

Question about speed of code generated with PropellerIDE
 tomcrawford
Posts: 1,129
tomcrawford
Posts: 1,129
I have been fiddling with MAX7219 recently. I found I could not write a string of 8x8 modules quickly enough in spin and had to go to PASM to get decent looking text scrolling. In large part it comes down to how long it takes to do a 16-bit SPI. In PASM, it is less than 10 uSec, in spin, it is about 600 uSec. Fair enough.
Then I thought, how about C? It is a lot faster than spin. But the results make it clear I am doing something wrong. Here is the nub of what I did:
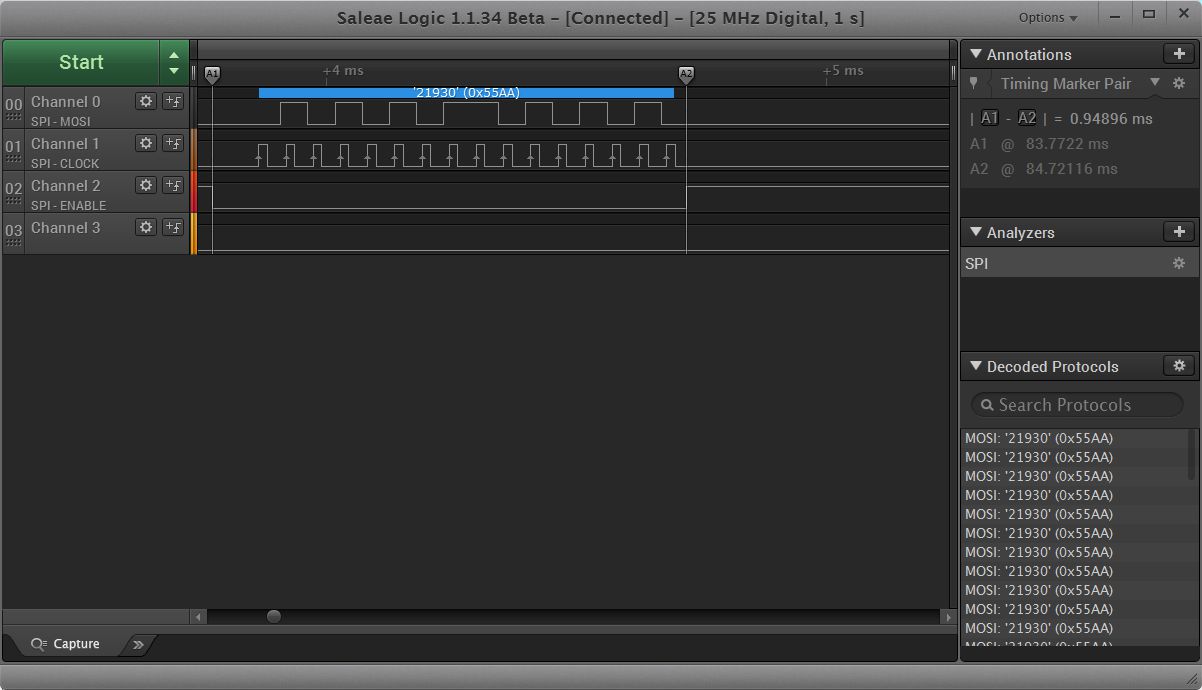
shiftout.jpg is a logic analyzer capture. It can be seen it takes nearly a mSec from CS active to CS inactive. Shiftout.zip is the actual program. Clearly I am missing something. That is not the sort of speed one would expect from compiled code.
I thought perhaps the shift_out function is artificially slowed down to avoid overrunning slow peripherals, so I wrote my own little shifter.
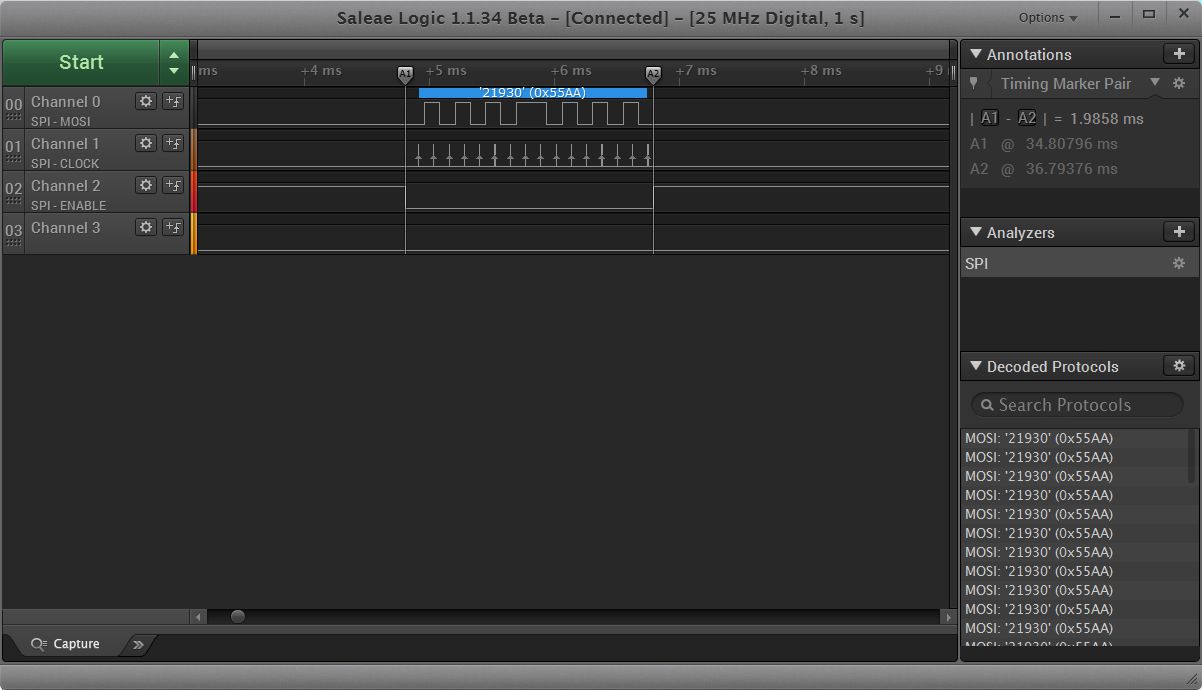
function.jpg is a capture, functionshift.zip is the actual program. It is even worse, almost 2 mSec to do a 16-bit SPI.
So I am hoping some kind soul can set me straight. What am I doing wrong?
Then I thought, how about C? It is a lot faster than spin. But the results make it clear I am doing something wrong. Here is the nub of what I did:
while(1)
{
low(MX7219CS);
shift_out(MX7219D, MX7219Clk, MSBFIRST, 16, 0x55aa);
high(MX7219CS);
}
shiftout.jpg is a logic analyzer capture. It can be seen it takes nearly a mSec from CS active to CS inactive. Shiftout.zip is the actual program. Clearly I am missing something. That is not the sort of speed one would expect from compiled code.
I thought perhaps the shift_out function is artificially slowed down to avoid overrunning slow peripherals, so I wrote my own little shifter.
void MyShift16(int ShiftVal) {
for (int i = 0; 1 < 16; i++) {
if ((ShiftVal & 0x8000) == 0)
low(MX7219D);
else
high(MX7219D);
ShiftVal = ShiftVal << 1;
pulse_out(MX7219Clk, 1);
}
}
function.jpg is a capture, functionshift.zip is the actual program. It is even worse, almost 2 mSec to do a 16-bit SPI.
So I am hoping some kind soul can set me straight. What am I doing wrong?

Comments
Edit: I found Project View. Thank you for the hint. EndEdit
tom
Re-edit: Okay, that helps LMM gets it down to less than 200 uSec (0.2 mSec). Thanks again. tc
I had an application where I needed to collect SPI data very quickly. The device (pixy cmucam5 color tracker) spit out 14 byte data blocks at 1usec/bit without any ability to pause it, and I needed to collect as many blocks of data as possible before it started a new frame of blocks (every 0.020 sec).
I had tried using the PropTool objects SPI.spin and SPI_ASM.spin, but they were too slow. I then tried the SimpleLibrary SPI functions (shift_in) in CMM memory model, but that was very slow. I couldn't use LMM because of the size of the project's code.
So I embarked on learning how to embed PASM code from a Spin object into a C program, and wrote (with a lot of help) an SPI library that used the PASM code from SPI_ASM.spin.
The adventures are here
forums.parallax.com/discussion/157441/can-spi-in-simple-libraries-be-speeded-up/p1
with the library in the next to last post.
An example of using the generic library with a device is here:
forums.parallax.com/discussion/163486/altimeter-module-ms5607-29124-c-driver-using-spi
The clock speed used in that example is 0.5usec.
Hope this helps.
Tom
The other thing I see that allows Tachyon to run faster is that I normally setup the pin masks in a separate operation, and usually just once so it is then just a matter of writing (or reading) data. One extra is that it is assumed that any SPI operation should assert the chip enable plus there is one instruction to release CE quickly.
Surely then something similar could be done with Spin and C methods?
btw, an 8-bit SPI read/write takes around 2us.
I, too, was surprised at the SPI implementation that comes shipped with SimpleIDE in the Learn folder. If you'd like to give PropWare a try, the SPI module will run at 4 MHz in both LMM and CMM modes if you invoke the shift_out_block_fast_msb_first() method. The other, simpler methods like shift_out() use waitcnt to clock a user-configurable frequency and are therefore limited to ~900 kHz.
This SPI demo assumes that a slave device is connected to the Propeller and configured to echo back each byte as it is sent.
You can also reference the code in the various SPI peripherals like the PropWare::MCP3xxx for more example code.
And if you're on Windows using SimpleIDE, I recommend installing PropWare via the first set of instructions here. If you're on Linux, the dedicated Linux packages combined with command line tools or your favorite IDE (VSCode, CLion, Eclipse, etc) are much easier IMO.
Cheers,
spincvt is part of a family of programs:
spin2cpp -- the original command line tool to convert Spin to C++, C, or PASM. Can also output binaries.
spincvt -- a GUI front end for spin2cpp
fastspin -- a different command line front end for spin2cpp that has the same argument format as openspin