

Reading SD card at 85MHz SPI bus frequency and getting 63.3Mbps or 7.9MB/s
 Peter Jakacki
Posts: 10,193
Peter Jakacki
Posts: 10,193
The SDHC card specification says that 50MHz is the highest bus frequency you can use for SD cards (the old spec was 25MHz). However, I finally got to 50MHz with a smartpin assisted bit-bash mode but now I am bit-smashing it at an 80MHz bus frequency. The read routine reads in at 1/4 of the P2 clock.
TAQOZ# 0 SECTOR $20 DUMP --- 7F800: 90 14 80 FD 50 32 45 56 41 4C 2D 42 03 00 00 00 '....P2EVAL-B....' 7F810: 00 2D 31 01 00 C2 EB 0B F8 09 00 01 00 C2 01 00 '.-1.............' ok TAQOZ# .CLK --- 320MHz ok
My 100MHz scope struggles to display this properly but confirms the frequency and also the data pattern for the first byte of the sector as $90.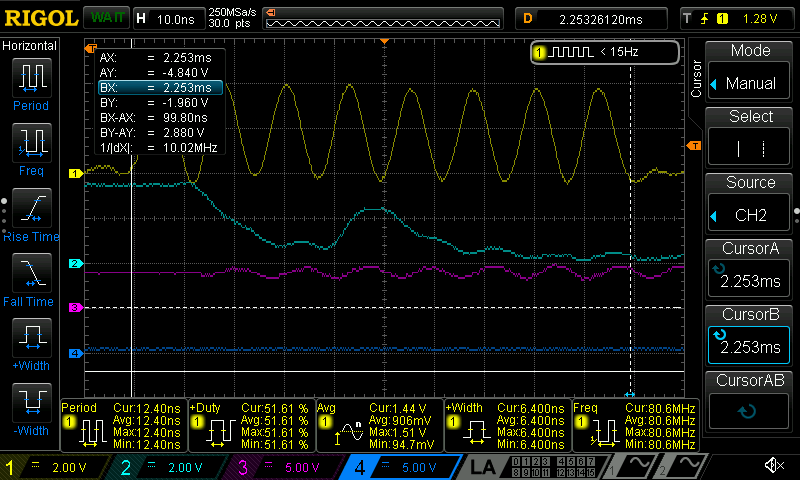
As you can see from these speed checks, most of the time spent reading a random sector is waiting for the data to be ready. So even though it might only take 85us to read 512 bytes, most of the time is spent waiting for the SD card to get the data ready which is around 270us or for an Sandisk Ultra. That is why it is very useful to use multi-block mode without all that latency between each sector.
TAQOZ# .CID --- CARD: SANDISK SD SC64G REV$80 #35190404 DATE:2018/10 ok
TAQOZ# .SPEEDS ---
*** SPEEDS ***
LATENCY......................... 467us,273us,253us,252us,274us,252us,254us,276us,
SECTOR.......................... 307us,359us,338us,337us,359us,337us,338us,360us,
BLOCKS.......................... 5,608kB/s @320MHz ok
Reading the data of four sectors (2kB) with multi-block mode takes 360us. That's 16,384 clock pulses @80MHz that the scope has trouble showing but the gaps between sectors are quite visible.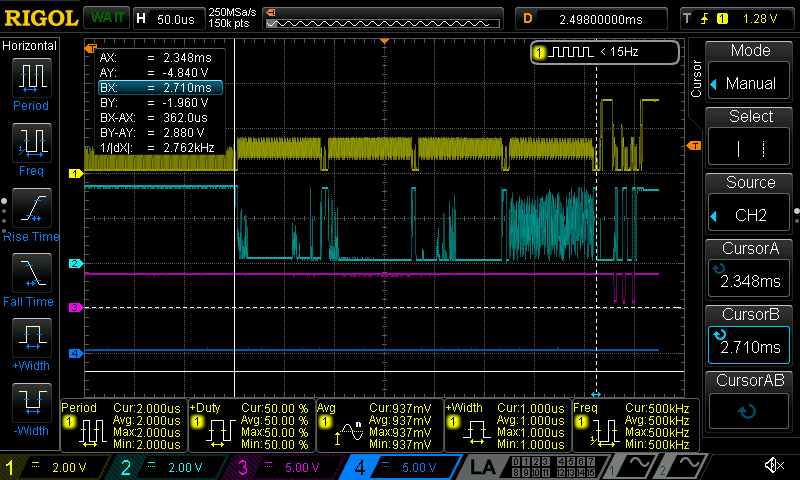
Comments
Peter,
I'm curious to know how long it takes using single but successive sectors, using the above as a reference ie start the timing when reading the first sector, until the last sector. I know it's significant.
That was why I included the speed tests results. Ignoring the first figure as the card does what it does, the other sectors take 273us, 253us to prepare the data. The overall sector read speeds on the next line are the combined latency and data read. So 300 to 360us is how long it takes to read a single sector.
*** SPEEDS *** LATENCY......................... 467us,273us,253us,252us,274us,252us,254us,276us, SECTOR.......................... 307us,359us,338us,337us,359us,337us,338us,360us, BLOCKS.......................... 5,608kB/s @320MHz okIf I viewed a bitmap file using this method then I would be limited to around 1.5MB/s, but using multi-block read then there is only a few microseconds gap between each sector.
Here is how long it takes to find a file, read in its header, then the palette and data, then flip it vertically to correct the image.
TAQOZ# " BIRD" LAP VIEW$ LAP .LAP --- 21,890,272 cycles= 68,407,100ns @320MHz okJust 68ms.
I haven't found the time to toy with it yet, but I have a big suspicion that releasing the card select between commands affects performance. Not sure about reads (a small difference if any), but certainly writes. Can you see what difference that makes for you?
The first read (after ~10 ms of idle) having increased latency is consistent with what I've been observing.
No, I can interact with the SD card via raw reads and write, via SD CMDs etc with simple one-liners and I can immediately test out "theories" of what-ifs. My latest change after seeing the gaps between each byte I thought I could just issue 32 clocks instead and then rearrange the bytes in the long before a wflong. I was speaking to Ray (Cluso99) just as I was in the middle of doing this and wondering about how to rearrange the bytes in the long and he reminded me of the movbyts instruction. So as I was chatting I added that bit in too, and after a couple of goes and fixing some of the code, I got it to work at 60Mbps.
Ray is not a true believer in multi-block reads and reckoned that if you did consecutive single sector reads, that it doesn't have that latency. Well, that can't be right because we have to issue a read command etc and even if data was immediately available, it would still be extra overhead for each and every sector. So I typed a few one-liners while we were talking and proved that while the latency is less than the first sector, it is still a lot. I can even time how long the card must be idle for before the latency resets and takes much longer. It seems as if the SD control chip is going to sleep to conserve power, and must be flushing its caches.
However, no matter the raw sector data transfer rate, it's all for nothing if you cannot sustain it which is why I do multi-block sector reads with only about 10us latency between each sector. For transfers larger than a cluster conventional wisdom tells you that you can't continue reading another cluster without reading the FAT cluster chain to find the next one. Of course you could buffer the cluster chain in RAM so you could continue onto the next cluster but there is a better way. The way I do it I "assume", and quite safely too, that all the clusters are contiguous and that there is no fragmentation. Even if there were, it would be easy to detect and correct too, perhaps at boot, although I have never ever needed to. Maybe I might add a defrag checker to the TAQOZ disk tools but do a defrag check on your P2 SD if you are worried, and go ahead and defrag it. Why should your P2 filesystem have to worry about that when you want to get the most out of it.
So you tried the thing where the CS line stays active between commands? Again, I didn't do any proper testing yet, but I strongly believe that it improves the latency of the first write after an idle period.
Got any exact figures?
(sorry for double post, glanced over this bit at first)
Yes, I think it is a very good idea to make sure a file is actually contiguous before treating it as such, especially when writing. As a special case, it's not very difficult or slow to check the FAT for fragmentation.
Exact figure? Ok, I type in a one-liner which basically starts off with a 0 ms delay between consecutive sector reads and measures the time the second sector read takes. It then increments that delay and repeats the test until I hit a key.
I've added a comment line to describe what it is doing.
When I hit enter this is what happens:
Notice that if I wait 7ms or more between the next sector read, that the sector read takes 2.36ms instead of 288us.
Thanks! So my 10ms estimate was a bit off, but not too far.
Using a 100us granularity instead I can home in and be more precise. It is 6.1ms. (I'm also using the delay value as a sector index)
0 BEGIN DUP SECTOR DROP DUP us LAP DUP 1+ SECTOR DROP LAP CRLF DUP . SPACE .LAP 100 + KEY UNTILIs it possible to read the first byte only of the next sector every 5 ms say, to avoid the long inter-sector latency?
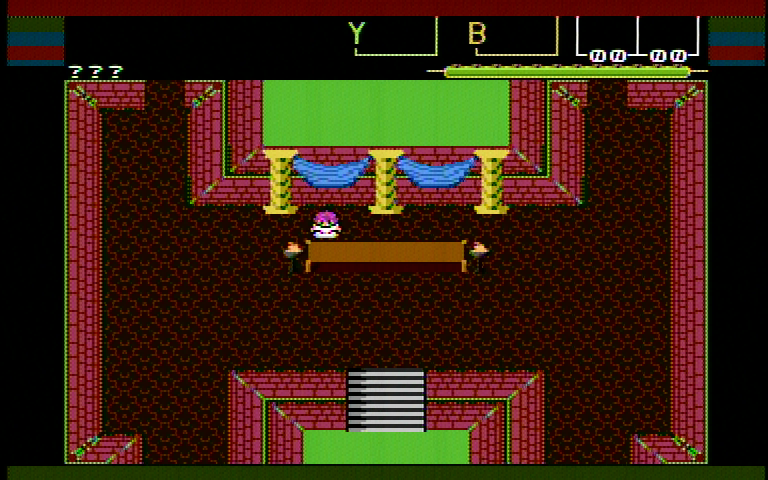
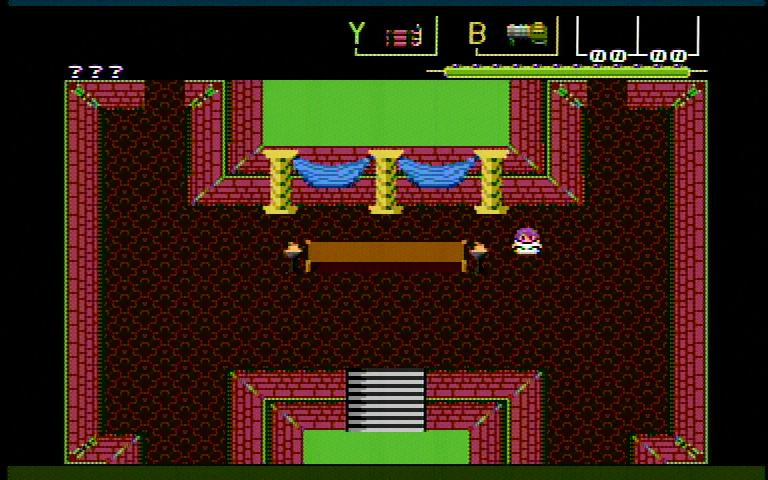
I just tried modifying the projekt menetekel memdriver (as a real world application that does loads of random SD reads that already has a performance monitoring tool in the form of the screen border color) to leave the CS line asserted and yep, it does affect read performance. Annoyingly, the read whose latency changes is cut off by the bottom of the screen.
Eitherhow, it seems to save up to 30 scanlines worth of time, which is indeed slightly less than 2 ms. Of course that latency would have gone away, anyways, if the idle time went below the aforementioned threshold, but there are some situations where this will benefit (SD access after long computation)
How to read the border colors: red/green bars represent SD access (alternating every command), blue bars mean code is running and black means idle.
Before:

After:

Unrelatedly, for I remember Peter saying files don't get fragmented, while messing with this, a file indeed became fragmented:
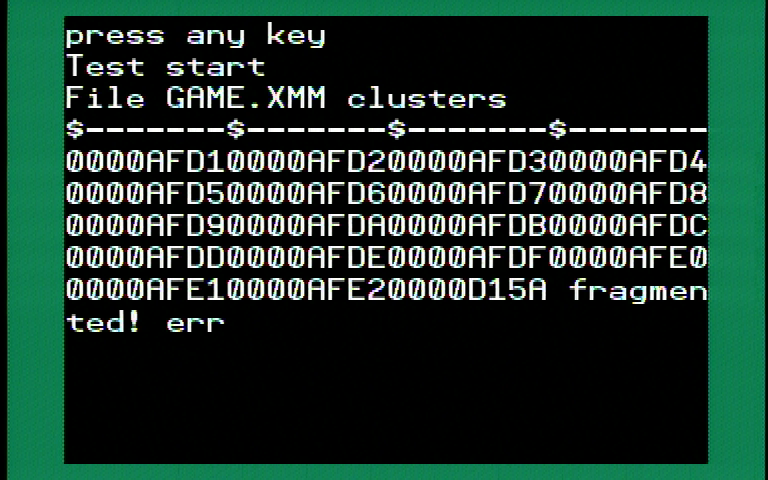
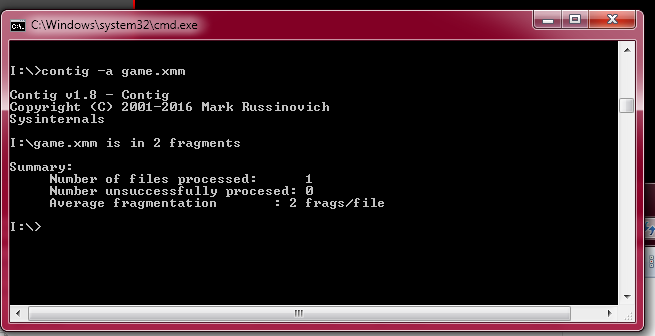
Fragmentation is not impossible but it is easily avoidable and can also be corrected, even on the P2 itself. My code is optimized to work with the starting sector of a file and to treat it as one flat 32-bit addressable memory up to 4GB in size.
I use Linux and maybe its FAT32 driver avoids fragmentation on SD cards, but practically all the files that are on the card are from the PC, so it is an easy matter to delete the files on the card and copy them back on again too. This is an easy once off operation on the PC to ensure the P2 doesn't have to follow cluster chains. When I create new files on an SD card, I do so after the highest file and update the FAT of course. There's so much memory left over on even an 8GB card that I don't have to worry about using that little bit here and that little bit there.
I do the same, but I check the FAT before potentially reading garbage.
To emphasize the advantage of multi-sector reading here is the scope capture when I read 12kB in multi-block mode.
I used this code for the test:
0 $40000 $3000 SDRDSAs you can see the blue trace shows the SD CS remaining low from go to whoa. The magenta trace shows the SD data out and for the first half it is inactive while the SD card takes about 2.5ms to wakeup and prepare the data and the 12k is transferred in the second half.
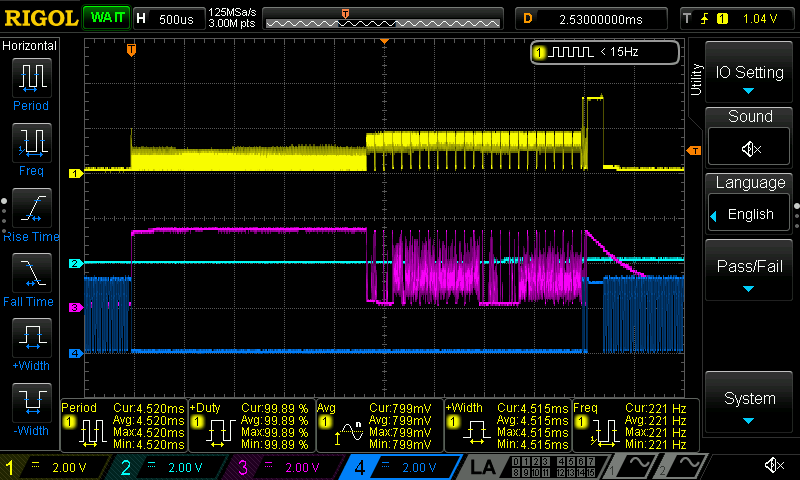
Now I will do that sector by sector with this code:
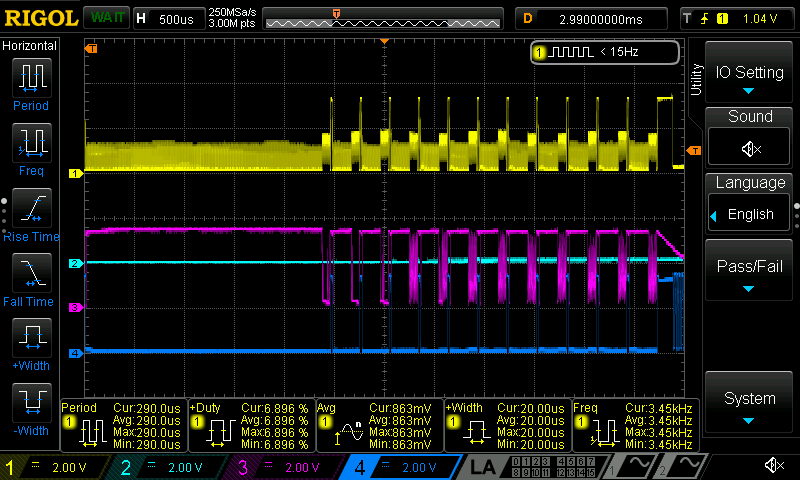
12 FOR I $40000 I 9<< + SDRD NEXTand it is not too shabby but not as good as a multi-block read. But wait! I made a mistake, I only transferred 12 sectors, that's 6k, not 12k.So, use multi-block read for large files.
Peter,
I never doubted block mode would be faster.
When reading one sector at a time, immediately following, then if I'm reading the scope correctly, it takes 2x longer to setup the next sector read than the actual sector read. Is that correct?
If so, singles are a lot faster than I really expected.
@Cluso99") This was mainly a general FYI for everybody but there is some other good news in the random sector read department. It is not only consecutive sectors that benefit if you access them within 6ms, but you can also read any sector with reduced latency too. But have a look at the 2nd last entry though, it seems to go into standby or internal housekeeping although most tests didn't show this.
This was mainly a general FYI for everybody but there is some other good news in the random sector read department. It is not only consecutive sectors that benefit if you access them within 6ms, but you can also read any sector with reduced latency too. But have a look at the 2nd last entry though, it seems to go into standby or internal housekeeping although most tests didn't show this.
Scrub that previous post, I was looking at a 64GB card before that seemed to have a lot more latency. These are the figures for consecutive sectors.
After the initial overhead of about 2.5ms, then...
So about 280us overhead when quickly requesting the next sector, and the sector takes about 350us or was it 130us?
For blocks, ?us overhead plus about 350us for each sector.
Is this correct?
Here's a rundown on some card read speed tests I did on various cards. When I mount the card it prints out the card information and then I run a speed test which also measures and reports a multi-block read speed.
Some cards only got to 5MB/s while others got to over 7.9MB/s.
TAQOZ# MOUNT --- CARD: SANDISK SD SC64G REV$80 #3995938650 DATE:2019/8 ok TAQOZ# .SPEEDS --- *** SPEEDS *** LATENCY......................... 447us,130us,129us,131us,129us,129us,131us,129us, SECTOR.......................... 264us,189us,188us,189us,189us,188us,189us,189us, BLOCKS.......................... 7,879kB/s @340MHz ok TAQOZ# MOUNT --- CARD: SANDISK SD SL08G REV$80 #1561170528 DATE:2016/2 ok TAQOZ# .SPEEDS --- *** SPEEDS *** LATENCY......................... 245us,1207us,306us,304us,303us,307us,337us,309us, SECTOR.......................... 276us,378us,365us,363us,361us,366us,395us,368us, BLOCKS.......................... 6,540kB/s @340MHz ok TAQOZ# MOUNT --- CARD: PHISON PH SD32G REV$30 #3788119258 DATE:2015/1 ok TAQOZ# .SPEEDS --- *** SPEEDS *** LATENCY......................... 326us,595us,615us,598us,621us,588us,629us,587us, SECTOR.......................... 394us,655us,673us,657us,679us,647us,688us,645us, BLOCKS.......................... 5,084kB/s @340MHz ok TAQOZ# MOUNT --- CARD: SANDISK SD SU04G REV$80 #1152213514 DATE:2010/10 ok TAQOZ# .SPEEDS --- *** SPEEDS *** LATENCY......................... 463us,639us,656us,708us,625us,658us,638us,500us, SECTOR.......................... 546us,697us,714us,768us,683us,717us,694us,559us, BLOCKS.......................... 7,344kB/s @340MHz ok TAQOZ# MOUNT --- CARD: SANDISK SD SU04G REV$80 #3538248202 DATE:2010/10 ok TAQOZ# .SPEEDS --- *** SPEEDS *** LATENCY......................... 464us,555us,450us,450us,450us,449us,450us,451us, SECTOR.......................... 524us,509us,508us,509us,509us,509us,509us,509us, BLOCKS.......................... 7,342kB/s @340MHz ok TAQOZ# MOUNT --- CARD: AData AD SD REV$10 #4127424548 DATE:2008/11 ok TAQOZ# .SPEEDS --- *** SPEEDS *** LATENCY......................... 329us,325us,395us,361us,401us,367us,408us,373us, SECTOR.......................... 425us,384us,454us,420us,460us,426us,466us,432us, BLOCKS.......................... 7,716kB/s @340MHz ok TAQOZ# MOUNT --- CARD: SANDISK SD SC64G REV$80 #38874969 DATE:2019/8 ok TAQOZ# .SPEEDS --- *** SPEEDS *** LATENCY......................... 442us,129us,129us,131us,130us,129us,131us,130us, SECTOR.......................... 258us,189us,188us,189us,189us,189us,189us,189us, BLOCKS.......................... 7,881kB/s @340MHz ok TAQOZ# MOUNT --- CARD: SANDISK SD SC64G REV$80 #38883160 DATE:2019/8 ok TAQOZ# .SPEEDS --- *** SPEEDS *** LATENCY......................... 448us,130us,130us,131us,130us,130us,131us,130us, SECTOR.......................... 265us,190us,189us,189us,190us,188us,189us,190us, BLOCKS.......................... 7,879kB/s @340MHz ok TAQOZ# MOUNT --- CARD: SANDISK SD SL16G REV$80 #3596491560 DATE:2014/9 ok TAQOZ# .SPEEDS --- *** SPEEDS *** LATENCY......................... 250us,1331us,329us,334us,336us,353us,337us,335us, SECTOR.......................... 298us,392us,387us,393us,396us,411us,397us,395us, BLOCKS.......................... 7,874kB/s @340MHz ok TAQOZ# MOUNT --- CARD: PHISON PH SD64G REV$30 #4775642 DATE:2016/7 ok TAQOZ# .SPEEDS --- *** SPEEDS *** LATENCY......................... 394us,437us,464us,415us,448us,468us,440us,451us, SECTOR.......................... 471us,496us,524us,473us,507us,527us,499us,510us, BLOCKS.......................... 5,080kB/s @340MHz ok TAQOZ# MOUNT --- CARD: SANDISK SD SL08G REV$80 #188035386 DATE:2016/7 ok TAQOZ# .SPEEDS --- *** SPEEDS *** LATENCY......................... 201us,253us,219us,230us,222us,231us,241us,205us, SECTOR.......................... 250us,280us,278us,288us,278us,290us,299us,264us, BLOCKS.......................... 7,913kB/s @340MHz okThat's pretty neat, to get 50+ MHz working. Wasn't clear to me that more than 25 MHz would work in MMC mode.
Maybe some of these newer formats would go even faster:
https://www.sdcard.org/developers/sd-standard-overview/bus-speed-default-speed-high-speed-uhs-sd-express/
Must be a bit tricky to pull off with the timing delays between in and out on I/O pins...
These Sandisk Ultras are SDCX UHS-I but even SDHC was spec'd to handle 50MHz. I don't even need to use CMD6 to switch it as it just works on all these cards and even the "slow" PHISON 5MB/s cards were working at 84MHz.
I'm not using the smartpin SPI mode though, rather I am generating multiple 32 clocks at 1/4 of the P2 clock and using bit-bashing to read the data.
At these speeds I can view a 640x360x8bpp BMP in 45ms.
TAQOZ# " minion" LAP VIEW$ LAP .LAP --- 15,161,032 cycles= 44,591,270ns @340MHz okSo, the smartpin generates the clock? How do you read the data at 1/4 P2 clock? Isn't that just 2 instructions per bit?
Are you just reading INA/B and then assembling the data bits afterward?
I'm guessing you could pause every 32 bits to transfer the accumulated pin data into LUT or COGRAM or just write to the FIFO. You'd not incur much of a penalty that way. This is probably why Peter says "multiple 32 clocks".
For example, after 32 bits of data (64 instructions - TESTP and RCL or RCR sequence), you'd need 1 instruction for a write to FIFO, another 1 for the smartpin clock restart, all done in a tight REP block. Maybe a short delay to resync. It's only a small amount of loop overhead.
That's the whole idea and all I need to do is rep "testp+rcl" 32 times then movbyts and a wflong etc. I can slow down the transfer by changing the clock timing pattern and if it's not $2_0004 anymore than the rep count increases to 3 to include an otherwise dummy waitx clkdly after the testp+rcl instructions.
This is the main loop with an extra waitx that gets included in the rep if it needs to run slower.
.l0 wypin #32,sck ' trigger 32 clocks waitx sddly ' delay (set to 8 for 200MHz) rep x,#32 ' x = 2 for fast or 3 for slower testp miso wc ' 4 cycle/bit read rcl r1,#1 waitx clkdly ' extra wait instruction for modified SPIRX movbyts r1,#%00011011 ' rearrange bytes wflong r1 ' save four bytes djnz a,#.l0 ' for long countI haven't been keen on the smartpin SPI mode although I ought to try it sometime. The thing is, of all the things we wanted P2 to do, SPI was one of the basics and it's a pity it is not as easy to use as the async modes. How have you found it?
That's pretty tight Peter and was close to what I expected (just missed the movbyts requirement). The only way to really go much higher (in SPI mode) is to use the streamer as that can double or quadruple the clock rate again but I very much doubt that will be achievable with regular SD card's IO.
At the same clock rate the streamer could only boost transfer performance by a factor up to 71/64 (~10% more) to account for the loop overheads. So this bit bash approach is very good indeed. The sddly value probably just needs to be tuned for the P2 operating frequency.
@"Peter Jakacki" That's great! thanks. I might also be able to use this to get my FLIR Lepton driver video over SPI up to the >25 MHz I need for Lepton3...
This is the main high-speed SPI receive routine that I use, and I will do the same for the transmit as well although I haven't tested that yet.
I have my settings registers just before the routine since this is part of the kernel and runs out of the same TAQOZ cog, and rather than having dedicated register names, which I could have, I instead find the address of SPIRX, and simply index back to write to the cog. My code is adjusting the rep count based on the timing pattern in sdhl, but this could just as well be a register too although it should only be set to 2 for fastest, or 3 for anything else.
' SPIRX ( dst cnt -- ) ' Read bytes in from SPI to memory ' high speed SD SPI read at sysclk/4 = 50MHz read speed @200MHz clock ' the clock timing is positioned just before SPIRX so runtime sw can find and adjust this ' Timing: TAQOZ# SDBUF 512 LAP SPIRX LAP .LAP --- 19,544 cycles= 61,075ns @320MHz ' clkdly long 0 ' normally left at zero for no extra delay sddly long 10 ' 4 @80MHz, 6 @160MHz, 8 @240MHz, 10 at 320MHz sdhl long $2_0004 ' pulses 2 cycles high, 2 low for fast 4 cycle bit-rate SPIRX ' ( b:dst a:cnt -- ) getbyte x,sdhl,#2 ' adjust rep loop for slower settings cmp x,#2 wz ' rep 2 or 3 instructions if_nz mov x,#3 ' 3 for slower tranfers using extra waitx fltl sck wrpin #%01_001000,sck ' pulse mode for sck drvl sck wxpin sdhl,sck ' set sck hilo period wrfast #0,b ' setup to write to dest shr a,#2 ' convert byte count to longs .l0 wypin #32,sck ' trigger 32 clocks waitx sddly ' delay (set to 8 for 200MHz) rep x,#32 ' x=2 for fast or 3 for slower testp miso wc ' 4 cycle/bit read rcl r1,#1 ' shift in next bit waitx clkdly ' optional extra wait instruction for modified SPIRX movbyts r1,#%00011011 ' rearrange bytes wflong r1 ' save four bytes in one long djnz a,#.l0 ' for long count drvl sck ' probably not necessary!! wrpin #0,sck ' disable smartpin jmp #\DROP2 ' discard dst and cntIs is possible to set sck with a smartpin for this?
rep #3,#16 testp miso wc testp miso wz rczl r1 ' shift in two bitsAha clever, use an asymmetric clock! Yeah that might be achievable for another speed boost. You just need to align it carefully each time it starts up, that's probably the tricky bit. Could be worth a try for those lower clock speed P2 applications where you still want to keep the SD transfer rate high, though the streamer is probably better for that as you could run as low as 50MHz and still get 50Mbps SPI transfers.
@TonyB_ To tell you the truth there are still a lot of instructions I have not worried about using even though I have documented them myself. Even Cluso99 had to remind me about movbyts")
While it's a clever hack the problem is that the 2 clock burst would have to occur at 1/2 P2 clock and that may be way too high for the SD card although as rogloh mentions, it would be more suitable for lower clock speeds but that is also where the streamer is handy too.