

HyperRAM Solutions for P2 (and P1)
 RJSM
Posts: 68
RJSM
Posts: 68
in Propeller 2
As noted on these forums on a number of previous occasions, HyperRAM (HR) is attractive for a number of reasons - its low cost, high density and relatively simple interface requirements.
Mouser show the ISSI 8MB, IS66WVH8M8BLL-100B1LI at $4.47 - qty 1- and dual-die stack 16 MB parts (IS66WVH16M8BLL-100B1LI) are also now available for $6.58. There is also an equivalent 8MB Cypress part, the S27KL0641DABHI020 for only $2.86, qty 1.
I’ve used HR previously in several XMOS-based instrument designs, and you’ll find some useful background information about these here -
http://www.instruments4chem.com/page10/page53/index.html
Recently, I’ve been working on interfacing HyperRAM to P2 using a smart pin to generate the clock signal and the streamer to manage the data bus transactions. Some careful management of the RWDS signal is also required.
I connected a small HR breakout PCB to a P2 emulation running on a DE2-115 FPGA and then wrote some code to configure the HR registers and read/write 128 byte buffers from/to HR.
I’ve got these latter routines running in ~ 2.6 usec, affording a data transfer rate between HUB RAM and HyperRAM in excess of 50 MB/s. The key step in getting this working was to correctly synchronize the smart pin and streamer so as to obtain reliable DDR transfers.
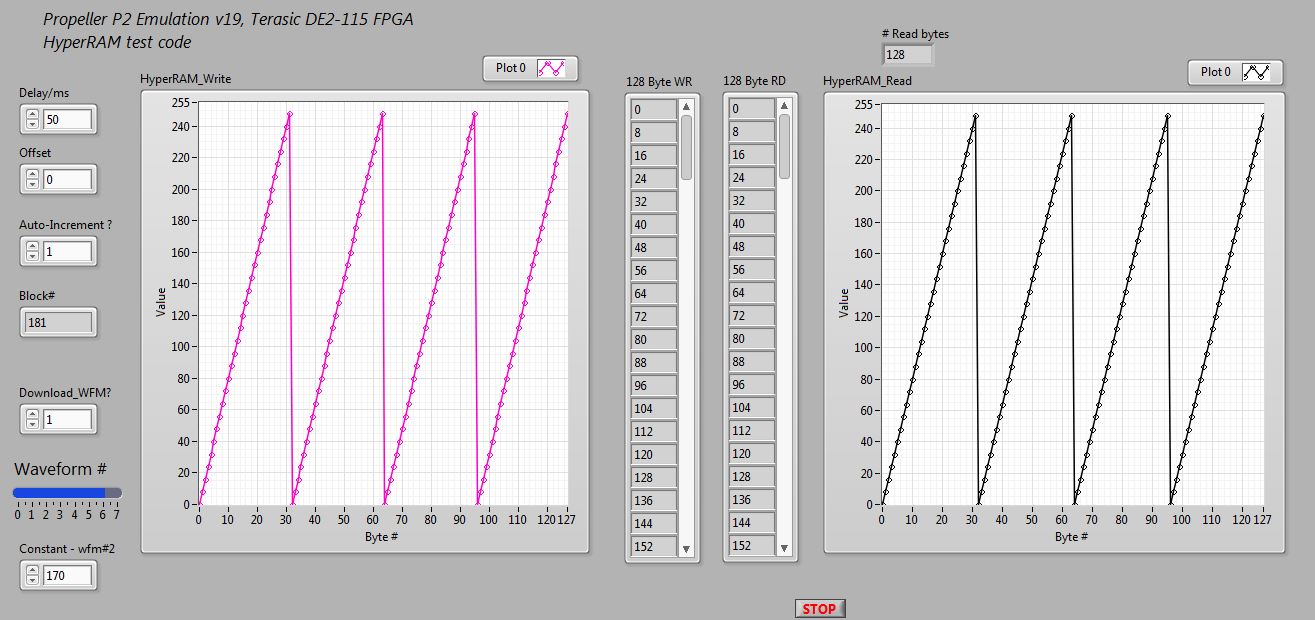
To test the interface I’ve developed a LabVIEW front end that allows a selection of different 128 byte waveforms to be downloaded into HyperRAM and then read back for comparison.
I’ve attached some screen grabs showing typical results. Here, reading/writing HyperRAM is done by reference to a block number; in an 8MB HR chip we have 65536 x 128 of these blocks. The two graph windows show the dataset written to HyperRAM (left) and read back (right), allowing for a quick visual validation of the data transfer.
At present, I’m seeing an occasional glitch in a few bytes in the data transfer in a couple of the waveforms I’ve tested. I’m currently waiting on a new PCB that I’m confident will fix this problem - which completely disappears if I touch the CLK signal from the DE2-115 board to the corresponding pin on the HR breakout with my finger (a capacitance/drive issue ??).
I’d like to thank ozpropdev for a P2 v19 version of his logic analyzer code for the DE2-115 that helped me sort out a few issues I had along the way…
After getting this far, I decided to have an attempt at a proof-of-concept for the P1. I started out by making a small P1-based PCB with an HR chip mounted on a small castellated breakout PCB – see the attached photo. The pin labelled GND in the lower left of my HyperRAM breakout is actually a Vcc pin and some surgery was needed to fix this issue (hence the red wire - that appears to short Vcc and GND !).
On the P1 the main issue is that hub accesses can only be guaranteed every 16 clock cycles (or 200 ns) - and this is only after you’ve synchronized your memory transfers. This means that in between each successive rdbyte/wrbyte instruction you’ve got just 2 intermediate instructions to work with.
Given the self-refresh requirements of the HR chip (with data buffer transfers typically restricted to a maximum of 4 us, but which can be stretched out to 8 us) it seemed the buffer size on the P1 would inevitably be restricted to a modest 16 bytes. For that buffer size it turns out there’s a roughly 100% overhead to provide a memory address plus additional latency clocks.
Based on these thoughts, however, it did still seem that a target goal of slightly > 2 MB/s would be feasible on the P1 (that’s the buffer transfer rate though).
To cut a long story short, after drawing some initial inspiration from some neat OBEX code posted by Tracy Allen, I’ve succeeded in achieving a viable P1 HR interface solution using 3 COG’s.
I’ll post P1 and P2 versions of my code after I’ve added some liberal comments to aid understanding. It will be after the coming weekend before I can get back on to this again but I felt forum members would be interested to learn of progress made thus far.
I’m fairly confident that others may see ways for further improvement given that I’m no code guru. Comparing my own P2 vs. P1 programming experiences after getting to this point we’ll be truly empowered when we’ve got some real Si to play with – the P2 instruction set/functionality really does provide us with some awesome capabilities.
Thus far, I’ve been able to document an ~ 25-fold performance increase on the P2 version using some very compact code (smart pin/streamer +++ !!) and even that factor can very likely be improved upon. I’m sure there are numerous other applications out there that will really benefit from a P2…
Richard
Mouser show the ISSI 8MB, IS66WVH8M8BLL-100B1LI at $4.47 - qty 1- and dual-die stack 16 MB parts (IS66WVH16M8BLL-100B1LI) are also now available for $6.58. There is also an equivalent 8MB Cypress part, the S27KL0641DABHI020 for only $2.86, qty 1.
I’ve used HR previously in several XMOS-based instrument designs, and you’ll find some useful background information about these here -
http://www.instruments4chem.com/page10/page53/index.html
Recently, I’ve been working on interfacing HyperRAM to P2 using a smart pin to generate the clock signal and the streamer to manage the data bus transactions. Some careful management of the RWDS signal is also required.
I connected a small HR breakout PCB to a P2 emulation running on a DE2-115 FPGA and then wrote some code to configure the HR registers and read/write 128 byte buffers from/to HR.
I’ve got these latter routines running in ~ 2.6 usec, affording a data transfer rate between HUB RAM and HyperRAM in excess of 50 MB/s. The key step in getting this working was to correctly synchronize the smart pin and streamer so as to obtain reliable DDR transfers.
To test the interface I’ve developed a LabVIEW front end that allows a selection of different 128 byte waveforms to be downloaded into HyperRAM and then read back for comparison.
I’ve attached some screen grabs showing typical results. Here, reading/writing HyperRAM is done by reference to a block number; in an 8MB HR chip we have 65536 x 128 of these blocks. The two graph windows show the dataset written to HyperRAM (left) and read back (right), allowing for a quick visual validation of the data transfer.
At present, I’m seeing an occasional glitch in a few bytes in the data transfer in a couple of the waveforms I’ve tested. I’m currently waiting on a new PCB that I’m confident will fix this problem - which completely disappears if I touch the CLK signal from the DE2-115 board to the corresponding pin on the HR breakout with my finger (a capacitance/drive issue ??).
I’d like to thank ozpropdev for a P2 v19 version of his logic analyzer code for the DE2-115 that helped me sort out a few issues I had along the way…
After getting this far, I decided to have an attempt at a proof-of-concept for the P1. I started out by making a small P1-based PCB with an HR chip mounted on a small castellated breakout PCB – see the attached photo. The pin labelled GND in the lower left of my HyperRAM breakout is actually a Vcc pin and some surgery was needed to fix this issue (hence the red wire - that appears to short Vcc and GND !).
On the P1 the main issue is that hub accesses can only be guaranteed every 16 clock cycles (or 200 ns) - and this is only after you’ve synchronized your memory transfers. This means that in between each successive rdbyte/wrbyte instruction you’ve got just 2 intermediate instructions to work with.
Given the self-refresh requirements of the HR chip (with data buffer transfers typically restricted to a maximum of 4 us, but which can be stretched out to 8 us) it seemed the buffer size on the P1 would inevitably be restricted to a modest 16 bytes. For that buffer size it turns out there’s a roughly 100% overhead to provide a memory address plus additional latency clocks.
Based on these thoughts, however, it did still seem that a target goal of slightly > 2 MB/s would be feasible on the P1 (that’s the buffer transfer rate though).
To cut a long story short, after drawing some initial inspiration from some neat OBEX code posted by Tracy Allen, I’ve succeeded in achieving a viable P1 HR interface solution using 3 COG’s.
I’ll post P1 and P2 versions of my code after I’ve added some liberal comments to aid understanding. It will be after the coming weekend before I can get back on to this again but I felt forum members would be interested to learn of progress made thus far.
I’m fairly confident that others may see ways for further improvement given that I’m no code guru. Comparing my own P2 vs. P1 programming experiences after getting to this point we’ll be truly empowered when we’ve got some real Si to play with – the P2 instruction set/functionality really does provide us with some awesome capabilities.
Thus far, I’ve been able to document an ~ 25-fold performance increase on the P2 version using some very compact code (smart pin/streamer +++ !!) and even that factor can very likely be improved upon. I’m sure there are numerous other applications out there that will really benefit from a P2…
Richard

1299 x 619 - 136K
1315 x 620 - 144K

1287 x 619 - 129K

1812 x 717 - 934K
Comments
I will make a new DE2-115 compile tomorrow for you, where I'll put some timing constraints on the I/O's to bring them into unison, as they will be on the actual silicon. That should solve your timing problem.
For HyperRAM, you do not actually want unison, as the data is meant to be centred on the clock. (ie ideally data changes well clear of the CLK edges)
That means it could be useful to either add a deliberate delay, or use a falling edge D-FF to offset the timing by SysCLK/2
If you touch the CLK, it will delay by another ns or two and that may be just enough. You could try adding a 1G17 or similar buffer to delay the CLK a little.
Great! Any scope shots ?
Did you try user-refresh, so you can go >> 4us ?
That's impressive.
Because the 4us is a royal pain, I've been running a pencil over self-refresh, with a view to a simple direct P1 <-> HyperRAM(s) -> LCD Display connection.
The LCD has an DE line, and needs parallel up to 24b, giving choices of 1,2 or 3 HyperRAMs connected.
With no DE, the data is ignored, so refresh or write can be done anytime DE is inactive. (more forgiving that VGA)
I think a P1 can read continually readily enough, and so that handles refresh the RAM of the displayed frame.
If you want to have another frame ready, that needs also Self Refresh, which is trickier, but I think from some replies Cypress gave, this may work on P1:
1 2 3 4 5 6 7 8 9 0 1 2 = 12 SysCLKs Refresh ? CS ___/==\_____________________________/==\____ tCSH > 10ns CLK ____________/====\_____/=====\_________________ From Timer, or SW Possible alternative ? Minimum CLK edges ? Data | | | | tRWR |-------------------------| >40ns |------|Tacc >40ns 'theoretical minimum cost is tRWR + tACC' {80ns}On P1 I think that's 12 lines of DJNZ code (with timer doing CLK) and so 600ns/row or 4.9152ms for a full 8192 row, tho P1 designs I'd expect to refresh less.
Addit: Strangely, Cypress forgot to allow disable of Auto-refresh, and it is unclear if a manual refresh resets that timeout, or it they can collide.
Some checking may be needed to see if collision effects do occur, or if being above 40+40+40ns is enough to tolerate that by time margin alone.
I used a logic analyser during the P2 work to check the relative timing of DQ7..0 and CLK. Yes jmg - the data should indeed be set up to be centered on the clock, not at the clock edges.
In my code I'm first launching the streamer to do the HubRAM <-> pin transfers, then configuring/starting the smart pin to generate the clock. By experimenting, I've found when doing that, some dummy bytes must be written/read to get the streamer and smart pin properly synchronized. Chip - it would be very useful to have some documentation/control over that relative timing - is that possible ?
I'm out of town for a few days but sure - will capture and post some waveforms. Also need to investigate the CLK timing on reads - good suggestion re the buffer for the P2 version. Thanks !
How far away are your PCBs? I have some breakout PCBs and HR chips that I haven't had much time to play with. I'm also playing with soldering BGAs and checking with thermal camera etc, HR makes a good BGA to start with because they're fairly cheap.
Would be nice if they could...
And that solution (having an option to choose between adding or not an offset of a single half-system-clock period to the Smart Pin NCO's output timing, by means of a single instance of an (Always@negedge clock)-clocked D-FF, just at the final stage of the logic that effectively drives the PIN I/O cell) is almost everything that is needed to help achieve the best centering of Hyper_CK right there, at Hyper_DQ[7:0] cat's eye center target.
Note that everything that occurs at the pin level could be assigned as an External Event within FPGA's (and Asic's too) timing analisys tools, whose timing does not effectively impacts the closure of the "inside" timing.
So, shifting the analisys from the "real" (@posedge clocked) pin to the someway "virtual" (@negedge clocked) one, does the same job of adding small ceramic capacitors directly at the pin output or long (and EMI prone) wires between clock outputs and their final destination on pcbs. But, they are at least predictable (Fclk period / 2)!!!!
The objective of the solution is to help improve the ability of management of the phase relationship between COG's Streamer (Always @ posedge clock)-NCO-driven data transfer, that effectively moves fifo's data to the (8, 16, 24 or 32 bit) data-bus alike pin group, during WRITE operations, whose destination are HyperBus enabled devices, or the like.
BUT, during HyperBus READ operations things need further syncing, due to the fact that both HyperRam (and HyperFlash too) RWDS and DQ[7:0] can be delayed by up to 7nS (8 nS for dual-dice stacked parts (128 Mb rams and ram/flash dual devices)) from the CK border that triggers them.
To help solve this last dilemma (to warrant that the first 8 bits of a WORD are captured only ((@posedge RWDS) AND (@posedge System clock)) and the next 8 at ((@negedge RWDS) AND (@posedge System clock))) perhaps needs a bit of thinking and experimenting, before a solid timing solution can be validated.
Thus, I believe that we could expect to reach some reliable 80 Mbyte/S or even higher data links, that will certainly get a lot of traction to any P2-enabled solution.
Henrique
I've got some PCB's being made at OSHPark that break out the HyperRAM chip to a 14 pin format that can be plugged into the Parallax add-on board for the DE2-115. Might be another week or so before they make it here to Oz. On that same panel is a reworked P1 design (similar to the photo I showed earlier) but which has the HR directly mounted on the PCB.
I've had no problems soldering the BGA package just by applying plenty of flux to the PCB. I'm using a cheap toaster oven
Really neat work!!!
If you need assistance I have an SMT oven and solderpaste but would need a stencil. Never done bga though so nothing to test with.
Currently in the U.K. Will not be back in Sydney for 2weeks.
That's great news.
I have spent some time at your website for the first time. It has a lot of amazing projects. I really like the sentence 'high performance and low cost'. I always wanted to do the spectrometer with linear CCD (in fact I have several Linear CCD arrays and various AD9826 ICs that are waiting for a breakboard). Never found time for them ... Ok, maybe I will ask you some questions another day, I don't want to derail this great topic so early ...
Now that it seems that you have already solved the issue about big and fast RAM for P2, I think that we have half the problem solved. The second part or the problem is how to do high speed transfer from P2 into a computer. Mostly I am talking about a PC here, but maybe there are a lot of people right now that would be thinking also in a Rasberry PI, Udoo x86, Odroid, LattePanda, x86duino, Up Board, Olinuxino ... name_your_favorite_SBC_here.
I have seen that you are using FT245 in several of your projects. I think that can handle 8MB/s. It seems that HR will deliver much faster rate than 8MB/s. Have you ever considered to use a FT232H as substitute for FT245?. The FT232H has a synchronous FIFO mode that can do around 40MB/s. The problem is that it will work by sourcing a 60 MHz Clock into the P2.
Do you think it would be possible to connect the P2 to both HR and FT232H?
Is there any other better IC (or any other way) to do it?
Of course, P2 can connect to either FT232H, or FT2232H (larger buffers, 2 channels)
Some of those speeds may have meant bits/s, not Bytes/s ?
Good question. There are many connection choices, and parallel FIFO is the fastest, but has a somewhat high pin-cost.
I get this table for possible USB Bridge candidates :
Comments:
Cheapest Bridge is a small MCU, EFM8UB1 (but this needs software installed, tho SiLabs have drivers+Code)
Cheapest std UART is CP2102N, good for 3~4MBd (4MBd with handshakes)
Fastest FS-USB Uart bridge is the XR21B1420, with fractional baud features and close to theoretical FS speed.
At HS-USB, things thin-out a little, and stalwarts FT232H/FT2232H have parallel FIFO modes for fastest, but many pins cost.
(all HS-USB solutions need a crystal or osc, but precise baud control is not a bad thing to have )
The C rev of FT4222 bumps QuadSPI to 6.725 Mbyte/s, so that starts to look interesting.
The NUC505 MCU is also a reasonable price, and highly flexible, and can do QuadSPI too.
I'm looking into FT4222H some more... this probably needs a separate thread..
Does give some time to play some more with HR.
I’ve just connected a logic analyzer to my DE2-115/HyperRAM interface with probes on CS, CLK, RWDS, DQ7, DQ5, DQ3 and DQ0.
To exercise these selected data lines I’ve filled the 128 byte buffer with the first 16 elements being the following sequence – 0,1,9,32,33,40,41,128,129,136,137,160,161,168,169,169
Due to an oversight I realized later that I overlooked including 8 in this sequence; (i.e. DQ3=1, all other DQ’s 0) in this test and somehow ended up with 2 x 169’s at the end !
HR_WR.jpg shows the start of a write cycle, CS goes low – there’s some activity on the first 3 clocks (ie 6 clock edges) to set up WR and an address, and then on the 9th clock rising edge (after some further fixed latency clocks - 5) the data starts – 0, then 1 on the falling edge, 9 on the 10th clock rising edge, 32 on the falling edge and so on.
HR_WR_Expansion shows this in a bit more detail – looking at the 4 selected data lines at the bottom of this image you can see the above data sequence playing out. Here, I’ve positioned cursors on the clock falling and rising edges to show where the data would be sampled and it’s evident that this is not exactly at the clock mid-point - but timing is still acceptable.
Based on the documentation we currently have to hand I could see no way to achieve any better control of the relative timing of the smart pin/streamer action and I’m hoping Chip can advise further on this point. Here, my P2 emulation is running at 120MHz (clkset #$FF) and the smart pin generating the clock is set up for 2 cycles high, total 4 cycles for a period of 33.3 nsec.
Next, I changed the buffer to now have 8 copies of the above data sequence (for a total of 128 bytes). Running the system repeatedly - writing this sequence then reading back (clearing the buffer before the read) I’m getting the LabVIEW trace shown in HyperRAM4.jpg – which looks fine.
HR_RD_Expansion.jpg shows a portion of the read cycle. As Henrique has insightfully pointed out in his earlier post, during a read cycle the data transitions occur on RWDS edges - which are delayed by 7 ns from the CLK edges – that’s clearly visible in this image. While DQ3 and DQ0 transition together, that seems not always to be the case for DQ5 and DQ7 and it appears there can be a couple of ns difference in their timing – but that could easily be just an artefact of not having a fast enough logic analyzer – I don’t know.
Once again I’ve positioned cursors on clock edges. The big question now is exactly when are the pins being sampled by the streamer ??? If its on the same edges as the CLK then the data should be OK – yet I do occasionally see some bad data bytes as mentioned before.
Currently my FPGA is connected by an ~ 10 cm length of ribbon cable to the HR breakout (P2_HR.jpg). Definitely not an ideal setup given the high speed transitions here – but I’ll be able to improve on this soon.
Yes, I think that is a sampling artifact, as sometimes they lineup and sometimes do not.
When you do get an error, how does that affect the group of bytes ?
What is the failure rate ?
eg Clock ringing you would expect to move/effect more than one byte, whilst byte sampling errors would be more isolated, but limited to bit-change boundaries.
You could (roughly) check sampling margins, by loading one data line with more C, here D3 seems to be not used during Address, so loading that is read-only delay.
To skew the other way, load the clock with more C, and roughly plot the error rate as you vary.
The problem seems to occur with byte data at, or near mid-range (~128). The error is that you'll typically then read back 3 repeated bytes - as you can see - with loss of data bytes from the end of the buffer. In the sqrt() function I posted earlier (HyperRAM3.jpg) the same thing happens but in this case it does so only once - again, in the middle of the trace. Initially I had thought that something odd was happening every 32nd byte but it actually seems to be data dependent.
Note that not all waveforms suffer from this problem - seems to happen as data is rising (not falling) through that mid-range value. But I've now realized this behaviour is absolutely repeatable - probe on CLK - absolutely no issues, off - just as I've described. Hope that might actually be a good thing in diagnosing the problem...
FYI my P2 pin assignments are
P7..0 to DQ7..0
P8 CS*
P9 CLK
P10 RWDS
P11 RES*
Appreciate the advice - I'm not an electrical engineer! Should I try a small cap to GND ( a few pF) on the CLK line ??
~128 (++) is when b01111111 changes to b10000000, so that has one of the highest ground bounce effects.
I'm impressed by how consistent that is on your plots.
If you are saying 3 bytes repeat, but 3 also miss off the end, that certainly suggests the clock bounced, to add 2 edges, which will load 3 the same, and the end ones have been pushed along.
A series resistor of 82 ~ 150 ohms can often help reduce clock bounce / false clock effects, with ribbon cable.
Probes and fingers reduce bounce, so that explains why that helps.
ie that plot is not an edge-alignment issue, but more to do with the ribbon cable.
You could try change of HR drive strength, to a higher R value, to make the data edges softer.
That would help on read-driven bounce, but have no change on write-driven bounce.
Further investigation is clearly required. The HR datasheet mentions the drive strength - which is currently set at the default value in register CR0 bits 14-12 - need to check the effect of that.
You can also try splitting the ribbon, and spreading as much as physically practical, with the CLK moved far from everything, and a GND wire between CLK and Data can help too.
How many GND wires do you have to HR board ?
I'd actually wondered about isolating the CLK signal from the ribbon cable but have not needed to do that. The drive strength doesn't at this stage appear to have any significant effect - I set that byte to $FF (its lowest value) and there was no difference in behaviour. There's only a single ground connection from the DE2-115 to the breakout board but the latter does have a ground plane.
Over the next few days I want to do some more exhaustive testing (very large numbers of read/write cycles) with sets of random numbers so I can check for buffer errors.
Once that's done i'll get some decent documentation done and post code
Thanks again for your help...
I'd suggest add some more GND wires, with maybe one or two GND between CLK and any other signal.
I'm not sure I'm seeing it in the above images, but does not hurt asking...
Are you modifying the contents of CR0[15:0] at the image sequence HR_WR.JPG?
I'm asking this because the waveform are clearly showing a larger than usual RWDS High level time, during the CA[47:00] write phase.
It should last a total of 3 clocks (3 up-going/down-going sequences) and I'm seeing almost 4 clocks!
Henrique
Fixed Latency
2 x 3 clock Latency Cnt
Apart from the timing mismatch (160 MHz x 120 MHz in your case), they appear to be the same, except for the duration of RWDS high level during CA[47:00] write phase, at the begining of the cycle.
In my youth, I've used to hand-draft timing charts; reticulated paper sheets, pencil and rubber, lots of rubbers in fact!
Now I'm older (and wiser, I presume???)
I've found a little gem brought to us by Dan Fabrizio; The Timing Analyzer you can find at
timing-diagrams.com/
Ive been using beta version B0.9896, and just now you've asked me about, I'm seeing another new beta, 0.9897 available for download.
Henrique
The rise and fall times presented are my own expectations due to my previous experiences (though I was used to do it under uS or even tens of nS rules, now I must account for each ten pS interval), so are the Time Of Flight delays too.
Great timing diagram !
Some clarification - In my code CR0 and CR1 are configured just once on program startup
Here are the 8 bytes (hex) I’m writing to each register :
CR0 : 60 00 01 00 00 00 AF E8
CR1 : 60 00 01 00 00 01 00 02
The E8 in the CR0 data stream configures HR for 3 clock latency and also requests a fixed 2x latency. Doing that seems desirable, simplifying the need to explicitly handle RWDS apart from a direction change before sending data. As far as the clock is concerned, all is as in your timing diagram.
In my file WR_HR.jpg, I’m not accessing CR0 – in the LA traces you’ll see that prior to the 1st clock rising edge DQ5 is set high - unfortunately I did not capture DQ6 here - which would have made this clearer as it would have been low ie my first data byte sent is $20 and not $60 which would indeed have been a register access.
On the question of the long duration of my RWDS I find the datasheet unclear regarding exactly when one should make RWDS an output. In HR_WR, after setting up the streamer and smart pin, then pulling CS low (with RWDS initially configured as an input pin), I’ve got the following lines in my code to change RWDS direction and pull it low (to ensure there’s no data masking) :
waitx #n
drvl #HR_RWDS
In WR_HR.jpg my delay cycles constant n was rather large and I’ve reduced it – now RWDS is high exactly as shown in your timing diagram. In the case of a RD_HR there is no need to change the direction of that pin, of course; it’s an input. Good to have that sorted out thanks to your input.
In a couple of minutes i'll post code (now with some documentation) and a short video clip as well
I've also just made a short video I recorded using VLC Media Player. This shows my LabVIEW front end communicating with the P2 emulation running this code. The graph window on the left is a waveform computed in LV that is sent down to the P2, loaded into HyperRAM and then read back and displayed in the graph window on the right.
At about the 12 second mark I'm clicking through a number of different waveforms so you can see the results, You'll notice the block # auto-incrementing during the run.
However its a .MP4 file - but that file type is not being accepted by the Forum file uploader - can someone advise me how to upload it ??
I'll post my effort on a P1 HyperRAM test in a week or so in that area of the forum. It still needs extensive documentation. Would be sooner - but a kitchen renovation here is making this slow-going !