

16 Bit External Memory Hardware Prototype?
 jazzed
Posts: 11,803
jazzed
Posts: 11,803
Hello hardware guys:
I've given some thought to a·16 bit parallel bus external memory XMM Propeller board and am looking for someone
who might take up the challenge. The memory could be used for video buffer or LMM code storage.
Here's the idea. Produce a PCB with Propeller (or two), optional basic IO connectors·like TV (VGA would need too
many pins), mouse, keyboard, audio jack, SD card connector, spin studio header(s), and up to 2MB of 16 bit wide
SRAM (4 512Kx8) or Flash.
Why does 16 bits make sense? Application and speed.
Two main applications are video buffer and LMM code. Video attributes are at least 16 bits wide. LMM instruction
and offset (text) fetch is always 32 bits wide in the ICC kernel and have no need to be anything but long for
instructions or program constants. This means that byte wide access will never happen for these applications.
Speed can come because of·two factors. The first is obvious in that 16 bits can be transfered at once. The second
is a little more subtle and takes patience. I've found that fetching a long or 32 bits using a byte-wide non-latched
address and data path takes at least 17 instructions (someone might do better) for 3.3V 50ns SRAM (20 instructions
for 5V SRAM because of series RC delay).· Fetching 32 bits using a full address/data latch design that would allow
32MB of memory would take at least 15 instructions. Fetching 32 bits using a partial address/data latch design with
up to 2MB memory could take as few as 10 instructions. So an almost·2x read32 XMM fetch·improvement with
16 bit over 8 bit access is possible.
In this case there are 4 pins left open on the primary XMM·Propeller that can be used for program load and boot from
SD card, SD ethernet, or whatever purpose including TV display.
Of course the primary could load the XMM from a secondary Propeller attached device. The second propeller could be
connected for communications (using any propeller·pins but most likely 12 pins P16-27) if the LMM interpreter cog can
be stalled for the transaction(s) and atomically send messages·between the primary Propeller's XMM bus accesses.
Using inter-propeller messaging IPM [noparse]:)[/noparse], many devices can be connected to 16 pins the secondary Propeller.
I will post a block diagram if necessary to more clearly communicate the connection requirements. Attached is an Eagle
schematic that shows most of the interconnects if you can see it for a 1MB SRAM XMM. Some notes describe work TBD
on the schematic.
Any takers?
▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔
--Steve
Propalyzer: Propeller PC Logic Analyzer
http://forums.parallax.com/showthread.php?p=788230
I've given some thought to a·16 bit parallel bus external memory XMM Propeller board and am looking for someone
who might take up the challenge. The memory could be used for video buffer or LMM code storage.
Here's the idea. Produce a PCB with Propeller (or two), optional basic IO connectors·like TV (VGA would need too
many pins), mouse, keyboard, audio jack, SD card connector, spin studio header(s), and up to 2MB of 16 bit wide
SRAM (4 512Kx8) or Flash.
Why does 16 bits make sense? Application and speed.
Two main applications are video buffer and LMM code. Video attributes are at least 16 bits wide. LMM instruction
and offset (text) fetch is always 32 bits wide in the ICC kernel and have no need to be anything but long for
instructions or program constants. This means that byte wide access will never happen for these applications.
Speed can come because of·two factors. The first is obvious in that 16 bits can be transfered at once. The second
is a little more subtle and takes patience. I've found that fetching a long or 32 bits using a byte-wide non-latched
address and data path takes at least 17 instructions (someone might do better) for 3.3V 50ns SRAM (20 instructions
for 5V SRAM because of series RC delay).· Fetching 32 bits using a full address/data latch design that would allow
32MB of memory would take at least 15 instructions. Fetching 32 bits using a partial address/data latch design with
up to 2MB memory could take as few as 10 instructions. So an almost·2x read32 XMM fetch·improvement with
16 bit over 8 bit access is possible.
'Initialize XMM kernel fetch for read with SIO (0xc0000000), 'WE* (0x20000000) pulled up, and data (0x0000ffff) as inputs. 'Initialize addrs (0x0fff0000) and ALE (0x10000000) as outputs. '//call with word-wide address (0x000fffff) in outa reg read32: 1 shl outa, #8 '// 0x0fffff00 ... upper 12 addr bits ready 2 or outa, ALE '// 0x1fffff00 ... latch upper addr bits 3 shl outa, #8 '// 0xffff0000 ... lower 8 addr bits on bus for read 4 mov tmp2, ina '// get even 16 bit word 5 add outa, K10000 '// odd address 6 shl temp, #16 '// make room for odd word and wait for bus 7 mov tmp2, ina '// get odd 16 bit word 8 or temp, tmp2 '// compose word 9 ror temp, #16 '// swap words to right place 10 ret
In this case there are 4 pins left open on the primary XMM·Propeller that can be used for program load and boot from
SD card, SD ethernet, or whatever purpose including TV display.
Of course the primary could load the XMM from a secondary Propeller attached device. The second propeller could be
connected for communications (using any propeller·pins but most likely 12 pins P16-27) if the LMM interpreter cog can
be stalled for the transaction(s) and atomically send messages·between the primary Propeller's XMM bus accesses.
Using inter-propeller messaging IPM [noparse]:)[/noparse], many devices can be connected to 16 pins the secondary Propeller.
I will post a block diagram if necessary to more clearly communicate the connection requirements. Attached is an Eagle
schematic that shows most of the interconnects if you can see it for a 1MB SRAM XMM. Some notes describe work TBD
on the schematic.
Any takers?
▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔
--Steve
Propalyzer: Propeller PC Logic Analyzer
http://forums.parallax.com/showthread.php?p=788230
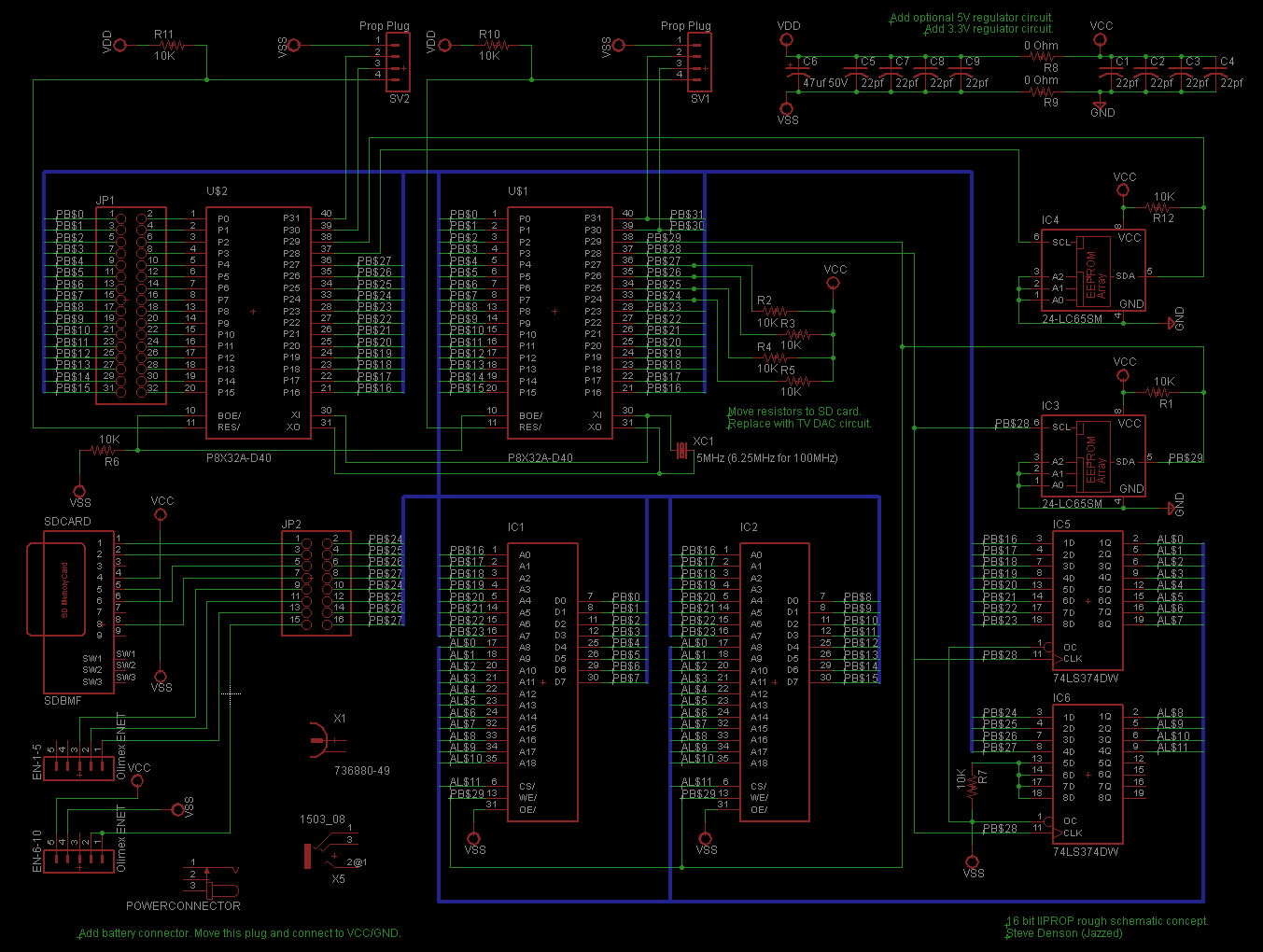
1353 x 1020 - 110K
Comments
While you are showing a 50% reduction in access, this is only part of the time in the whole program execution time issue. Depending on how many other instructions are being executed, this improvement could reduce significantly when scaled over the whole program.
If you require byte access (for other style programs) you have major penalty hit, because each access has to latch the address, and to use the other half of the memory you have to shift half of the bytes read. I would do the design if I could see the benefit over my TriBladeProp, but at present I cannot. I have everything you are asking for and more on my TriBladeProp, with the exception of audio. While I only have 1MB on #2 it has provison for 4MB (v.expensive) and as you know we are running PropCMD and CPM now. There is provision for 2x spin studio connectors on #3.
There is also provision for 512KB on #1 (video) with VGA. So far, no-one seems interested in this for video buffers, or anything else for that matter.
So far, the interest in my TriBladeProp has a limited audience, mainly to the few active members. This may change.
Steve, this is not meant as criticism - great you are thinking about the issues of RAM. So I hope this helps. Maybe you might try the TriBladeProp and see where that leads? If there seems enough interest and the results proved, then I will do the design.
▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔
Links to other interesting threads:
· Home of the MultiBladeProps: TriBladeProp, SixBladeProp, website (Multiple propeller pcbs)
· Single Board Computer:·3 Propeller ICs·and a·TriBladeProp board (ZiCog Z80 Emulator)
· Prop Tools under Development or Completed (Index)
· Emulators: Micros eg Altair, and Terminals eg VT100 (Index)
· Search the Propeller forums (via Google)
My cruising website is: ·www.bluemagic.biz·· MultiBladeProp is: www.bluemagic.biz/cluso.htm
1MB yes, the 2MB picture is hard to read. I will certainly be buying one of your boards. I'm just a little distracted [noparse]:)[/noparse]
The 50% reduction in access time for X-LMM is very helpful. Using the byte wide access method with data on bits P0..7 and address on bits P8..28, total instruction to instruction fetch with ICC averages 1.4us (wait states added for my slow SRAM interface). Of this 1.4us the 32 bit fetch takes 1us. Moving to a 3.3V SRAM interface would reduce the fetch time to 850ns. With the 16 bit interface and 3.3V SRAM as shown fetch time will be 500ns. The instruction to instruction fetch average will then be 900ns.
So in terms of LIPS "LMM Instructions Per Second"
Of course for a big application (and cheap CAE software), I'm tempted to just use Propeller as a peripheral/co-processor for an ARM CPU. That would be far simpler, cheaper, and faster. Shrug shoulders.
Thanks.
▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔
--Steve
Propalyzer: Propeller PC Logic Analyzer
http://forums.parallax.com/showthread.php?p=788230