

More cogs or more ram?
 Sleazy - G
Posts: 79
Sleazy - G
Posts: 79
I say how about more hub ports?· It would be beneficial for interleaved cogs to be able to read and write to the hub in the same system clock.· That way the hub clock runs at the system clock rate, and 4 interleaved·cogs can do 4 instructions from mutually exclusive resources·2 times every hub cycle, instead of once.
an extra hub port would let those 4·interleaved-cog·hi-speed I/O·programs pass double the amount of data to·hub ram·each hub cycle
i really dont know if its possible, but heres how i see it looking, one input hub port, one output hub port.· Maybe be able to get "DO NOTHING" hub throughput routines when you elect to bypass any read/write routines.·
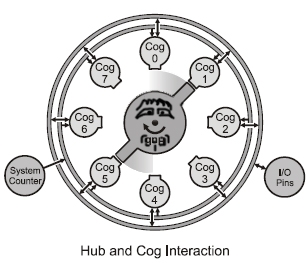
oh yeah, and just ignore the goofy squirrel drawing in the center of the hub, but notice where the ports could be in order to balance the interleaved ASM cogs.· Its kinda like an actual·propeller with both sides now, instead of just one.
I understand this is just a representation, but I want to give CHIPster something to think about.·
Post Edited (Sleazy - G) : 12/30/2007 11:08:01 AM GMT
an extra hub port would let those 4·interleaved-cog·hi-speed I/O·programs pass double the amount of data to·hub ram·each hub cycle
i really dont know if its possible, but heres how i see it looking, one input hub port, one output hub port.· Maybe be able to get "DO NOTHING" hub throughput routines when you elect to bypass any read/write routines.·
oh yeah, and just ignore the goofy squirrel drawing in the center of the hub, but notice where the ports could be in order to balance the interleaved ASM cogs.· Its kinda like an actual·propeller with both sides now, instead of just one.
I understand this is just a representation, but I want to give CHIPster something to think about.·
Post Edited (Sleazy - G) : 12/30/2007 11:08:01 AM GMT
308 x 263 - 62K
Comments
> hub cycle
Disregarding the address-confict when two ports try to access memory, what happens if both ports access the same location? One reading, one writing? Both writing? Wh wins?
Nick
▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔
Never use force, just go for a bigger hammer!
The DIY Digital-Readout for mills, lathes etc.:
YADRO
The point is to make a pipeline bus from one cog to another , without any hub instructions, to serve as a DO NOTHING throughput.
I guess an example is where cog 1 and cog 5 could be looked at as the pipeline, cog one could be an·adc input process·and cog 5 could be dac output process.
You could·add to·the hub some sort of single clock flip flop buffer, just incase there are greater conflicts, and put it right in with the siliicon.
and there wouldnt be more than 4 conflicts every 8 clocks with 4 interleaved cogs 1,3,5,7··· , so you could buffer any data to rectify post·conflict .
?
▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔
Help to build the Propeller wiki - propeller.wikispaces.com
Play Defender - Propeller version of the classic game
Prop Room Robotics - my web store for Roomba spare parts in the UK
I my opinion, each COG needs significantly more RAM. Either by faster access or by having significantly more RAM available in each COG. The current "balance" is too limiting.
▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔
---
Jo
Dual ported ram!
Chip you should really consider this.
Post Edited (Sleazy - G) : 12/31/2007 9:03:16 AM GMT
The conflict would also be resolved by deciding the order in which the operations are interleaved, and therefore making it deterministic like it was before. (there would still be a race-condition for other hubops like cognew which would have to be dealt with, eg. by allowing only another one of the HUB ports to do ops other than memory reading).
Design of dual port RAM for parallel volume rendering system
Xiaotu Li; Jizhou Sun; Weifang Nie; Yurong Wang
Electrical and Computer Engineering, 2004. Canadian Conference on
Volume 1, Issue , 2-5 May 2004 Page(s): 177 - 180 Vol.1
Digital Object Identifier ·
Summary: A dual port RAM, used in the local memories of a parallel accelerator, was designed and implemented to support the parallel-execution oriented volume rendering algorithm. The temporary processing results of the rendering, and so on, were stored in the memories. One port of the dual port RAM was connected to the multi-CPU by the Omega Net, and the other connected to the global bus to input data into the display cache. Thus, collision can be avoided by adopting mutual exclusions during the parallel operation. The designed dual port RAM can support asynchronous control, separate the reading operation from the writing operation and be read or written parallel by the multi-CPU. The RAM improves the throughput and the read/write ratio of the parallel volume rendering system efficiently and has good practicability.
This is awesome! This is exactly what the prop needs!
Post Edited (Sleazy - G) : 12/31/2007 11:10:26 AM GMT
But this requires an async bus access. I think nothing a RISC-CPU can do (fixed number of cycles).
Nick
PS:
Your spinning avatar picture is causing eye-cancer.
▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔
Never use force, just go for a bigger hammer!
The DIY Digital-Readout for mills, lathes etc.:
YADRO
As it's now been mentioned in public, I have to agree; it's migraine inducing. I'd hate to have to use 'ignore poster' just to avoid the problems it causes me, but I don't want to disable all avatars.
So if you could change it to something static I think that would be the preferable solution, but the choice is entirely yours. I hate to sound as if I'm dictating what you must do.
en.wikipedia.org/wiki/Dynamic_random_access_memory#Video_DRAM_.28VRAM.29
Note that this does not require doubling the RAM speed or anything; however it is based on dynamic ram. I do not know what process the Propeller uses and whether it is compatible with dynamic ram.
But multi-ported cache rams are commonly available on logic processes and dual port cache is not particularly expensive or hard, particularly not in the limited size that a propeller like chip uses.
▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔
---
Jo
There is no parallelism at the heart of a memory array... The standard way to address this problem is defining separate memory banks. They can be connected to all processors using a crossbar switch. This is the most general configuration, thought about, improved, specialized for decades now...
There are two more or less unsolved issues:
- how implement the masses of connections required
- how to schedule access to occupied memory banks
I found this nice idea here the other day, showing a queued access as a partial solution to the last issue. Though queuing requests work fine for writing only (notwithstanding a major inconsistancy issue) reading from an occupied memory bank will delay the corresponding processor.
Even in this advanced scheme all conflikting issues have to be resolved by a central supervisor.
It was extremely wise of Chip to select the simplest and most stable alternative: a fixed timeslot concept.
Post Edited (deSilva) : 1/1/2008 4:41:11 PM GMT
Steven
Don't say:" Oh, but that's what a dual port ram is for!" Poppycock! It will reduce the throughput for justthe time you win by the doubled HUB.
Chips HUB concept is extremely bad with asymmetric load from the COGs. However it is close to perfect for equal load from all COGs. This technique is exactly used when engaging multiple COGs for increaed bandwidth.
I think the real problem though is that there is no easy way to access external memory yet. This is what is really holding the prop back. If we had a simple, fast external memory than we could do high res graphics. The question is, can parallax add on an external memory interface that adds the memory to the end of the hub? We could theoretically address 4 GB. Imagine what that would do.
Steven
If you could set up the second port to read cog "A"·and the first port to write to cog "B" in one clock, you could still get around
that way 4 interleaved cogs doing 1 instruction a clock could then be reading hub ram once every 2 clocks on average·instead of 4 clocks, as fast as you concieveably could fit 2 clocks with·one cog read and one cog write
the speed doesnt come from the mechanism of the duality, the reads and writes should take the same total amount of time.· However since 4 interleaved cogs cannot update their registers from·hub ram·with more than·4 new·longs·per hub cycle 16clks, but·could update INA up to 8 times per hub cycle·with their own local ram if they could have buffered the hub information·with the same speed that they could output it.
If the hub ran at 1 clock with 1 port·we could fix the problem, but that cant happen of course with one read and one write in a shift register
so if the hub had 2 ports and accessed·2 cogs at the same time in·1 clock , splitting the read / write between the two hub ports,·that way one of·4 interleaved cogs·would always·be doing either a read or a write to hub ram.
·as it stands, 4 interleaved cogs cannot collectively·access hub ram half of·the time,· even though they are capable of assuming the process load if they had the port.· The hub is just too slow for the cogs.· Only half as fast as it should be. the cogs are wasting their time wating around for the hub when they could go twice as fast.· at least with the amount of ram that we are working with.
This problem·was coined as the "VonNeumann bottleneck" along time ago
Post Edited (Sleazy - G) : 1/2/2008 7:25:11 AM GMT
The HUB-COG system is excellently tuned wrt long range throughput. There are hardly any cases where the COG has to wait, as it needs
- an I/O instrauction
- a HUB read/write
- a loopcontrol
- some address incrementing.
The main problem had generally been that these actions in fact took MORE THAN 16 TICKS! But not MUCH more... So the waiting was for the second cycle if you could not fill it with 4 further instructions.
This will be addressed in the Propeller II.
The "burst rate issue" can only occur with unrolled loops in the COG. The limiting factor is the COG RAM, not access time.
1) The Prop II will have 64 I/O pins. You are free to assign any of these that you want to use for an external RAM interface and manage that yourself. Keep in mind that there are many kinds of RAM and each has different I/O requirements and timing. The Propeller is intended as a general purpose processor. Some applications may need one size memory and others may need a different size. One application may need one set of control lines while another may require a different configuration. I understand that the memory space is not monolithic in this case, but in many ways, memory will continue to need to be treated as an I/O device and specific speedups provided in other ways.
2) You can't just keep adding I/O pins. These take up a lot of chip real estate. They have to be run at the higher voltage (3.3V) and use physically large MOSFETs because of the current requirements for off-chip driving. They need heavier "wiring" and static protection circuitry, etc.
3) The interleaved hub/cog setup used in the Propeller and planned for the Prop II is fairly simple and straightforward. Any possible alternative cannot significantly complicate the logic (and logic on-chip is not necessarily the same as logic on-paper, particularly in terms of the cost of implementation ... mostly in chip area). Interconnects are another difficulty. What looks easy on paper may be very expensive on-chip because of the difficulty or cost of the interconnections. I'm not a chip designer, but I've read enough to understand some of the tradeoffs and design difficulties.
Post Edited (Mike Green) : 1/2/2008 6:53:16 AM GMT
For an embedded processor - this is NOT the bottleneck.
As I see it, I'm using this device to replace a 68HC11 or an·8051 with 32K of program memory. Now, which one would I rather have? Let me think about this - for about 2 seconds!!
I think the fact that this processor is able to generate a video output and stereo-spacialized singing monks has misplaced its position in the micro market. This chip is NOT a PC replacement, it's NOT a DSP processor, it's NOT a high-speed communications processor, it's NOT a video processor, it's NOT a dedicated sound synthesis chip. And yet, if you're doing a little embedded job, then this chip is THE swiss army knife of embedded processors. It will handle simplified variations of any of the previous tasks.
I think that optimization effort is better spent in investigating various tasks to the limits of capability.·eg: 1600x1200 video driver, singing monks, ViewPort, 8MBaud prop-to-prop connection and numerous·others. Then, build your product with the best compromise of what is learned from these best efforts.
·
the new prop is supposed to be 160 MIPS per cog instead of 160MIPS per propeller, right?
a double propeller (64IO) with crossover dual hubs would get this done. I wonder what the design change is.
in my opinion you are terribly mislead in your assessment where the bottlenecks of the Propellers are, though I am fully aware that the bottlenecks one sees are usually the specific bottlenecks one encounters in one's recent project
Mirror has put it quite well: This is a microcontroller with a specific price/performance parameter. Chip-technology (pun intended) is able to produce something in the same package with 10 times the perfomance (and most likely the 10 fold price tag). Have a look at Tilera's TILE64 e.g.
Many requests go just the other direction: A chip with 4 COGs and 16 kByte HUB only is a very desirable device - for half the price!
Post Edited (deSilva) : 1/2/2008 3:15:43 PM GMT
Agreed the HUB is not the real bottleneck. IMHO, that's RAM, for the most part, on the current Propeller. It's only that way, due to what the chip appears capable of, and how that relates to the 32K number.
▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔
Propeller Wiki: Share the coolness!
The current implementation of the Propeller hits a nice sweet spot. Memory access performance has not impacted my projects much.
What has made things more difficult than expected has been how little memory is available in each COG, or for that matter in the HUB. Space is very tight in the Propeller by comparison to ARM, AVR chips. Sure, using overlays and eeprom/SD card access some of this can be mitigated, but more memory would be certainly be nice. I haven't (yet) run out of COGs in any of my projects, but running out of RAM happens regularly.
My current project is creating a spaceship console (as per old Startrek shows) as a prop for a friends LARP games. The idea was to have the Propeller generate the video (composite out) for spaceship status, controlling the obligatory flashing LEDs, receiving IR control codes (from the gamemaster) to change ship status and possibly playing sounds (using Rayman's wav player). keyboard & mouse input for player to pretend to be doing engineering tasks to fix the ship.
Spaceship bitmaps stored in an SD card. LEDs controlled via a 16 way I2C port expander.
And when nobody is looking, SD card also holds implementation for a few games (defender, paralloxoids, etc)
Mostly using Mike's femtoBasic as the control engine behind all of this (with a few modifications removing stuff I don't need to fit in the parts I do need)
▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔
---
Jo
what you say shows how difficult (impossible) it is to find an agreement what is most to be improved - if anything at all.
The propeller is used for so many DIFFERENT needs, being a "generalist".
I should like to quote from my list of "absolutely needed features"
- embedded EEPROM to reduce chip count
- embedded 8 channel 12 bit-ADC (this is the most often added device)
- more HUB-RAM (or dedicated Video RAM on chip)
- more COG RAM
- faster instruction execution
- multiplication and division instruction
- 16-color video mode
- time-out enabled WAITPEQ/NE instruction
- fast serial shift-in (1,2,4 or 8 ticks/shift)
- double-long access to HUB
- fast C Compiler
- advanced IDE (including Hardware Debugger, Software simulator)
- advanced Compiler (conditional compilation, code optimization,...)
Well Christmas is over now, and - in fact - there is no Santa Claus :-(
Post Edited (deSilva) : 1/2/2008 3:09:15 PM GMT
Now I know theat there's 160MIPS of gross execution speed available, but have you ever taken the time to figure out how many of those are actually being used?
Eg: You have rockiki's SD card driver and the Spin test program that goes with it. How many MIPS do you get? Well you might think 2 COGs = 2 x 20 = 40MIPS. BUT, in fact those two pieces of code are mutually exclusive (they wait for each other), so in fact you only get 20MIPS!! You've just thrown away half the potential of these two COGs.
A similar performance hit happens if you use many of the other specialised PASM libraries (I2C, SPI). What you effectively add when you include these libraries is "supplementary to Spin" instructions.
The real trick to getting the Propeller singing is by figuring out how to get those COGs running concurrently.
Some COGs do run concurrently: eg. FullDuplexSerial (and variants), the various graphics drivers, stereo spacializer. In fact, the singing monks code is quite a good example of concurrent cog operation.
▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔