

Software RFLONG work-alike in 6 clocks (extra on block load)
 cgracey
Posts: 14,323
cgracey
Posts: 14,323
I was thinking about how to make stacks faster and I came up with a way to do a software RFLONG in six clocks (3 inst's). More clocks are needed for periodic block loads, but it's a lot faster than waiting 9..16 clocks to do each RDLONG if your data is contiguous.
This uses compounded ALTI instructions to first point to a unique instruction and modulo-inc the instruction pointer, and then execute that instruction indirectly. You could implement as many independent instances as you might need. This is important for when the FIFO is already configured and busy, but you need some faster way to sequentially read the hub RAM. You just place the 3-instruction sequence where you want the fake RFLONG to happen and 7/8ths of your reads will take only 6 clocks. WFLONG work-alikes could be made, too.
Here is the code. It outputs the fake-RFLONG data to the DAC on P0 for viewing:
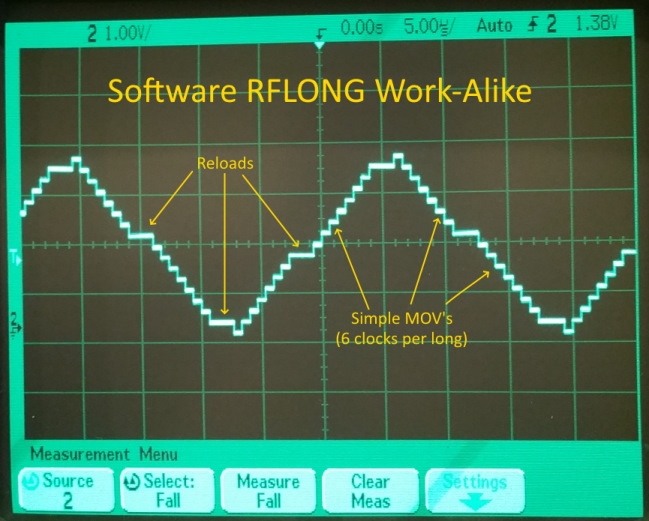
Here is a scope picture of the DAC output. You can see where the loader was called, instead of a simple MOV executing:
This uses compounded ALTI instructions to first point to a unique instruction and modulo-inc the instruction pointer, and then execute that instruction indirectly. You could implement as many independent instances as you might need. This is important for when the FIFO is already configured and busy, but you need some faster way to sequentially read the hub RAM. You just place the 3-instruction sequence where you want the fake RFLONG to happen and 7/8ths of your reads will take only 6 clocks. WFLONG work-alikes could be made, too.
Here is the code. It outputs the fake-RFLONG data to the DAC on P0 for viewing:
' ' ' Software RFLONG work-alike - implement as many as you need ' - Takes 3 instructions (6 clocks) to read next long. ' - 3-instruction sequence can be used wherever needed. ' - Every first/8th read uses extra clocks to read 8 more longs. ' - Additional RFLONG work-alikes only require buffer and control variables. ' dat org ' This is the 3-instruction sequence which acts like RFLONG sw_rflong alti rf_ptr,rf_inc 'next D = rf_ptr[17:9], increment rf_ptr[11:9] alti 0 'substitute D points to next instruction nop 'execute rf_inst_0..7 ' Output the long value to DAC on P0 for testing setbyte dacmode,x,#1 'write value to DAC field wrpin dacmode,#0 'update DAC pin drvl #0 'enable DAC jmp #sw_rflong 'loop dacmode long %10110_00000000_00_00000_0 ' ' ' Eight instructions at addresses where only the three LSBs differ (ie %00001xxx) ' orgf ($ & %111) == 0 ? $ : ($ | %111) + 1 'make 8-long alignment rf_inst_0 call #\loader 'load and return long 0 (first and every 8th time) rf_inst_1 mov x,rf_buff+1 'return long 1 rf_inst_2 mov x,rf_buff+2 'return long 2 rf_inst_3 mov x,rf_buff+3 'return long 3 rf_inst_4 mov x,rf_buff+4 'return long 4 rf_inst_5 mov x,rf_buff+5 'return long 5 rf_inst_6 mov x,rf_buff+6 'return long 6 rf_inst_7 mov x,rf_buff+7 'return long 7 ' ' ' Loader routine - loads rf_buff with 8 new longs, wraps address, returns long 0 ' loader setq #8-1 'load 8 longs from current address rdlong rf_buff+0,rf_curr add rf_curr,#8*4 'update address and wrap when at limit cmp rf_curr,rf_wrap wz if_z mov rf_curr,rf_init _ret_ mov x,rf_buff+0 'return long 0 ' ' ' Data ' rf_inc long %000_110_000__000_111_000 'inc D[2:0] and substitute D into next instruction rf_ptr long rf_inst_0 << 9 'initially point D to rf_inst_0, inc's and wraps 0..7 rf_curr long test_data 'current address rf_init long test_data 'initial address rf_wrap long test_data+(8*4)*4 'wrap address (+4 blocks of 8 longs) rf_buff res 8 '8 longs for read buffer x res 0 'register to receive longs ' ' ' Test data to fake-RFLONG from hub - 4 blocks of 8 longs ' orgh test_data long $00,$10,$20,$30,$40,$50,$60,$70,$80,$90,$A0,$B0,$C0,$D0,$E0,$F0 long $FF,$EF,$DF,$CF,$BF,$AF,$9F,$8F,$7F,$6F,$5F,$4F,$3F,$2F,$1F,$0F
Here is a scope picture of the DAC output. You can see where the loader was called, instead of a simple MOV executing:
649 x 521 - 105K
Comments
Still, any alternative will also have management overheads
Hmmm... yeah, that overhead averages time to ~10 clocks per long.
Roger is doing probably the best with his line buffers using RDLUT/WRLUT with PTRx for the indexing ops (instead of ALTx prefixing), plus scanline length burst transfers between hubram and lutram.
EDIT; Err, might not be full lines at a time. Might of had to reduce them to make room.
Plus an overhead of 15 longs for the mechanism (8 rf_inst, 6 loader, 1 rf_inc), plus 15 longs per instance (3 instruction sequence, rf_ptr, rf_curr, rf_init, rf_wrap, 8 rf_buff).
This seems to me like a solution in search of a problem: a big, expensive exercise, that except in particular circumstances is possibly better achieved by careful instruction timing (and placement) to match to the egg-beater to give a consistent 9-10 cycle result; or through LUT sharing with a second cog if the timing is that tight. Either of these other approaches has the advantage of much less jitter.