

Z80 emulator object in 4 COGS. !!! PROJECT CANCELLED !!!
 heater
Posts: 3,370
heater
Posts: 3,370
!!!! THIS PROJECT IS CANCELLED !!!! See end of thread for details.
Announcing i8080_emu an 8080/8085 emulator object running in 4 COGS. Please find attached.
OK, the title of this thread is a bit cheeky at the moment because this is not a Z80 emulator. Not yet, it could be soon. Read on...
What is it:
Well having squeezed as much juice out of one cog for 8080 emulation as I could it was time to throw caution to the wind and totally rewrite the thing to use four COGS in a hope that:
1. It would gain some speed.
2. Would make the code understandable.
3. Would make it expandable to full Z80.
4. It would be a reusable object that can be incorporated into other simulators, CP/M, ZX81, Nascom. Or otherwise used.
Status:
Pretty much all 8080 opcodes are coded.
Only about 20% of them have had any kind of testing yet.
Currently in runs in test harness executing a loop of four instructions, each of which is handled by a different cog.
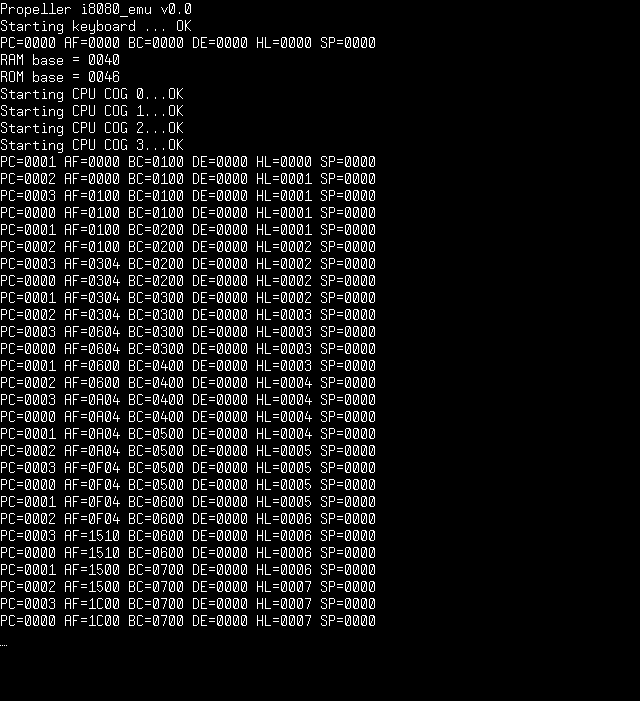
It can be run on a plain Prop Demo board talking to PropTerminal where you will see the execution in progress as per the attached screen shot.
Just compile i8080_emu as the top object.
What next:
Over the next few days I will test all the other op codes and get it to pass the CPU diagnostics I have, after that I want to get it running CP/M (Didn't you know)
HELP NEEDED:
I'm hoping for some volunteers to step forward and contribute the extra Z80 op code handlers !! There is quite a lot of free space in the 4 COGs remaining and we could easily go to 5 if need be.
Perhaps someone could look over the code and suggest any speed ups that come to mind. In the dispatch loop for example. Would be nice to find a way to not have to have 4 dispatch tables. Would be nice to be able to reclaim the COG code space in HUB for 8080 memory.
Also if any one has external RAM interfaces working it will be much easier to add them to this emulator than the one in PropAltair.
This launch may be a bit premature as it is not fully working yet but as Linus says "Release early and release often"
After 4 days solid hacking on this I'm going to crack open a couple of bottles of Chardonnay so don't expect any post from here for a while [noparse]:)[/noparse]
Cheers all.
▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔
For me, the past is not over yet.
Post Edited (heater) : 2/27/2009 10:13:56 PM GMT
Announcing i8080_emu an 8080/8085 emulator object running in 4 COGS. Please find attached.
OK, the title of this thread is a bit cheeky at the moment because this is not a Z80 emulator. Not yet, it could be soon. Read on...
What is it:
Well having squeezed as much juice out of one cog for 8080 emulation as I could it was time to throw caution to the wind and totally rewrite the thing to use four COGS in a hope that:
1. It would gain some speed.
2. Would make the code understandable.
3. Would make it expandable to full Z80.
4. It would be a reusable object that can be incorporated into other simulators, CP/M, ZX81, Nascom. Or otherwise used.
Status:
Pretty much all 8080 opcodes are coded.
Only about 20% of them have had any kind of testing yet.
Currently in runs in test harness executing a loop of four instructions, each of which is handled by a different cog.
It can be run on a plain Prop Demo board talking to PropTerminal where you will see the execution in progress as per the attached screen shot.
Just compile i8080_emu as the top object.
What next:
Over the next few days I will test all the other op codes and get it to pass the CPU diagnostics I have, after that I want to get it running CP/M (Didn't you know)
HELP NEEDED:
I'm hoping for some volunteers to step forward and contribute the extra Z80 op code handlers !! There is quite a lot of free space in the 4 COGs remaining and we could easily go to 5 if need be.
Perhaps someone could look over the code and suggest any speed ups that come to mind. In the dispatch loop for example. Would be nice to find a way to not have to have 4 dispatch tables. Would be nice to be able to reclaim the COG code space in HUB for 8080 memory.
Also if any one has external RAM interfaces working it will be much easier to add them to this emulator than the one in PropAltair.
This launch may be a bit premature as it is not fully working yet but as Linus says "Release early and release often"
After 4 days solid hacking on this I'm going to crack open a couple of bottles of Chardonnay so don't expect any post from here for a while [noparse]:)[/noparse]
Cheers all.
▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔
For me, the past is not over yet.
Post Edited (heater) : 2/27/2009 10:13:56 PM GMT
640 x 701 - 18K
zip
114K
Comments
I am looking forward to Cluso finishing his six cog board design to make this project finished.
▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔
JMH - Electronics: Engineer - Programming: Professional
Post Edited (Quantum) : 1/27/2009 7:49:54 PM GMT
Your driver code is small enough to put a copy into each of the 4 emulator COGS.
There could be a dedicated SRAM driver COG with prefetch of the instructions etc, I can't see how it would gain much speed though.
Still its the quickest simplest way to a add RAM to a demo board. Isn't it?
▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔
For me, the past is not over yet.
btw, I know it's only a one long saving, but it's a one instruction speed increase [noparse]:D[/noparse]
halt rdword data_16, cpu_control '\ cmp data_16, #0 wz ' | DEBUG CODE if_z jmp #halt '/can be replaced by
halt rdword data_16, cpu_control wz '\ if_z jmp #halt '/also, I'd probably inline alu_inc_dec_flags to both alu_increment and alu_decrement, might take more, but will save two instructions processing time [noparse]:D[/noparse]
Also, read_memory_word
I was initially going to say change
read_memory_word call #read_memory_byte 'Read the low byte mov data_16, data_8 ror data_16, #8 add address, #1 call #read_memory_byte 'Read the high byte or data_16, data_8 rol data_16, #8 read_memory_word_ret retto
read_memory_word call #read_memory_byte 'Read the low byte mov data_16, data_8 ' ror data_16, #8 add address, #1 call #read_memory_byte 'Read the high byte rol data_8,#8 or data_16, data_8 ' rol data_16, #8 read_memory_word_ret retagain that'll save one instruction in terms of speed, then I thought how about this instead!
read_memory_word call #read_memory_byte 'Read the low byte mov data_16, data_8 ' add address, #1 ' don't think you need this any more, due to this method so removed it! add hub_pointer,#1 rdbyte data_8,hub_pointer rol data_8,#8 or data_16, data_8 read_memory_word_ret retMy thinking behind this, is because the ram will be in a continous block, as will the ROM [noparse]:D[/noparse]
Can do the same kind of thing with write too [noparse]:D[/noparse]
Are they ok changes for you so far?
▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔
http://www.propgfx.co.uk/forum/·home of the PropGFX Lite
·
▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔
http://www.propgfx.co.uk/forum/·home of the PropGFX Lite
·
The code I timed is as published but with the "DEBUG" stuff commented out running around that 4 instruction test loop.
I am only getting about 310 thousand instructions per second (KIPS?). Timed with a wrist watch.
My record for the single cog emulator was 380KIPS which only went down to 350KIPS after a moved some ops to LMM when fixing flag setting issues.
What is going on?
A quick count up of PASM instructions executed for one iteration of the loop is:
INR B - 38 (inc 7 HUB ops)
MOV A,L - 22 (inc 5 HUB ops)
ANA A - 42 (inc 8 HUB ops)
JMP 0 - 46 (inc 5 HUB ops)
Total - 148 (inc 25 Hub ops)
Average PASM instructions per 8080 op = 148 / 4 = 37.
My Prop is running at 80Mhz or 20 MIPs so 8080 should be 20,000,000/37 = 540540 emulated ops per second.
Of course we have to account for the extra clocks of all the HUB ops, not sure just now what the numbers are there.
Can the HUB ops really be eating so much time ?
I could save some instructions, as Baggers suggests, and in line some functions but lets say that saves 20 instructions per the 8080 test loop iteration. That's only about 13% gain. I will in line things when I'm done with testing, just now it's easier to debug them once !
Is there something screwy about my dispatch loop or COG synchronization ?
Or is it that its just plain hard work to get the 8080 flags set.?
@Baggers: Feel free to add Z80 ops to this when you are done with 6502 [noparse]:)[/noparse]
▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔
For me, the past is not over yet.
▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔
For me, the past is not over yet.
Heater, this method gains over LMM as LMM reads hub for instructions as well as decoding. you're only in a small program size at the moment, when you do a full Z80 it would be mostly in HUB-RAM.
As for some other optimisations, which we're doing with the 6502 one, is because of the fact that we have multiple cogs handling it, the second ( 1st free cog, ie the first one that isn't decoding current opcode ) will get the next 3 bytes ( after opcode and only next 2 in the case of 6502 ) and store it in a hub-ram long, so the opcodecog can retreive it as a single hub-op.
if you have enough cogs, this could even be in it's own cog, to makeit even faster, ie do it while the opcodecog gets the instructio jump table stuff sorted. [noparse]:)[/noparse]
▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔
http://www.propgfx.co.uk/forum/·home of the PropGFX Lite
·
In fact, thinking about it, it may just be sensible to read ALL the registers as LONGS, with a further 2 HUB ops, when ever a COG takes over, only writing them out again when it releases control. Then, as long as an 8080 instruction sequence happens to be all in the same COG everything flies around at COG speed !
Sorry, just thinking aloud to myself here. But any suggestions welcome.
▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔
For me, the past is not over yet.
AFPC is a good option though [noparse]:)[/noparse]
▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔
http://www.propgfx.co.uk/forum/·home of the PropGFX Lite
·
Also with a bit of profiling it would make sense to put the most used opcodes into one or two COGs. Thats not going to happen soon either.
I think I've realized a subtle potential bug in my COG swapping mechanism. Scheduling a COG to do something relies on the program counter changing.
A COG in the "waiting" state is constantly checking the program counter. If the PC changes it then goes off to look up the op to see if its for him(her?). Well, what if there was some self modifying 8080 code that changed the opcode at the current program counter location, such that the waiting COG should actually do it, but did not change the PC? Then all COGs are waiting and we are hung!
Impossible you might think. What about this:
0100 CALL 0100
0101 ...
0102 ...
Where the stack pointer is pointing at location 0102 or 0101. What happens?
At the end of CALL the PC is still 0100 but the return address (0101) has been pushed
over the CALL instruction changing it to LXI B which the waiting COG should now execute. The PC has not changed so nothing happens !
I can't think of any other 8080 code that would cause this (can you?) and any program written like that deserves to hang anyway so I'll let it be for now.
▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔
For me, the past is not over yet.
I think what you are saying is: that when executing an op it would be nice to just rdword or rdlong from a fixed location to pick up the immediate bytes rather than having to call some function that does it, checking for RAM/ROM, checking for RAM limits and assembling bytes into words etc.
To do this we get another COG, lets say a dedicated COG, to watch for changes in the Program Counter and then when it sees a change does all the immediate byte reading stuff and dumps them into said fixed location. Hopefully it can do all that before the executing COG gets to the point that it needs them !
So far so good I think.
Now what if there is no dedicated COG? Is it so that the COG that is just giving up execution can do this prior to entering it's idle wait loop?
Sounds like a bugger to keep up. I'll have to start cycle counting.
Just now my COGs are only synchronized, if that's the right word for it, by the fact that they start op code executing when the PC changes. Is it necessary to be more clever about it?
▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔
For me, the past is not over yet.
▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔
Links to other interesting threads:
· Prop Tools under Development or Completed (Index)
· Emulators (Micros eg Altair, and Terminals eg VT100) - index
· Search the Propeller forums (via Google)
My cruising website is: ·www.bluemagic.biz
I'm sure I can get the 8080 logic right, but when it comes to optimization any help is appreciated. Also anyone with enthusiasm for the full up Z80 extension would be great to have on board.
Just now I'm putting in the tweaks that Baggers suggested, before getting on with testing, as they are little changes all around the opcodes.
▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔
For me, the past is not over yet.
You don't need to be more clever about the sync being on PC change, it also means that if we get them all inside the correct speeds, we can do what I planned for 6502 emu, use one of the not processing currentop cogs to do a get cycle count and perform the waitcnt [noparse]:D[/noparse] ( although I had each cog writing a zero byte, to say Done! then they all read the long til it's zero. then write nonzero long with a not processing currentop cog )
as for the immediate bytes are you talking about getword? ( just increase the hubpointer and get next byte [noparse]:D[/noparse] since all ram and rom in continuous )
or are you talking about the instruction pre-fetch? ignore me, as they would all have to go through the jump table code, unless you break cogs into ED etc instructions, then if first byte is ED and your not the ED cog, then quickly prescan 2 following bytes at hubaddress+2 and put them into a word in hubram, so EDcog can read it in as a word. not sure if this would be faster or not,with the compare etc. but it was an idea, but if it's a seperate cog, ie none opcode cog, that sits and when instruction grab starts, it reads not the opcode byte, but the three following bytes, and puts them into a long ready for the opcode cogs to grab, as that would be fast enough while the opcode cogs access the jump table.
▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔
http://www.propgfx.co.uk/forum/·home of the PropGFX Lite
·
In the 8080/85 all opcodes are uniquely determined by a one byte instruction. Some instructions have one or two immediate data bytes following.
So the way I see it is:
1. A COG that is just giving up control, as it were, writes out the PC to trigger the next COG into action.
2. The COG having given up control can read two bytes of immediate data, quickly using the hub_pointer as you suggest.
3. Those two bytes get dumped into a fixed location.
4. That last COG now enters it's idle wait loop.
5. The COG that takes over can now read the immediate data , if required, from the fixed location super quick.
Of course a COG may want to execute two or more instructions, without rescheduling, that require immediate data and only the first one will have the pre-fetched data. So there must be a flag to indicate that pre-fetched data has been used and a real fetch has to now be made. Only a couple of instructions.
So the pre-fetch only works once per COG schedule period, but given the way instructions are mixed up in programs that may be quite a lot of the time. So could be well worth doing. For example all the jumps and other control transfers that require immediate words and are in one COG. In normal code there will be mostly other instructions between jumps etc so a COG reschedule will occur to do the jump and the pre-fetch works.
That's assuming we have time between step 1) above and the need for immediate data in step 5)
Now I have not looked at Z80 so much yet with multi byte instructions but they may need subtly different pre-fetch handling if it is workable at all. Perhaps requiring a dedicated pre-fetch COG as you say.
What's all this about waitcnt and "zero bytes"? Is this some kind of effort towards accurate instruction timing?
▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔
For me, the past is not over yet.
That is:
1. A COG giving up control writes out the PC and sets a pin TRUE and then FALSE.
2. COGs don't have an idle loop, instead they use waitpe to look for that pulse and then proceed to read the PC etc etc.
Seems to be that with the idle wait loop during compare and jump a HUB slot may be missed... I'm not sure how this works out but a waitpe is only one instruction so must be better[noparse]:)[/noparse] no?
Also means that idle COGs are in a low power state as a bonus!
▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔
For me, the past is not over yet.
thats basically what the zero byte writes are for etc. waits til ALL cogs are ready! but this 1PIN will be lots faster [noparse]:)[/noparse]
▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔
http://www.propgfx.co.uk/forum/·home of the PropGFX Lite
·
If each type was dealt with by a different COG then the fetch loop in each COG could possibly be optimised to hit the HUB sweet spot, fetching both the opcode and any following data.
Or maybe I'm just barking up the wrong tree. I'll happily admit to being very new at this Propeller lark and am still trying to unlearn 30 years of 'classic' micro designs.
0. A COG starting on emulation (gaining control as it were) sets the pin TRUE
1. A COG giving up control writes out the PC and sets the pin FALSE.
2. COGs don't have an idle loop, instead they use waitpe to look for the pin going FALSE and then proceed to read the PC etc etc.
3. If the new PC is not a instruction for you just go back to waitpe.
Basically the pin is a busy flag. Given that all the pin outputs from all the COGs are ORed together I think we are in business.
This sounds like it should quicker than any kind of polling wait loop, I just can't figure out exactly what the gain might be. Sounds like its worth one pin though.
@Brian: I think you have a good point about allocating opcodes to COGs depending on their needs and optimising the "run loop" accordingly. Which I will look into at some point. As this is my first pass at the problem I just divided the instruction set by 4 by opcode, as you say. Just to see how it fits. Also I decided that initially I would keep all 4 run loops identical so as not to get to confused when debugging/optimizing/changing it. As it turns out there is some sense in the distribution of ops that way, all the MOVs are in one COG, all the control transfers JMP,CALL etc are in one COG. Most of the arithmetic, logical ops are in one COG. In fact I did already move arithmetic ops with immediate operands to the "arithmetic" COG so as to use the same ALU subroutines.
As we are hoping to go to full Z80 emulation in the future, and I don't know so much about the needs ofZ80 yet, I will keep the run loops identical for now.
@mikedev. There is already an 8080 emulation running CP/M on the Propeller with emulated floppy disks in SD card:
PropAltair http://forums.parallax.com/showthread.php?p=711157. You can run it up on a Propeller Demo Board just to see, but it really needs external RAM for a useful 64K system...a topic of endless debate in itself. This multi COG version will be put into PropAlair when it's up and running properly.
▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔
For me, the past is not over yet.
I just included a frequency counter object in the build (From the counters appnote) and it tells me things are looking better.
Straightforward jumps (JMP) are happening at 714 thousand per second and register to register moves (MOV) at 750.
However register increments and adds are down at 380 thousand per second. Problem is when they are interleaved in the 8080 program the emulator thrashes betwen COGs and then its down to 280 thousand per second !!!!.
Given that jumps use two bytes of immediate data and are happening the quickest I don't think I should worry about immediate byte pre-fetching just yet. Rather the COG swapping needs looking at. And arithmetic ops.
How did you 6502 Guys get to a whole MIP ? As I think I read you did.
▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔
For me, the past is not over yet.
What I did was run the boot strap code on an Atari 400, time it, then do the same for the partial 6502 emulation. This confirmed the simple math used to size up how the emulation might be best done.
Baggars helped out with the thinking by computing the number of Propeller instructions that would fit into a 6502 cycle. From there, it's easy to trace the code path and see where it's slower or faster than the real deal. On single byte instructions it's right on the line, if maybe a bit over. On multi-byte ones, it's still way under.
The end result is on par with a 1Mhz 6502, which happens to be what the Apple is running. We've got to squeeze just a bit more speed out for a VCS. (the 96Mhz jump probably will deliver that!)
Right now, addressing issues and how to really use the COGs, with the pre-fetch ideas and such are being worked out before we build in all the opcodes.
And the addressing is in my court at the moment, so I best get back to coding stuff, so I can lob it back at Baggars!!
I agree with you on immediate mode stuff. Same for single byte opcodes. They need to be quick, but on the other hand, they don't need to do much. Best to just code them with the cleanest path, and save the complexity for the longer opcodes, where the time constraints are more roomy!! @ 1.1 Mhz emulated clock, a single clock cycle boiled down to 17 instructions @ 80 Mhz. (tight) Some of the longer 6502 instructions are 5 to 7 cycles. Much more roomy.
Given we need virtual addressing (Z-page and stack are at page 00 and 01 hard coded), a quick code path for that is essential. Looks like the best overall deal is to just assume RAM is linear, meaning a simple offset will do. Other troubles, depending on what is emulated boil down to address shadowing and decoding for memory mapped I/O's and such. If the CPU is exporting it's state, these things might be able to be moved into their COG's, where they apply to the virtual device being emulated.
Don't know yet.
Right now, the single byte opcodes are running right at the target speed. The longer ones are way faster. The net result on the partial CPU is faster overall execute speed. I'll bet your project is seeing a similar thing happen too.
▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔
Propeller Wiki: Share the coolness!
Chat in real time with other Propellerheads on IRC #propeller @ freenode.net
Safety Tip: Life is as good as YOU think it is!
Post Edited (potatohead) : 2/2/2009 12:21:15 AM GMT
1. Reading/writing the program counter, A register and Flags in one hit as LONG. Seems all the time gained by going to a long is lost by having to pack/unpack all the parts. (But it occurs to be now that writing A and Flags AFTER the PC as a word, during the "idle" time, may still be a gain)
2. Using a pin as a "signal" to trigger COG execution from waitpeq, actually I used one pin per COG but the code path length is the same, was slower than just doing a rdword on the PC and looking for change.
3. These speed ups that involve reading memory via just a HUB pointer of course do work BUT I want 64K RAM which means external RAM, which means all reads/writes will have to go through some access functions. So that optimization is not good in the long run.
4. Same goes for immediate data prefetch. With external RAM the prefetch will probably not arrive in time and worse still requires 2 COGS to be accessing external RAM at the same time which is not going to happen.
So I'm going to skip all this "premature optimization", as it has become known, and get back to finishing the opcodes and regression testing.
One final optimization, at least for plain the 8080 version, is to squeeze everything into 3 GOGs to reduce COG thrashing.
At least I'm up to PropAltair speeds on arithmetic ops and much faster on many others. The 16 bit ops should be way faster.
▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔
For me, the past is not over yet.
I seriously wondered about #1. Those kinds of ops are costly. From my experience, simple data structures are the way to go on the Prop. Your experience confirms that.
#2 is kind of surprising. I read that part and thought for sure it was going to be a boost.
#3. Bummer that! That's where I'm working right now. The code path gets long quick! We've been working with either, just an offset, which limits the RAM space, or a page table. The page table isn't too bad instruction wise, but it's a bit long for the single byte ops. It does have the advantage of being able to swap in RAM a page at a time, without the CPU emulation knowing about it. For those things where cycle exact does not matter, it might be the way to go. Your project seems to fit that criteria. Worst case is a fetch, outside the swapped in HUB addresses, pause the CPU emulation, another COG does DMA like operation from external RAM, then it's off to the races again, until the next fetch. Maybe keep stats on that too. Probably not though. Long code path problem again, but I thought I would mention it.
#4 Bummer on that one too. [noparse]:([/noparse]
The saga goes on!
Yeah, your 16 bit operations are gonna fly. Nice boost there. Have you run program profiles?
Might be possible to tune the code statistically as well. Focus on very common paths with larger and faster code, leaving the special cases special and perhaps somewhat less than optimal.
▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔
Propeller Wiki: Share the coolness!
Chat in real time with other Propellerheads on IRC #propeller @ freenode.net
Safety Tip: Life is as good as YOU think it is!
Post Edited (potatohead) : 2/2/2009 8:08:35 PM GMT
I might urge you to slog through that wait pin idea (#2) though. It still really feels to me like it should be a gain. If it is not I'd really like someone to explain to me where the time went! Perhaps I just implemented it badly. I would show you but, as I say, I got really frustrated and deleted all these experiments.
Just now my "data structures" are as simple as I can be whilst giving both BYTE and WORD access to the registers.
No, I have not done any profiling. Only when doing the single COG PropAltair version I had a look though a whole bunch of CP/M sources and made a guess at what were lesser used instructions that I could move out into LMM mode. Starting with the pesky DAA instruction. No I tell a lie, at one point I had the thing set up to count how many times each opcode was used while running the T8080 CPU diagnostic. There were sure some ops that saw little use. Perhaps I'll try that again. Trouble is a lot of programs just spin around checking the keyboard so you easily get a skewed result.
All that stuff about external RAM and paging etc will now have to wait until I have got the thing into a state where I can regression test it.
It did occur to me that as I have chopped the opcode space into 4 equal parts, there might be some gain in putting a quarter of the dispatch table into each COG, there is room. Using the lower 6 bits of the op code to make the jump. But then I have to check the top two bits to see "is this for me" so perhaps it balances out again....BUT it would save all that wasted space in having 4 dispatch tables which appeals to me.
▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔
For me, the past is not over yet.
The profiling I saw when looking at other emulator projects boiled down to running a batch of sources through stats to see how often each instruction actually occurs. That's going to skew a different way. Maybe not a better way either.
For what it's worth, I deleted a bunch of Smile on Sunday too. LOL!!
▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔
Propeller Wiki: Share the coolness!
Chat in real time with other Propellerheads on IRC #propeller @ freenode.net
Safety Tip: Life is as good as YOU think it is!
▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔
For me, the past is not over yet.