\x1b[40m\x1b[2J");
DECLARE_MENU(M0I1, "\x1b[6;30H\x1b[37;40mMiniPlate Participant");
DECLARE_MENU(M0I2, "\x1b[8;20H\x1b[37;40mFirmWare Version 1.0, Rev Data: 14 Sep 22");
DECLARE_MENU(M0I3, "\x1b[10;21H\x1b[37;40mCopyright(c) 2022, All Rights Reserved");
DECLARE_MENU(M0I4, "\x1b[12;31H\x1b[37;40m(1) WiFi Main Menu");
DECLARE_MENU(M0I5, "\x1b[14;31H\x1b[37;40m(2) GPS Main Menu ");
DECLARE_MENU(M0I6, "\x1b[16;31H\x1b[37;40m(3) Diagnostics ");
DECLARE_MENU(M0I7, "\x1b[18;28H\x1b[37;40mMake Selection (1 To 3):");
END_MENUS(0); // a marker can be added to indicate the end of the menus
}
I loaded Catalina 6.1 onto a secondary Windows 10 PC, but for some odd reason and for the first time ever with Catalina, I had to manually go into the System Environment Variables and add Catalina to the PATH. Never seen that before and don't know why it happened.
Recent versions of Catalina don't automatically set the LCCDIR environment variable any more, to make it easier to have multiple versions installed. Instead, LCCDIR is set by the various menu entries and shortcuts, which call the relevant use_catalina batch script - but if you don't use those, you have to do that manually. You can still ask for LCCDIR to be set on installation - it is one of the options you can choose, but is now not selected by default.
Anyway, after I modified the PATH I was able to compile the loadmenus.c file. It looks completely different from the previous ones I sent you in the sense that the menu strings look like they are correctly offset.
But, I had to compile using the -C C3 designation because using the -C FLIP designation yielded a XMM not supported on this platform error.
Yes, the FlIP has no dedicated XMM RAM hardware. But it does support XEPROM. Just add -C XEPROM -C CACHED_1K to the compilation command. **
Ross.
** EDIT: I've added that into the recommended compile command for loadmenus.c
Well, I updated Catalina on my software development PC to version 6.1 and was able to finally compile loadmenus.c so that it generates the menu table entries. After uploading it to EEPROM and using a separate program I wrote called grabmenus.c to grab and display it, what appeared on the screen was wrong:
\x1b[2J\x1b[6;30H\x1b[37;40mMiniPlate Participant\x1b[8;20H\x1b[37;40mFirmWare Version 1.0, Rev Data: 14 Sep 22\x1b[10;21H\x1b[37;40mCopyright(c) 2022, All Rights Reserved\x1b[12;31H\x1b[37;40
m(1) WiFi Main Menu\x1b[14;31H\x1b[37;40m(2) GPS Main Menu \x1b[16;31H\x1b[37;40
m(3) Diagnostics \x1b[18;28H\x1b[37;40mMake Selection (1 To 3):
What should have happened was that the screen was cleared, and each menu string would appear on its own line, with each line being centered on the screen.
Looking over the loadmenus.lst file I see where things went wrong.
For This Declaration: DECLARE_MENU(M0I0, "\x1b[1m\x1b[40m\x1b[2J");
What the compiler needed to do was parse each string and convert each \x1b into a single character
with a value of 1B instead of storing four separate characters: '\','x','1',and 'b'.
I don't know how hard it will be, or even if it's possible, to get the compiler to make the correct
substitution whenever it encounters the \x1b
Yes, I see the problem. The string literal to the PASM() function is not a C string. It is a PASM string, and PASM does not interpret C escape sequences like \x. It just treats them as normal characters.
However, this should not be hard to fix - I will add a new macro that can be used within the PASM() function - I will call it something like _PSTR() - it will take a C string argument and generate the PASM string equivalent, interpreting escape sequences like \x.
Then I will change the DECLARE_MENU macro to be something like:
This should give you the result you expect. Unfortunately we are a bit busy here at the moment - tourist season is just starting - and it may take me a couple of days. I will post a patch when it is ready.
Ross.
EDIT: The way I implemented _PSTR means it includes generating the "byte" keyword, so I have amended the code above.
Your Menu creation technique is awesome and I was concerned that you might have done all that work for nothing if the escape code sequence issue couldn't be resolved.
Glad to hear it looks like a new Macro can fix it. I'm ready to try it out as soon as you have it ready.
In the meantime, I will resume my coding on the Multi-Model program and swing everything over to work with XMM XEPROM instead of XMM LARGE. And yes, it appears increasingly likely I will need to replace the 64 kilobyte EEPROM with a 128 kilobyte one to make all of this work. Looking over the FLiP schematic it appears that the 128 kilobyte chip will be a drop in replacement. But getting the old one off and the new one on is my big concern.
If the XEPROM with caching and the Multi-Model running CMM does everything I want it to do, then I will have arrived at my desired solution of using a FLiP without requiring any additional external memory hardware.
Oh, one more thing. We know that the XMM XEPROM works nicely to retrieve data from the EEPROM with little coding effort on our part.
However, I will also need the ability to be able to store configuration data from time to time in the EEPROM. That, of course, requires the ability to write, which we know can't be done with the XMM XEPROM cog.
Since I will be using the Multi-Model capability anyway, how about I hand the write responsibility over to a CMM cog using its own I2C driver? The CMM cog could simply stop the XMM XEPROM cog, perform the write operation, then do a complete reboot.
Any time I change the configuration data a reboot will be required anyway, so it seems that assigning the EEPROM write function to a CMM cog would be a good solution.
Just in case you aren't able to create a Macro to accommodate the ANSI Escape Code sequences, I've modified your readmenus.c file that does just that on the fly as the Menu strings are read from EEPROM. Seems to grab and display the Menus at a pretty decent speed too.
Here it is:
/*
* readmenus.c - read menu data from EEPROM
*
* Compile with a command like:
*
* catalina readmenus.c -C C3 -C TTY -lci -C XEPROM -C SMALL -C CACHED_1K -D MENU_ADDR=16384
*
* catalina readmenus.c -C FLIP -C TTY -lci -C XEPROM -C SMALL -C CACHED_1K -D MENU_ADDR=16384 -y
*
* Note that MENU_ADDR must be specified as a decimal number. The menus must
* have been previously loaded into EEPROM using loadmenus.c
*
* Load with a command like:
* payload EEPROM readmenus.binary -i
*/
#include <string.h>
#include <math.h>
char OutStr[256];
unsigned long GetMemAddr(unsigned long Address)
{
PASM("mov RI, r2");
PASM("jmp #RLNG");
return PASM("mov r0, BC");
}
char GetMemChar(unsigned long Address)
{
PASM("mov RI, r2");
PASM("jmp #RBYT");
return PASM("mov r0, BC");
}
void main(void)
{
unsigned long menuindex;
unsigned long menuaddress;
char idex;
char jdex;
char cval;
char flag=0;
char outptr;
forever:
menuindex=MENU_ADDR;
for(idex=0; idex<8; idex++)
{
menuaddress=GetMemAddr(menuindex);
outptr=0;
for(jdex=0; jdex<255; jdex++)
{
cval=GetMemChar(menuaddress + jdex);
if(cval == 0) break;
switch(cval)
{
case 0x5c: flag=1;
break;
case 'x': if(flag == 1) flag=2;
break;
case '1': if(flag == 2) flag=3;
break;
case 'b': if(flag == 3) cval=0x1b;
default: flag=0;
break;
}
if(flag != 0) continue;
OutStr[outptr++]=cval;
OutStr[outptr]=0x00;
}
t_printf("%s",OutStr);
menuindex=menuindex + 4;
}
t_printf("\r\n");
k_wait();
goto forever;
}
Just in case you aren't able to create a Macro to accommodate the ANSI Escape Code sequences, I've modified your readmenus.c file that does just that on the fly as the Menu strings are read from EEPROM.
That's good. It will keep you going.
I got my first cut at a macro working - it decodes all C escape sequences so it will be generally useful in PASM - but at the moment it is a stand-alone program (like yours) and I need to do more testing before I am ready to integrate it into the compiler.
However, I will also need the ability to be able to store configuration data from time to time in the EEPROM. That, of course, requires the ability to write, which we know can't be done with the XMM XEPROM cog.
Since I will be using the Multi-Model capability anyway, how about I hand the write responsibility over to a CMM cog using its own I2C driver? The CMM cog could simply stop the XMM XEPROM cog, perform the write operation, then do a complete reboot.
This is a bit too complex to answer off the top of my head. But I don't see why it would be necessary to even stop the XEPROM cog. I think that some synchronization is all that is required to ensure multiple programs don't use the I2C bus at the same time. As long as the XEPROM program is either waiting and/or in a tight loop it will be executing entirely from the cache, and if there are no cache misses another process should be able to just use the I2C bus. But as I say, I'd want to try it before I gave any guarantees!
I have just uploaded a patch (6.1.1) that adds the _PSTR macro to address your issue with the menu strings not being encoded properly when used in the PASM function. It is a beta release available here.
Install this over an existing Catalina 6.1 installation. It contains slightly modified versions of the loadmenus.c and readmenus.c programs (in folder demos\pasm_pstr) that should now store and display your menus correctly.
Let me know how you go. I will include this in the next official release.
I have just uploaded a patch (6.1.1) that adds the _PSTR macro to address your issue with the menu strings not being encoded properly when used in the PASM function. It is a beta release available here.
Thanks. I did the update and so far the strings are being correctly output to the screen. I'll let you know if I see any weird behavior, but given the number of strings I've defined and displayed already, I don't expect to see anything strange. Your encoding appears to be working perfectly.
My task now is to see if I can speed up the screen displays. The fixed Menu strings seem to display pretty fast. The other Menu screens which show each WiFi Station name, coordinates, MAC address, signal strength, etc. update at a snails pace.
All of this information for each Station is placed into a string then output to the display. Right now I'm not using my own ConPrint function but am using a function that populates the aforementioned string using the library vsprintf() function. That's probably the big time consumer there, so I need to find a more efficient and faster way to populate the Station display string. It's been over a year since I've done any actual work on my ConPrint function so I need to revisit it and see if I can make it better since the Forum posting about it appears to be a flop.
The actual output of the Station string itself I can toss over to a CMM cog using the Multi-Model capability. That seemed to speed things up when using the LARGE memory model. Whatever I end up doing, it will have to be compatible with the s4 serial library. Otherwise I could try using the tiny printf function.
It's a shame that your serial library doesn't have the equivalent of s4_hex(), s4_dec(), s4_bin() , s4_str(), etc, that place the information into a string instead of sending it to the serial port. These functions would go a long way to allowing me to build a new ConPrint() function that could call each one as needed to build the display string. All I would need to do would be to create my own s4_float() type function to handle floating point and I would be all set.
But, so far, so good. Things are going as well as I expected. I'm optimistic that I will be able to get the FLiP to do everything I want, but I will have to replace its 64 kilobyte EEPROM with a 128 kilobyte one to get it all to work. One step at a time...
It's a shame that your serial library doesn't have the equivalent of s4_hex(), s4_dec(), s4_bin() , s4_str(), etc, that place the information into a string instead of sending it to the serial port.
Very easy to write your own. You can use the sources for s4_hex, s4_dec, s4_bin etc in source\lib\serial4 - here is a quick hack to make them output their results to a string instead of to the plugin (which this demo program then prints using the TTY plugin, but you could just as easily use the S4 plugin):
/*
* trivial implementations of s4 functions that write to a buffer, based on
* s4_bin.c, s4_dec.c, s4_hex,c etc found in /source/lib/serial4
*
* All functions accept a char buffer as an additional parameter - the
* result is null terminated. It is the responsibility of the caller to
* make sure the buffer is big enough!
*
* Compile this demo program with a command like:
*
* catalina -C C3 -C TTY str_functions.c -lci
*
*/
void str_bin(unsigned value, int digits, char *buffer) {
value <<= (32 - digits);
while (digits-- > 0) {
*(buffer++) = (((value & 0x80000000) == 0) ? '0' : '1');
value <<= 1;
}
*buffer++ = 0;
}
void str_decl(int value, int digits, int flag, char *buffer) {
int i = 1000000000;
int j;
int result = 0;
if (digits < 1) {
digits = 1;
}
if (digits > 10) {
digits = 10;
}
if (value < 0) {
value = -value;
*(buffer++) = '-';
}
if (flag & 3) {
for (j = 10-digits; j > 0; j--) {
i /= 10; // adjust divisor
}
}
for (j = 0; j < digits; j++) {
if (value >= i) {
*(buffer++) = value / i + '0';
value %= i;
result = -1;
}
else if ((i == 1) || result || (flag & 2)) {
*(buffer++) = '0';
}
else if (flag & 1) {
*(buffer++) = ' ';
}
i /= 10;
}
*buffer = 0;
}
#define str_dec(value, buffer) str_decl(value, 10, 0, buffer)
#define str_decf(value, width, buffer) str_decl(value,width,1, buffer)
#define str_decx(value, width, buffer) str_decl(value,width,2, buffer)
void str_hex(unsigned value, int digits, char *buffer) {
int i;
int j;
int count = 0;
// value <<= (8 - digits) << 2
// repeat digits
// tx(port,lookupz((value <-= 4) & $F : "0".."9", "A".."F"))
if (digits < 1) {
digits = 1;
}
if (digits > 8) {
digits = 8;
}
value <<= ((8 - digits) << 2);
for (j = 0; j < digits; j++) {
i = ((value >> 28) & 0xF);
if (i > 9) {
i += 'A' - 10 - '0';
}
*(buffer++) = (i + '0');
value <<= 4;
}
*buffer = 0;
}
void main() {
char buffer[100] = "";
str_hex(0x1234, 4, buffer);
printf("result = \"%s\"\n", buffer);
str_dec(0x1234, buffer);
printf("result = \"%s\"\n", buffer);
str_decf(0x1234, 8, buffer);
printf("result = \"%s\"\n", buffer);
str_decx(0x1234, 8, buffer);
printf("result = \"%s\"\n", buffer);
str_bin(0x1234, 16, buffer);
printf("result = \"%s\"\n", buffer);
while(1);
}
In another recent thread, the possibility of Catalina supporting 64 bit floating point was briefly mentioned. I don't want to hijack that thread onto an unrelated topic, so will continue the discussion here instead.
I have done a bit of poking about in my old code to see why I didn't support 64 bit floats in the first place - as I thought, the problem is that on the Propeller 1 there is just not enough space in the LMM kernel to implement both 32 bit and 64 bit floating point primitives. Too much other stuff had to be sacrificed, which slowed down all programs unacceptably - even those that did not need floating point at all.
At the time my own projects needed floating point implemented in the kernel for speed (LMM on the P1 already being quite slow) so instead of supporting both 32 bit and 64 bit primitives I just used 32 bits for both floats and doubles. But one option I don't recall considering was using 64 bits for both floats and doubles instead - very likely because the P1 only had 32 bit floating point PASM code (still does AFAIK!) and I didn't want to have to spend the time writing 64 bit ones even if I could have done so (which is highly doubtful).
But actually supporting 64 bit floating point in the compiler is not that hard - LCC already does most of the heavy lifting here, so if C implementations of the maths library functions are acceptable (i.e. no fast PASM ones) then it may not even take too much effort. Mostly just a lot of testing time.
However, even though it looks feasible, the results are likely to be too large and too slow to be of much practical use on the P1. So I would still have to offer the option of 32 bit floating point only.
I will continue to investigate, partly because I already had on my "to do" list the job of tidying up some of the messier code in Catalina's code generator (I have already found some useful speed improvements that will end up in a future release).
So 64 bit floating point is now on the "to do" list. However - I can't imagine ever doing anything myself on the Propeller that might need it. So the question is - who might want it, and what applications might you want it for? A really interesting application might get it bumped up the priority list!
It's a shame that your serial library doesn't have the equivalent of s4_hex(), s4_dec(), s4_bin() , s4_str(), etc, that place the information into a string instead of sending it to the serial port.
Very easy to write your own. You can use the sources for s4_hex, s4_dec, s4_bin etc in source\lib\serial4 - here is a quick hack to make them output their results to a string instead of to the plugin (which this demo program then prints using the TTY plugin, but you could just as easily use the S4 plugin):
Thanks, Ross. I'll took a look at these functions and see if I can improve my int2asc() function within my ConPrint using the techniques you outlined here.
Looking over my ConPrint function things look a bit messy and some portions are just asking for trouble, so I will see if I can clean it up.
To complete the set of str_xxxx functions I posted above, here is a version of a floating point function that prints to a buffer:
/*
* str_float, an enhanced version of the original t_float found in
* /source/lib/catalina/tfloat.c. Accepts a char buffer as an additional
* parameter - the result is null terminated. It is the responsibility
* of the caller to make sure the buffer is big enough!
*
* Also accepts the following to specify how to print the float:
*
* width : field width (up to MAX_WIDTH)
* precision : number of digits after decimal point (up to MAX_PRECN)
* flags : bit 0 : 0 use 'e' when printing exponents.
* 1 use 'E' when printing exponents
* bit 1 : 0 precision takes priority over width.
* 1 width takes priority over precision
* bit 2 : 0 do not include sign for positive numbers.
* 1 always include sign (i.e. '+' or '-').
*
* Enhancements:
*
* Exponents will always be output with at least 2 digits (as per printf).
*
* It can print 'E' in place of 'e' for exponents (as per printf).
*
* It can always include a sign (as per printf).
*
* If the width is greater than zero, and greater than that required by
* the specified precision (up to MAX_PRECN) the field will be padded to
* the specified width (up to MAX_WIDTH) with spaces.
*
* If the precision is greater than zero, that number of digits will be
* added after the decimal point (up to MAX_PRECN).
*
* If the precision is zero, the decimal point will be omitted.
*
* If width is given priority only width characters will be output unless
* the width is too small to contain the result.
*
* If precision is given priority, that number of digits will always
* be output after the decimal point even if the result is wider than the
* specified width.
*
* If the specified width and precision cannot both be honoured then
* precision is prioritized over field width.
*
* Compile this demo program with a command like:
*
* catalina -C C3 -C TTY str_float.c -lc -lm
*
*/
#include <float.h>
#include <math.h>
#include <limits.h>
#include <stdlib.h>
#define MAX_WIDTH 30 // maximum field width supported (arbitrary)
#define MAX_PRECN FLT_DIG+2 // maximum precision supported (for float)
/*
* itoa() - convert integer to string
*
* expects: an integer, and a char buffer of at least ITOA_BUFSIZE
*
* returns: a pointer to the filled portion of the buffer
*/
#define ITOA_BUFSIZE 22 /* for 64 bits = 20 digits + sign + trailing nul */
static char *itoa(int i, char *itoa_buf) {
char *pos = itoa_buf + ITOA_BUFSIZE - 1;
unsigned int u;
int negative = 0;
if (i < 0) {
negative = 1;
u = ((unsigned)(-(1+i))) + 1;
}
else {
u = i;
}
*pos = 0;
do {
*--pos = '0' + (u % 10);
u /= 10;
} while (u);
if (negative) {
*--pos = '-';
}
return pos;
}
/* ascii exponent, padded to at least 2 digits and with sign - 32 bit only! */
static char *exptoa(int e, char *itoa_buf) {
char *pos = itoa_buf + ITOA_BUFSIZE - 1;
unsigned int u;
int pad = 0;
int negative = 0;
if (e < 0) {
negative = 1;
u = ((unsigned)(-(1+e))) + 1;
}
else {
u = e;
}
if (u < 10) {
pad = 1;
}
*pos = 0;
do {
*--pos = '0' + (u % 10);
u /= 10;
} while (u);
if (pad) {
*--pos = '0';
}
if (negative) {
*--pos = '-';
}
return pos;
}
/* check for nan or inf - 32 bit only! */
static char * NanOrInf(double r, char *s) {
float f = r;
if ((*((unsigned long *) &f) & 0x7f800000) == 0x7f800000) { /* NaN or Inf */
if ((*((unsigned long *) &f) & 0x007fffff) == 0) { /* Inf */
if (*((unsigned long *) &f) & 0x80000000) {
*s++ = '-';
}
strcpy(s, "inf");
return s+3;
}
else { /* NaN */
if (*((unsigned long *) &f) & 0x80000000) {
*s++ = '-';
}
strcpy(s, "nan");
return s+3;
}
}
else {
return (char *)0;
}
}
static float _powten[] = {
1e-37, 1e-36, 1e-35, 1e-34, 1e-33, 1e-32, 1e-31, 1e-30,
1e-29, 1e-28, 1e-27, 1e-26, 1e-25, 1e-24, 1e-23, 1e-22, 1e-21, 1e-20,
1e-19, 1e-18, 1e-17, 1e-16, 1e-15, 1e-14, 1e-13, 1e-12, 1e-11, 1e-10,
1e-09, 1e-08, 1e-07, 1e-06, 1e-05, 1e-04, 1e-03, 1e-02, 1e-01, 1e-00,
1e+01, 1e+02, 1e+03, 1e+04, 1e+05, 1e+06, 1e+07, 1e+08, 1e+09, 1e+10,
1e+11, 1e+12, 1e+13, 1e+14, 1e+15, 1e+16, 1e+17, 1e+18, 1e+19, 1e+20,
1e+21, 1e+22, 1e+23, 1e+24, 1e+25, 1e+26, 1e+27, 1e+28, 1e+29, 1e+30,
1e+31, 1e+32, 1e+33, 1e+34, 1e+35, 1e+36, 1e+37, 1e+38
};
/* calculate 10^n with as much precision as possible - 32 bit only! */
float powten(int n)
{
if (n < -37) {
return 0.0f;
}
if (n > 38) {
return FLT_MAX; /* infinity */
}
return _powten[n+37];
}
/*
* str_float - print a float to a buffer.
*
*/
void str_float(double d, int width, int precision, int flags, char *buffer) {
char str1[MAX_WIDTH + 1];
char str2[MAX_WIDTH + 1];
char str3[MAX_WIDTH + 1];
char str[MAX_WIDTH + 1];
char itoa_buf[ITOA_BUFSIZE];
int n;
double frac;
int exp;
int l1;
int l2;
int l3;
int digits;
int sign;
if (NanOrInf(d, str)) {
strcpy(buffer, str);
return;
}
if (d < 0) {
d = -d;
sign = -1;
str[0] = '-';
str[1] = '\0';
}
else if (flags & 4) {
sign = -1;
str[0] = '+';
str[1] = '\0';
}
else {
sign = 0;
str[0] = '\0';
}
if (d == 0.0) {
exp = 0;
}
else {
exp = (int)log10(d);
}
if (width > MAX_WIDTH) {
width = MAX_WIDTH;
}
if (flags & 2) {
// width takes precedence when calculating digits
digits = width + sign - 1;
if (precision > 0) {
digits --; // allow for '.'
}
if (digits <= 0) {
digits = (precision > 0 ? 1 : 0);
}
}
else {
// precision takes precedence
digits = precision;
}
if (digits > MAX_PRECN) {
digits = MAX_PRECN;
}
if ((exp > digits) || (d > (float)(INT_MAX & ~0x7F))) {
d /= powten(exp);
if (d >= 10.0) {
d /= 10.0;
exp++;
}
}
else if ((exp < 0) && ((exp <= -digits) || (digits > precision))) {
d *= powten(-exp);
if (d < 1.0) {
d *= 10.0;
exp--;
}
}
else {
// print without exponent
if (exp > 0) {
digits -= exp;
}
exp = 0;
}
if (flags & 2) {
// calculate digits required for exponent
if (exp > 0) {
digits -= 1 + (exp < 100 ? 2 : 3);
}
else if (exp < 0) {
digits -= 2 + (-exp < 100 ? 2 : 3);
}
if (digits <= 0) {
digits = (precision > 0 ? 1 : 0);
}
}
n = (int)d;
frac = d - n;
if (digits > precision) {
digits = precision;
}
frac *= powten(digits);
strcpy(str1, itoa(n, itoa_buf));
l1 = strlen(str1);
if (precision > 0) {
strcpy(str2, itoa((int)frac, itoa_buf));
l2 = strlen(str2);
}
else {
str2[0] = 0;
l2 = 0;
}
*str3 = 0;
if (exp != 0) {
strcpy(str3, exptoa(exp, itoa_buf));
l3 = strlen(str3);
}
else {
l3 = 0;
}
strcat(str, str1);
if (precision > 0) {
strcat(str, ".");
for (n = strlen(str2); n < digits; n++) {
strcat(str, "0");
}
strcat(str, str2);
if (exp != 0) {
for (n = strlen(str2); n < precision; n++) {
strcat(str2, "0");
}
}
}
if (exp != 0) {
if (flags & 1) {
strcat(str, "E");
}
else {
strcat(str, "e");
}
strcat(str, str3);
}
for (n = strlen(str); n < width; n++) {
*(buffer++) = ' ';
}
n = 0;
while (str[n] != 0) {
*(buffer++) = str[n++];
}
*buffer = 0;
}
void test_float (float f, int width, int precision, int flags) {
char buffer[MAX_WIDTH + 1] = "";
str_float(f, width, precision, flags, buffer);
t_printf("result = \"%s\"\n", buffer);
}
void main() {
char buffer[MAX_WIDTH + 1] = "";
float f;
f = 1.2345678;
test_float(f, 0, 1, 3);
f = -1.2345678;
test_float(f, 0, 1, 3);
f = 123.45678;
test_float(f, 5, 1, 3);
f = -123.45678;
test_float(f, 5, 1, 3);
f = 123.45678;
test_float(f, 8, 8, 3);
f = -123.45678;
test_float(f, 8, 8, 3);
f = 1234.5678e-03;
test_float(f, 10, 8, 0);
f = -1234.5678e-03;
test_float(f, 10, 8, 2);
f = -1.2345678e06;
test_float(f, 10, 8, 3);
f = 1.2345678e-06;
test_float(f, 10, 8, 3);
f = -1.2345678e09;
test_float(f, 10, 2, 7);
f = 1.2345678e-09;
test_float(f, 10, 2, 7);
f = -1.2345678e09;
test_float(f, 10, 8, 0);
f = 1.2345678e-09;
test_float(f, 10, 8, 0);
f = -1.2345678e15;
test_float(f, 20, 8, 0);
f = 1.2345678e-15;
test_float(f, 20, 8, 0);
f = -1.2345678e15;
test_float(f, 40, 4, 4);
f = 1.2345678e-15;
test_float(f, 40, 4, 4);
f = -1.2345678e38;
test_float(f, 40, 0, 4);
f = 1.2345678e-38;
test_float(f, 40, 0, 4);
while(1);
}
You will see it incorporates @ersmith's neat suggestion (posted here) to use a lookup table instead of the pow() function - but I did not post it to that thread because it is not really printf compatible. However, it is more sophisticated than the original t_float() function it is based on, and it may be useful to you in your project.
To complete the set of str_xxxx functions I posted above, here is a version of a floating point function that prints to a buffer:
Thanks, Ross, I will take a look at these as well. I've slowly been overhauling my conprint function. I also ripped off Eric's idea about just using a table with the powers of 10. Using Eric's table, the current optimized size of conprint and its two support functions, int2asc() and eftoa(), along with a few test output routines, amounted to about 5548 bytes of code. Interestingly, omitting the table and computing the powers of 10 instead yielded a larger code size.
As I begin to overhaul the eftoa() function, I'm probably going to use the modf() function to split the float into its whole and fractional parts. If the whole number is less than 2E32 I will probably cast it and its fractional part into int values and then use the int2asc() function to convert them into strings. If the whole number is >= 2E32 I will probably have to use the scanning and parsing scheme similar to what I'm doing now.
However I end up doing all of this, the conprint function must be compact, efficient, and accurate. If I can get it under 5000 bytes in code size that would be awesome. The code size isn't overly critical if I run it using the XMM XEPROM cog. However, one idea I'm kicking around is to place any string values, integers, and floats into the shared structure with a CMM cog and have it do all the conversions for me. In that case, the code size would be critical.
Anyway, it's late here so I'm going to call it a day.
Interestingly, omitting the table and computing the powers of 10 instead yielded a larger code size.
This might be the case if the code still needs pow() somewhere else, or if your code uses the -lma or -lmb libraries instead of -lm.
The -lma and -lmb libraries implement pow() (and other floating point functions) in cog RAM, not Hub RAM, so using the table instead will add about 80 longs to the Hub RAM code size. But using the table would probably be faster and more accurate.
There is a bug in the Linux version of the build_utilities script. The Windows version is fine.
An updated script is attached. Note that there are two copies of this script in the distribution - one in the bin folder and the other in the utilities folder. Update them both.
@RossH said:
So 64 bit floating point is now on the "to do" list. However - I can't imagine ever doing anything myself on the Propeller that might need it. So the question is - who might want it, and what applications might you want it for? A really interesting application might get it bumped up the priority list!
Double precision (64-bit) floating point would be a nice feature to have, although at this point I don't need it. But as they say, it's better to have it and not need it, than to need it and not have it.
However, in my application where I have to work with 48-bit MAC addresses, 64-bit integers (long long) would be more useful.
But I'll be more than happy to take whatever you want to put on the table
However, in my application where I have to work with 48-bit MAC addresses, 64-bit integers (long long) would be more useful.
That's less likely to make it onto my "todo" list. A lot of work for not much benefit.
A MAC address is a type with 48 bits, not a 48 bit integer value. You don't generally need integer operations on a MAC address, and it is probably better represented not as an integer at all, but as a type with 6 octets and with any operations you need specifically defined for it. For example:
#include <stdio.h>
#include <stdint.h>
typedef uint8_t MAC_ADDR[6];
void printm(MAC_ADDR m) {
int i;
for (i = 0; i < 5; i++) {
printf("%02X-", m[i]);
}
printf("%02X", m[5]);
}
void main() {
MAC_ADDR my_mac = { 0x01, 0x02, 0x03, 0x04, 0x05, 0x06 };
printf("my MAC address is ");
printm(my_mac);
while(1);
}
This is more efficient than using 64 bits to represent each MAC address - if you have a lot of them, 16 bits of every one is just wasted.
AFAIK, even on the Propeller 2 there is only one register that is 64 bits wide (the system counter) and because the rest of the chip is 32 bits, it has to be accessed as 2 x 32 bit operations anyway. About the only operation you might ever need to do on it are simple comparison or addition, which are trivial to do using 32 bit operations. Supporting 64 bits just for things like that seems like massive overkill!
@RossH said:
A MAC address is a type with 48 bits, not a 48 bit integer value. You don't generally need integer operations on a MAC address, and it is probably better represented not as an integer at all, but as a type with 6 octets and with any operations you need specifically defined for it.
That's pretty much how I do it now. In my code, the MAC address is defined as a union of six bytes with three unsigned shorts.
Here's how I apply the MAC address info:
Using a batch of WiFi stations at fixed survey sites, a rover can estimate its own coordinates if it knows the location of and distance to each fixed site. While the rover can use the RSSI info to sort its pseudorange distance to each site, from closer to farther, it will need to use a lookup table to find the location of each site based upon its MAC address.
The rover can find the name and location of each site it hears by scrolling through the lookup table and comparing the MAC addresses. The MAC address comparison can be done byte by byte, but I actually do it by comparing each of the unsigned shorts within the MAC union.
Comparing each of the three unsigned shorts works fine, but having the 48-bit MAC address stored within a union containing a 64-bit long might allow a faster and more efficient way, at least from a coding perspective, to perform the lookup. But this would come at the cost of an increased size of the union.
But, no worries, the 64-bit long was just an inquiry and what I'm using and doing now works. And with that I now need to return to working on my conprint() function...
@RossH said:
So 64 bit floating point is now on the "to do" list. However - I can't imagine ever doing anything myself on the Propeller that might need it. So the question is - who might want it, and what applications might you want it for? A really interesting application might get it bumped up the priority list!
Do you support 64b integers ?
A partial support for 64b can be to have a library that does MULDIV with an interim 64b value. That's useful, without needing full type support in the compiler.
Some systems also support DIVMOD, that gives the result and remainder in one call. That can double the speed of binary to decimal conversion.
No. I am only considering supporting 64 bits for floating point because the C standard appears to require it, not for any practical reason I can think of. And also because doing so would not slow down programs that do not need floating point, whereas supporting 64 bit integers would slow down all programs, whether it needed them or not. At least it would do so on the Propeller 1, because on that chip C is implemented using LMM, not natively (via HUBEXEC) as it can on the P2. Adding new primitives to the P1 LMM kernel would mean something else has to be sacrificed by moving it out of the kernel - where it can be implemented in fast cog PASM - and implementing it as slower LMM PASM instead.
@RossH said:
This is a bit too complex to answer off the top of my head. But I don't see why it would be necessary to even stop the XEPROM cog. I think that some synchronization is all that is required to ensure multiple programs don't use the I2C bus at the same time. As long as the XEPROM program is either waiting and/or in a tight loop it will be executing entirely from the cache, and if there are no cache misses another process should be able to just use the I2C bus. But as I say, I'd want to try it before I gave any guarantees!
All of which has me wondering if I can get the XMM XEPROM cog to perform write operations to the EEPROM itself, assuming, of course, that it is executing instructions strictly from cache at that time.
Previously you had mentioned that the WBYT primitive wouldn't work because of the time needed to perform a page write to the EEPROM. But if the code is being executed strictly from the cache, is this still a concern?
Getting the XMM XEPROM cog to read blocks of data from EEPROM (like my various Menus) using the RBYT primitive is an awesome feature.
On rare occasions I will need to write a block of configuration data (around 800 bytes or so) to EEPROM, and if WBYT can somehow be made to do that it would be fantastic.
There are no write functions implemented in the XEPROM XMM driver, only read functions - see target\p1\XEPROM_XMM.inc).
You would need to at least add code for XMM_WritePage if you wanted to be able to write back to the EEPROM - this would be enough if the cache were used, and speed was not an issue.


Comments
Neither the offset nor the data looks right to me. Can you post the actual commands you used to compile and load both programs?
Here are the commands I used to load the data:
Then this is what I see in the EEPROM at address 49152 (i.e. 48k = 32k + 16k)
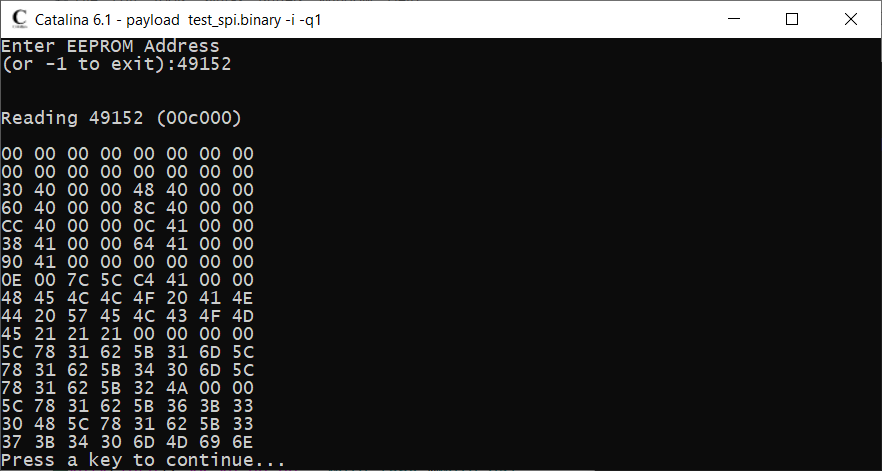
Ross.
Sure, but to verify there's no funny business going on with the EEPROM, this time I used Tachyon to zero out every location within it:
$0000 $FFFF $00 EFILL
Then I examined all locations within memory. Except for these locations everything was zero:
Then I used this compile command for the loadmenus.c program:
catalina loadmenus.c -C FLIP -C SMALL -D MENU_ADDR=16384 -y
and uploaded it using
payload eeprom loadmenus.binary
Here's the EEPROM Hex Dump for the portion containing the menu items:
Same problem as before. I then cleared the EEPROM again. Like before, all of the locations were zero except for these:
This time I compiled the loadmenus.c program for the C3 like you did:
catalina loadmenus.c -C C3 -C SMALL -D MENU_ADDR=16384 -y
And uploaded it like before:
payload eeprom loadmenus.binary
Here's the resulting EEPROM memory dump for the locations containing the menu items:
It looks like the same problem. I've enclosed the list files and the binary files for both the C3 and the FLiP and the loadmenus.c source file just to make sure.
Maybe theres some clues there but I can't tell the difference.
For the record, I'm using Catalina 5.9.2
I've tried adjusting the MENU_ADDR parameter from 16384, to 8192, to 4096
Interestingly enough, it appears that the menu items are always stored in EEPROM here:
Is the #define START_MENUS(addr) within the loadmenus.c program storing the strings in the proper location?
I think this might be the problem. I'm using 6.1. I'll reload 5.9.2 and see what I get.
Ross.
Ok. I can confirm it doesn't seem to work with Catalina 5.9.2.
Not yet sure why, but I'll find out.
Ross.
I can confirm your confirmation.
I loaded Catalina 6.1 onto a secondary Windows 10 PC, but for some odd reason and for the first time ever with Catalina, I had to manually go into the System Environment Variables and add Catalina to the PATH. Never seen that before and don't know why it happened.
Anyway, after I modified the PATH I was able to compile the loadmenus.c file. It looks completely different from the previous ones I sent you in the sense that the menu strings look like they are correctly offset.
But, I had to compile using the -C C3 designation because using the -C FLIP designation yielded a XMM not supported on this platform error.
I would attach the .lst file but for some reason the secondary computer I installed Catalina 6.1 on will not let me copy and paste the file to this internet computer I'm using right now.
Tomorrow I can upgrade my software development PC from Catalina 5.9.2 to Catalina 6.1 to get around this problem. Hopefully I won't encounter the problems on it that I'm encountering on the secondary machine I just installed it on.
It's late here so I'm going to call it a night.
Oops - my bad.
Somewhere between Catalina 5.9.2 and 6.1 I modified the PASM function to stop it adding a leading space to its string parameter. Doing so was ok if the first line was a normal PASM statement, but caused problems if the first line was a signal to the binder (such as
' Catalina Init, which tells the binder to place what follows into the initialized data segment until the next signal).I had forgotten about this. Adding an initial blank line to each PASM string also fixed the problem, so the following replacement for loadmenus.c will work in all versions of Catalina, including 5.9.2 and 6.1:
/* * loadmenus.c - load menu data into EEPROM * * Compile with a command like: * catalina loadmenus.c -C C3 -C SMALL -C XEPROM -C CACHED_1K -D MENU_ADDR=16384 * * Note that MENU_ADDR must be specified as a decimal number. This program * does nothing - it is simply used to store the menu data into EEPROM. The * menu data is stored as an array of addresses starting at MENU_ADDR, followed * by the data of each menu. If the number of menus is not known in advance, * terminate the array by adding a known end marker value such as a zero. * * Load with a command like: * payload EEPROM loadmenus.binary */ // stringizing functions (required to process MENU_ADDR): #define STRING_VALUE(x) STRING_VALUE__(x) #define STRING_VALUE__(x) #x // start menus by padding to the address: #define START_MENUS(addr) \ PASM( \ "\n" \ "' Catalina Init\n" \ " alignl\n" \ "Menu_Pad\n" \ " byte $00["STRING_VALUE(addr) " - @Menu_Pad]\n" \ ); // declare a menu - the name must be unique and the value must be a string: #define DECLARE_MENU(name, value) \ PASM( \ "\n" \ "' Catalina Init\n" \ " alignl\n" \ ""#name" long @"#name"_val\n" \ "' end\n" \ "' Catalina Data\n" \ " alignl\n" \ ""#name"_val byte "#value"\n" \ " byte 0\n" \ "' end\n" \ ); // add an optional end marker (this allows for a variable number of menus) #define END_MENUS(marker) \ PASM( \ "\n" \ "' Catalina Init\n" \ " alignl\n" \ " long "#marker"\n" \ ); void main(void) { START_MENUS(MENU_ADDR); // the menu addresses will be stored here DECLARE_MENU(HELLO, "HELLO AND WELCOME!!!"); DECLARE_MENU(M0I0, "\x1b[1m\x1b[40m\x1b[2J"); DECLARE_MENU(M0I1, "\x1b[6;30H\x1b[37;40mMiniPlate Participant"); DECLARE_MENU(M0I2, "\x1b[8;20H\x1b[37;40mFirmWare Version 1.0, Rev Data: 14 Sep 22"); DECLARE_MENU(M0I3, "\x1b[10;21H\x1b[37;40mCopyright(c) 2022, All Rights Reserved"); DECLARE_MENU(M0I4, "\x1b[12;31H\x1b[37;40m(1) WiFi Main Menu"); DECLARE_MENU(M0I5, "\x1b[14;31H\x1b[37;40m(2) GPS Main Menu "); DECLARE_MENU(M0I6, "\x1b[16;31H\x1b[37;40m(3) Diagnostics "); DECLARE_MENU(M0I7, "\x1b[18;28H\x1b[37;40mMake Selection (1 To 3):"); END_MENUS(0); // a marker can be added to indicate the end of the menus }I have also fixed it in the previous post.
Ross.
Recent versions of Catalina don't automatically set the LCCDIR environment variable any more, to make it easier to have multiple versions installed. Instead, LCCDIR is set by the various menu entries and shortcuts, which call the relevant use_catalina batch script - but if you don't use those, you have to do that manually. You can still ask for LCCDIR to be set on installation - it is one of the options you can choose, but is now not selected by default.
Yes, the FlIP has no dedicated XMM RAM hardware. But it does support XEPROM. Just add -C XEPROM -C CACHED_1K to the compilation command. **
Ross.
** EDIT: I've added that into the recommended compile command for loadmenus.c
Hi RossH,
Well, I updated Catalina on my software development PC to version 6.1 and was able to finally compile loadmenus.c so that it generates the menu table entries. After uploading it to EEPROM and using a separate program I wrote called grabmenus.c to grab and display it, what appeared on the screen was wrong:
What should have happened was that the screen was cleared, and each menu string would appear on its own line, with each line being centered on the screen.
Looking over the loadmenus.lst file I see where things went wrong.
For This Declaration: DECLARE_MENU(M0I0, "\x1b[1m\x1b[40m\x1b[2J");
The compiler did this:
It literally took each character within the string and placed them in memory.
But this is incorrect because \x1b[1m\x1b[40m\x1b[2J is an ANSI Escape Code sequence
where each \x1b is actually 1B.
So the compiler should have done this instead:
What the compiler needed to do was parse each string and convert each \x1b into a single character
with a value of 1B instead of storing four separate characters: '\','x','1',and 'b'.
I don't know how hard it will be, or even if it's possible, to get the compiler to make the correct
substitution whenever it encounters the \x1b
Yes, I see the problem. The string literal to the PASM() function is not a C string. It is a PASM string, and PASM does not interpret C escape sequences like \x. It just treats them as normal characters.
However, this should not be hard to fix - I will add a new macro that can be used within the PASM() function - I will call it something like _PSTR() - it will take a C string argument and generate the PASM string equivalent, interpreting escape sequences like \x.
Then I will change the DECLARE_MENU macro to be something like:
#define DECLARE_MENU(name, value) \ PASM( \ "\n" \ "' Catalina Init\n" \ " alignl\n" \ ""#name" long @"#name"_val\n" \ "' end\n" \ "' Catalina Data\n" \ " alignl\n" \ ""#name"_val _PSTR("#value")\n" \ " byte 0\n" \ "' end\n" \ );This should give you the result you expect. Unfortunately we are a bit busy here at the moment - tourist season is just starting - and it may take me a couple of days. I will post a patch when it is ready.
Ross.
EDIT: The way I implemented _PSTR means it includes generating the "byte" keyword, so I have amended the code above.
Sounds good.
Your Menu creation technique is awesome and I was concerned that you might have done all that work for nothing if the escape code sequence issue couldn't be resolved.
Glad to hear it looks like a new Macro can fix it. I'm ready to try it out as soon as you have it ready.
In the meantime, I will resume my coding on the Multi-Model program and swing everything over to work with XMM XEPROM instead of XMM LARGE. And yes, it appears increasingly likely I will need to replace the 64 kilobyte EEPROM with a 128 kilobyte one to make all of this work. Looking over the FLiP schematic it appears that the 128 kilobyte chip will be a drop in replacement. But getting the old one off and the new one on is my big concern.
If the XEPROM with caching and the Multi-Model running CMM does everything I want it to do, then I will have arrived at my desired solution of using a FLiP without requiring any additional external memory hardware.
Oh, one more thing. We know that the XMM XEPROM works nicely to retrieve data from the EEPROM with little coding effort on our part.
However, I will also need the ability to be able to store configuration data from time to time in the EEPROM. That, of course, requires the ability to write, which we know can't be done with the XMM XEPROM cog.
Since I will be using the Multi-Model capability anyway, how about I hand the write responsibility over to a CMM cog using its own I2C driver? The CMM cog could simply stop the XMM XEPROM cog, perform the write operation, then do a complete reboot.
Any time I change the configuration data a reboot will be required anyway, so it seems that assigning the EEPROM write function to a CMM cog would be a good solution.
Hi RossH,
Just in case you aren't able to create a Macro to accommodate the ANSI Escape Code sequences, I've modified your readmenus.c file that does just that on the fly as the Menu strings are read from EEPROM. Seems to grab and display the Menus at a pretty decent speed too.
Here it is:
/* * readmenus.c - read menu data from EEPROM * * Compile with a command like: * * catalina readmenus.c -C C3 -C TTY -lci -C XEPROM -C SMALL -C CACHED_1K -D MENU_ADDR=16384 * * catalina readmenus.c -C FLIP -C TTY -lci -C XEPROM -C SMALL -C CACHED_1K -D MENU_ADDR=16384 -y * * Note that MENU_ADDR must be specified as a decimal number. The menus must * have been previously loaded into EEPROM using loadmenus.c * * Load with a command like: * payload EEPROM readmenus.binary -i */ #include <string.h> #include <math.h> char OutStr[256]; unsigned long GetMemAddr(unsigned long Address) { PASM("mov RI, r2"); PASM("jmp #RLNG"); return PASM("mov r0, BC"); } char GetMemChar(unsigned long Address) { PASM("mov RI, r2"); PASM("jmp #RBYT"); return PASM("mov r0, BC"); } void main(void) { unsigned long menuindex; unsigned long menuaddress; char idex; char jdex; char cval; char flag=0; char outptr; forever: menuindex=MENU_ADDR; for(idex=0; idex<8; idex++) { menuaddress=GetMemAddr(menuindex); outptr=0; for(jdex=0; jdex<255; jdex++) { cval=GetMemChar(menuaddress + jdex); if(cval == 0) break; switch(cval) { case 0x5c: flag=1; break; case 'x': if(flag == 1) flag=2; break; case '1': if(flag == 2) flag=3; break; case 'b': if(flag == 3) cval=0x1b; default: flag=0; break; } if(flag != 0) continue; OutStr[outptr++]=cval; OutStr[outptr]=0x00; } t_printf("%s",OutStr); menuindex=menuindex + 4; } t_printf("\r\n"); k_wait(); goto forever; }That's good. It will keep you going.
I got my first cut at a macro working - it decodes all C escape sequences so it will be generally useful in PASM - but at the moment it is a stand-alone program (like yours) and I need to do more testing before I am ready to integrate it into the compiler.
This is a bit too complex to answer off the top of my head. But I don't see why it would be necessary to even stop the XEPROM cog. I think that some synchronization is all that is required to ensure multiple programs don't use the I2C bus at the same time. As long as the XEPROM program is either waiting and/or in a tight loop it will be executing entirely from the cache, and if there are no cache misses another process should be able to just use the I2C bus. But as I say, I'd want to try it before I gave any guarantees!
Hello @Wingineer19
I have just uploaded a patch (6.1.1) that adds the _PSTR macro to address your issue with the menu strings not being encoded properly when used in the PASM function. It is a beta release available here.
Install this over an existing Catalina 6.1 installation. It contains slightly modified versions of the loadmenus.c and readmenus.c programs (in folder demos\pasm_pstr) that should now store and display your menus correctly.
Let me know how you go. I will include this in the next official release.
Ross.
Thanks. I did the update and so far the strings are being correctly output to the screen. I'll let you know if I see any weird behavior, but given the number of strings I've defined and displayed already, I don't expect to see anything strange. Your encoding appears to be working perfectly.
My task now is to see if I can speed up the screen displays. The fixed Menu strings seem to display pretty fast. The other Menu screens which show each WiFi Station name, coordinates, MAC address, signal strength, etc. update at a snails pace.
All of this information for each Station is placed into a string then output to the display. Right now I'm not using my own ConPrint function but am using a function that populates the aforementioned string using the library vsprintf() function. That's probably the big time consumer there, so I need to find a more efficient and faster way to populate the Station display string. It's been over a year since I've done any actual work on my ConPrint function so I need to revisit it and see if I can make it better since the Forum posting about it appears to be a flop.
The actual output of the Station string itself I can toss over to a CMM cog using the Multi-Model capability. That seemed to speed things up when using the LARGE memory model. Whatever I end up doing, it will have to be compatible with the s4 serial library. Otherwise I could try using the tiny printf function.
It's a shame that your serial library doesn't have the equivalent of s4_hex(), s4_dec(), s4_bin() , s4_str(), etc, that place the information into a string instead of sending it to the serial port. These functions would go a long way to allowing me to build a new ConPrint() function that could call each one as needed to build the display string. All I would need to do would be to create my own s4_float() type function to handle floating point and I would be all set.
But, so far, so good. Things are going as well as I expected. I'm optimistic that I will be able to get the FLiP to do everything I want, but I will have to replace its 64 kilobyte EEPROM with a 128 kilobyte one to get it all to work. One step at a time...
Very easy to write your own. You can use the sources for s4_hex, s4_dec, s4_bin etc in source\lib\serial4 - here is a quick hack to make them output their results to a string instead of to the plugin (which this demo program then prints using the TTY plugin, but you could just as easily use the S4 plugin):
/* * trivial implementations of s4 functions that write to a buffer, based on * s4_bin.c, s4_dec.c, s4_hex,c etc found in /source/lib/serial4 * * All functions accept a char buffer as an additional parameter - the * result is null terminated. It is the responsibility of the caller to * make sure the buffer is big enough! * * Compile this demo program with a command like: * * catalina -C C3 -C TTY str_functions.c -lci * */ void str_bin(unsigned value, int digits, char *buffer) { value <<= (32 - digits); while (digits-- > 0) { *(buffer++) = (((value & 0x80000000) == 0) ? '0' : '1'); value <<= 1; } *buffer++ = 0; } void str_decl(int value, int digits, int flag, char *buffer) { int i = 1000000000; int j; int result = 0; if (digits < 1) { digits = 1; } if (digits > 10) { digits = 10; } if (value < 0) { value = -value; *(buffer++) = '-'; } if (flag & 3) { for (j = 10-digits; j > 0; j--) { i /= 10; // adjust divisor } } for (j = 0; j < digits; j++) { if (value >= i) { *(buffer++) = value / i + '0'; value %= i; result = -1; } else if ((i == 1) || result || (flag & 2)) { *(buffer++) = '0'; } else if (flag & 1) { *(buffer++) = ' '; } i /= 10; } *buffer = 0; } #define str_dec(value, buffer) str_decl(value, 10, 0, buffer) #define str_decf(value, width, buffer) str_decl(value,width,1, buffer) #define str_decx(value, width, buffer) str_decl(value,width,2, buffer) void str_hex(unsigned value, int digits, char *buffer) { int i; int j; int count = 0; // value <<= (8 - digits) << 2 // repeat digits // tx(port,lookupz((value <-= 4) & $F : "0".."9", "A".."F")) if (digits < 1) { digits = 1; } if (digits > 8) { digits = 8; } value <<= ((8 - digits) << 2); for (j = 0; j < digits; j++) { i = ((value >> 28) & 0xF); if (i > 9) { i += 'A' - 10 - '0'; } *(buffer++) = (i + '0'); value <<= 4; } *buffer = 0; } void main() { char buffer[100] = ""; str_hex(0x1234, 4, buffer); printf("result = \"%s\"\n", buffer); str_dec(0x1234, buffer); printf("result = \"%s\"\n", buffer); str_decf(0x1234, 8, buffer); printf("result = \"%s\"\n", buffer); str_decx(0x1234, 8, buffer); printf("result = \"%s\"\n", buffer); str_bin(0x1234, 16, buffer); printf("result = \"%s\"\n", buffer); while(1); }In another recent thread, the possibility of Catalina supporting 64 bit floating point was briefly mentioned. I don't want to hijack that thread onto an unrelated topic, so will continue the discussion here instead.
I have done a bit of poking about in my old code to see why I didn't support 64 bit floats in the first place - as I thought, the problem is that on the Propeller 1 there is just not enough space in the LMM kernel to implement both 32 bit and 64 bit floating point primitives. Too much other stuff had to be sacrificed, which slowed down all programs unacceptably - even those that did not need floating point at all.
At the time my own projects needed floating point implemented in the kernel for speed (LMM on the P1 already being quite slow) so instead of supporting both 32 bit and 64 bit primitives I just used 32 bits for both floats and doubles. But one option I don't recall considering was using 64 bits for both floats and doubles instead - very likely because the P1 only had 32 bit floating point PASM code (still does AFAIK!) and I didn't want to have to spend the time writing 64 bit ones even if I could have done so (which is highly doubtful).
But actually supporting 64 bit floating point in the compiler is not that hard - LCC already does most of the heavy lifting here, so if C implementations of the maths library functions are acceptable (i.e. no fast PASM ones) then it may not even take too much effort. Mostly just a lot of testing time.
However, even though it looks feasible, the results are likely to be too large and too slow to be of much practical use on the P1. So I would still have to offer the option of 32 bit floating point only.
I will continue to investigate, partly because I already had on my "to do" list the job of tidying up some of the messier code in Catalina's code generator (I have already found some useful speed improvements that will end up in a future release).
So 64 bit floating point is now on the "to do" list. However - I can't imagine ever doing anything myself on the Propeller that might need it. So the question is - who might want it, and what applications might you want it for? A really interesting application might get it bumped up the priority list!")
Ross.
Thanks, Ross. I'll took a look at these functions and see if I can improve my int2asc() function within my ConPrint using the techniques you outlined here.
Looking over my ConPrint function things look a bit messy and some portions are just asking for trouble, so I will see if I can clean it up.
Hello @Wingineer19
To complete the set of str_xxxx functions I posted above, here is a version of a floating point function that prints to a buffer:
/* * str_float, an enhanced version of the original t_float found in * /source/lib/catalina/tfloat.c. Accepts a char buffer as an additional * parameter - the result is null terminated. It is the responsibility * of the caller to make sure the buffer is big enough! * * Also accepts the following to specify how to print the float: * * width : field width (up to MAX_WIDTH) * precision : number of digits after decimal point (up to MAX_PRECN) * flags : bit 0 : 0 use 'e' when printing exponents. * 1 use 'E' when printing exponents * bit 1 : 0 precision takes priority over width. * 1 width takes priority over precision * bit 2 : 0 do not include sign for positive numbers. * 1 always include sign (i.e. '+' or '-'). * * Enhancements: * * Exponents will always be output with at least 2 digits (as per printf). * * It can print 'E' in place of 'e' for exponents (as per printf). * * It can always include a sign (as per printf). * * If the width is greater than zero, and greater than that required by * the specified precision (up to MAX_PRECN) the field will be padded to * the specified width (up to MAX_WIDTH) with spaces. * * If the precision is greater than zero, that number of digits will be * added after the decimal point (up to MAX_PRECN). * * If the precision is zero, the decimal point will be omitted. * * If width is given priority only width characters will be output unless * the width is too small to contain the result. * * If precision is given priority, that number of digits will always * be output after the decimal point even if the result is wider than the * specified width. * * If the specified width and precision cannot both be honoured then * precision is prioritized over field width. * * Compile this demo program with a command like: * * catalina -C C3 -C TTY str_float.c -lc -lm * */ #include <float.h> #include <math.h> #include <limits.h> #include <stdlib.h> #define MAX_WIDTH 30 // maximum field width supported (arbitrary) #define MAX_PRECN FLT_DIG+2 // maximum precision supported (for float) /* * itoa() - convert integer to string * * expects: an integer, and a char buffer of at least ITOA_BUFSIZE * * returns: a pointer to the filled portion of the buffer */ #define ITOA_BUFSIZE 22 /* for 64 bits = 20 digits + sign + trailing nul */ static char *itoa(int i, char *itoa_buf) { char *pos = itoa_buf + ITOA_BUFSIZE - 1; unsigned int u; int negative = 0; if (i < 0) { negative = 1; u = ((unsigned)(-(1+i))) + 1; } else { u = i; } *pos = 0; do { *--pos = '0' + (u % 10); u /= 10; } while (u); if (negative) { *--pos = '-'; } return pos; } /* ascii exponent, padded to at least 2 digits and with sign - 32 bit only! */ static char *exptoa(int e, char *itoa_buf) { char *pos = itoa_buf + ITOA_BUFSIZE - 1; unsigned int u; int pad = 0; int negative = 0; if (e < 0) { negative = 1; u = ((unsigned)(-(1+e))) + 1; } else { u = e; } if (u < 10) { pad = 1; } *pos = 0; do { *--pos = '0' + (u % 10); u /= 10; } while (u); if (pad) { *--pos = '0'; } if (negative) { *--pos = '-'; } return pos; } /* check for nan or inf - 32 bit only! */ static char * NanOrInf(double r, char *s) { float f = r; if ((*((unsigned long *) &f) & 0x7f800000) == 0x7f800000) { /* NaN or Inf */ if ((*((unsigned long *) &f) & 0x007fffff) == 0) { /* Inf */ if (*((unsigned long *) &f) & 0x80000000) { *s++ = '-'; } strcpy(s, "inf"); return s+3; } else { /* NaN */ if (*((unsigned long *) &f) & 0x80000000) { *s++ = '-'; } strcpy(s, "nan"); return s+3; } } else { return (char *)0; } } static float _powten[] = { 1e-37, 1e-36, 1e-35, 1e-34, 1e-33, 1e-32, 1e-31, 1e-30, 1e-29, 1e-28, 1e-27, 1e-26, 1e-25, 1e-24, 1e-23, 1e-22, 1e-21, 1e-20, 1e-19, 1e-18, 1e-17, 1e-16, 1e-15, 1e-14, 1e-13, 1e-12, 1e-11, 1e-10, 1e-09, 1e-08, 1e-07, 1e-06, 1e-05, 1e-04, 1e-03, 1e-02, 1e-01, 1e-00, 1e+01, 1e+02, 1e+03, 1e+04, 1e+05, 1e+06, 1e+07, 1e+08, 1e+09, 1e+10, 1e+11, 1e+12, 1e+13, 1e+14, 1e+15, 1e+16, 1e+17, 1e+18, 1e+19, 1e+20, 1e+21, 1e+22, 1e+23, 1e+24, 1e+25, 1e+26, 1e+27, 1e+28, 1e+29, 1e+30, 1e+31, 1e+32, 1e+33, 1e+34, 1e+35, 1e+36, 1e+37, 1e+38 }; /* calculate 10^n with as much precision as possible - 32 bit only! */ float powten(int n) { if (n < -37) { return 0.0f; } if (n > 38) { return FLT_MAX; /* infinity */ } return _powten[n+37]; } /* * str_float - print a float to a buffer. * */ void str_float(double d, int width, int precision, int flags, char *buffer) { char str1[MAX_WIDTH + 1]; char str2[MAX_WIDTH + 1]; char str3[MAX_WIDTH + 1]; char str[MAX_WIDTH + 1]; char itoa_buf[ITOA_BUFSIZE]; int n; double frac; int exp; int l1; int l2; int l3; int digits; int sign; if (NanOrInf(d, str)) { strcpy(buffer, str); return; } if (d < 0) { d = -d; sign = -1; str[0] = '-'; str[1] = '\0'; } else if (flags & 4) { sign = -1; str[0] = '+'; str[1] = '\0'; } else { sign = 0; str[0] = '\0'; } if (d == 0.0) { exp = 0; } else { exp = (int)log10(d); } if (width > MAX_WIDTH) { width = MAX_WIDTH; } if (flags & 2) { // width takes precedence when calculating digits digits = width + sign - 1; if (precision > 0) { digits --; // allow for '.' } if (digits <= 0) { digits = (precision > 0 ? 1 : 0); } } else { // precision takes precedence digits = precision; } if (digits > MAX_PRECN) { digits = MAX_PRECN; } if ((exp > digits) || (d > (float)(INT_MAX & ~0x7F))) { d /= powten(exp); if (d >= 10.0) { d /= 10.0; exp++; } } else if ((exp < 0) && ((exp <= -digits) || (digits > precision))) { d *= powten(-exp); if (d < 1.0) { d *= 10.0; exp--; } } else { // print without exponent if (exp > 0) { digits -= exp; } exp = 0; } if (flags & 2) { // calculate digits required for exponent if (exp > 0) { digits -= 1 + (exp < 100 ? 2 : 3); } else if (exp < 0) { digits -= 2 + (-exp < 100 ? 2 : 3); } if (digits <= 0) { digits = (precision > 0 ? 1 : 0); } } n = (int)d; frac = d - n; if (digits > precision) { digits = precision; } frac *= powten(digits); strcpy(str1, itoa(n, itoa_buf)); l1 = strlen(str1); if (precision > 0) { strcpy(str2, itoa((int)frac, itoa_buf)); l2 = strlen(str2); } else { str2[0] = 0; l2 = 0; } *str3 = 0; if (exp != 0) { strcpy(str3, exptoa(exp, itoa_buf)); l3 = strlen(str3); } else { l3 = 0; } strcat(str, str1); if (precision > 0) { strcat(str, "."); for (n = strlen(str2); n < digits; n++) { strcat(str, "0"); } strcat(str, str2); if (exp != 0) { for (n = strlen(str2); n < precision; n++) { strcat(str2, "0"); } } } if (exp != 0) { if (flags & 1) { strcat(str, "E"); } else { strcat(str, "e"); } strcat(str, str3); } for (n = strlen(str); n < width; n++) { *(buffer++) = ' '; } n = 0; while (str[n] != 0) { *(buffer++) = str[n++]; } *buffer = 0; } void test_float (float f, int width, int precision, int flags) { char buffer[MAX_WIDTH + 1] = ""; str_float(f, width, precision, flags, buffer); t_printf("result = \"%s\"\n", buffer); } void main() { char buffer[MAX_WIDTH + 1] = ""; float f; f = 1.2345678; test_float(f, 0, 1, 3); f = -1.2345678; test_float(f, 0, 1, 3); f = 123.45678; test_float(f, 5, 1, 3); f = -123.45678; test_float(f, 5, 1, 3); f = 123.45678; test_float(f, 8, 8, 3); f = -123.45678; test_float(f, 8, 8, 3); f = 1234.5678e-03; test_float(f, 10, 8, 0); f = -1234.5678e-03; test_float(f, 10, 8, 2); f = -1.2345678e06; test_float(f, 10, 8, 3); f = 1.2345678e-06; test_float(f, 10, 8, 3); f = -1.2345678e09; test_float(f, 10, 2, 7); f = 1.2345678e-09; test_float(f, 10, 2, 7); f = -1.2345678e09; test_float(f, 10, 8, 0); f = 1.2345678e-09; test_float(f, 10, 8, 0); f = -1.2345678e15; test_float(f, 20, 8, 0); f = 1.2345678e-15; test_float(f, 20, 8, 0); f = -1.2345678e15; test_float(f, 40, 4, 4); f = 1.2345678e-15; test_float(f, 40, 4, 4); f = -1.2345678e38; test_float(f, 40, 0, 4); f = 1.2345678e-38; test_float(f, 40, 0, 4); while(1); }You will see it incorporates @ersmith's neat suggestion (posted here) to use a lookup table instead of the pow() function - but I did not post it to that thread because it is not really printf compatible. However, it is more sophisticated than the original t_float() function it is based on, and it may be useful to you in your project.
Ross.
Thanks, Ross, I will take a look at these as well. I've slowly been overhauling my conprint function. I also ripped off Eric's idea about just using a table with the powers of 10. Using Eric's table, the current optimized size of conprint and its two support functions, int2asc() and eftoa(), along with a few test output routines, amounted to about 5548 bytes of code. Interestingly, omitting the table and computing the powers of 10 instead yielded a larger code size.
As I begin to overhaul the eftoa() function, I'm probably going to use the modf() function to split the float into its whole and fractional parts. If the whole number is less than 2E32 I will probably cast it and its fractional part into int values and then use the int2asc() function to convert them into strings. If the whole number is >= 2E32 I will probably have to use the scanning and parsing scheme similar to what I'm doing now.
However I end up doing all of this, the conprint function must be compact, efficient, and accurate. If I can get it under 5000 bytes in code size that would be awesome. The code size isn't overly critical if I run it using the XMM XEPROM cog. However, one idea I'm kicking around is to place any string values, integers, and floats into the shared structure with a CMM cog and have it do all the conversions for me. In that case, the code size would be critical.
Anyway, it's late here so I'm going to call it a day.
This might be the case if the code still needs pow() somewhere else, or if your code uses the -lma or -lmb libraries instead of -lm.
The -lma and -lmb libraries implement pow() (and other floating point functions) in cog RAM, not Hub RAM, so using the table instead will add about 80 longs to the Hub RAM code size. But using the table would probably be faster and more accurate.
Ross.
There is a bug in the Linux version of the build_utilities script. The Windows version is fine.
An updated script is attached. Note that there are two copies of this script in the distribution - one in the bin folder and the other in the utilities folder. Update them both.
Ross.
Double precision (64-bit) floating point would be a nice feature to have, although at this point I don't need it. But as they say, it's better to have it and not need it, than to need it and not have it.
However, in my application where I have to work with 48-bit MAC addresses, 64-bit integers (long long) would be more useful.
But I'll be more than happy to take whatever you want to put on the table
That's less likely to make it onto my "todo" list. A lot of work for not much benefit.
A MAC address is a type with 48 bits, not a 48 bit integer value. You don't generally need integer operations on a MAC address, and it is probably better represented not as an integer at all, but as a type with 6 octets and with any operations you need specifically defined for it. For example:
#include <stdio.h> #include <stdint.h> typedef uint8_t MAC_ADDR[6]; void printm(MAC_ADDR m) { int i; for (i = 0; i < 5; i++) { printf("%02X-", m[i]); } printf("%02X", m[5]); } void main() { MAC_ADDR my_mac = { 0x01, 0x02, 0x03, 0x04, 0x05, 0x06 }; printf("my MAC address is "); printm(my_mac); while(1); }This is more efficient than using 64 bits to represent each MAC address - if you have a lot of them, 16 bits of every one is just wasted.
AFAIK, even on the Propeller 2 there is only one register that is 64 bits wide (the system counter) and because the rest of the chip is 32 bits, it has to be accessed as 2 x 32 bit operations anyway. About the only operation you might ever need to do on it are simple comparison or addition, which are trivial to do using 32 bit operations. Supporting 64 bits just for things like that seems like massive overkill!")
Ross.
That's pretty much how I do it now. In my code, the MAC address is defined as a union of six bytes with three unsigned shorts.
Here's how I apply the MAC address info:
Using a batch of WiFi stations at fixed survey sites, a rover can estimate its own coordinates if it knows the location of and distance to each fixed site. While the rover can use the RSSI info to sort its pseudorange distance to each site, from closer to farther, it will need to use a lookup table to find the location of each site based upon its MAC address.
The rover can find the name and location of each site it hears by scrolling through the lookup table and comparing the MAC addresses. The MAC address comparison can be done byte by byte, but I actually do it by comparing each of the unsigned shorts within the MAC union.
Comparing each of the three unsigned shorts works fine, but having the 48-bit MAC address stored within a union containing a 64-bit long might allow a faster and more efficient way, at least from a coding perspective, to perform the lookup. But this would come at the cost of an increased size of the union.
But, no worries, the 64-bit long was just an inquiry and what I'm using and doing now works. And with that I now need to return to working on my conprint() function...
Do you support 64b integers ?
A partial support for 64b can be to have a library that does MULDIV with an interim 64b value. That's useful, without needing full type support in the compiler.
Some systems also support DIVMOD, that gives the result and remainder in one call. That can double the speed of binary to decimal conversion.
No. I am only considering supporting 64 bits for floating point because the C standard appears to require it, not for any practical reason I can think of. And also because doing so would not slow down programs that do not need floating point, whereas supporting 64 bit integers would slow down all programs, whether it needed them or not. At least it would do so on the Propeller 1, because on that chip C is implemented using LMM, not natively (via HUBEXEC) as it can on the P2. Adding new primitives to the P1 LMM kernel would mean something else has to be sacrificed by moving it out of the kernel - where it can be implemented in fast cog PASM - and implementing it as slower LMM PASM instead.
Ross.
All of which has me wondering if I can get the XMM XEPROM cog to perform write operations to the EEPROM itself, assuming, of course, that it is executing instructions strictly from cache at that time.
Previously you had mentioned that the WBYT primitive wouldn't work because of the time needed to perform a page write to the EEPROM. But if the code is being executed strictly from the cache, is this still a concern?
Getting the XMM XEPROM cog to read blocks of data from EEPROM (like my various Menus) using the RBYT primitive is an awesome feature.
On rare occasions I will need to write a block of configuration data (around 800 bytes or so) to EEPROM, and if WBYT can somehow be made to do that it would be fantastic.
Maybe some experimentation is in order here...
There are no write functions implemented in the XEPROM XMM driver, only read functions - see target\p1\XEPROM_XMM.inc).
You would need to at least add code for XMM_WritePage if you wanted to be able to write back to the EEPROM - this would be enough if the cache were used, and speed was not an issue.
Ross.