

The case for Additional/Extended COG RAM (+2/4/6/8KB)
 Cluso99
Posts: 18,071
Cluso99
Posts: 18,071
Exactly what is additional COG RAM ?
1. It is an additional 2/4/6/8KB block of full cog speed, single port RAM (~200MHz).
2. It has no latency, fully deterministic, and no jitter.
3. It is private to the cog, so it cannot be trampled by another errant cog.
4. Provides additional cog program/data/stack space. If used as data, it will be accessed like hub data (ie standard register instructions eg MOV do not work as this data is NOT registers).
5. Can be used as a stack using software. If sufficiently large, may be useful by GCC instead of using slower hub based stack, or as the primary stack with software managing overflow to hub.
6. Could be used as a stack with additional instructions (CALL/RET/PUSH/POP).
7. Extremely useful for slightly larger drivers that previously could not fit into cog ram, or required data space such as screen text buffer (80*25=2KB), font table (256*8*Bytes=0.5KB), lookup tables such as CRC tables, etc.
8. Larger program space inside the cog permits more complex drivers without resorting to LMM or hubexec in hub.
9. It is the memory (ram/flash/eeprom) that traditional RISC micros have for program and/or data memory.
What cannot this additional COG RAM be used for ?
10. It cannot be used as additional register space (only 9 bits available in instructions).
11. It cannot be shared with other cogs.
12. When used as data, it can only be accessed by rdlong/wrlong instructions or optionally a new MOV (or LOAD/STORE) instruction(s). Needs discussion for best method.
13. Only usable as longs (not byte or word).
14. It cannot be used for self-modifying instructions that reside in additional cog ram.
Why is additional COG RAM useful ?
15. Simple to use
16. Provides additional program/data/stack space at full cog speed (no latency, fully deterministic, no jitter)
17. Helps solve a typical complaint of many P1 users (lack of cog space)
18. Easier for larger cog programs (shortcoming of P1)
19. Useful for PASM, SPIN, GCC, etc.
20. SPIN on P1 was >25% slower than it needed to be because of the lack of cog space (and ROM space).
21. Can be used as data space for text screen buffers, font tables, lookup tables, etc
22. Can be used as a cog ram stack (by software and/or with additional support instructions)
23. GCC can make use of the extra cog ram
23.1. Stack space instead of hub (much faster)
23.2. More fast cog resident routines, etc
23.3. C drivers will be easier to implement (more resident cog space)
24. Removes strain on fixed registers $1F0-1FF (less additional support instructions because we can use say $1E0-1FF)
25. Cannot be trashed by errant cog trampling over shared hub
26. Improved flat memory model
27. Single port RAM (could be 2 / 4 / 6 / 8KB or more, depending on die space)
28. Uses less power than accessing hub memory
29. Makes the P2 feel more like a traditional micro. P2 is multi-cored, but also has additional large shared memory (hub) for those larger programs and/or data requirements (easier model to understand)
30. Not an afterthought/kludge like LMM or hubexec (its a normal native mode of RISC micros)
31. Should save implementing the otherwise useful CALL/RET with internal 4 deep (but bigger requested) LIFO stack.
32. Should permit a simpler hubexec implementation for hub (hub stack instructions may/should not be required).
33. Hubexec will use the new JMP/CALL/RET relative/absolute instructions, and DJZ/DJNZ/etc relative instructions.
What additional hw support is required ?
34. Obviously the RAM (standard single port OnSemi RAM)
35. Relative and/or Absolute JMP/CALL/RET instruction(s) (same as required for hubexec)
36. DJZ/DJNZ/etc should have Relative mode or be Relative mode as standard (same as required for hubexec)
What additional hw support would be nice ?
37. Support instructions to use this as a stack. JMP/CALL/RET/PUSH/POP instructions and Stack Pointer Register in main register bank.
Questions:
38. Could it be used for CLUT / WAVETABLE ?
39. Is there a requirement for RDLONG/WRLONG to be different (ie MOV/LOAD/STORE instructions) to access this new cog ram?
Notes:
40. The reason hub ram is remapped over cog ram (where part of hub ROM becomes invisible) is to keep the hub addressing the same. This saves hw from needing to perform a calculation on all hub addresses.
41. There should be no differences in GCC to compile to this new cog ram vs compiling to hub ram.
42. This method may make hubexec simpler to implement because instruction caching may not be required (somewhat slower performance).
43. GCC performance should benefit significantly by placing the stack in the new cog ram.
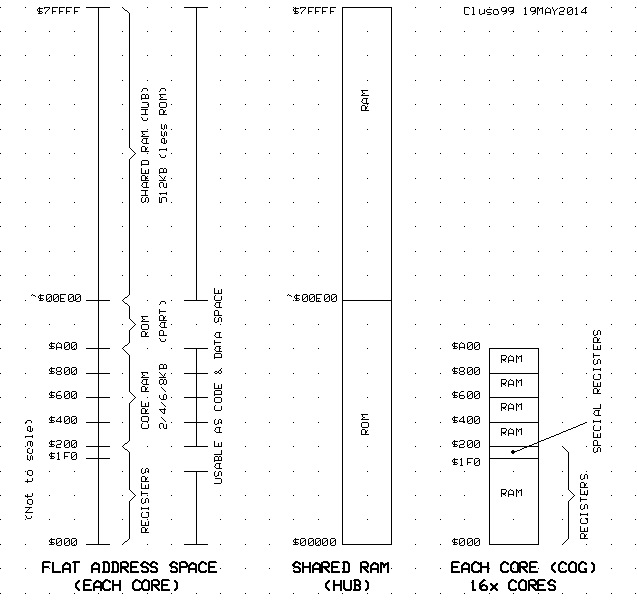
For background info, see this thread
http://forums.parallax.com/showthread.php/155687-A-solution-to-increasing-cog-ram-works-with-any-hub-slot-method
and the poll thread (currently 5 for +8KB cogs, 4 for +24KB cogs, 21 against). Note this thread does not fully represent what is proposed here though.
http://forums.parallax.com/showthread.php/155703-POLL-How-much-hub-ram-and-how-much-cog-ram-would-you-prefer
1. It is an additional 2/4/6/8KB block of full cog speed, single port RAM (~200MHz).
2. It has no latency, fully deterministic, and no jitter.
3. It is private to the cog, so it cannot be trampled by another errant cog.
4. Provides additional cog program/data/stack space. If used as data, it will be accessed like hub data (ie standard register instructions eg MOV do not work as this data is NOT registers).
5. Can be used as a stack using software. If sufficiently large, may be useful by GCC instead of using slower hub based stack, or as the primary stack with software managing overflow to hub.
6. Could be used as a stack with additional instructions (CALL/RET/PUSH/POP).
7. Extremely useful for slightly larger drivers that previously could not fit into cog ram, or required data space such as screen text buffer (80*25=2KB), font table (256*8*Bytes=0.5KB), lookup tables such as CRC tables, etc.
8. Larger program space inside the cog permits more complex drivers without resorting to LMM or hubexec in hub.
9. It is the memory (ram/flash/eeprom) that traditional RISC micros have for program and/or data memory.
What cannot this additional COG RAM be used for ?
10. It cannot be used as additional register space (only 9 bits available in instructions).
11. It cannot be shared with other cogs.
12. When used as data, it can only be accessed by rdlong/wrlong instructions or optionally a new MOV (or LOAD/STORE) instruction(s). Needs discussion for best method.
13. Only usable as longs (not byte or word).
14. It cannot be used for self-modifying instructions that reside in additional cog ram.
Why is additional COG RAM useful ?
15. Simple to use
16. Provides additional program/data/stack space at full cog speed (no latency, fully deterministic, no jitter)
17. Helps solve a typical complaint of many P1 users (lack of cog space)
18. Easier for larger cog programs (shortcoming of P1)
19. Useful for PASM, SPIN, GCC, etc.
20. SPIN on P1 was >25% slower than it needed to be because of the lack of cog space (and ROM space).
21. Can be used as data space for text screen buffers, font tables, lookup tables, etc
22. Can be used as a cog ram stack (by software and/or with additional support instructions)
23. GCC can make use of the extra cog ram
23.1. Stack space instead of hub (much faster)
23.2. More fast cog resident routines, etc
23.3. C drivers will be easier to implement (more resident cog space)
24. Removes strain on fixed registers $1F0-1FF (less additional support instructions because we can use say $1E0-1FF)
25. Cannot be trashed by errant cog trampling over shared hub
26. Improved flat memory model
27. Single port RAM (could be 2 / 4 / 6 / 8KB or more, depending on die space)
28. Uses less power than accessing hub memory
29. Makes the P2 feel more like a traditional micro. P2 is multi-cored, but also has additional large shared memory (hub) for those larger programs and/or data requirements (easier model to understand)
30. Not an afterthought/kludge like LMM or hubexec (its a normal native mode of RISC micros)
31. Should save implementing the otherwise useful CALL/RET with internal 4 deep (but bigger requested) LIFO stack.
32. Should permit a simpler hubexec implementation for hub (hub stack instructions may/should not be required).
33. Hubexec will use the new JMP/CALL/RET relative/absolute instructions, and DJZ/DJNZ/etc relative instructions.
What additional hw support is required ?
34. Obviously the RAM (standard single port OnSemi RAM)
35. Relative and/or Absolute JMP/CALL/RET instruction(s) (same as required for hubexec)
36. DJZ/DJNZ/etc should have Relative mode or be Relative mode as standard (same as required for hubexec)
What additional hw support would be nice ?
37. Support instructions to use this as a stack. JMP/CALL/RET/PUSH/POP instructions and Stack Pointer Register in main register bank.
Questions:
38. Could it be used for CLUT / WAVETABLE ?
39. Is there a requirement for RDLONG/WRLONG to be different (ie MOV/LOAD/STORE instructions) to access this new cog ram?
Notes:
40. The reason hub ram is remapped over cog ram (where part of hub ROM becomes invisible) is to keep the hub addressing the same. This saves hw from needing to perform a calculation on all hub addresses.
41. There should be no differences in GCC to compile to this new cog ram vs compiling to hub ram.
42. This method may make hubexec simpler to implement because instruction caching may not be required (somewhat slower performance).
43. GCC performance should benefit significantly by placing the stack in the new cog ram.
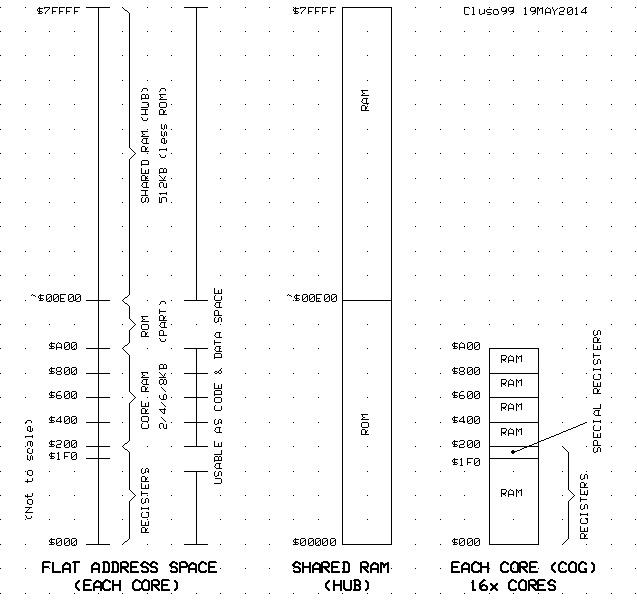
For background info, see this thread
http://forums.parallax.com/showthread.php/155687-A-solution-to-increasing-cog-ram-works-with-any-hub-slot-method
and the poll thread (currently 5 for +8KB cogs, 4 for +24KB cogs, 21 against). Note this thread does not fully represent what is proposed here though.
http://forums.parallax.com/showthread.php/155703-POLL-How-much-hub-ram-and-how-much-cog-ram-would-you-prefer
637 x 611 - 82K
Comments
But the biggest savings might be in power, as well as from determinism (that's for you heater), jitter (for you again), and latency.
I am a bit concerned about the power envelope of this new hub scheme. What is all cogs run hubexec? We will likely have all cogs filling their caches continually. What will the power envelope be accessing 512KB of hub at 16 * 32bits @ 200+MHz ? That is 16 longs or 512 bits wide @ 200MHz.
Also, the new scheme is using quite a lot of silicon (2.5 cogs worth IIRC). What if by the end we get to the situation where 512KB does not fit. The next reduction might be to 256KB (maybe 384KB will work) because the memory has to be built in 16 blocks of longs, all equal in size. So 16*32KB=512KB, 16*16KB=256KB. If the memory is made up of 8KB blocks then 16*24KB=384KB might work, being 3*8KB=24KB but this I think takes more space to build.
It has already been acknowledged that jitter is an issue with the new hub scheme. This means any program using hubexec will suffer. However, if you have a program that will fit totally in the cog, and it does not require lots of hub access otherwise, then you can code around the jitter by implementing a waitcnt around all hub accesses. The hub access would then be forced to be 16 clocks, plus the additional two instructions for the waitcnt implementation gives another 4 clocks. SO every hub access has to take 20 clocks to avoid timing jitter, and you cannot use any of the wasted clocks because you do not know which side of the access they lie. Of course, this is only for the drivers - oh wait, isn't that what the majority of the cogs are used for?
So this is another method, be it separate or in conjunction with, hubexec mode.
My reasoning is this:
An awful lot of in COG code follows the FullDuplexSerial model. If I may call it that:
1) It has to bit bang data out of the Propeller and clock data in. This requires deterministic timing. The more accurate the better. This is often done by instruction counting and/or by use of waitcnt. The Propeller instruction set allows this kind of timing determinism easily because all it's instructions take the same time.
2) It has to fetch data to transmit from the rest of the Propeller via the HUB RAM. Or deliver received data to the HUB RAM. This is a lot less deterministic. It has a lot of jitter. That jitter is caused by the fact that incoming data on pins is in no way synchronized to the HUB cycle. It is unavoidable. It is deterministic in that there is a known upper bound on HUB access time. One HUB cycle.
Now, with the new HUB arbiter scheme this is all still true.
So why all this demand for an even more jitter free HUB in the P2 with the new arbiter? Or any other HUB sharing scheme for that matter.
Especially since there is a lot less jitter in the P2 anyway by virtue of the chips execution speed being an order of magnitude higher!
I fail to see where cycle accurate HUB timing is required.
However, those burried registers in the old p2 that required special instructions to access them could now use $1E0-1EF register space and standard instructions. This may be more beneficial.
That one could be tough, but the IDATA you have here, will need new opcodes and maybe those will include
@Ptr, to make self-modifying instructions less mandated.
ie any P1 code ported could still use self-modifying instructions, but new compiled code could avoid them.
I can see the appeal of COG IDATA, especially if LUT RAM is being added anyway, (is it?) but this IDATA does imply additional Opcodes.
Maybe enough of those come-along with HUB-Exec ? Chip alone knows .
One option there is reconfigure the crosspoint switch to an 8x8 rather than the current 16x16. Much smaller then. It would operate at half the bandwidth and needs only 8 RAM blocks. The one downside is it would also need a two way mux tacked between each pair of Cogs to share the 8 switch ports.
Certainly true, but backward compatibility has rather 'locked' registers to be 9 bits worth. hasn't it ?
On a 'clean slate' design 256Reg and 768 IDATA would free opcode space, and double Code Size, but this is not a 'clean slate' design ?
You have been the biggest opponent to any slot sharing scheme presented. You basis was that code could run slower and that therefore a cog could miss a slot. Also, you said all cogs must be equal.
Now you say jitter is acceptable, but it could break code precisely in the way you tried to make out against slot sharing, even though it could be limited to co-operating cogs.
Now for a real example...
USB FS requires some extremely difficult timing restraints. Jitter is not tolerable, and neither is hubexec tolerable in reading in the bitstream. At some point, the code will be required to communicate with another cog via the hub. To avoid jitter I shall have to waste 20 additional clock cycles. USB FS is only 12MHz yet it is almost impossible to read this data as it comes in, a bit at a time, let alone pass the data via hub.
Will more cog ram help - absolutely. I can place more code there and also crc tables because the mood on these threads is not to allow extras that were originally likely to be included in the old P2.
But it would seem a shame for the cogs not to have 2KB of private ram (same amount as for registers) at a minimum, with more being preferred if feasible (i.e., not cutting too deeply into hub ram). Seems like it would be an attractive selling point when describing the cogs...eh...I mean cores: 2KB of register space (512 longs) and 2KB (or more) of private RAM.
If the separate LUT's that Chip is considering for video and signaling purposes either don't get implemented or can't handle fast stacks (and last I heard, they probably can't, as he wanted to keep the cogs simple), then that (stack usage) would be a compelling reason for private cog rams with the easy addressing scheme you've proposed, not that you don't have a whole list of potential uses.
Chip seems to be at just the place in the design process right now to consider such a proposal. Hopefully, he'll take a look at it. Maybe you could PM him. You've got forum-cred. Once he gets a full handle on how he wants to handle LUT/DMA stuff and that whole (video, etc.) chain (and he seems to have figured that out for the most part already), I think his mind would be unburdened enough to take a good look at this proposal.
I think it's clean enough to allow pretty much anything. The question on register count is how many are important for code store? Can self-modifying be disposed of in the new instruction set?
Instruction counting is also done to stay in-phase with the Hub. This becomes more important with higher bandwidth requirements. It eliminates the waitcnt from being needed and still be jitter free.
Anything that helps accommodate even more of this appeals to me.
That's from the other thread. Is this still an assumption for this one?
If so, then I disagree. The HUB ROM needs to be present after boot. It will contain the crypto and monitor.
This is getting into the idea of an entirely different CPU. The answer is "all of them" for those people who will use COGS as intended.
Maybe it or something like it will make it into the P3 or P4
Quite possibly the register count could be halved without any problems at all. Hopefully this would be compensated by additional (extended) cog ram.
Self-modifying code is regularly used in P1 drivers, so maybe some compatibility is desirable. Perhaps the new SETCOND is no longer required for the P2.
But, if MOVS/MOVD/MOVI were to be removed, then I would like to see a replacement for the regular use of indirect addressing (major use for self-modifying code).
Indirect addressing can be achieved by RDLONG/WRLONG or MOV/LOAD/STORE with the table in the extended cog ram, not in registers.
And, the JMPRET instruction would need to be considered.
Thinking further, better to leave MOVS/MOVD/MOVI in.
heater replied: heater,
Really, you don't remember tweeking code to do 2 instructions between hub accesses on the P1 !!!
Examples:
* Video code to load (to fast load a scanline from hub) - lots of samples in obex
* Overlay loader - yes, you used my overlay loader in ZiCog
I would expect that COGINIT/COGRUN or whatever, would only address hub, so I don't see any issues here for the hardware. It probably requires an EQU at the beginning of code for the MONITOR start address (as is required now). ie COGINIT etc only use hub addressing, not the flat programming model. Remember, the flat and hub models only differ by the total cog ram overmapping part of the hub ROM. I presume the CRYPTO will operate identically to the MONITOR.
Not sure what you mean with the second part???
This model is more in tune with normal processors where code usually runs from FLASH or RAM, large data resides in FLASH or RAM, and variables reside in registers (and get loaded/stored between data and registers. The real difference is that code can run from cog register space - this is unusual in other micros.
Thanks.
Why wait - its a couple of lines of Verilog and perhaps a new ORGC in pnut - simple for Chip.
And it will likely make implementing hubexec (from hub) simpler.
Summary:
It's simple, elegant, and fits the real world much better.
Means easier to describe to other micro users.
Easier to market the P2 because it better fits the existing micro analogy - use terms like core(s), shared memory, registers, etc.
Easy to implement with little additional silicon excluding the actual RAM.
Uses same concepts as hubexec, only simpler.
Makes hubexec the "standard" use where the hubexec memory can be in...
* cog register ram
* cog extended/private ram
* shared/hub ram
Running from cog register ram is the "extra" use case where self-modifying code can be used. Remember, the general community frowns upon self-modifying code.
The majority of cogs (intelligent peripheral drivers) will use the cog extended/private ram for code/data and hub will only be used to pass data between cogs.
The only real downside is that any unused (extended) cog ram cannot be shared. But, there is huge upside.
It is by far the biggest complaint about the P1, and the reason things like LMM, hubexec and fast overlay loaders were developed as workarounds.
Well, I suppose I could go and just start working with "normal" processors right now then. Just skip this part.
I agree. I don't understand the reasoning behind many of these recent threads at all (not just this one).
If we wanted to use "normal" processors, we were already spoiled for choice - we chose the Propeller precisely because it wasn't "normal".
So why the sudden rush to turn the Propeller into a "normal" processor? I just don't get it.
Ross.
Play to the strengths. They are great strengths, and we know a lot about them too.
Why this imagined concern. We already know that the P2 is going to need to refer to cogs as cores, and hub as shared memory, etc. Same goes for peripherals - we need to list what can be done, then say its done in sw.
The P1 is perceived to be different. It is in many ways, but in others, its just the same.
What I am saying here, is that hubexec is not a new method, its the traditional way of other micros. Its all perception, not implementation.
Its the same as C is a requirement. Not because the P1 or P2 is suited for it, but because its being demanded, and also accepted as a requirement.
So, I am not trying to make the P2 look like other processors, except where it makes sense.
The reality is that running a program from registers is non-traditional. The traditional way is to use non-register memory. So we call that "native" or "standard" and then we have this "super mode" where we can have the program executing in the register ram too.
You are both missing the really important part. Hubexec is viewed as a new evil way to extend the program size. But it isn't !!! It's really the "normal" way, and once you realise this, you will realise the support instructions for this are simpler to implement - it's all in the way you perceive it - they are really one of the same instructions.
Now, expand this a little - we would have new cog ram running "normal = hubexec" programs in private ram, and be capable of running in "shared ram = hub ram" too, without any differences, capable of calling/jumping between these at will. No different instructions, just the same old jmp/call/ret as required for hubexec = normal programs. The only difference here is "shared memory" execution interposes the hub slots which may cause jitter, latency and determinism issues. Caching may be provided for "shared memory" but is not required for the new cog ram.
Now the P2 becomes a multi-core micro with shared memory for data interchange between cores. Cores do not require interrupts because they are standalone objects communicating via shared memory. Programming is an order of magnitude simpler when you don't have to worry about interrputs.
What aren't you getting ??? Or are you really being argumentative for the sake of it - I really don't know ???
Once you comprehend this, the P2 is far easier to explain. It has some great features, but don't change existing understood details to make it sound more complex than it really is.
I don't think it makes a lot of sense, unless one decides the Propeller concept is a failure. I don't believe it is. I want the device Chip will build, not some ARM wanna be.
Sorry man. We don't need this.
Go too far down this road and there aren't a lot of reasons to continue. Might as well step up and use a more "normal" device that has maximized those "normal" ways of doing things.
No thanks.
I completely oppose this.
The extra instructions to support the hubexec = normal programming model are the same whether the code resides in the "new cog = core ram" or "hub =shared ram".
These extra instructions ought to be included even for code residing in "register = cog ram". They provide the mechanism to avoid self-modifying code.
You want to make the P2 seem complex and different when in reality some parts are simple and the same ?
Sounds like deception to me ?
Are you for or against hubexec ?
If you are for hubexec, then the only difference here that you can actually raise an argument against it, is on the grounds of the additional silicon to implement the additional cog ram.
Absolutely everything else is a requirement for hubexec running from hub.
The remainder is only in perception - not in any physical traits.
Right now, Chip has mapped out hubex. Let's see that. I'll bet it works just fine.
I think you were trying to say here, that Hubexec opcodes have natural support for any local COG memory.
To me, a leverage question on this is if the LUT is coming as separate RAM, then it makes sense to execute from it.
(ie extend he LUT a little, with Hubexec, to support code ).
This also tends to deprecate Self-Modifying-Code, so presumes opcode support to replace that.
The P2 has to stand on it's own feet.
It's advantages are
Nothing else is required - nothing, nothing, nothing...
Yes, hubexec has ways around self-modifying code. I have a hubexec program running on the last (interim) FPGA release. It was so simple to write.
I have raised the question (first post) about could this ram also be used for the LUT and for wave shaping. If it can, it is likely one or other, not both concurrently.
I'm not against HubExec - I just don't regard it as the main game for programming the Propeller. To get the most benefit from its unique architecture, the "normal" way to program a Propeller will remain the parallel execution of cog-based PASM objects.
My objection is the purely related to the complexity it would add. As well as four different types of RAM on the Propeller (five if you include XMM), each with different access instructions, we will also now have three "native" execution modes:
- Execution from Cog RAM
- Execution from Hub RAM
- Execution from Extended Cog RAM (which seems to be a hybrid of the above two).
Plus, we will still have LMM mode, since (I believe) none of the above can address more than the 512K of Hub RAM and we already run programs larger than that on the P1 (and we will want to do even more on the P2). And we will probably still have CMM mode, just as the ARM has "thumb" mode, for code compactness where speed is not critical.So, now we have at least three native modes two additional special purpose execution modes.
In total, five RAM types and five execution modes. Is this really necessary?
Ross.
I have to say, I find it funny that people are complaining about the potential time involved in adding this, as we are looking at 6,9, more(?) months before anyone possibly sees the P2.
The P2 is currently in the middle of a significant reboot, for a feature that no one outside of this forum has previously identified as being a sellable feature.
However, a simple 5 minute job, ok maybe it will be a bit more, has the potential to address one of the most oft complained about deficiencies that the Prop has, namely Cog/Core RAM.
And the kicker is, even if this were added, there is no change to how the Prop works vis-a-vis the current 16-rotor plan.
Actually I lied, the kicker is that LMM is the fix to a design feature that was sub-optimal in the first place, and what appears to be a simple fix that will result in even faster code is no longer wanted, but some form of LMM is.....
If Parallax wants to increase revenue with the P2 line, this single feature seems like one of the very few it has that will compel people to give it a serious look.