

Faster LMM Code: Not reversed this time. (IMPORTANT Addendum in Top Post)
 Phil Pilgrim (PhiPi)
Posts: 23,514
Phil Pilgrim (PhiPi)
Posts: 23,514
The "standard" LMM kernel, first devised by Bill Henning, uses a loop like this:
This misses the hub sweet spot by one instruction, thereby lengthening the execution time. In order to hit the sweet spot, I came up with the reverse LMM awhile back, in which the LMM assembly code has to be arranged in hub memory in reverse order:
Reverse LMM code runs a lot faster as a result, but it's a real pain to write and debug. The reason the code has to be in reverse is that there's no ijnz instruction to complement djnz. Unfortunately, djnz is the only instruction in the Propeller's instruction set that both modifies a destination value by adding or subtracting and which causes a jump to occur. So it seemed that the reverse LMM was it, as far as hitting the sweet spot was concerned.
Today I was determined to find a way to do a fast forward LMM. I've learned that, with the Propeller, virtually anything is possible, and this turned out to be no exception. The secret is to fetch the instructions out of order but to execute them in order. This is done with a pipeline of sorts and takes advantage of the Propeller's own pipelining. Here's the basic loop:
Every time through the loop the PC jumps ahead by 9 bytes, then back by 1, for a net gain of 8 bytes, or two instructions. For the first instruction in the loop, the PC points to the actual long address, plus 3. It then increments the address by 9, thus pointing 12 bytes, or 3 instructions away. Then it executes the first instruction. The next step is to fetch the instruction three instructions away from the one it just executed. But before it can be stored in instr2, the Propeller fetches the instruction previously loaded there and executes it. This is the effect of the Propeller's pipelining. Finally, by using a djnz, the instruction two instructions from the first one is pointed to and fetched at the beginning of the loop. So, to summarize, in a program sequence denoted "ABCDEFGHIJ", the instructions are fetched in the order "BADCFEHGJI" but executed in the order "ABCDEFGHIJ".
One downside to this scheme is that the value of the PC does not change between instr1 and instr2. This makes it impossible to implement a simple add pc,#daddr for relative jumps, since you don't know in which slot it will be executed and, consequently, can't tell what the value of the PC is relative to the jump. For that reason, every jump has to be a long jump, with the jump address in the next long.
Here's a program that I used to test and compare this fast LMM with the normal one — both using long jumps:
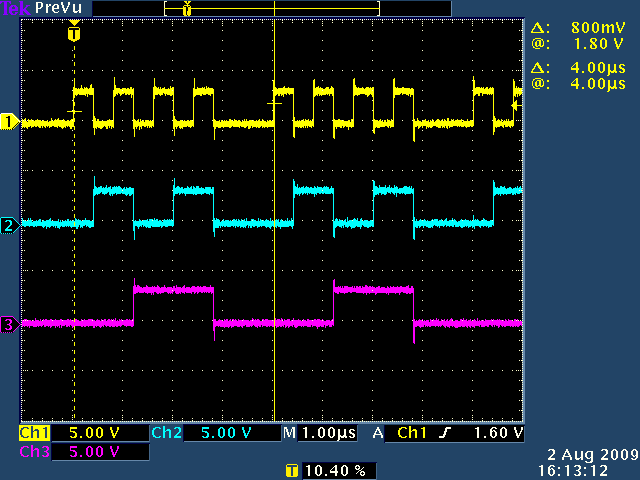
Here is what the scope output looked like for the normal LMM:

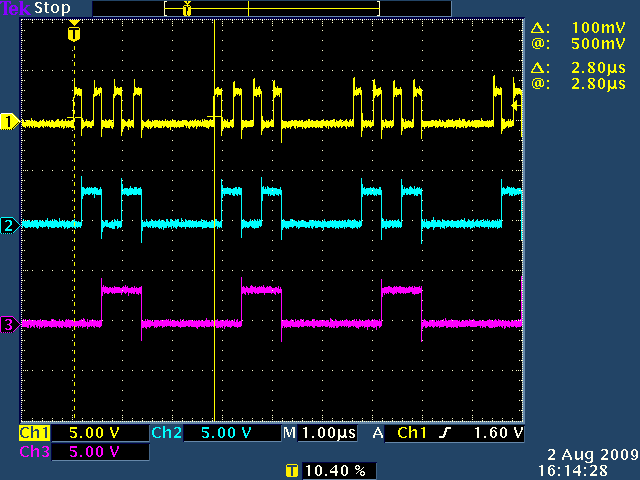
The total length of the loop was 4.00µs. Here's the same test program run with the fast LMM kernel:

Now the total length of the loop is 2.80µs, for a 42.8% speedup. Although the fast LMM goes twice as fast on the straightaway, it's slower in the turns, due to its more complicated gear shifting.
One other thing to notice is that individual instruction times in the fast LMM vary, depending on whether they are executed in instr1 or instr2. This will have consequences when output timings are critical.
-Phil
Addendum: I just realized that this version has one huge, and fatal, flaw. That would be the use of the z flag in the jump routine. Setting flags is a big no-no in LMM kernels, since doing so will interfere with their use in the users' code. As such, the improved kernel code (below) is recommended instead.
Post Edited (Phil Pilgrim (PhiPi)) : 8/4/2009 6:19:29 PM GMT
lmm_loop rdlong instr,pc 'Read the next instruction.
add pc,#4 'Increment the PC.
instr long 0-0 'Execute the instruction.
jmp #lmm_loop 'Loop back for next instruction.
This misses the hub sweet spot by one instruction, thereby lengthening the execution time. In order to hit the sweet spot, I came up with the reverse LMM awhile back, in which the LMM assembly code has to be arranged in hub memory in reverse order:
instr2 long 0-0
rdlong instr1,pc
sub pc,#7
instr1 long 0-0
start_here rdlong instr2,pc
djnz pc,#instr2
Reverse LMM code runs a lot faster as a result, but it's a real pain to write and debug. The reason the code has to be in reverse is that there's no ijnz instruction to complement djnz. Unfortunately, djnz is the only instruction in the Propeller's instruction set that both modifies a destination value by adding or subtracting and which causes a jump to occur. So it seemed that the reverse LMM was it, as far as hitting the sweet spot was concerned.
Today I was determined to find a way to do a fast forward LMM. I've learned that, with the Propeller, virtually anything is possible, and this turned out to be no exception. The secret is to fetch the instructions out of order but to execute them in order. This is done with a pipeline of sorts and takes advantage of the Propeller's own pipelining. Here's the basic loop:
flush add pc,#4 'Get next instruction address.
rdlong instr2,pc 'Preload pipe with next instruciton.
sub pc,#1 'Point back to first instr, plus 3 bytes.
pipe rdlong instr1,pc 'Read PC instruction.
add pc,#9 'Point to PC+3 instruction.
instr1 long 0-0 'Execute PC instruction.
rdlong instr2,pc 'Read PC+3 instruction.
instr2 long 0-0 'Execute PC+1 instruction.
djnz pc,#pipe 'Point to PC+2 instruction.
Every time through the loop the PC jumps ahead by 9 bytes, then back by 1, for a net gain of 8 bytes, or two instructions. For the first instruction in the loop, the PC points to the actual long address, plus 3. It then increments the address by 9, thus pointing 12 bytes, or 3 instructions away. Then it executes the first instruction. The next step is to fetch the instruction three instructions away from the one it just executed. But before it can be stored in instr2, the Propeller fetches the instruction previously loaded there and executes it. This is the effect of the Propeller's pipelining. Finally, by using a djnz, the instruction two instructions from the first one is pointed to and fetched at the beginning of the loop. So, to summarize, in a program sequence denoted "ABCDEFGHIJ", the instructions are fetched in the order "BADCFEHGJI" but executed in the order "ABCDEFGHIJ".
One downside to this scheme is that the value of the PC does not change between instr1 and instr2. This makes it impossible to implement a simple add pc,#daddr for relative jumps, since you don't know in which slot it will be executed and, consequently, can't tell what the value of the PC is relative to the jump. For that reason, every jump has to be a long jump, with the jump address in the next long.
Here's a program that I used to test and compare this fast LMM with the normal one — both using long jumps:
CON
_clkmode = xtal1 + pll16x
_xinfreq = 5_000_000
PUB Start | rslt
cognew(@fast_lmm, @test_code)
DAT
'-------[noparse][[/noparse]Normal LMM Kernel]--------------------------------------------------
org 0
norm_lmm mov nbase_addr,par 'Get the base address of the code.
mov npc,par 'PC is base address to start.
lmm_loop rdlong instr,npc 'Read the next instruction.
add npc,#4 'Increment the PC.
instr long 0-0 'Execute the instruction.
jmp #lmm_loop 'Loop back for next instruction.
njump rdlong npc,npc 'Long jump: address in next instr.
add npc,nbase_addr 'Add relative address to base address.
jmp #lmm_loop 'Resume with new address.
njump_ret long 0-0 'Dummy needed to accommodate CALL.
nbase_addr res 1
npc res 1
'-------[noparse][[/noparse]Fast LMM Kernel]----------------------------------------------------
org 0
fast_lmm mov fbase_addr,par 'Get the base address of the code.
mov fpc,par 'PC is base address to start.
flush add fpc,#4 'Get next instruction address.
rdlong instr2,fpc 'Preload pipe with next instruciton.
sub fpc,#1 'Point back to first instr, plus 3 bytes.
pipe rdlong instr1,fpc 'Read PC instruction.
add fpc,#9 'Point to PC+3 instruction.
instr1 long 0-0 'Execute PC instruction.
rdlong instr2,fpc 'Read PC+3 instruction.
instr2 long 0-0 'Execute PC+1 instruction.
djnz fpc,#pipe 'Point to PC+2 instruction.
fjump cmp fjump_ret,#instr1+1 wz 'Where did the CALL come from?
if_z mov fpc,instr2 ' instr1: Jump target is in instr2
if_nz sub fpc,#1 ' instr2: Need to read jump target from hub.
if_nz rdlong fpc,fpc ' Get it.
add fpc,fbase_addr 'Add base address.
jmp #flush 'Go back and restart the pipeline.
fjump_ret long 0-0 'Contains address of the CALL. (Do not use RET!)
fbase_addr res 1
fpc res 1
'-------[noparse][[/noparse]LMM Test Code]--------------------------------------------------------
org 0
test_code mov dira,#7
:loop mov outa,#1
mov outa,#2
mov outa,#3
mov outa,#4
mov outa,#5
mov outa,#6
mov outa,#7
mov outa,#0
nop 'Added to ensure worst case for jump in fast LMM.
call #fjump 'Change to #njump for normal LMM.
long :loop << 2
Here is what the scope output looked like for the normal LMM:
The total length of the loop was 4.00µs. Here's the same test program run with the fast LMM kernel:
Now the total length of the loop is 2.80µs, for a 42.8% speedup. Although the fast LMM goes twice as fast on the straightaway, it's slower in the turns, due to its more complicated gear shifting.
One other thing to notice is that individual instruction times in the fast LMM vary, depending on whether they are executed in instr1 or instr2. This will have consequences when output timings are critical.
-Phil
Addendum: I just realized that this version has one huge, and fatal, flaw. That would be the use of the z flag in the jump routine. Setting flags is a big no-no in LMM kernels, since doing so will interfere with their use in the users' code. As such, the improved kernel code (below) is recommended instead.
Post Edited (Phil Pilgrim (PhiPi)) : 8/4/2009 6:19:29 PM GMT
640 x 480 - 15K
640 x 480 - 15K
Comments
You continue to amaze me. Your brain must work equally well backwards, forwards, sideways and time-sliced
I'm currently reworking my XMM kernel to fit in the new Catalina memory model (i.e. 16Mb data/code/heap, with 32kb stack). It's a struggle because I'm just a few longs short.
Now I'll have to re-write it again and try and find even more space. If you don't stop doing this, I swear I'm going to come over there and confiscate your Propeller
Ross.
▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔
Catalina - a FREE C compiler for the Propeller - see Catalina
WOW!
Very impressive work.
My brain hurts a bit, thinking through it, but still... impressive speedup.
For comparisons sake, what does your scope show with my recommended 4 way unrolled loop?
Very very cool work...
Bill
▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔
Please use mikronauts _at_ gmail _dot_ com to contact me off-forum, my PM is almost totally full
Morpheus & Mem+ Advanced dual Propeller SBC with XMM and 256 Color VGA - PCB, kit, A&T available NOW!
www.mikronauts.com - my site 6.250MHz custom Crystals for running Propellers at 100MHz
Las - Large model assembler for the Propeller Largos - a feature full nano operating system for the Propeller
▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔
--Steve
Propalyzer: Propeller PC Logic Analyzer
http://forums.parallax.com/showthread.php?p=788230
That's impossible to follow first thing after waking up in the morning bleary-eyed and bleary-brained.
Reminds me of when I attended the UK launch presentation of Intel's i860. With it's parallel execution of integer and float ops, its pipelined execution, its assortment of multiply-add style instructions. It could hit 66 MFLOPS (huge at the time) only problem was Intel did not know how to code it to do that. Took another company to show them !
Looks like you might have just saved my one cog 6809 emulation. Currently it uses a lot of overlays to run op emulation codes which are mostly straight line (no bends to slow down). This could save the space used for overlay loading, which is very tight now, and give a tad of a speed gain.
Time for some experiments.
▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔
For me, the past is not over yet.
As for timing critical stuff, you could always jump back to normal LMM for that section! [noparse]:D[/noparse]
▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔
http://www.propgfx.co.uk/forum/·home of the PropGFX Lite
·
And with 120MHz overclocking giving another 50% gain
▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔
Links to other interesting threads:
· Home of the MultiBladeProps: TriBladeProp, RamBlade, TwinBlade,·SixBlade, website
· Single Board Computer:·3 Propeller ICs·and a·TriBladeProp board (ZiCog Z80 Emulator)
· Prop Tools under Development or Completed (Index)
· Emulators: Micros eg Altair, and Terminals eg VT100 (Index) ZiCog (Z80), MoCog (6809)
· Search the Propeller forums (via Google)
My cruising website is: ·www.bluemagic.biz·· MultiBladeProp is: www.bluemagic.biz/cluso.htm
For "straight line" code that is, overlays will surely be quicker if there are tight loops in there.
▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔
For me, the past is not over yet.
At first I "got it" but in the morning before a cup o' joe I was suffering riddle amnesia. What is wrong with the following picture?
In the first line is the Bill's original LMM kernel, very straightforward steps by 4 through the longs in the hub.
Second is the picture you have painted for the "not reversed" fast LMM. Leapfroging in the RDs but sequential in execution.
Now the dilemma, a source of confusion for the bleary eyed. Third is the actual calculation of the PC, which involves pointing to the last byte of a long, not the first byte, correct? Does this work because the Prop automatically truncates the address of a long so that the RDLONG does in fact fetch the correct long and not some weird offset value?
Forth in the diagram is the reverse model, same issue.
▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔
Tracy Allen
www.emesystems.com
-Phil
CON _clkmode = xtal1 + pll16x _xinfreq = 5_000_000 PUB Start | rslt cognew(@fast_lmm, @test_code) DAT '-------[noparse][[/noparse]Normal LMM Kernel]-------------------------------------------------- org 0 norm_lmm mov nbase_addr,par 'Get the base address of the code. mov npc,par 'PC is base address to start. lmm_loop rdlong instr,npc 'Read the next instruction. add npc,#4 'Increment the PC. instr long 0-0 'Execute the instruction. jmp #lmm_loop 'Loop back for next instruction. njump rdlong npc,npc 'Long jump: address in next instr. add npc,nbase_addr 'Add relative address to base address. jmp #lmm_loop 'Resume with new address. njump_ret long 0-0 'Dummy needed to accommodate CALL. nbase_addr res 1 npc res 1 '-------[noparse][[/noparse]Quad LMM Kernel]---------------------------------------------------- org 0 quad_lmm mov qbase_addr,par 'Get the base address of the code. mov qpc,par 'PC is base address to start. qlmm_loop rdlong instra,qpc 'Read the next instruction. add qpc,#4 'Increment the PC. instra long 0-0 'Execute the instruction. rdlong instrb,qpc 'Read the next instruction. add qpc,#4 'Increment the PC. instrb long 0-0 'Execute the instruction. rdlong instrc,qpc 'Read the next instruction. add qpc,#4 'Increment the PC. instrc long 0-0 'Execute the instruction. rdlong instrd,qpc 'Read the next instruction. add qpc,#4 'Increment the PC. instrd long 0-0 'Execute the instruction. jmp #qlmm_loop 'Loop back for next instruction. qjump rdlong qpc,qpc 'Long jump: address in next instr. add qpc,qbase_addr 'Add relative address to base address. jmp #qlmm_loop 'Resume with new address. qjump_ret long 0-0 'Dummy needed to accommodate CALL. qbase_addr res 1 qpc res 1 '-------[noparse][[/noparse]Fast LMM Kernel]---------------------------------------------------- org 0 fast_lmm mov fbase_addr,par 'Get the base address of the code. add fbase_addr,#4 'Pre increment to second instruction. mov fpc,fbase_addr 'PC is base address to start. flush rdlong instr2,fpc 'Preload pipe with second instruciton. sub fpc,#1 'Point back to first instr, plus 3 bytes. pipe rdlong instr1,fpc 'Read PC instruction. add fpc,#9 'Point to PC+3 instruction. instr1 long 0-0 'Execute PC instruction. rdlong instr2,fpc 'Read PC+3 instruction. instr2 long 0-0 'Execute PC+1 instruction. djnz fpc,#pipe 'Point to PC+2 instruction. fjump mov fpc,instr2 add fpc,fbase_addr jmp #flush { Old (improved) fjump code. fjump cmp fjump_ret,#instr1+1 wz 'Where did the CALL come from? if_z mov fpc,instr2 ' instr1: Jump target is in instr2 if_nz sub fpc,#1 ' instr2: Need to read jump target from hub. if_nz rdlong fpc,fpc ' Get it. add fpc,fbase_addr 'Add base address. jmp #flush 'Go back and restart the pipeline. End of old fjump code. } fjump_ret long 0-0 'Contains address of the CALL. (Do not use RET!) fbase_addr res 1 fpc res 1 '-------[noparse][[/noparse]LMM Test Code]-------------------------------------------------------- org 0 test_code mov dira,#7 :loop mov outa,#1 mov outa,#2 mov outa,#3 mov outa,#4 mov outa,#5 mov outa,#6 mov outa,#7 mov outa,#0 nop 'Kept in for accurate comparison with prior tests. call #fjump 'Change to #njump for normal LMM; #qjump for quad LMM. long :loop<<2,:loop<<2 'Need to include loop target twice.Here's an image of the test results for the fast LMM:
Here's the same program run with Bill's quad LMM:
The fast LMM is faster in the straightaway, with the quad LMM showing a slight (50ns) advantage in the turns.
-Phil
▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔
Please use mikronauts _at_ gmail _dot_ com to contact me off-forum, my PM is almost totally full
Morpheus & Mem+ Advanced dual Propeller SBC with XMM and 256 Color VGA - PCB, kit, A&T available NOW!
www.mikronauts.com - my site 6.250MHz custom Crystals for running Propellers at 100MHz
Las - Large model assembler for the Propeller Largos - a feature full nano operating system for the Propeller
So in essence, I would expect Overlay code to be faster in overall execution than LMM because code inherrently has loops and this is where Overlays shines. However, Overlay coding is more complex than LMM as it has to fit within a sub-block in the cog. Therefore, there is no doubt a place for both systems.
Now, knowing what you are after for emulations, I would expect that LMM will definately have its place in the emulator where code is inline, as will overlays where loops are used. The LMM only takes a few longs anyway. So, I would expect you should use both methods.
▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔
Links to other interesting threads:
· Home of the MultiBladeProps: TriBladeProp, RamBlade, TwinBlade,·SixBlade, website
· Single Board Computer:·3 Propeller ICs·and a·TriBladeProp board (ZiCog Z80 Emulator)
· Prop Tools under Development or Completed (Index)
· Emulators: Micros eg Altair, and Terminals eg VT100 (Index) ZiCog (Z80), MoCog (6809)
· Search the Propeller forums (via Google)
My cruising website is: ·www.bluemagic.biz·· MultiBladeProp is: www.bluemagic.biz/cluso.htm
The MoCog 6809 emulator is VERY tight on space. Already it has many overlaid ops. In fact I've stopped work on it for a long while as it looks like it won't fit, there is so much code that needs to be "resident".
So, I was looking at this new LMM technique as a way of saving space, the overlay area in COG is no longer required, whilst at the same time having comparable speed. It helps that most of the code that would be LMMed is "straight line ", loop free.
However, the issue is that, unlike Z80, all 6809 ops are heavily used so overlays or LMM are a real speed killer.
Yesterday I woke up with a possible solution in mind:
1) Forget overlays and LMM and the single COG goal.
2) Load all the functions that are currently overlaid into a second COG with a small loop of code that is looking for commands from the first COG.
3) Arrange that our op vector table can vector us to those routines in the second COG and command it to go.
BINGO the equivalent of overlays put they are all preloaded into the second COG waiting for "remote" invocation.
This is now a topic for another thread.
▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔
For me, the past is not over yet.
▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔
Links to other interesting threads:
· Home of the MultiBladeProps: TriBladeProp, RamBlade, TwinBlade,·SixBlade, website
· Single Board Computer:·3 Propeller ICs·and a·TriBladeProp board (ZiCog Z80 Emulator)
· Prop Tools under Development or Completed (Index)
· Emulators: Micros eg Altair, and Terminals eg VT100 (Index) ZiCog (Z80), MoCog (6809)
· Search the Propeller forums (via Google)
My cruising website is: ·www.bluemagic.biz·· MultiBladeProp is: www.bluemagic.biz/cluso.htm
That multi-cog approach relied on all COGs inspecting all opcodes and the ones who could do the work did it.
Now it occurs to me that we should be able to load a bunch of opcode handlers into a second COG and have the first COGs dispatcher decode the op-codes and get the address in the second COG of the required handler from the dispatch table. Then stuff that vector somewhere for the second COG to pick up and run with.
Sort of a COG to COG procedure call, the single dispatch table look up can find a vector to a procedure in the current COG or another one. No duplicate decoding and such going on, not much time wasted in handing over from COG to COG. A lot less than loading an overlay anyway.
Not sure if we have discussed that idea before.
I don
▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔
For me, the past is not over yet.
The best way is to get your 6809 emulator running properly. Hopefully by then I will have time to help you get it running fast
▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔
Links to other interesting threads:
· Home of the MultiBladeProps: TriBladeProp, RamBlade, TwinBlade,·SixBlade, website
· Single Board Computer:·3 Propeller ICs·and a·TriBladeProp board (ZiCog Z80 Emulator)
· Prop Tools under Development or Completed (Index)
· Emulators: Micros eg Altair, and Terminals eg VT100 (Index) ZiCog (Z80), MoCog (6809)
· Search the Propeller forums (via Google)
My cruising website is: ·www.bluemagic.biz·· MultiBladeProp is: www.bluemagic.biz/cluso.htm
I don't remember any such discussion, but then I have a lot of gray hair as well...
Anyway this will take a while as I'm pretty busy now, just time to ponder it occasionally.
▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔
For me, the past is not over yet.
Anyway, just put the code in overlays for now when you get time. Maybe we can chat later when I have time as well.
▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔
Links to other interesting threads:
· Home of the MultiBladeProps: TriBladeProp, RamBlade, TwinBlade,·SixBlade, website
· Single Board Computer:·3 Propeller ICs·and a·TriBladeProp board (ZiCog Z80 Emulator)
· Prop Tools under Development or Completed (Index)
· Emulators: Micros eg Altair, and Terminals eg VT100 (Index) ZiCog (Z80), MoCog (6809)
· Search the Propeller forums (via Google)
My cruising website is: ·www.bluemagic.biz·· MultiBladeProp is: www.bluemagic.biz/cluso.htm
-Phil
'-------[Fast LMM Kernel]---------------------------------------------------- org 0 fast_lmm mov fbase_addr,par 'Get the base address of the code. add fbase_addr,#4 flush add fpc,fbase_addr 'PC is base address to start. rdlong instr2,fpc 'Preload pipe with next instruciton. sub fpc,#1 'Point back to first instr, plus 3 bytes. pipe rdlong instr1,fpc 'Read PC instruction. add fpc,#9 'Point to PC+3 instruction. instr1 long 0-0 'Execute PC instruction. rdlong instr2,fpc 'Read PC+3 instruction. instr2 long 0-0 'Execute PC+1 instruction. djnz fpc,#pipe 'Point to PC+2 instruction. fjump add fjump_ret,#one-(instr1+1) jmp fjump_ret fjump_ret long 0-0 'instr1+1 or instr2+1 ' two - one == (instr2+1) - (instr1+1) one mov fpc,instr2 jmp #flush two sub fpc,#1 rdlong fpc,fpc jmp #flush fpc long 0 fbase_addr res 1 fitAnd while I'm at it, a counter version as well:org 0 ctrx_lmm movi ctrb, #%0_11111_000 ' LOGIC always mov frqb, #1 eins {embedded} call #cjump ' -4 _one rdlong eins, phsb ' +0 = base + 6f zwei {embedded} long 0 ' +8 _two add phsb, #8 ' -4 main rdlong zwei, phsb ' +0 = base + 2f tjnz phsb, #eins wr ' +8 ' eins zwei cjump xor cjump_ret, #_one ^ _two ' swap targets +0 = -4 sub cjump_ret, #1 ' final source +4 +0 = mov phsb, par ' base address +8 +4 cjump_ret add phsb, 0-0 ' +offset -4 +8 rdlong eins, phsb ' +0 = insn at jump target add phsb, #4 ' +8 tjnz phsb, #main wr ' -4 fitI assume is has something to do with the phsb shadow register, but I can't puzzle out how it is being used.
Thanks,
Bean
DAT eins nop ' -4 _one [COLOR="blue"]rdlong eins, phsb[/COLOR] ' +0 = base + 6f zwei nop ' +8 _two add phsb, #8 ' -4 main [COLOR="#FFA500"]rdlong zwei, phsb[/COLOR] ' +0 = base + 2f tjnz phsb, #eins wr ' +8The code is setup so that the actual LMM insn fetch starts with the second rdlong. Lets also assume that phsb is set to some non-zero 4n address. This means - as indicated by the comment - that the insn is read from base_4n + 2*frqb (which for a rdlong equals base_4n). Now assume for a moment that the tjnz is a normal jump insn. At the time we execute the first rdlong phsb would be base_4n + (2+16)*frqb (next hub window). Which is not what we want. Put back the tjnz. Because shadow[phsb] is non-zero we still get the jump, OK. Writing the result (wr) will update shadow[phsb] with itself (base_4n). This also resets counter[phsb] to base_4n in the last cycle of tjnz. IOW now the first rdlong will read the next insn from base_4n + 6*frqb (effectively base_4n + 4). From there we simply add 8 to the base address and do this all again.Note, the default for tj[n]z is nr.
Nicely done, Kuroneko-san!
-Phil