

USB/uSD/Hyperram/Flash/Camera test board for P123
 Rayman
Posts: 16,460
Rayman
Posts: 16,460
Been testing this board today. USB and uSD are working with April version of P2V.
I'll update tomorrow and see if they still work.
Then, I'll post my test code.
Assuming it still works, it seems I'll have some extra boards.
If you want one for free, private message me your address.
I can also put SMT parts down with my stencil.
In that case, PM me to reserve a board and then mail me the parts.
I have about 18 extra boards.
Here are Digikey part numbers for SMT parts:
mini USB receptacle: 151-1206-1-ND
Micro SD card socket: HR1941CT-ND
706-1466-ND: HyperRam
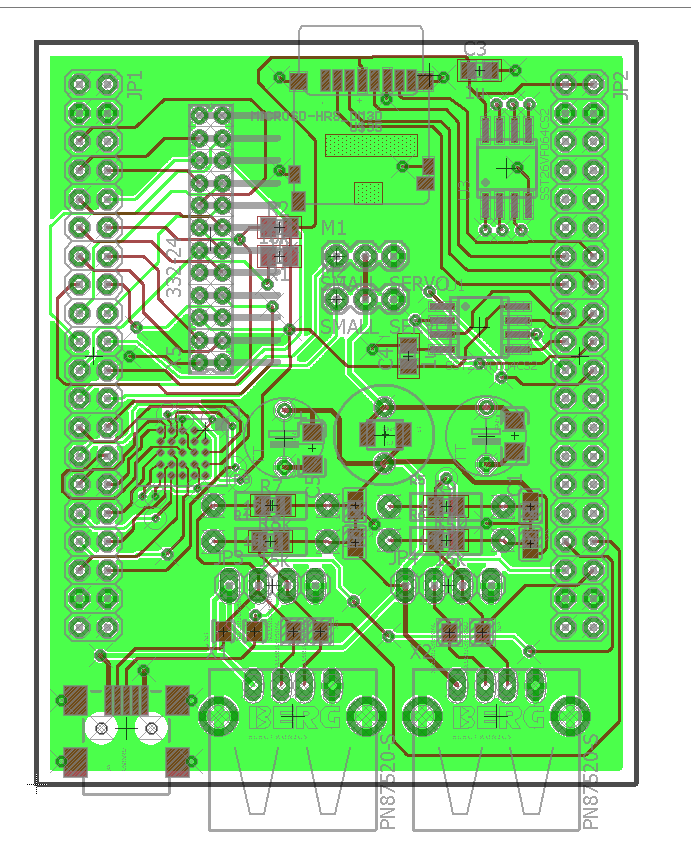
Schematic and layout attached. Also, I've attached FSRW reading code for uSD socket and USB sniffing code.
Note: USB Sniffing is set for using the mini-A and fullsize A next to it. You need to close the SMT solder jumpers to allow data lines from mini-A to connect to fullsize A to do this...
I'll update tomorrow and see if they still work.
Then, I'll post my test code.
Assuming it still works, it seems I'll have some extra boards.
If you want one for free, private message me your address.
I can also put SMT parts down with my stencil.
In that case, PM me to reserve a board and then mail me the parts.
I have about 18 extra boards.
Here are Digikey part numbers for SMT parts:
mini USB receptacle: 151-1206-1-ND
Micro SD card socket: HR1941CT-ND
706-1466-ND: HyperRam
Schematic and layout attached. Also, I've attached FSRW reading code for uSD socket and USB sniffing code.
Note: USB Sniffing is set for using the mini-A and fullsize A next to it. You need to close the SMT solder jumpers to allow data lines from mini-A to connect to fullsize A to do this...
pdf
48K
691 x 845 - 101K
Comments
I've been searching around for it, including at the USB Testing thread, but did not find the last schematic of your pcb, the one that includes the HyperRam at the board.
In fact I'm specifically looking for the existence of at least one (weak?) pull-up resistor, connecting VCCQ to CE#, in order to ensure a proper logic level at CE# intput, during power-up sequencing. Both Cypress and Issi mention it on their datasheets.
Sure, the corresponding driver pin at the processor should be tri-stated during power-up, or actively driven high, by pin's circuit. In the last case, there is no need to mount a pull-up at all.
It's also advisable to have a second pull-up, connecting VCCQ to RESET#, for the same reason that CE# needs one.
Although Issi datasheeet mentions the existence of a weak pull-up at its RESET# input, Cypress didn't say a word about it, so, just in case....
Hope it helps avoiding any surprises during pcb's testing.
Henrique
This code reads ID register #0 and outputs result over serial.
I'm getting $0C81. Bitfields say that is 13 rows and 9 columns, which is what it supposed to be for 64 MB device (see bottom of p.8 datasheet)
Had to give a lot more latency clocks that I thought before data came out...
Reading configuration register #0 gives $8F1F, looks right.
Fixed latency (roughly doubles the number of clocks between CA and data phases) is the "default" condition after Power On Reset and also after the RESET# pin was cycled(low then high).
On Issi IS66WVH8M8ALL/BLL datasheet, this condition can be checked under par. 13.2.0.4 Fixed Latency.
It someway "eases" master interface (programm) design, by providing a "deterministic" timing, between the end of the Command/Address phase and the beggining of the data transfer phase, though it consumes some clock cycles, thus making transactions a bit longer.
Henrique
Any opinions of the device so far? Does it appear with your limited experience with it that it will pay off in terms of speeds or writes and reads vs Quad SPI?
Big difference is that can have 160 MByte/sec transfer speed
where dual SQI RAM is only 20 MByte/sec
I've I'm reading the datasheet right, we can dial down latency from 6 clocks to 3 clocks, since clock speed is probably going to be limited to 80 MHz with 160 MHz P2.
Then, I guess using a fixed 2X latency makes things easier.
Otherwise, you have to process the RWDS signal.
Maybe I'm wrong, but using fixed latency means you can ignore RWDS.
At the very beginning they suggest a word is 8-bits.
But, for memory addresses, a word looks like 16-bits.
Anyway, if I see it right, the addresses are for 16-bit data.
So, you can't write individual bytes, have to write whole 16-bit words.
This could work well for 16 or 32 bit graphics, maybe.
I'm trying to remember how Chip described using the streamer for the HyperRam.
Seems like some tight choreography between cog and smartpin required...
1st - Yes, you can program CR0[7:4] = "1110", in order to select the lowest possible latency clock count = 3, corresponding to a maximum clock rate of 83MHz, totaly compatible with actual P2 maximum of 80MHz.
2nd - Of course, you can almost ignore RWDS during read from memory operations, because, in fact, after the Command/Address phase of the interface, where it is used to flag the need of accounting for one more latency count, its steady states (High and Low levesl) are only identifiers that data pins are ready to be sampled, and, by Issi datasheet, they'll occur tCKDS (1 to 7 nS) (Issi only, Cypress Advance Information mutes about it) after the clock edge that "triggers" the accompanied byte data transfer to the pins, whose valid timing is dictated by tCKD (Issi).
Since, at 80MHz clock rate (160MHz data rate), the next transition of the CK pin, will occur ~6.25 nS after the one that triggered the transfer of the former data, then there can be an uncertainity of ~0.75 nS (7 nS(maximum) - 6.25 nS) plus any delays between HyperRam data pin and the input of the latch that holds the value that will be finally written into P2 memory, by the 160 MHz internal clock.
As per Issi datasheet, theese tCKDS, tCKD values are intended to be used under a 3Vcc = Vcc pin = VccQ pins condition. Things get better when 1.8 Vcc = Vcc pin (tCKD = tCKDS = 1 to 5.5 nS), then they'll probably get worse at 3.3 Vcc = Vcc pin = VccQ pins.
If you experiment any problems, during HiSpeed data transfers, perhaps it's wise to select a 2.85V LDO regulator, suitable to operate in the ~200 mA max. current range (e.g, TI TPS799) and use it to feed HyperRam Vcc and VccQ pins.
3rd - Perhaps its wise to track the first occurence of RWDS going high, after the end of the CA phase, before starting any Hi-speed (160 MB/S) data transfer, to be totaly sure of being in sync with the data stream.
Also, starting from the first byte, you can track both RWDS falling down and raising up transitions by means of two counters, whose sum, at the end of the data stream, will show precisely how many bytes were captured during the just terminated data stream operation.
Henrique
Two of these for down under, please.
Do you want me to order the parts from Digikey/Mouser for delivery to you, or just send you funds via Paypal so you can tack onto a future order? Either is fine
Thanks for doing this
I think this needs care...
because of :
My reading is with less latency, you add the lottery of refresh, but the higher value covers all cases.
By the time you read & check RWDS, you have probably added more cycles anyway, unless pure HW did that.
Refresh is the next question. If you read/write slowly, say 1 word/ms and roll 8192 values, that's ~8 seconds to loop.
If you always read the previous written value, (& with warm device?) with CS mostly high, & CLK stopped, that suggests a background, hidden clock, refresh is occurring, which would make this part easier to use.
If that fails, try CLK active during CS=H, and if that fails, it may need more CS=L time. ie bump the speed to sub 1us and re-check. That sub-8ms scan time, should meet refresh specs from read-repeat alone.
I'm not following the reasoning here ?
The 1.8V parts are faster, but not because of lower Vcc.
CMOS always gets slower as Vcc falls, so the 1.8V Part is a special process/design/setting change to make use of less bounce at lower dV, and to use the differential clock to better tolerate bounce too.
To push these parts at the high end of clocking, ideally the RWDS signal should be used, as that has significantly tighter timing.
Otherwise, there is not just the HyperRAM timing budget to consider, but also skews between PIN and sampling in the P2 itself.
However, first get them working at modest speeds, so a known reference point is available to push up clock speeds.
With FPGAs limited to 80MHz, and probably lower skews than P2 silicon, some of this testing is going to be tricky ?
Or, could be maybe adapted other generic Omnivision camera module boards
Hi Rayman
As per Issi datasheet, Rev.00C 05/01/2015, Par. 8.3.4 Write Transaction Diagrams.
Memory array and configuration register read operations are always word (16 bits) adressed and aligned and also generates a word of data to be transfered to HyperBus master (e.g. P2).
Configuration register write operations also follow the principles of word (16 bit) alignement and data lenght. (Figure 8.9)
But when it comes to memory array data write operations, things are someway different.
As per Figures 8.7 and 8.8, sure you can do individual byte writes, since, after the total latency count (1x or 2x), RWDS can be used by the HyperBus master to select wich byte(s) within a 16 bit word will be written to the internal memory array, or not.
Whenever RWDS is actively driven High by the HyperBus master, the currently affected byte within the actual word will not be modified. In fact, one could place any value at DQ[7:0] including totaly tri-state the bus, and the contents of the selected byte into the memory array will not be modified.
Otherwise, if RWDS is actively driven Low by the HyperBus Master, the currently affected byte within the actual word will be modified, and receive the value driven by the master at DQ[7:0].
Sure, actively controling RWDS to select each byte that will be modified or not, is far from an easy task, at least during fast pace transactions, where RWDS will be required to change at the same rate of CK pin and in sync with data values driven at DQ[7:0].
During slow pace ops (e.g. programatically controling each interface pin, by a program loop) this task is very easy to accomplish.
Henrique
But, you can use RWDS to select which bytes are actually written when writing a group of 16 bytes.
This isn't so great for code execution from SDRAM.
But, maybe fine for screen buffer.
I you want to set just one pixel though, need to figure out how to use RWDS.
More would be better to reduce average overhead.
It's not quite clear in the datasheet and seems to depend on temperature.
At 80 MHz clock from 160 MHz P2, it looks like 160 bytes is safe at any temperature.
But, I might have to take a closer look...
Certainly worth testing.
I think you can read any number of consecutive bytes, provided you are ok with the caveat of the 64ms refresh and anything not read in that time, is not read-refreshed. ie that may give a simpler mode, for some video apps.
Exactly what happens on a boundary is unclear. The flash data suggests RWDS could pause at that time, SRAM seems to not mention anything ?
At least, I think that is what this means:
"The host system is required to respect the tCMS value"...
Yes, I think that applies if you want the refresh to correctly maintain all memory.
ie if doing full memory RAM R/W, then certainly follow that.
There are other areas that say the user can exceed that, but then the user is in charge of refresh.
The simplest form of that, is to just raster read inside 64ms (which I guess could manage 2 LCD screens, or 1 VGA screen), and accept to not use the rest of the memory.
I'm also curious if that tCMS needs many accesses, or if the chip still refreshes OK with no Clock ?
Because these are also Max Temp specs, actually testing this is going to be tricky, as some cases may appear to work on the bench, but actually be outside PVT spec.
Finding the actual typical room temp refresh hold time will be useful, as it gives a practical test point.
The following comments and numeric references are based on Issi IS66-67WVH8M8ALL-BLL datasheet, Rev.00C 05/01/2015.
There's not necessarily a minimum transaction lenght, since you can finnish it whenever you want, provided you control its end by transitioning CE# from Low to High, when CK is level steady (Low or High).
Remember: interface operations don't require that CK pin (clock signal) to be free running. Nor even switching at any particular frequency (provided the maximum clock rate for the part isn't exceeded and also tCMS is respected, to avoid data loss due to the lack of refresh to some/many/all rows), unless you intend to continue any data transaction within Command/Address register space or data memory array space.
The 16 word (16 x 16 bit) data transactions are the minimum programmable between the eight selectable possibilities of "Wrapped Burst Type" lenghts, that are expressed thru CR[2:0], after setting CA[45] = 0.
If you program CA[45] = 1, then "Linear Burst Type" operations are selected, and you can also select their start addresses (Table 5.5; Sheets 1 and 2).
Note that, when you program CA[45] = 1 (Linear Burst Type Select), CR0[2:0] (Wrapped Burst Type Lenght Select) bits became meaningless.
From Issi datasheet, page 3:
"Read and write transactions are burst oriented, transferring the next sequential word during each clock cycle. Each individual read or write transaction can use either a wrapped or linear burst sequence. During wrapped transactions, accesses start at a selected location and continue to the end of a configured word group aligned boundary, then wrap to the beginning location in the group, then continue back to the starting location. Wrapped bursts are generally used for critical word first instruction or data cache line fill read accesses. During linear transactions, accesses start at a selected location and continue in a sequential manner until the transaction is terminated when CS# returns High. Linear transactions are generally used for large contiguous data transfers such as graphic image moves. Since each transaction command selects the type of burst sequence for that access, wrapped and linear burst transactions can be dynamically intermixed as needed."
My following conclusions are based on Linear Burst Type operations, things can be different if Wrapped Burst Type operations are selected, but only in the way HyperRam memory internal 8192 bit row buffer operation automatically transfer its contents from/to the memory array, since during any read or write operation, data into the memory array travels twice, from the internal array to the row (8192 bit) buffer, and when the word counter overlaps, the whole row buffer is written back to the memory array, so a refresh operation is indeed occuring during read operations too.
But, during writes, after the initial loading of the internal row buffer, each write from DQ[7:0] to the selected byte will modify the targeted byte at the selected word at the buffer, commanded by the composite states of RWDS and CK.
Then, finally, when the internal word counter overlaps, or the operation ends by raising CE# high, whichever goes first, a global 8192 bit write from the row buffer to the array will occur
-If one intends to modify a single bit inside a byte of the memory array, and assuming he/she don't yet have a copy of the byte (where the intended bit to be modified resides), first a read command (preferably a Linear Burst Type one) should be issued, directly targeting the word where the byte resides (selectable thru CA[44:0] bits, despite the fact that CA[44:35] and CA[15:3] are currently reserved for future expansions and has to be programmed to "0" for compatibility reasons), and grab its contents (full word read will occur, despite the fact that the targeted byte can reside at "Dn A" portion of the word, or at "DN B" portion, but "Dn A" will came first, thus you can ignore its contents, during read, if the target resides at "Dn B").
When the intended byte value is forwarded to the program that is running at the HyperBus master (e.g P2), CE# can be negated (CE# goes high), ending the Read Operation that is "in course".
After the contents are modified to reflect the new intended one, then a new (preferably) Linear Burst Write should be initiated (CA phase, then Latency (1x or 2x) Count then Data Write phase), targeting the word where the byte resides.
If the targeted byte is at "Dn A", then RWDS must be driven Low, in sync with the transfer of the byte new contents to DQ[7:0], and CK must switch from Low to High, to effectively transfer DQ[7:0] contents to the internal row buffer.
If the targeted byte is at "Dn B", then RWDS must be firstly driven High (masked write transfer option), and CK must switch from Low to High, to logicaly complete the "fake" transfer of the "Dn A" byte portion of the currently addressed word.
Then RWDS must be driven Low, in sync with the transfer of the byte new contents to DQ[7:0], and CK must switch from High to Low, to logicaly complete the transfer of the "Dn B" byte portion of the currently addressed word.
The new word contents ("Dn A" portion and "Dn B" portion, togheter) will be finally transfered from the row buffer to the internal memory array, as soon as one of the following conditions occur:
1 - transaction is suddenly ended, by raising CE# high while CK is level steady (High after "Dn A" write, Low after "Dn B" write);
2 - the Word Address Counter overflows, indicating the next access will target the next row, if any.
3 - the above "if any" expression means that, trying a read or write access, beyond memory array addressable limits has "undefined results". Whichever "undefined results" does means, under the scope of a HyperRam device.
The following conclusion is mine. It was logically constructed during my readings.
In order to sustain data throughput without interspersed delays, there should be a second row buffer, that will receive data from the next addressable row inside the memory array (limited in validity but not precluded from occuring to the "if any" above), just a few "word" times (if not at the very last one) before the currently "being operated" row exhausts its contents, irrespective to the type of operation being performed, read or write (writes always internally begin with a read transfer from the data array into the row buffer, to provide stable contents for the bytes that will not be overwritten (Mask => RWDS = High ) during the whole row operation.
My assumption is that only the rows that are explicitly addressed and have at least one of its bytes (words) "legally" accessed, will participate into the "write back" mechanism, that occurs when the former row buffer (exposed one), that was being operated is substituted by the new one, that was waiting in the background.
This also suggests that extending any access past the end of a row, without realy intending to access the next one (e.g., unnecessarily switching CK after the last word of a row read or write operation completes), can also "trigger" the "write back" mechanism into the next row, when CE# goes high.
Then I suggest ending any write operations just after the last "mandatory" CK transition (the one that effectively writes the last intended DQn[7:0] contents into the row buffer), raising CE# to a High level when CK is steady, if you don't intend to extend your access to the next word within the same row or the first word of the next row, "if any".
The same applies to read operations, just after grabbing the last intended DQ[7:0] contents, irrespective of being it the first or second byte that composes the last word to be accessed.
The "just operated row write back" mechanism is responsible for the "hidden and automatic" refresh that occurs when any ongoing set of word access within a row ends, either by automatically wrapping the word counter to the beggining of the next row, or by CE# going High, forcefully ending the current operation (not to be confused with the also automatic self-refresh, that can occur between the CA phase and the memory array data transfer phase of the interface, nor with the self-refresh operations that occur when CE# is High, whose occurence is totaly independent of any (CK) clock transition at all).
Sure, one could use the "someway unintentional invasion" into the next row space, to gain an "almost free", "last clock tick", hidden-refresh of its contents into the memory array, because you can totally ignore the next (word)/(byte) contents that will be driven at DQ[7:0] during a read operation, or forcefully mask any unintended write operation (thru the use of RWDS = High) during the access cycle(s) of the first (word)/(byte) from the next row.
Both read and write operations will be ended by CE# going high, when CK is steady state (either Low or High), forcing the "currently exposed" row buffer to be written back to the data memory array, thus actually "refreshing" its contents.
This proposed behavior isn't precluded by the considerations expressed in (2) and (3) above, sure, provided one doesn't try to extend its access past the last available row address into device's map.
Sorry for this long post, but, due to my difficulties in writing in English, i've been elaborating so many bits on it, all day long.
Henrique
Did you do any tests on this, and push it until it lost refresh ?
Do you have waveforms for the HyperRAM access ?
I did find useful waveforms here
https://warmcat.com/embedded/hardware/lattice/hyperbus/hyperram/2016/09/19/hyperbus-implementation-tips-on-ice5.html
This seems to show the chip expects a gated clock, idle LO, and can pause the clock anytime.
So I was wondering if the streamer hardware allowed a Clk/2 output, and a Source & Count form, if a simple chain of two streamer commands, could then get decent speeds ?
eg
WriteStreamer(AddressArray,#AdrPulses)
then, either Rd or Wr
WriteStreamer(DataWrArray,#DatPulses)
or
ReadStreamer(DataRdArray,#DatPulses)
& the bus turns around between these commands, if required.
It seems RWDS is defined from CS =\_, so this could become
if RWDS then
WriteStreamer(AddressArray,#SlowerPulses)
else
WriteStreamer(AddressArray,#FasterPulses)
I think the P2 streamer can manage a Buffer pointer and count fine, so that leaves the details of CLK
~~~~~~~~~~~~~~~~~ Shifter to HyperRAM in short bursts ~~~~~~~~~~~~~~~~~ Shift CLK __/==\__/==\__/==\__/==\__/==\__/==\__/==\__/==\_ Data ___/==0==\__1__/==2==\__3__/==4==\__5__/==6==\__7__ HR_CLK _______/=====\_____/=====\_____/=====\_____/=====\_____ HR_CLKn =======\_____/=====\_____/=====\_____/=====\_____/===== ie Data-Out Pins change on Shift CLK _/= and CLK,CLKn pins change on Shift CLK =\_ That leaves pin-direction change, and some clock edge details : Shift CLK __/==\__/==\__/==\__/==\__/==\__/==\__/==\__/==\________ _/= WR Dirn xxxxxx\_________________________________________________ L=Write Data ___/==0==\__1__/==2==\__3__/==4==\__5__/==6==\__7__ Out ^ ^ ^ ^ ^ ^ ^ ^ Updates OUT HR_CLK _______/=====\_____/=====\_____/=====\_____/=====\_____ HR_CLKn =======\_____/=====\_____/=====\_____/=====\_____/===== Shift CLK __/==\__/==\__/==\__/==\__/==\__/==\__/==\__/==\_________ =\_ Rd Dirn xxxxxx/=============================================== H=Read Data ___/==0==\__1__/==2==\__3__/==4==\__5__/==6==\__7__ In ^ ^ ^ ^ ^ ^ ^ ^ Samples In HR_CLK ____/=====\_____/=====\_____/=====\_____/=====\_____ Clk phase changes HR_CLKn ====\_____/=====\_____/=====\_____/=====\_____/===== ie the Dirn needs to apply on the leading shift clock, and Pin-Read sampling is done on the falling edge.Question is, can the Streamer manage 100% of this now, or something only close to 100% ?Standard SPI config, allows a choice of which edge samples Data In, so hopefully that is there already.
Balanced CLK out I think is supported ?
What about CLK out toggles on Shift-CLK ? ( as needed by DDR )
Maybe just the direction change detail needs to be checked ?
Just let me know.
I doubt I'll be able to get to this anytime soon...