

Needle in a haystack (aka memory leak, stack problems or SD card issues?)
 pgbpsu
Posts: 460
pgbpsu
Posts: 460
For the last 2 weeks I've been trying to figure out the behavior of my propeller based datalogger. The system has 3 channels of ADC data sampled at 625 sps and one channel that captures the system counter at each sample. These 4 samples are passed from an ASM cog up to a SPIN routine that places them into a circular buffer. When the buffer is more than half full the system writes the buffer contents to an SD card. I'm trying to write/maintain 2 different files on the sd card. One with the raw data and a second containing meta data. The meta data file should contain information about the number of samples written, date, time, etc. These meta and data files are appended to as more data come in. If the current hour is 00, 06, 12, or 18 a new meta and data files are created.
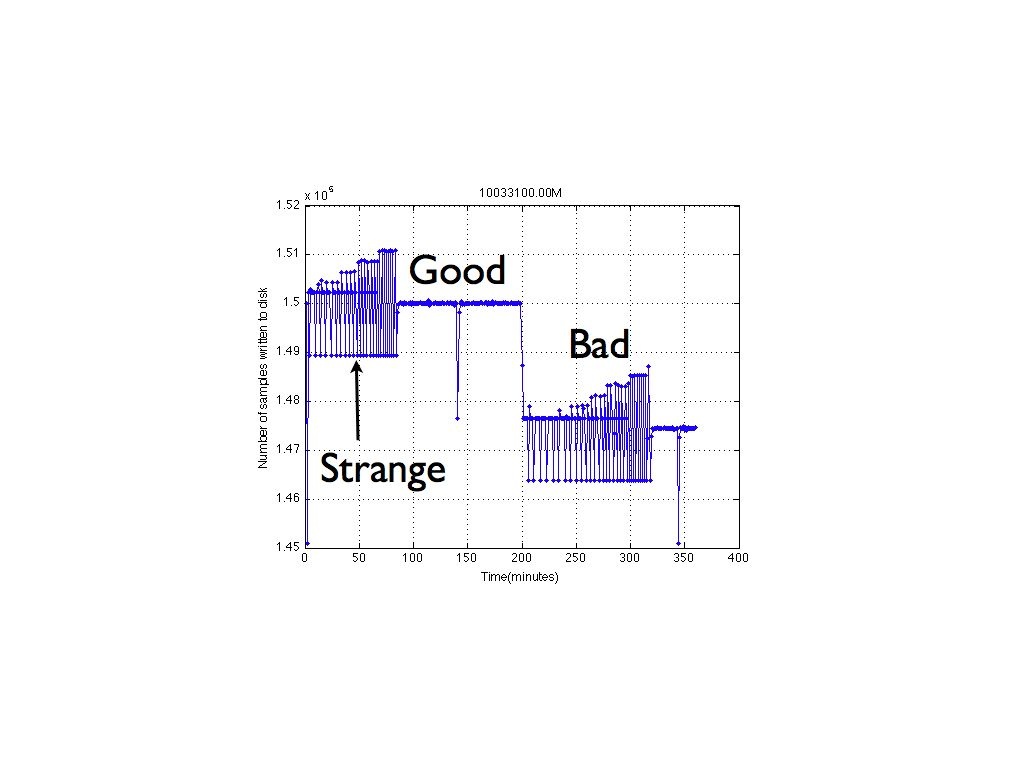
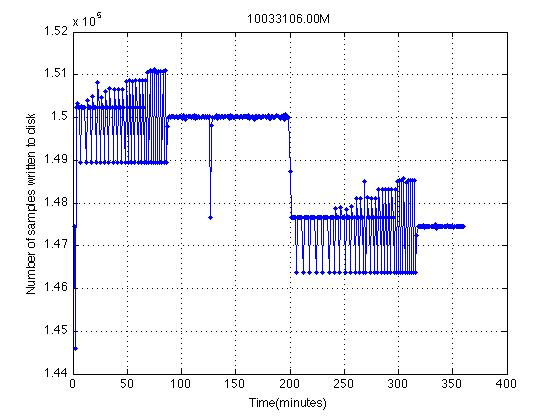
I've attached a figure created from the meta data file. The vertical axis is number of samples written to disk. Horizontal axis is the time (in minutes) since the beginning of the file. This is typical of the records I've been pulling from these units. A new line is added to the meta data file when at least one minutes worth of data has been written to the data file (4 channels * 625sps * 60 sec = 150_000). I expect a flat line at 150_000 (with jitter kept down to ~10 samples) across the entire 6 hours. Clearly that's not happening. This behavior is not only repeatable but extends from unit to unit with the drop from "Good" to "Bad" happening at nearly the same time on two separate units. It also repeats itself in the NEXT 6 hour chunk (attached figure 2).
I should point out that these units have GPS on them and in fact the gps engine in use provides a 5.12Mhz clock to the prop and to the ADC. This provides sampling accuracy across different units. This GPS output drives the ADC clock which in turn (should) govern the rate at which data are dumped to the SD card. If we trust our GPS (which we do) the ADC should be providing data to the Prop at a known rate. The prop should be getting a new sample from the ADC every 1.6mS (625sps). Every time I scope this it's right. So I suspect that although the Prop is getting samples on time, it's not getting them out of the buffer on time. Nothing prevents new data from entering the buffer before all old data have been written out (possibly a problem but not the cause of what is seen here). Data are fed into the buffer by one cog and written out by another. The dump buffer cog basically waits while the buffer is filled. When it reaches half full (or greater) it will dump the data to the SD card and update the tail pointer. This cog also dumps the meta data when at least 150_000 samples have been written to the data file. This SHOULD happen once per minute. The meta data are not in any kind of circular buffer. I simply write 60 bytes of HUB memory to disk. The circular data buffer is 2560 longs (~ 1 second at 4 channels at 625 sps) which should be long enough to absorb SD card jitter and account for the time needed to write the 60 bytes of meta data.
Reviewing the first attached figure, it would make more sense if the system never seemed to work, but it appears to start off very strangely bouncing around for the first 80 minutes. Then something clicks and it's happy for ~2 hours. Then it goes crazy before settling down (at the wrong value). The second attached plot is the next chunk of data from the same unit. It's the 6 hours immediately following those plotted in figure 1. There is NO REBOOT between these files. Only a final closing of the first pair of files and opening of a new set.
I'm willing to post the code, although I thought I'd first ask for people's impression of this type of problem. Should I be looking at the SD card stability, memory leak, stack problems, or something else all together.
Many thanks for looking and for suggestions.
Regards,
Peter
I've attached a figure created from the meta data file. The vertical axis is number of samples written to disk. Horizontal axis is the time (in minutes) since the beginning of the file. This is typical of the records I've been pulling from these units. A new line is added to the meta data file when at least one minutes worth of data has been written to the data file (4 channels * 625sps * 60 sec = 150_000). I expect a flat line at 150_000 (with jitter kept down to ~10 samples) across the entire 6 hours. Clearly that's not happening. This behavior is not only repeatable but extends from unit to unit with the drop from "Good" to "Bad" happening at nearly the same time on two separate units. It also repeats itself in the NEXT 6 hour chunk (attached figure 2).
I should point out that these units have GPS on them and in fact the gps engine in use provides a 5.12Mhz clock to the prop and to the ADC. This provides sampling accuracy across different units. This GPS output drives the ADC clock which in turn (should) govern the rate at which data are dumped to the SD card. If we trust our GPS (which we do) the ADC should be providing data to the Prop at a known rate. The prop should be getting a new sample from the ADC every 1.6mS (625sps). Every time I scope this it's right. So I suspect that although the Prop is getting samples on time, it's not getting them out of the buffer on time. Nothing prevents new data from entering the buffer before all old data have been written out (possibly a problem but not the cause of what is seen here). Data are fed into the buffer by one cog and written out by another. The dump buffer cog basically waits while the buffer is filled. When it reaches half full (or greater) it will dump the data to the SD card and update the tail pointer. This cog also dumps the meta data when at least 150_000 samples have been written to the data file. This SHOULD happen once per minute. The meta data are not in any kind of circular buffer. I simply write 60 bytes of HUB memory to disk. The circular data buffer is 2560 longs (~ 1 second at 4 channels at 625 sps) which should be long enough to absorb SD card jitter and account for the time needed to write the 60 bytes of meta data.
Reviewing the first attached figure, it would make more sense if the system never seemed to work, but it appears to start off very strangely bouncing around for the first 80 minutes. Then something clicks and it's happy for ~2 hours. Then it goes crazy before settling down (at the wrong value). The second attached plot is the next chunk of data from the same unit. It's the 6 hours immediately following those plotted in figure 1. There is NO REBOOT between these files. Only a final closing of the first pair of files and opening of a new set.
I'm willing to post the code, although I thought I'd first ask for people's impression of this type of problem. Should I be looking at the SD card stability, memory leak, stack problems, or something else all together.
Many thanks for looking and for suggestions.
Regards,
Peter
1024 x 768 - 85K
560 x 420 - 40K
Comments
And if I understood you right, you have 4 channels, meaning that 625 times per second your gather 4 longs from the ADC and store them away at the next 4 locations in the circular buffer, probably keeping the hub pointer in the cog for that time, then writing it back to its hub RAM location.
The other cog then watches whenever this head pointer enters the other half of the buffer, and then writes the filled in half to the SD. Is that right?
If this is the scenario, then the corrupted (strange) data could perhaps be just you inadvertently having the buffer halves swapped? I.e. when you would write the buffer that is just being sampled into, that could explain the strange or corrupt data. I would try a different approach to writing buffer halves, e.g. writing quarters or eights. It might also make a difference to try to write in chunks of the SD card's sector or cluster size instead of the odd 2500 longs = 10000 bytes. I'd try with a power of 2 < 1250 longs, such as 1024. That way you avoid pending sector or cluster writes and that should produce more consistent timing than sometimes writing only a few bytes of a sector or cluster.
To allow easy writing of x^2 sized chunks, I would place the 60 longs at the beginning of the buffer, followed by 2500 longs circular buffer, followed by an overflow buffer of write-block-size - 1 longs. In the case the write would wrap at the end of the circular buffer, the other cog can just copy the longs from the beginning of the circular buffer to the padding area, then advise the SD writer to store the block from (worst case) circular buffer + 2499
Of course this is all guessing in the wild. I could perhaps make more educated guesses when seeing the code.
Juergen
▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔
He died at the console of hunger and thirst.
Next day he was buried. Face down, nine edge first.
Post Edited (pullmoll) : 3/31/2010 8:47:05 PM GMT
Close. I have a circular buffer in HUB memory that is 2560 longs that is used to store the 4 longs passed up from the ADC cogs (actually it's 3 ADC samples, and 1 system counter). There is a separate 60 longs of meta data stored else where in HUB. I don't have enough free space to double buffer the ADC data which is why I'm using a circular buffer. Normally the system will write ~5120 BYTES of ADC data to the SD card when the buffer is dumped. I realize the SD card would prefer 512 byte chunks, but I believe the newest version of fsrw is smart enough to chunk my request into the 512-byte size it likes. I see your point about the odd size at the end and maybe moving to 2^ writes would help. I'll see what I can do to implement that. In my head I imagine this buffer as 4 columns of data. Each row contains 3 ADC samples and one counter. I'd like to dump entire rows if possible because it will make the book keeping simpler. But I think that could be arranged given your suggestions.
What really confuses me is the fact that for part of the 6 hour record, it works great. I can't explain why it works then but not other times or vice versa. When sampling at 625 sps the buffer is dumped to SD card ~15000 times in the 2 hours it works. I know for certain that it is successfully writing and wrapping around the circular buffer. But something happens to make that work and something happens again to make it fall apart.
I've attached the code if you are interested in looking at it further. The methods of most interest are MANAGE_BUFFER, DUMP_META_DATA, and DUMP_SEISMIC_BUFFER. The code hasn't been polished and has lots of debug messages as I track down this problem. However debug messages are too slow to put into the dump buffer/meta data methods.
Thanks for your comments.
p
Okay, then changing it to a power of two is probably useless, as you at least don't write partial sectors.
I would - out of the wild again - explain that with some slow drift that is in the system and its timing, shifting the point in time of writes happening over the buffer window and at some point then syncing to the correct buffer half, only to drift further and some time later losing sync again.
I'll have a close look. I'm sitting here without anything important to do right now
▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔
He died at the console of hunger and thirst.
Next day he was buried. Face down, nine edge first.
▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔
He died at the console of hunger and thirst.
Next day he was buried. Face down, nine edge first.
Post Edited (pullmoll) : 3/31/2010 9:42:12 PM GMT
And, I just saw that, you have commented the _clkmode and _xinfreq lines. I hope you did that just in the file you attached and have those settings in your real code... or are you running at RCFAST, i.e. ~12MHz? [noparse]:)[/noparse]
▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔
He died at the console of hunger and thirst.
Next day he was buried. Face down, nine edge first.
Post Edited (pullmoll) : 3/31/2010 10:38:32 PM GMT
I'd suggest trying a freshly formatted large SHDC card, and not erasing from it.
▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔
www.mikronauts.com E-mail: mikronauts _at_ gmail _dot_ com 5.0" VGA LCD in stock!
Morpheus dual Prop SBC w/ 512KB kit $119.95, Mem+2MB memory/IO kit $89.95, both kits $189.95 SerPlug $9.95
Propteus and Proteus for Propeller prototyping 6.250MHz custom Crystals run Propellers at 100MHz
Las - Large model assembler Largos - upcoming nano operating system
Again, thanks for looking at this.
SET_BIT and CLEAR_BIT may not be good programming, but I think they work. I don't return anything because the address passed (as arg1) is a global. It's the register that should be altered. The second argument to these 2 functions is the bit that should be altered. I'd be very surprised if the problem is here, but if what I just described sounds problematic (or doesn't match what the code ACTUALLY does) I'll have to revisit it. But debugInfo is the same as @debugInfo i believe since I'm only addressing a byte.
The clkfreq settings are commented out because when the program starts it starts in RCFAST. The first thing the system does is SETUP_CLOCK. That method watches for a 1PPS from the gps engine. When it has a 1PPS that means the 5.12Mhz signal from the gps (which feeds the prop) is present. At that point I reset the system clock
From here on the system clock speed is 81.92Mhz.
I realize that DUMP_SEISMIC_DATA doesn't always have the same size chunks, but I believe that FSRW takes the starting address I've passed it, and writes things in 512-byte chunks. In all likelihood the final write is not a full 512-bytes. There maybe something useful in making sure I only request writes that are powers of 2 but I believe that in the 2 hours where it works, the writes aren't always 2^. Still it's worth looking into. I'm not sure I understand your suggestion of always writing "@seismicBuffer+0 or @seismicBuffer+(SEISMIC_BUFFER_LENGTH>>1)*4".
In order to give my self the maximum buffer size (in time) I elected to use a circular buffer. If I have some number of bytes to write (say half my buffer (1280 samples = .5 sec) ) I have a full 1280 samples empty that can be filled while I write. That means I have as much as .5 seconds to complete the write before I run out of buffer space. As I write this I see that mabye I'm not using the circular buffer as efficiently as I should. And in fact I'm treating it as BUF_A and BUF_B. If I dump data to the SD card MORE frequently say when there are at least 512 bytes, maybe things get better. Is this what you're getting at?
@Bill Henning-
I too suspect some kind of SD card problem, but I've tried 16GB cards that have been freshly formatted as per FSRW's formatting suggetions and the results are the same. I'll try again just to be sure.
Thanks both of you for looking at this.
Peter
I thought that would be easy. The seismicNew can at any time either be less or greater/equal than SEISMIC_BUFFER_LENGTH>>1. You could always only write the other half of the buffer in its entirety, i.e. 1280 longs = 5120 bytes = 10 sectors. Writing some more of the data that was already accumulated in the active half of the buffer adds nothing but overhead. Of course you might have to take care of a final, partial buffer, but I think you write until the SD is full anyway.
For the "debugInfo is the same as @debugInfo": no, debugInfo is the current value of the byte while @debugInfo is its address. I trashed hub memory @0 many times, because I forgot to put an @ on a variable I intended to be passed by reference. If you use SET_BIT and CLEAR_BIT only for changing debugInfo, you could of course alter the global, but what you do now is alter the stack variable and then lose when returning.
▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔
He died at the console of hunger and thirst.
Next day he was buried. Face down, nine edge first.
Post Edited (pullmoll) : 3/31/2010 11:48:06 PM GMT
Thanks for pointing this out. I'll have to look at that more carefully. Honestly, that's a debug feature. Wouldn't it be ironic if that debug effort is causing problems!
Thanks again. I'll keep you posted on how this goes.
Peter
No, it can't cause a problem because it doesn't do anything except wasting a few cycles [noparse]:)[/noparse]
See it this way: the byte debugInfo is converted into a long and pushed to the stack. Then your function SET/CLEAR_BIT is called and acts on that long on the stack. Then it returns, giving the stack space back and (I think) returning a 0, because you have neither return value nor a result := value in the code. And if you had either, you would also have to assign that result (a long) to the byte debugInfo.
The other way would be to pass the address of debugInfo with the @ and in the function then alter byte[noparse][[/noparse]value_ptr] |= or &= ... And doing it this way can lead to code trashing memory in the case where you pass it a value instead of an address. The global arrays byte/word/long should therefore be handled with care.
I'd be interested to hear if anything changes if you simplify the code in DUMP_SEISMIC_DATA.
▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔
He died at the console of hunger and thirst.
Next day he was buried. Face down, nine edge first.
append each time. Note that opening a file for append can take a while (linear in the length of the file) since it has to
chase the FAT chain. If you keep both files open, things may work better.
In the big picture, expecting relatively low latency from the SD routines may be too much to ask for. This may mean
you need larger buffers, or simply a mechanism for dealing with occasional lost samples. You also need a decision on
flushing; every pclose() flushes and that writes out multiple blocks (the current dirty block, the current FAT block, and
updates the directory entry) so in reality there's a lot going on every time you switch files.
The behavior can easily change dramatically; initially both files may have been using the same cluster chain block
but eventually one moved into another cluster chain block, so now the FAT chain reading/updating was ping-ponging
slowing things down.
But start with leaving both files open, and *maybe* add a pflush() occasionally. Try not to flush both files
concurrently unless you really need to.
I believe my problem is related to the SD card and buffer size. Unfortunately, my buffer size options are kind of limited but with Pullmoll help I realized that my circular buffer of 1 second was really functioning as a buffer A and buffer B with only 1/2 second of storage. I hope some small changes will fix that.
I am ping-ponging, but I spend a minute writing to one file before opening the other for a single write (of 60 bytes), then return to file A for another minute of writing. I think the popen method in the version of fsrw I'm using closes any open files before opening the new one. So you must be suggesting using 2 instances of fsrw? Do I understand that correctly? Or is there a way with fsrw (2.7 I think) to have multiple files open with only one fsrw object?
Thanks,
Peter
Perhaps you can solve the issue by using external RAM to buffer the data for a much longer time.
There was a thread started by Bill Henning who offers an SRAM/FRAM/FLASH add on board.
Your data is 625*16 = 10'000 bytes/sec. With the 128KB FlexMem board that's 13.1 seconds of data until it wraps, leaving you with ~6.5 seconds per 64KB flush. I think reading 64K from the RAM to the hub RAM in e.g. 512 byte chunks and writing them to the SD should always be possible in 6.5 seconds. You need 8 spare port bits for this card, on a 10 pin connector, probably with Vcc + GND. Perhaps you could go with FRAMs (512KB), but I think they are more expensive.
To avoid collisions you would have to use the lock mechanism for the DUMP_SEISMIC_DATA cog writing hub RAM blocks to external RAM and the DUMP_TO_SD cog reading blocks back to another buffer in hub RAM and writing them to SD. The locking would have to be around the external RAM access, i.e. only one of both "threads" can have access to the external RAM at the same time. With a small block size the delay for the DUMP_SEISMIC_DATA cog acquiring the lock should be lower than with direct SD writing.
▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔
He died at the console of hunger and thirst.
Next day he was buried. Face down, nine edge first.
Post Edited (pullmoll) : 4/1/2010 6:34:01 AM GMT
Realy ONE that card need only 6 pins.
Other 2 pins on it are Spare pins to alternate /CS addresses for posibility to STACK 2 more that FlexMem PCB's on same Connector bus.
Connector have -
3.3V, GND, DIO,DIO,DIO,DIO, SCK, and /CS1, /CS2, CS3
Regards
▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔
Nothing is impossible, there are only different degrees of difficulty.
For every stupid question there is at least one intelligent answer.
Don't guess - ask instead.
If you don't ask you won't know.
If your gonna construct something, make it·as simple as·possible yet as versatile as posible.
Sapieha
As Sapieha says, you really only need 6 pins - however for highest speed burst transfers, it need P0-P5, and one (or optionally two) cogs.
Actually, if wired differently, it really only needs P0-P3 for the 4 bit data bus, SCK and /CS can be any pin. Simply don't use the 10 pin header, and run wires.
▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔
www.mikronauts.com E-mail: mikronauts _at_ gmail _dot_ com 5.0" VGA LCD in stock!
Morpheus dual Prop SBC w/ 512KB kit $119.95, Mem+2MB memory/IO kit $89.95, both kits $189.95 SerPlug $9.95
Propteus and Proteus for Propeller prototyping 6.250MHz custom Crystals run Propellers at 100MHz
Las - Large model assembler Largos - upcoming nano operating system
For future designs I'll keep Bill's FlexMem in mind.
Regards,
Peter
and other "global" operations on the first, but for popen/read/write you can use both.
Can you tell me what will happen if, during that every-one-minute ping, it just so happens to take enough time for your buffer to wrap, what do you think
will happen? Is it possible things will get sufficiently discombobulated where you'll see odd behavior? You might even intentionally "trigger" this by adding
a waitcnt() of a second or some such in that ping-pong code just to try to trigger this behavior.
But do remember, open for append can take some time depending on the size of the file. (But certainly under a second.)
I'm sure we can make this work just fine. I'd say one key is in understanding. Maybe we can get cnt-based timestamps in the sample file and in the
metadata file so we can explicitly see any places where something bad happened?
Although I'm not ready to call it fixed just yet, the most recent results are very encouraging. I fixed a couple of things that pullmoll pointed out about my SET and CLEAR_BIT routines and I changed my DUMP_SEISMIC_BUFFER so that it dumps to SD anytime there are more than 512 bytes in it. Previously I had it set to dump when half full. Now it dumps more frequently, but it also leaves more space in the buffer for those occasions when it can't return and dump as fast as I'd like it to. I have nearly a second of buffer space rather than the .5 seconds in my previous setup.
You are absolutely correct about keeping track of the timing. All along I've been reading 3 ADC channels. The forth channel is the timer so I have a system time stamp for every row in my 4xN array. That's one of the items I've been using to see how this system performs and it is necessary to put all the data back together and account for small timing errors.
I've attached 2 new figures. Figure3 is the same type of plot as the 2 in the OP, made from the meta-data. Y-axis is number of samples dumped. X-axis is time since start of file. This doesn't have the 6 hours that I showed yesterday, but it certainly starts out just the way I'd like. First thing I record to the meta data file is a start line (0 samples written thus far). Each point after that is at the top of the next minute. The second sample doesn't have 150_000 samples because the system started part way through the first minute. After that things are flat.
The second figure (figure 4) is the plot Tom was asking for. To make this plot I recorded the system timer every time I got my 3 ADC samples. I took these counter times and, accounting for counter rollover, I calculated the difference in the counter between consecutive samples. From that I subtracted the number of counts I expected to be between consecutive samples. That leaves me with a plot of how many extra (or fewer) counts there are between consecutive samples. Zero would be perfect, 1 means I have 12.2nanoSeconds of jitter (which is just fine by me). Again, not 6 hours of data. Both figures contain ~75 minutes. In the case of figure 4 that's ~3_000_000 points.
Not too shabby.
Tom-
This is still using one instance of fsrw. I write to the seismic file for 1 minutes. Close it, open the metadata file, write to it, close it and reopen the seismic file. This happens every minute and has happened more than 75 times in these plots. I'll let this run overnight (and over the weekend) and post if there are any changes. I am using large cards (16GB) when the disk starts to fill and I have say 14GB and 475 files do you think I can expect trouble? It takes several weeks to collect that much data, but I can fake it by copying duplicate files to the disk. I'll find out. Care to make a prediction?
Thanks to all for helping me. I think this is on the right track now!
Regards,
Peter
To mitigate this, make sure you are using the largest possible sector size. The reason is we need to scan the FAT to find free
sectors. I think fsrw always attempts to scan from the most recent place it left off, so things *should* be okay, but I'm not
certain, and when you reopen the metadata file that may cause it to "jump back" to the earlier portion of the FAT.
If you use 32K sectors, and a 16GB card, that means 500K sectors. At 4 bytes each, the entire FAT table is 2MB. A worst-case
scan of this will take probably a bit more than a second (assuming it is nearly full and the scan starts at the beginning).
(It may take quite a bit longer in reality because the scanning code is in spin, and the spin overhead may well dominate).
So I'd be a bit worried, yes. Keeping both files open simultaneously may help this case.
You can test this explicitly if you want. Start with an empty card. Open file A for write, and write say 50K bytes.
Close file A. Now fill the card to nearly full (say, 15GB) using whatever method you want (using a Windows PC will be
the fastest way to do this.) Now, reinsert the card into your prop setup, and time the entire process to open file A for
append, and append another 100K bytes. At some point in the write (probably at about 16K bytes) you will see a
*huge* delay (most likely) as fsrw scans the entire FAT (2MB) for a free cluster.
If this does happen and it is a real problem, there are probably ways we can significantly improve it.
This isn't just a thought experiment; your metadata file is relatively small, and its clusters may live early on in the
file system, and the other files fill up the card, and it may well be the case that reopening and appending to that
metadata file for a particular location may cause exactly this huge delay.
Note that the same thing might occur on a real PC using FAT32, except there, a few things happen to make things
work better. First, the PC processor is *much* faster so scanning the FAT is faster. Also, most real FAT32
filesystems use an in-memory bitmap of free clusters to avoid this scanning (on the prop, we don't have enough
RAM for this).
clusters. In this case there are 4M clusters, at 4B each that's 16MB of FAT. Scanning that FAT would take
*forever*. This is why I always say to use the largest possible clusters.
Thanks for the comments. These disks have been formatted to 32K clusters as per FSRWs instructions. I'll try all this out tomorrow and see what kind of times we're talking about.
How much of this goes away if I combine my meta and data files into one file. I like it because it allows me to have smaller files and still not bump into the 512 files on disk problem. My boss like splitting the two. No pressure to say one file is better ; )
Peter
to make that happen. So if 512 files is your problem, I can probably arrange for that problem to go away on FAT32 (easiest if we
allocate the root directory initially and make it contiguous and large). But I'm a bit under the gun on a number of projects, so I
probably won't get a round tuit for a bit.
A 16GB card divided by (say) 512 files is 32MB per file. I guess that's a bit large for what you are trying to do. But that's certainly
the easiest solution.
This system generates ~36Mbytes/hour so my 6 hour files are 216Mbytes! A 16Gig card is full between 2 and 3 weeks. If I were to combine the meta and data files into one I could start a new file every hour and run for 21 days before running out of files. By that time I will have run out of disk space. I'll look into doing things that way. I personally don't like the 6 hour files. The are just to big to work with. Matlab chokes after just a few plots. Besides if a file gets corrupted or lost we lose 6 hours. The other way we'd only lose 1.
Thanks for your kind offer, but I don't see any need to alter FSRW to address more than 512 files. If the boss really wants separate files for meta and data, I'll go to 2 hour files. But I'm going to argue that we should combine them.
p
Sometimes the only problem is making things too complex for no good reason, and I guess your buffer write handling was the cause here.
Juergen
▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔
He died at the console of hunger and thirst.
Next day he was buried. Face down, nine edge first.
I'm not out of the woods yet. Attached is a plot of 6 hours of data recorded last night. Things look very good for about 200 minutes, then revert to the behavior from before. I'm going to try putting everything into one file and see if that helps. Certainly converting what I thought was a ring buffer but was actually a double buffer in to a true ring buffer helped, but maybe 1 second of buffer space isn't enough when I'm asking FSRW to close this current (big) file find the end of a small file, write to that small file, then return to the end of a big file. Hopefully combining those files into one will reduce the time required to accomplish this AND I can have shorter files because I'll have half as many files on disk.
I'll post again when I've got results.
I'd like to thank both of you and everyone who's helped sort this out.
Regards,
Peter