Just did the real run from PSRAM test using P2-EVAL and my own PSRAM board at 160MHz. Only made a small improvement in the total tick count but that's to be expected given the number of iterations and the fact that only 31 rows are ever loaded.
Worked first go which is great but almost makes me believe it's not real. Now want to intentionally impair PSRAM to ensure it's legit. Will just yank the breakout board out for that. UPDATE: yep crashed right away with the board removed. So it's loading the code from the PSRAM now!
2K performance run parameters for coremark.
CoreMark Size : 666
Total ticks : 1853091552
Total time (secs): 11
Iterations/Sec : 18
Iterations : 200
I thought the P2 was originally designed for a maximum 180Mhz clock speed, although it has since shown it can generally go much, much faster. For myself I tend to use 200Mhz, but Catalina's default is 180Mhz, because I thought that was still the design maximum. If there is now a reason to make the default slower than that, I'd like to know it.
Haven't considered it yet but in theory multiple COGs running from external memory could each have their own I-caches and share a common external memory, with a commensurate reduction in performance. The main limitation here is that this model doesn't keep directly accessed data in the external RAM, just code,
That would be analogous to Catalina's SMALL mode, which only stores code in external RAM (as opposed to LARGE mode is where both code and data are stored in external RAM). But even multi-processing in SMALL mode would be a huge win. My biggest problem is that I always tried to keep Catalina compatible with both the P1 and the P2, which I have (just about!) managed. But that is largely just nostalgia on my part - I have really fond memories of the P1, but I knew one day this compatibility would probably have to come to an end.
I thought the P2 was originally designed for a maximum 180Mhz clock speed, although it has since shown it can generally go much, much faster. For myself I tend to use 200Mhz, but Catalina's default is 180Mhz, because I thought that was still the design maximum. If there is now a reason to make the default slower than that, I'd like to know it.
There's no reason for that IMO, 160MHz is just what flexspin had setup as the default from way back.
Haven't considered it yet but in theory multiple COGs running from external memory could each have their own I-caches and share a common external memory, with a commensurate reduction in performance. The main limitation here is that this model doesn't keep directly accessed data in the external RAM, just code,
That would be analogous to Catalina's SMALL mode, which only stores code in external RAM (as opposed to LARGE mode is where both code and data are stored in external RAM). But even multi-processing in SMALL mode would be a huge win. My biggest problem is that I always tried to keep Catalina compatible with both the P1 and the P2, which I have (just about!) managed. But that is largely just nostalgia on my part - I have really fond memories of the P1, but I knew one day this compatibility would probably have to come to an end.
I will follow progress with interest
I think it's probably doable to have multiple COGs sharing the external RAM for their code (or even run different code as separate applications). Right now for this proof of concept setup I init an I-cache and block mapping table at startup time in another linked module called extmem.c whose addresses I pass into the COG external memory handler routines executed from LUTRAM during startup. The only change needed would be to not have this as defined a global variable block but allocated on a per COG stack instead via alloca in main() or something like that. I'm running the cache transfer requests through my external memory mailbox so other COGs can certainly make other requests in parallel to the COG executing external C routines. I can easily already prove that out to myself by introducing another video COG which shares the memory but I know it would work, just slower.
Now I have something functioning running via external memory and a cache, I was wondering about some of the potential target applications that might work with a larger memory model on a P2. I wonder if flexspin/spin2cpp could be setup to compile itself as a P2 application or whether the small 512k of HUBRAM for data would be a major limitation. This is assuming most/all of the executable code is stored externally with say a 64kB I-cache and (say) a 16-32kB block mapping table and some required library and filesystem APIs are present leaving up to 436kB or so for data. Flexspin on my Mac is only a 2.8MB executable so with any luck it might still compile to fit within some 16MB external address space (PSRAM) on a P2. I guess there would be some native OS and memory management APIs used that would need to be ported/provided on a P2 but it's more of whether it could be made to compile with much less available RAM for data that I'd be concerned about.
Is there any scope for something like this or is it a fools errand even considering the idea compiling flexspin source from itself, especially without a linker?
Output of make for building spin2cpp etc is shown below. It has dependencies on bison and builds each module separately before final link step.
Interesting observation. Running CoreMark with the I-cache row count total configured as 4 active rows each containing 256 byte blocks (instead of 255 rows I used above) still works! Performance drops by half. It's quite a small test program so its working set is very small. In this case the I-cache is only 1kB in size holding 256 P2 instructions. I probably should add some cache row load/miss counter which would help in dimensioning the cache size for the application.
CoreMark Size : 666
Total ticks : 3473502264
Total time (secs): 21
Iterations/Sec : 9
Iterations : 200
Now I have something functioning running via external memory and a cache, I was wondering about some of the potential target applications that might work with a larger memory model on a P2. I wonder if flexspin/spin2cpp could be setup to compile itself as a P2 application
Currently wondering where to go next with this code...
So far I've basically proven the general concept of using flexspin to build code to run with external memory can be made to work on a P2.
I've found that prefixing "FAR_" to function names to identify them for storage in the external memory segment is rather tedious when the project contains lots of files and functions. Not only do you need to modify all the source code that will target the external memory, the calling code also has to be modified to prefix the same FAR_ to the function name. This is not really very scalable and was only done for this proof of concept in order to get something working before flexspin might potentially be modified to enable a proper external memory solution.
Another alternative is to locate all code in external memory by default when the external memory option is enabled for the build and perhaps use some function list or attribute that places some subset of this code in internal memory otherwise. This is better if you wanted to port a large project to the P2, the bulk of which would be held in external RAM but has some small number of critical loop / non-cachable functions which make sense to keep in internal hub RAM for sharing with other COGs (eg. any included SPIN2 object APIs) or if it could really benefit from some optimizations that are only allowed in regular internal memory code to increase performance further.
I've started down that path but already found one big problem with this plan is that the cache initialization step at startup time requires some minimal number of functions to be called before the PSRAM is configured to respond to cache row loading. Right now it that would be identifying the PSRAM mailbox address and running the PSRAM startup code and these API functions are needed to be called before the system is ready to execute from external memory. So some method of identifying which functions need to remain in HUBRAM is going to be required even just for system initialization at the very start, even if everything else targets external memory for storage.
If this external memory functionality is going to become available in flexspin we ideally require some way to quickly identify which functions are to be placed into external memory, possibly by using some new #define or #pragma, or use some new attribute list option per function.
For now I believe it's probably easier to just enable this external memory code storage feature on a file by file basis and selectively pull out the functions that need to remain in internal hub memory - you could probably move them into other files if the set is small. One way I was thinking of how to achieve it is just to separate the internal/external module's functions by their module file order on the command line, with the extmem.c module that configures the external memory also being the delimiter that separates them. Something like
This keeps main.c, intmodule.c intmodule2.c and extmem.c in internal memory, while storing extmodule1.c and extmodule2.c in PSRAM for example.
I started going down this path and am already finding that for the standard library functions that get called, we don't really get much control as they are simply included by whatever parent module calls them, and they'll sit in the same location as their caller. So it's still not ideal.
Any other ideas on the best way forward with this...?
ps. I'm looking at the LVGL project (GUI/graphics library) as something that might be useful as a demo for this external memory feature. A large amount of its code could be stored in external memory keeping hub RAM free for other stuff (including a graphics framebuffer). Unfortunately I'm currently having issues with its build process with flexspin in general so it may not be a good example demo if I can't get it to build with flexspin. Still learning/persevering for now before possibly abandoning the idea...by default lvgl seems to want to build a static library that is then linked to the application code whilst flexspin wants all files on the same command line and doesn't directly support linking. Not sure if/how it can be split up instead.
Any other ideas on the best way forward with this...?
I think you are on the right track doing it file by file using compile-time options. Trying to do it within the language without mangling things too much would be tricky (look at the complexities Microsoft had to introduce in their version of C to accommodate "near" and "far" pointers). Ideally, you compile each file separately with the appropriate memory model, and then use a binary linker to figure out to to put it all together and get it to execute.
But that assumes you have a suitable linker. I don't know much about flexspin - maybe it has one you can modify. But it would be a big job!
Catalina does not have a linker - for programs that use a single memory model you don't really need a linker - and for programs that use multiple memory models I built a separate utility (called Catapult) to help automate the build process. Catapult essentially turns anything to be executed from Hub RAM into a binary blob that can be loaded at run time either from external memory or from a disk file. The blobs can be loaded in separate Hub RAM locations, or all in the one location (i.e. as overlays). In Catalina, each component executes on a different cog, and they communicate via the Registry - this sounds complex but it actually simplifies many things. However, that would not be an option in flexspin - you might have to implement something similar yourself. But even when using Catapult you still effectively have do the linkage between the components yourself.
See (for example) demos/catapult/srv_c_p2.c - the my_service_list table in that program is essentially doing manually what it would be ideal to have a linker or other utility do automatically - it does so by using "proxy" functions. When I get time I may add the capability for Catapult to automatically generate those proxy functions. This would have been too difficult for me to do in lcc (which is a bit of a monster) but now that Catalina also uses Cake (which does semantic analysis of the C source code) it should be a lot easier. But even if the proxy functions have to be manually created, the idea of using them may be worth exploring - all the complexity could at least be contained in one file.
One downside of the way Catalina does things is that if both a hub function and an external function call the same functions, you end up with two completely separate copies of each called function - one that executes from Hub RAM, and the other that executes from external RAM. Again, this makes some things easier, but it also complicates other things if the functions are not built to deal with such a possibility - for example, you cannot use stdio library functions from two different components - all stdio library calls have to be done from within one of the components.
I was thinking some more about this last night. In particular, the idea of using "proxy" functions, which do whatever is required to invoke the actual functions compiled to use a different memory model.
In my previous post I thought that this would require additional processing of the source code to generate the necessary information, but my midnight brainwave was that debuggers already require the same information. For example, Catalina's -g option causes lcc to generate a standard "stabs" file (with a .debug extension) containing information about each function in the source. Catalina's Blackbox debugger uses this information.
You may find that flexspin has something similar that could help automate the creation of proxy functions.
Another option would be to add pragmas to the source code to include the necessary information required to call each external function compiled with a different memory model. This does not require a change in the language, and is probably the option I will explore first, because Catapult already uses pragmas (and processing "stabs" files is a black art!).
I was thinking some more about this last night. In particular, the idea of using "proxy" functions, which do whatever is required to invoke the actual functions compiled to use a different memory model.
Interesting, I guess one issue with that is that it would slow down ALL function calls via these proxies.
In my previous post I thought that this would require additional processing of the source code to generate the necessary information, but my midnight brainwave was that debuggers already require the same information. For example, Catalina's -g option causes lcc to generate a standard "stabs" file (with a .debug extension) containing information about each function in the source. Catalina's Blackbox debugger uses this information.
You may find that flexspin has something similar that could help automate the creation of proxy functions.
I don't think flexspin has that. The only other output file I know of apart from the .p2asm intermediate source is the listing file. And that just gives me opcodes and preliminary HUB RAM addresses assuming a normal internal memory target for everything in the set of files passed. This p2asm file is what I mess about with with my sed scripts to reorder it and insert an ORG $100000 at the internal/external address boundary before re-assembling the updated file to a final binary.
Another option would be to add pragmas to the source code to include the necessary information required to call each external function compiled with a different memory model. This does not require a change in the language, and is probably the option I will explore first, because Catapult already uses pragmas (and processing "stabs" files is a black art!).
I think a special pragma to enable and disable external memory target (applies globally) would be useful. If the command line input is sorted to be internal modules first following by external modules, then a single pragma could change the target model applied from then on when invoked (until it is optionally disabled). This would avoid needing lots of source code modifications. It could simply be placed in a single file once (e.g my extmem.c file) and it would also limit which optimizations can be applied to the functions it compiles when enabled. Otherwise adding a special "FAR" attribute per function is a lot of changes if the source code is extensive. Then if you do have a few special functions in your mostly external source that do need to target internal memory instead you could either pull them out into a separate file or if not, just place the pragma around those functions to disable/re-enable FAR mode at will. It's probably the most convenient way to go.
After testing out the method of separating code by command line order it looks like I was wrong about how flexspin brings in its dependent functions called by each of its compiled modules. I'm now not totally sure how it generates the order of code in the p2asm output file. A few internal library functions get pulled into the same part of the code that calls them, but most library functions seem to actually be placed at the end of the group of compiled files. What differentiates this actual placement I don't know.
Here's the function order in the image you get when building the coremark benchmark according to this command line file order. flexspin -DITERATIONS=200 -O0,const -gbrk core_main.c extmem.c core_list_join.c core_util.c core_matrix.c core_state.c core_portme.c
It starts out with a small handful of internal functions, then the module code seem to follow, then some more internal library functions, then some SPIN2 modules incorporated in the C source, then a whole bunch of __system__ prefixed functions. I guess I can try to place some fixed file at the end of the compiled file list that defines a specific function name I can search for to disable external memory placement in my scripts... Messy but maybe achievable.
popregs__ret <--- special function in COGRAM (ignore)
___default_getc_ret <--- why are these ones placed here?
___default_putc_ret
___default_flush_ret
___lockio_ret
___unlockio_ret
___getftab_ret
_printf_ret <--- called in core_main.c (again why here)
_FAR_iterate_ret <--- defined in core_main.c
_main_ret <--- defined in core_main.c
_extmeminit_ret <--- defined in extmem.c
_FAR_calc_func_ret <--- defined in core_list_join.c
.... <--- lots of other functions but still in command line file order
_portable_init_ret <--- defined in core_portme.c
_portable_fini_ret <--- defined in core_portme.c
__dofmt_ret <--- all of these functions now seem to be from internal library functions
__strrev_ret
__fmtpad_ret
__fmtstr_ret
__fmtchar_ret
__uitoall_ret
__uitoa_ret
__fmtnum_ret
__fmtnumlong_ret
_disassemble_0254_ret
_emitsign_0256_ret
__fmtfloat_ret
__getiolock_0295_ret
__rxtxioctl_0356_ret
___dummy_flush_0357_ret
_parseint_0408_ret
_parseflags_0415_ret
_parsesize_0419_ret
__asfloat_0421_ret
___default_filbuf_ret
_psram_spin2_start_ret <--- defined in my psram.spin2 file
_psram_spin2_startx_ret
_psram_spin2_stop_ret
_psram_spin2_write_ret
_psram_spin2_getMailbox_ret
_psram_spin2_lookupDelay_ret
_psram16drv_spin2_getDriverAddr_ret <--- another nested SPIN2 file declared in psram.spin2 as an OBJ
__system___getcnt_ret <--- now all these __system___* functions are placed here
__system___cogid_ret
__system___cogstop_ret
__system___locknew_ret
__system___lockret_ret
__system___coginit_ret
__system___txwait_ret
__system___setbaud_ret
__system___txraw_ret
__system___rxraw_ret
__system___dirl_ret
__system___dirh_ret
__system___drvl_ret
__system___pinr_ret
__system___rdpin_ret
__system___rdpinx_ret
__system___div64_ret
__system___wrpin_ret
__system___wxpin_ret
__system___wypin_ret
__system____builtin_memset_ret
__system__longfill_ret
__system___make_methodptr_ret
__system___int64_add_ret
__system___int64_sub_ret
__system___int64_cmpu_ret
__system___int64_cmps_ret
__system____builtin_strlen_ret
__system____builtin_strcpy_ret
__system___lockmem_ret
__system___unlockmem_ret
__system___getrxtxflags_ret
__system___setrxtxflags_ret
__system___tx_ret
__system___rx_ret
__system___basic_print_nl_ret
__system___basic_print_char_ret
__system___basic_print_string_ret
__system___basic_print_integer_ret
__system___basic_print_unsigned_ret
__system___fmtchar_ret
__system___fmtstr_ret
__system___fmtnum_ret
__system___seterror_ret
__system___int64_signx_ret
__system___int64_zerox_ret
__system___int64_and_ret
__system___int64_neg_ret
__system___int64_muls_ret
__system___int64_divmodu_ret
__system___int64_divu_ret
__system___int64_modu_ret
__system___float_fromuns_ret
__system___float_fromint_ret
__system___float_negate_ret
__system___float_mul_ret
__system___float_div_ret
__system___float_cmp_ret
__system___float_Unpack_ret
__system___float_Pack_ret
__system____builtin_signbit_ret
__system____builtin_ilogb_ret
__system___float_pow_n_ret
__system____default_getc_ret
__system____default_putc_ret
__system____default_flush_ret
__system____getftab_ret
__system___gettxfunc_ret
__system___strrev_ret
__system___fmtpad_ret
__system___uitoa_ret
__system___rxtxioctl_0563_ret
__system____dummy_flush_0564_ret
__system__asFloat_0625_ret
__system__asInt_0627_ret
__system__pack_0630_ret
__system____default_filbuf_ret
__system___struct__s_vfs_file_t_putchar__ret
__system___struct__s_vfs_file_t_getchar__ret
__system___struct___bas_wrap_sender_tx__ret
__system___struct___bas_wrap_sender_rx__ret
__system___struct___bas_wrap_sender_close__ret
UPDATE:
just modified my script to look for extmem_start and extmem_stop functions in the p2asm file to delineate the external memory target and this command seems to work (at least for the coremark application). flexspin -l -DITERATIONS=200 -O0,const -gbrk core_main.c extmem.c core_list_join.c core_util.c core_matrix.c core_state.c core_portme.c extmemoff.c
I just created a closing extmemoff.c file with this function
void extmem_end(void)
{
return;
}
which assembles to this code after I patched it in my output file. I can then use extmem_start and extmem_end function names to enclose the external memory target functions. Ugly but it works at least for now.
I've never really studied memory caching hardware but I've just come to a realisation that I've probably had an incorrect view of their behaviour. I've just been looking at a block diagram of HBM4, as recently posted to a news site, and it kind of drove home to me that cache doesn't initiate memory accesses at all. It only sits on the side lines and intercepts the data flows as suits it.
Note the allowance for up to 32 pseudo channels. A unified L3 cache isn't going to distinguish between threads/cores where as direct core to main memory accesses will easily be separable into channels matching each core or thread.
@evanh said:
I've never really studied memory caching hardware but I've just come to a realisation that I've probably had an incorrect view of their behaviour. I've just been looking at a block diagram of HBM4, as recently posted to a news site, and it kind of drove home to me that cache doesn't initiate memory accesses at all. It only sits on the side lines and intercepts the data flows as suits it.
Note the allowance for up to 32 pseudo channels. A unified L3 cache isn't going to distinguish between threads/cores where as direct core to main memory accesses will easily be separable into channels matching each core or thread.
That's actually not at all how it typically works.
You definitely need memory access from the cache system, to store dirty evicted lines back into memory. There's also often an uncore prefetcher that observes LLC miss patterns. Shared caches also need to keep track of which core "owns" a line to avoid corruption. If e.g. two cores want to modify one value each that happen to be next to each other in the same line, the coherency algorithm needs to stop the second core from wholly overwriting the line with its own L1 cached version (where the first value hasn't been changed). That sort of "false sharing" typically causes severe slowdown to ensure correctness.
Mostly over and above where I was talking. The storing dirty lines I guess is slightly relevant in that the cache does address memory itself for that. But mainly I was talking about how the L3 cache is positioned in the data flow. For some reason I had imagined it stood in the middle, gobbling everything.
@rogloh Are there some small changes to flexspin we could make that would help you out? I think it would be straightforward to add new attributes like FAR and NEAR, but I'm not sure how to pass those through to the pasm file so that you could best make use of them. Maybe some kind of prefix/suffix attached to the name?
@ersmith said:
@rogloh Are there some small changes to flexspin we could make that would help you out? I think it would be straightforward to add new attributes like FAR and NEAR, but I'm not sure how to pass those through to the pasm file so that you could best make use of them. Maybe some kind of prefix/suffix attached to the name?
Yeah, as mentioned earlier, it's probably easier to just put support code for this in the actual compiler. It doesn't usually bite (unlike GCC or LLVM).
Incidentally, I'd for a while thought about adding more "classic style" overlay support (that you'd just load into memory as a whole). I feel like that could share a lot of implementation with roger's XMM thing here.
Basically need to be able to tag/color functions (and in the case of the classic overlays, constant data, too) as belonging to a group, then grouping them in the ASM output, ideally with useful marker comments to easily extract the portions needed. Ideally we'd be able to assemble usable binaries directly, but there's open questions as to how those should look like (alignments/checksums/etc). Though I'm thinking it'd be tricky to actually assemble it correctly, since the assembler doesn't really have a "pseudo PC" feature to assemble the code for a different load address.
@ersmith said:
@rogloh Are there some small changes to flexspin we could make that would help you out? I think it would be straightforward to add new attributes like FAR and NEAR, but I'm not sure how to pass those through to the pasm file so that you could best make use of them. Maybe some kind of prefix/suffix attached to the name?
Hi Eric. Yes some flexpin changes could be helpful. Here are my thoughts:
This external memory feature has two fundamental scenarios.
1) some greenfield C project code for the P2 that is or will become large needs to be placed into external RAM to make more HUB RAM space for other features & other COG's requirements. It's probably reasonably easy to rename or add some function attributes as you code it that control the function's placement in memory (hub vs external). It's a little tedious but still workable to do these changes as you code up your fresh project. This could involve attributes and/or prefixed names as long as they make it into the .p2asm file somehow. I think for that we could even have some commented out list at the end of the .p2asm file of all these external memory functions and my script could hunt for these function blocks to place them after $100000 in the modified file. Given the standardized formatting used in a .p2asm file it's fairly easy with SED to extract a given function name's code block up to the function_ret at the end of the function (plus the extra line after that).
2) some existing large codebase in C is being ported to the P2 and we need to put it into external RAM to make it fit. This was what I was attempting recently with LVGL (but now I think it probably has its own issues with its C99 requirements vs current flexspin capabilities as I'm seeing a very large number of errors when compiling - could still be some mistake in include file paths, but not sure yet - I could post more details on that topic after this).
We basically need a good way to identify which functions or files/C modules will be located in external memory that handle both scenarios. For now we might want any embedded SPIN2 object code to still remain in HUB RAM especially if they are to be shared with other regular SPIN2 COGs etc but maybe down the track these could also be optionally placed into high memory under our control.
I've already tried the prefixing approach and it works, but it's certainly going to become a bit of a nightmare for large C codebases under the second scenario as you need to edit lots of third party files/functions for this and anything written using existing macros for function names can be problematic too. So I think a better solution may be to have some binary switch state in the compiler (persisting across input files) that is on or off during compilation and probably under control of a #pragma which directs compilation to target either internal/external memory. Whenever the switch is off (the default) all output code targets internal memory as usual and when it is on the code targets external memory and will be generated after an ORGH $100000 statement in the p2asm file which separates low/high memory. My script can do this ORGH $100000 reordering step on a .p2asm file, but it just needs a list of functions which will be moved to the end of this file after the special ORGH statement. Perhaps we can add some comments at the end of the .p2asm file as mentioned above that lists this group of functions, or output it as another file that just contains the names of these functions that will need to be moved by my script.
For example the .p2asm file could print this at the end...
...<snip>
local40
res 1
muldiva_
res 1
muldivb_
res 1
fit 480
' EXT_TARGET external functions follow
' extfunction_name1
' extfunction_name2
' ...<more>
Also while the switch is on we may have to override some of the optimizations to cancel those that will create unsupported instructions in the code. We can figure that part out as we go but I already have a list of all the unsupported instructions. I search through the high memory segment code to ensure the code doesn't have them before I try to run the code but ultimately it would be best enforced by the compiler, rather than checked after it generates the code.
For scenario 2 with this approach we can fairly easily enable/disable the switch state without even editing any imported project source files by compiling some dummy code in the module list order that simply enables or disables the external memory via the #pragma. For example to place some set of module's code in external memory we'd just separate these modules from the internal RAM target by ordering them on the command line (or in the .side file), as done with the following command:
And in the extmemoff.c file at the end of the list of compiled files we'd simply have this:
#pragma external-disable
This would end up keeping core_main.c and extmem.c in internal memory, but the other functions in the other files would be placed in external memory.
In fact in this case we don't need to turn it off because it's the last thing in the list, we'd only need this if there were more internal modules following this.
The example above needs no file changes to the code targeting external memory, although if you wanted to you could still choose place the pragma's in these files.
One remaining issue are the library file functions called by the project file's C code. For now mostly they seem to be placed at the end of the .p2asm file. I'm assuming they won't be quite as large as the main project code's function so am just keeping these in internal memory for simplicity but eventually it would be nice to have a way to place them in external memory somehow as well. Not sure if/how that could be controlled. We'd potentially need some other input file like a linker's .ld file for example I suspect. This could use wildcards and other named strings to identify which functions from which files go where...?
Even the bare minimum of the #pragma that collects function names while it's enabled and then lists them also at the end of the .p2asm file is going to be helpful, although for now we probably need it to ignore embedded SPIN2 object API names detected while enabled. If its state can also reduce the optimizations applied to the external memory functions during the time it is activated that would still enable more optimizations to work with the internal functions (which otherwise would have to be turned off globally to be safe).
What are your own thoughts on the feasibility of these ideas for flexspin?
p.s. Also is there any way for flexspin to generate a pre-processor output file so we see the source code before its compiled but after the include files are included? Like the gcc -E option. Mainly relates to LVGL porting...
Also with this external memory feature in flexspin we may want to increase the number of source files that are allowed to be listed in a project file (or on the command line). I found that LVGL has over 400 smallish source files (after I reduced it down by removing extra demos/tests which are bundled in) and they already max out flexspin and I get an error. I'm still assuming its likely to fit into 16MB PSRAM as it only consumes 2.4MB of ARM64 code space when I build it all locally. So some increase to the compiler limits are likely needed for scaling up the image size.
Propeller Spin/PASM Compiler 'FlexSpin' (c) 2011-2026 Total Spectrum Software Inc. and contributors
Version 7.6.2 Compiled on: Mar 2 2026
error: too many files in project file proj3.side
error: too many files in project file proj3.side
error: too many files in project file proj3.side
...
So I'm still trying to get this LVGL project to build with flexspin as an example of something large and ideal if it could run from external memory but am running into severe build issues using flexspin which almost makes it look like some include files are not being included or something related to unknown/unsupported types being assigned. It's meant to work with C99 compatible compilers so I was hoping that may include flexspin. What's weird is that it does build okay with the same list of files on my Mac locally using Gcc/Clang so it does appear that these could be real bugs/limitations of flexspin. I just don't really know if they are all known bugs or limitations or something new that might be fixable?
I did define the top level include path for the project file (included below in the zip) that is being passed into flexspin for this source tree and am presuming it is also recursive if there is an included file buried deeper and that flexspin won't simply silently fail if the file is not found in the defined include path(s).
The list of compiled C files in the project does get printed out initially (I'm presuming that's pass 1) then all the errors begin. I logged them all and split the errors and warnings into two different files in the attached zip and sorted and uniq'd them. Many are of the same type, like this sort of thing:
Users/roger/Documents/Code/lvglproj/lvgl/src/draw/lv_draw.c:460: error: incompatible types in assignment: expected _struct___anon_306468b10000002a but got const _struct___anon_ea3968a50000002a
/Users/roger/Documents/Code/lvglproj/lvgl/src/draw/lv_draw.c:461: error: incompatible types in assignment: expected _struct___anon_306468b10000002a but got const _struct___anon_ea3968a50000002a
/Users/roger/Documents/Code/lvglproj/lvgl/src/draw/lv_draw.c:462: error: incompatible types in assignment: expected _struct___anon_306468b10000002a but got const _struct___anon_ea3968a50000002a
but I also got several other interesting things such as these presumably simple pointer conversion errors:
/Users/roger/Documents/Code/lvglproj/lvgl/src/misc/lv_color.c:268: error: unable to convert c to a pointer type
/Users/roger/Documents/Code/lvglproj/lvgl/src/misc/lv_color.c:279: error: unable to convert c1 to a pointer type
/Users/roger/Documents/Code/lvglproj/lvgl/src/misc/lv_color.c:279: error: unable to convert c2 to a pointer type
/Users/roger/Documents/Code/lvglproj/lvgl/src/misc/lv_style.c:428: error: bad cast of white
/Users/roger/Documents/Code/lvglproj/lvgl/src/misc/lv_style.c:429: error: incompatible types in assignment: expected int but got _struct___anon_98b868fb0000006d
with the code shown below:
138 typedef union {
139 int32_t num; /**< Number integer number (opacity, enums, booleans or "normal" numbers)*/
140 const void * ptr; /**< Constant pointers (font, cone text, etc)*/
141 lv_color_t color; /**< Colors*/
142 } lv_style_value_t;
416 lv_style_value_t lv_style_prop_get_default(lv_style_prop_t prop)
417 {
418 const lv_color_t black = LV_COLOR_MAKE(0x00, 0x00, 0x00);
419 const lv_color_t white = LV_COLOR_MAKE(0xff, 0xff, 0xff);
420 switch(prop) {
421 case LV_STYLE_TRANSFORM_SCALE_X:
422 case LV_STYLE_TRANSFORM_SCALE_Y:
423 return (lv_style_value_t) {
424 .num = LV_SCALE_NONE
425 };
426 case LV_STYLE_BG_COLOR:
427 return (lv_style_value_t) {
428 .color = white // <--- doesn't like to assign a struct to the .color field element of lv_style_value_t union?
429 };
And this sort of error:
/Users/roger/Documents/Code/lvglproj/lvgl/src/core/lv_observer.c:360: error: Expecting identifier after '.'
/Users/roger/Documents/Code/lvglproj/lvgl/src/core/lv_observer.c:360: error: assignment to constant value
/Users/roger/Documents/Code/lvglproj/lvgl/src/core/lv_observer.c:360: error: unknown identifier expression in class _struct___anon_3c7b68e30000002f
/Users/roger/Documents/Code/lvglproj/lvgl/src/core/lv_observer.c:361: error: Expecting identifier after '.'
/Users/roger/Documents/Code/lvglproj/lvgl/src/core/lv_observer.c:361: error: assignment to constant value
/Users/roger/Documents/Code/lvglproj/lvgl/src/core/lv_observer.c:361: error: unknown identifier expression in class _struct___anon_3c7b68e30000002f
with these defined types
47 typedef union {
48 int32_t num; /**< Integer number (opacity, enums, booleans or "normal" numbers) */
49 const void * pointer; /**< Constant pointer (string buffer, format string, font, cone text, etc.) */
50 lv_color_t color; /**< Color */
51 #if LV_USE_FLOAT
52 float float_v; /**< Floating point value*/
53 #endif
54 } lv_subject_value_t;
59 struct _lv_subject_t {
60 #if LV_USE_EXT_DATA
61 lv_ext_data_t ext_data;
62 #endif
63 lv_ll_t subs_ll; /**< Subscribers */
64 lv_subject_value_t value; /**< Current value */
65 lv_subject_value_t prev_value; /**< Previous value */
66 lv_subject_value_t min_value; /**< Minimum value for min. int or float*/
67 lv_subject_value_t max_value; /**< Maximum value for max. int or float*/
68 void * user_data; /**< Additional parameter, can be used freely by user */
69 uint32_t type : 4; /**< One of the LV_SUBJECT_TYPE_... values */
70 uint32_t size : 24; /**< String buffer size or group length */
71 uint32_t notify_restart_query : 1; /**< If an Observer was deleted during notification,
72 * start notifying from the beginning. */
73 };
So do you think there's much/any hope for fixes that could let this be built by flexspin or is this all too much for flexspin to work with?
Googling LVGL requirements resulted in this, which I thought may be reasonable on a P2 assuming the compiler worked:
LVGL (Light and Versatile Graphics Library) is designed to be highly portable and has minimal compiler requirements, making it compatible with almost any modern embedded system. The core requirements focus on language standard compliance rather than a specific toolchain.
Core Compiler Requirements
Language Standard: A compiler supporting C99 or newer is required.
Language Support: While written in C, it is fully compatible with C++.
Build Systems: The source code is compatible with Make, CMake, and simple globbing.
Dependencies: LVGL has no external dependencies.
Minimal Hardware/Compiler Resources
To successfully compile and run LVGL, the target environment must meet these minimum standards:
Architecture: 16, 32, or 64-bit microcontroller (MCU) or processor.
Clock Speed: > 16 MHz (recommended: > 48 MHz).
Flash/ROM: > 64 kB (recommended: > 180 kB).
RAM:
Static RAM: ~2 kB (depends on features).
Stack: > 2 kB (recommended: > 8 kB).
Dynamic Data (Heap): > 2 kB (recommended: > 48 kB if using many widgets).
Buffer: A display buffer of at least 1 "Horizontal resolution" pixel size is required (recommended: > 1/10 screen size).
Unfortunately LVGL is probably too much for flexspin to deal with, at least in its current state and particularly with the added complication of external memory.
You might have better luck with riscvp2, which is full GCC and already has support for putting code into flash memory. Although given the specs of LVGL it may not need external memory at all?
I'm still thinking about how to attack external memory in flexspin, but at least some of your suggestions seem feasible. We should be able to put some kind of annotations in the output .p2asm file. In the meantime, an easy fix was increasing the number of files that can fit in a .pide, and I've done that.
@ersmith said:
Unfortunately LVGL is probably too much for flexspin to deal with, at least in its current state and particularly with the added complication of external memory.
You might have better luck with riscvp2, which is full GCC and already has support for putting code into flash memory. Although given the specs of LVGL it may not need external memory at all?
Ugh. Want to use native P2 code not RISCV instructions.
I'm reasonably confident the external memory scheme I have is likely workable. The main issue is the final performance and how large the working set will be.
@ersmith said:
I'm still thinking about how to attack external memory in flexspin, but at least some of your suggestions seem feasible. We should be able to put some kind of annotations in the output .p2asm file. In the meantime, an easy fix was increasing the number of files that can fit in a .pide, and I've done that.
Thanks! Yeah the annotations in the .p2asm file will be a big help as will be increasing the number of files possible. Also some method of checking of this int/ext memory target mode (a new #pragma state) during optimization to restrict the actual enabled optimizations in external (far) target mode is likely needed so we can keep internal functions fully optimized and not need to disable them globally just because some will break the cached code. Although for now we can probably begin without that change and simply disable all risky optimizations but performance will be lowered more than it needs to be until such a change is done as well.
If you are looking for a good test program, how about Dave Hein's awesome P2 assembler (p2_asm)?
It is written in clean C and should compile "out of the box" with any C compiler. It is completely self-contained, self-verifying (from memory there is one test that fails - testjmploc - which I keep forgetting to fix because I never use the LOC instruction), is large enough to make a good test program, and is also a very useful tool to have available on any Propeller 2!
I think Dave's original source is still online somewhere (although I can't currently find it after doing a quick search) but the source is also included in Catalina (in catalina/source/p2_asm). There are a few minor Catalina-specific extensions, but these are surrounded by #ifdef ... #endif and are disabled unless you compile it with Catalina.
@RossH said:
If you are looking for a good test program, how about Dave Hein's awesome P2 assembler (p2_asm)?
It is written in clean C and should compile "out of the box" with any C compiler. It is completely self-contained, self-verifying (from memory there is one test that fails - testjmploc - which I keep forgetting to fix because I never use the LOC instruction), is large enough to make a good test program, and is also a very useful tool to have available on any Propeller 2!
I think Dave's original source is still online somewhere (although I can't currently find it after doing a quick search) but the source is also included in Catalina (in catalina/source/p2_asm). There are a few minor Catalina-specific extensions, but these are surrounded by #ifdef ... #endif and are disabled unless you compile it with Catalina.
Ross.
Yeah I've used it before and also modified it slightly back then to allow native P2 MicroPython to work on the P2. Not a bad idea for something that might work if flexspin can compile it and if the internal RAM is sufficient for compiling programs. Will need to keep that in mind.
@ersmith said:
Unfortunately LVGL is probably too much for flexspin to deal with, at least in its current state and particularly with the added complication of external memory.
The reason I still have hope is that with some changes I made that make flexspin happier (remove inline and const and rename some variables) I've been able to get the error list down to only the same type of incompatible assignment type error and if you do end up finding a general fix for that issue it might potentially resolve all of them (with any luck).
I do have one other strange error left though which is some internal error now reported in the C startup code added automatically at the end - not part of my project list but something flexspin is adding. Strangely it is reported on line 24 and the file only goes up to line 23.
./Users/roger/Applications/spin2cpp/include/libsys/c_startup.c:24: error: Internal error, unknown type 114 passed to IsArrayType
1 //
2 // startup code for C
3 //
4 #include <sys/ioctl.h>
5 #include <sys/argv.h>
6 #include <stdlib.h>
7
8 void _c_startup()
9 {
10 int r;
11 int argc = 0;
12 char **argv;
13
14 #ifdef __FLEXC_NO_CRNL__
15 _setrxtxflags(TTY_FLAG_ECHO); // make sure TTY_FLAG_CRNL is off
16 #endif
17
18 _waitms(20); // brief pause
19 argv = __fetch_argv(&argc);
20 r = main(argc, argv);
21 _waitms(20); // brief pause
22 _Exit(r);
23 }
~
All the other ~380 errors are this type of thing...
/Users/roger/Documents/Code/lvglproj/lvgl/src/core/lv_obj_draw.c:133: error: incompatible types in assignment: expected _struct___anon_98b868fb0000006d but got unknown type
/Users/roger/Documents/Code/lvglproj/lvgl/src/core/lv_obj_draw.c:243: error: incompatible types in assignment: expected _struct___anon_98b868fb0000006d but got unknown type
/Users/roger/Documents/Code/lvglproj/lvgl/src/core/lv_obj_draw.c:470: error: incompatible types in assignment: expected _struct___anon_98b868fb0000006d but got unknown type
/Users/roger/Documents/Code/lvglproj/lvgl/src/core/lv_obj_draw.c:471: error: incompatible types in assignment: expected _struct___anon_98b868fb0000006d but got unknown type
/Users/roger/Documents/Code/lvglproj/lvgl/src/core/lv_obj_draw.c:492: error: incompatible types in assignment: expected _struct___anon_98b868fb00000079 but got unknown type
/Users/roger/Documents/Code/lvglproj/lvgl/src/core/lv_obj_draw.c:493: error: incompatible types in assignment: expected _struct___anon_98b868fb00000079 but got unknown type
/Users/roger/Documents/Code/lvglproj/lvgl/src/core/lv_obj_draw.c:500: error: incompatible types in assignment: expected _struct___anon_98b868fb00000079 but got unknown type
/Users/roger/Documents/Code/lvglproj/lvgl/src/core/lv_obj_pos.c:1151: error: incompatible types in assignment: expected _struct___anon_ea3968a50000002a but got _struct___anon_306468b10000002a
/Users/roger/Documents/Code/lvglproj/lvgl/src/core/lv_obj_style.c:650: error: incompatible types in assignment: expected _struct___anon_98b868fb00000079 but got unknown type
/Users/roger/Documents/Code/lvglproj/lvgl/src/core/lv_obj_style.c:663: error: incompatible types in assignment: expected _struct___anon_98b868fb00000079 but got unknown type
/Users/roger/Documents/Code/lvglproj/lvgl/src/core/lv_obj_style.c:997: error: incompatible types in assignment: expected _struct___anon_98b868fb0000006d but got unknown type
/Users/roger/Documents/Code/lvglproj/lvgl/src/draw/lv_draw.c:107: error: incompatible types in assignment: expected _struct___anon_306468b10000002a but got const _struct___anon_ea3968a50000002a
/Users/roger/Documents/Code/lvglproj/lvgl/src/draw/lv_draw.c:108: error: incompatible types in assignment: expected _struct___anon_306468b10000002a but got const _struct___anon_ea3968a50000002a
/Users/roger/Documents/Code/lvglproj/lvgl/src/draw/lv_draw.c:426: error: incompatible types in assignment: expected _struct___anon_98b868fb00000079 but got unknown type
/Users/roger/Documents/Code/lvglproj/lvgl/src/draw/lv_draw.c:460: error: incompatible types in assignment: expected _struct___anon_306468b10000002a but got const _struct___anon_ea3968a50000002a
/Users/roger/Documents/Code/lvglproj/lvgl/src/draw/lv_draw.c:461: error: incompatible types in assignment: expected _struct___anon_306468b10000002a but got const _struct___anon_ea3968a50000002a
/Users/roger/Documents/Code/lvglproj/lvgl/src/draw/lv_draw.c:462: error: incompatible types in assignment: expected _struct___anon_306468b10000002a but got const _struct___anon_ea3968a50000002a
/Users/roger/Documents/Code/lvglproj/lvgl/src/draw/lv_draw.c:539: error: incompatible types in assignment: expected _struct___anon_ea3968a50000002a but got _struct___anon_306468b10000002a
/Users/roger/Documents/Code/lvglproj/lvgl/src/draw/lv_draw.c:560: error: incompatible types in assignment: expected _struct___anon_ea3968a50000002a but got _struct___anon_306468b10000002a
/Users/roger/Documents/Code/lvglproj/lvgl/src/draw/lv_draw_arc.c:44: error: incompatible types in assignment: expected _struct___anon_98b868fb0000006d but got unknown type
/Users/roger/Documents/Code/lvglproj/lvgl/src/draw/lv_draw_image.c:354: error: incompatible types in assignment: expected _struct___anon_d2d368f40000006d but got _struct___anon_98b868fb0000006d
/Users/roger/Documents/Code/lvglproj/lvgl/src/draw/lv_draw_image.c:53: error: incompatible types in assignment: expected _struct___anon_98b868fb0000006d but got unknown type
/Users/roger/Documents/Code/lvglproj/lvgl/src/draw/lv_draw_label.c:358: error: incompatible types in assignment: expected _struct___anon_98b868fb0000006d but got unknown type
/Users/roger/Documents/Code/lvglproj/lvgl/src/draw/lv_draw_label.c:460: error: incompatible types in assignment: expected _struct___anon_98b868fb0000006d but got unknown type
/Users/roger/Documents/Code/lvglproj/lvgl/src/draw/lv_draw_label.c:500: error: incompatible types in assignment: expected _struct___anon_98b868fb0000006d but got _struct___anon_d2d368f40000006d
/Users/roger/Documents/Code/lvglproj/lvgl/src/draw/lv_draw_label.c:510: error: incompatible types in assignment: expected _struct___anon_98b868fb0000006d but got _struct___anon_d2d368f40000006d
/Users/roger/Documents/Code/lvglproj/lvgl/src/draw/lv_draw_label.c:519: error: incompatible types in assignment: expected _struct___anon_98b868fb0000006d but got _struct___anon_d2d368f40000006d
/Users/roger/Documents/Code/lvglproj/lvgl/src/draw/lv_draw_label.c:523: error: incompatible types in assignment: expected _struct___anon_d2d368f40000006d but got _struct___anon_98b868fb0000006d
@RossH said:
If you are looking for a good test program, how about Dave Hein's awesome P2 assembler (p2_asm)?
It is written in clean C and should compile "out of the box" with any C compiler. It is completely self-contained, self-verifying (from memory there is one test that fails - testjmploc - which I keep forgetting to fix because I never use the LOC instruction), is large enough to make a good test program, and is also a very useful tool to have available on any Propeller 2!
I think Dave's original source is still online somewhere (although I can't currently find it after doing a quick search) but the source is also included in Catalina (in catalina/source/p2_asm). There are a few minor Catalina-specific extensions, but these are surrounded by #ifdef ... #endif and are disabled unless you compile it with Catalina.
Ross.
Yeah I've used it before and also modified it slightly back then to allow native P2 MicroPython to work on the P2. Not a bad idea for something that might work if flexspin can compile it and if the internal RAM is sufficient for compiling programs. Will need to keep that in mind.
It does seem to build on Flexspin first time (only two warnings) and consumes 884416 bytes, so yes it's a good candidate for running from external RAM. I'll have to see how much internal RAM it needs to run ok and try to setup some sort of test with a filesystem somehow. Unfortunately right now I'm getting segfaults with my psram driver and flexspin building it so not sure what is going on, worked fine a few days ago when I used it last. Need to figure it out and fix that first.
EDIT: Actually that 884416 was wrong because that number was before running my script on it, and it included some of the p2asm data structures. The symbol table consumed 320000 bytes, and the data buffer was set to 1000000 bytes. So of the 1408704 bytes reported the actual total assembler program code is very small, only 88704 bytes. It's arguable whether it's worth putting that into external memory when you still need a cache and block map table, may as well keep it in internal hub RAM. Maybe if the linker is included it will consume more...yep but only 47kB, and data is 2.6MB! I guess some of that could be put into external RAM as well).
Cheers,
Roger.
Propeller Spin/PASM Compiler 'FlexSpin' (c) 2011-2026 Total Spectrum Software Inc. and contributors
Version 7.6.2 Compiled on: Mar 2 2026
p2asm.c
symsubs.c
strsubs.c
c_startup.c
/Users/roger/Documents/Code/p2gcc/p2asm_src/p2asm.c:1698: warning: variable srcval may be used before it is set in function ParseDat
/Users/roger/Documents/Code/p2gcc/p2asm_src/strsubs.c:110: warning: variable len may be used before it is set in function Tokenize
fmt.c
fprintf.c
sscanf.c
fgets.c
fopen.c
fwrite.c
fseek.c
strcat.c
strcmp.c
strncmp.c
exit.c
_Exit.c
ctype.c
toupper.c
argv.c
basicfmt.c
ieee32.c
s_floorf.c
vfs.c
posixio.c
bufio.c
isatty.c
fputs.c
vfscanf.c
stringio.c
fflush.c
fileno.c
dofmt.c
posixio.c
fmt.c
errno.c
bufio.c
ioctl.c
isxdigit.c
tolower.c
mbrtowc_ascii.c
_mount.c
powers.c
vfs.c
strncpy.c
strncat.c
strncmp.c
p2asm.p2asm
warning: final output size of 1408704 bytes exceeds maximum of 524288 by 884416 bytes
warning: output size with debugger (1408704 + 0 = 1408704) exceeds maximum of 524288 by 884416 bytes
Done.
Program size is 1408704 bytes
Another good candidate would be Lua - written in clean C which should compile with any C compiler, completely self-contained and also easy to verify. And with a code size around 250kb.
A word of warning though - once you start programming in Lua, you won't ever want to go back to any other language!
@ersmith said:
You might have better luck with riscvp2, which is full GCC and already has support for putting code into flash memory. Although given the specs of LVGL it may not need external memory at all?
Ugh. Want to use native P2 code not RISCV instructions.
How much are you writing in assembly though? If you're worried about performance, riscvp2 does eventually compile the code to native P2, just at runtime rather than ahead of time. It's coremark score is around 52 iterations/sec at 180 MHz (when run from HUB or Flash; results are the same either way) vs around 37 iterations/sec for flexspin and 17 for an older Catalina.
I was remiss earlier in not mentioning Catalina, which already has external memory support too. Although I'd definitely be very happy to have you continue to work on an external memory solution for flexspin, which would be awesome but if you need something working sooner then Catalina may do the job.
The reason I still have hope is that with some changes I made that make flexspin happier (remove inline and const and rename some variables) I've been able to get the error list down to only the same type of incompatible assignment type error and if you do end up finding a general fix for that issue it might potentially resolve all of them (with any luck).
I'll continue looking into that. On that note, do you think you could re-post your current code? The all.zip that you posted up-thread was missing the actual lvgl directory .
I do have one other strange error left though which is some internal error now reported in the C startup code added automatically at the end - not part of my project list but something flexspin is adding. Strangely it is reported on line 24 and the file only goes up to line 23. ./Users/roger/Applications/spin2cpp/include/libsys/c_startup.c:24: error: Internal error, unknown type 114 passed to IsArrayType
When the error comes at the end of the file like that it usually means it's some internal issue not really associated with any source code (and the source file name is probably bogus too). The particular error is complaining about trying to find the type, and 114 is an AST_USING, so it's probably upset about a struct __using statement somewhere. It might be related somehow to the other struct errors, hard to say.


Comments
Just did the real run from PSRAM test using P2-EVAL and my own PSRAM board at 160MHz. Only made a small improvement in the total tick count but that's to be expected given the number of iterations and the fact that only 31 rows are ever loaded.
Worked first go which is great but almost makes me believe it's not real. Now want to intentionally impair PSRAM to ensure it's legit. Will just yank the breakout board out for that. UPDATE: yep crashed right away with the board removed. So it's loading the code from the PSRAM now!
@roghloh
I thought the P2 was originally designed for a maximum 180Mhz clock speed, although it has since shown it can generally go much, much faster. For myself I tend to use 200Mhz, but Catalina's default is 180Mhz, because I thought that was still the design maximum. If there is now a reason to make the default slower than that, I'd like to know it.
That would be analogous to Catalina's SMALL mode, which only stores code in external RAM (as opposed to LARGE mode is where both code and data are stored in external RAM). But even multi-processing in SMALL mode would be a huge win. My biggest problem is that I always tried to keep Catalina compatible with both the P1 and the P2, which I have (just about!) managed. But that is largely just nostalgia on my part - I have really fond memories of the P1, but I knew one day this compatibility would probably have to come to an end.
I will follow progress with interest")
There's no reason for that IMO, 160MHz is just what flexspin had setup as the default from way back.
I think it's probably doable to have multiple COGs sharing the external RAM for their code (or even run different code as separate applications). Right now for this proof of concept setup I init an I-cache and block mapping table at startup time in another linked module called extmem.c whose addresses I pass into the COG external memory handler routines executed from LUTRAM during startup. The only change needed would be to not have this as defined a global variable block but allocated on a per COG stack instead via alloca in main() or something like that. I'm running the cache transfer requests through my external memory mailbox so other COGs can certainly make other requests in parallel to the COG executing external C routines. I can easily already prove that out to myself by introducing another video COG which shares the memory but I know it would work, just slower.
Probably originates from the Prop2-Hot days. Its design was targetted for 160 MHz I think.
Now I have something functioning running via external memory and a cache, I was wondering about some of the potential target applications that might work with a larger memory model on a P2. I wonder if flexspin/spin2cpp could be setup to compile itself as a P2 application or whether the small 512k of HUBRAM for data would be a major limitation. This is assuming most/all of the executable code is stored externally with say a 64kB I-cache and (say) a 16-32kB block mapping table and some required library and filesystem APIs are present leaving up to 436kB or so for data. Flexspin on my Mac is only a 2.8MB executable so with any luck it might still compile to fit within some 16MB external address space (PSRAM) on a P2. I guess there would be some native OS and memory management APIs used that would need to be ported/provided on a P2 but it's more of whether it could be made to compile with much less available RAM for data that I'd be concerned about.
Is there any scope for something like this or is it a fools errand even considering the idea compiling flexspin source from itself, especially without a linker?
Output of make for building spin2cpp etc is shown below. It has dependencies on bison and builds each module separately before final link step.
bison -p spinyy -t -b build/spin -d frontends/spin/spin.y bison -p basicyy -t -b build/basic -d frontends/basic/basic.y bison -p cgramyy -t -b build/cgram -d frontends/c/cgram.y frontends/c/cgram.y: conflicts: 5 shift/reduce gcc -g -Wall -fwrapv -Wc++-compat -I. -I./backends -I./frontends -Ibuild -DFLEXSPIN_BUILD -o build/lexer.o -c frontends/lexer.c gcc -MMD -MP -g -Wall -fwrapv -Wc++-compat -I. -I./backends -I./frontends -Ibuild -DFLEXSPIN_BUILD -o build/uni2sjis.o -c frontends/uni2sjis.c gcc -MMD -MP -g -Wall -fwrapv -Wc++-compat -I. -I./backends -I./frontends -Ibuild -DFLEXSPIN_BUILD -o build/symbol.o -c symbol.c gcc -MMD -MP -g -Wall -fwrapv -Wc++-compat -I. -I./backends -I./frontends -Ibuild -DFLEXSPIN_BUILD -o build/ast.o -c ast.c gcc -MMD -MP -g -Wall -fwrapv -Wc++-compat -I. -I./backends -I./frontends -Ibuild -DFLEXSPIN_BUILD -o build/expr.o -c expr.c gcc -MMD -MP -g -Wall -fwrapv -Wc++-compat -I. -I./backends -I./frontends -Ibuild -DFLEXSPIN_BUILD -o build/dofmt.o -c util/dofmt.c gcc -MMD -MP -g -Wall -fwrapv -Wc++-compat -I. -I./backends -I./frontends -Ibuild -DFLEXSPIN_BUILD -o build/flexbuf.o -c util/flexbuf.c gcc -MMD -MP -g -Wall -fwrapv -Wc++-compat -I. -I./backends -I./frontends -Ibuild -DFLEXSPIN_BUILD -o build/lltoa_prec.o -c util/lltoa_prec.c gcc -MMD -MP -g -Wall -fwrapv -Wc++-compat -I. -I./backends -I./frontends -Ibuild -DFLEXSPIN_BUILD -o build/strupr.o -c util/strupr.c gcc -MMD -MP -g -Wall -fwrapv -Wc++-compat -I. -I./backends -I./frontends -Ibuild -DFLEXSPIN_BUILD -o build/strrev.o -c util/strrev.c gcc -MMD -MP -g -Wall -fwrapv -Wc++-compat -I. -I./backends -I./frontends -Ibuild -DFLEXSPIN_BUILD -o build/strdupcat.o -c util/strdupcat.c gcc -MMD -MP -g -Wall -fwrapv -Wc++-compat -I. -I./backends -I./frontends -Ibuild -DFLEXSPIN_BUILD -o build/to_utf8.o -c util/to_utf8.c gcc -MMD -MP -g -Wall -fwrapv -Wc++-compat -I. -I./backends -I./frontends -Ibuild -DFLEXSPIN_BUILD -o build/from_utf8.o -c util/from_utf8.c gcc -MMD -MP -g -Wall -fwrapv -Wc++-compat -I. -I./backends -I./frontends -Ibuild -DFLEXSPIN_BUILD -o build/sha256.o -c util/sha256.c gcc -MMD -MP -g -Wall -fwrapv -Wc++-compat -I. -I./backends -I./frontends -Ibuild -DFLEXSPIN_BUILD -o build/softcordic.o -c util/softcordic.c gcc -MMD -MP -g -Wall -fwrapv -Wc++-compat -I. -I./backends -I./frontends -Ibuild -DFLEXSPIN_BUILD -o build/preprocess.o -c preprocess.c gcc -g -Wall -fwrapv -Wc++-compat -I. -I./backends -I./frontends -Ibuild -DFLEXSPIN_BUILD -o build/testlex testlex.c build/lexer.o build/uni2sjis.o build/symbol.o build/ast.o build/expr.o build/dofmt.o build/flexbuf.o build/lltoa_prec.o build/strupr.o build/strrev.o build/strdupcat.o build/to_utf8.o build/from_utf8.o build/sha256.o build/softcordic.o build/preprocess.o -lm gcc -MMD -MP -g -Wall -fwrapv -Wc++-compat -I. -I./backends -I./frontends -Ibuild -DFLEXSPIN_BUILD -o build/common.o -c frontends/common.c gcc -MMD -MP -g -Wall -fwrapv -Wc++-compat -I. -I./backends -I./frontends -Ibuild -DFLEXSPIN_BUILD -o build/case.o -c frontends/case.c gcc -MMD -MP -g -Wall -fwrapv -Wc++-compat -I. -I./backends -I./frontends -Ibuild -DFLEXSPIN_BUILD -o build/spinc.o -c spinc.c gcc -MMD -MP -g -Wall -fwrapv -Wc++-compat -I. -I./backends -I./frontends -Ibuild -DFLEXSPIN_BUILD -o build/functions.o -c functions.c gcc -MMD -MP -g -Wall -fwrapv -Wc++-compat -I. -I./backends -I./frontends -Ibuild -DFLEXSPIN_BUILD -o build/cse.o -c cse.c gcc -MMD -MP -g -Wall -fwrapv -Wc++-compat -I. -I./backends -I./frontends -Ibuild -DFLEXSPIN_BUILD -o build/loops.o -c loops.c gcc -MMD -MP -g -Wall -fwrapv -Wc++-compat -I. -I./backends -I./frontends -Ibuild -DFLEXSPIN_BUILD -o build/hloptimize.o -c frontends/hloptimize.c gcc -MMD -MP -g -Wall -fwrapv -Wc++-compat -I. -I./backends -I./frontends -Ibuild -DFLEXSPIN_BUILD -o build/hltransform.o -c frontends/hltransform.c gcc -MMD -MP -g -Wall -fwrapv -Wc++-compat -I. -I./backends -I./frontends -Ibuild -DFLEXSPIN_BUILD -o build/types.o -c frontends/types.c gcc -MMD -MP -g -Wall -fwrapv -Wc++-compat -I. -I./backends -I./frontends -Ibuild -DFLEXSPIN_BUILD -o build/pasm.o -c pasm.c gcc -MMD -MP -g -Wall -fwrapv -Wc++-compat -I. -I./backends -I./frontends -Ibuild -DFLEXSPIN_BUILD -o build/outdat.o -c backends/dat/outdat.c gcc -MMD -MP -g -Wall -fwrapv -Wc++-compat -I. -I./backends -I./frontends -Ibuild -DFLEXSPIN_BUILD -o build/outlst.o -c backends/dat/outlst.c gcc -MMD -MP -g -Wall -fwrapv -Wc++-compat -I. -I./backends -I./frontends -Ibuild -DFLEXSPIN_BUILD -o build/outobj.o -c backends/objfile/outobj.c gcc -MMD -MP -g -Wall -fwrapv -Wc++-compat -I. -I./backends -I./frontends -Ibuild -DFLEXSPIN_BUILD -o build/spinlang.o -c frontends/spin/spinlang.c gcc -MMD -MP -g -Wall -fwrapv -Wc++-compat -I. -I./backends -I./frontends -Ibuild -DFLEXSPIN_BUILD -o build/basiclang.o -c frontends/basic/basiclang.c gcc -MMD -MP -g -Wall -fwrapv -Wc++-compat -I. -I./backends -I./frontends -Ibuild -DFLEXSPIN_BUILD -o build/clang.o -c frontends/c/clang.c gcc -MMD -MP -g -Wall -fwrapv -Wc++-compat -I. -I./backends -I./frontends -Ibuild -DFLEXSPIN_BUILD -o build/bflang.o -c frontends/bf/bflang.c gcc -MMD -MP -g -Wall -fwrapv -Wc++-compat -I. -I./backends -I./frontends -Ibuild -DFLEXSPIN_BUILD -o build/outasm.o -c backends/asm/outasm.c gcc -MMD -MP -g -Wall -fwrapv -Wc++-compat -I. -I./backends -I./frontends -Ibuild -DFLEXSPIN_BUILD -o build/assemble_ir.o -c backends/asm/assemble_ir.c gcc -MMD -MP -g -Wall -fwrapv -Wc++-compat -I. -I./backends -I./frontends -Ibuild -DFLEXSPIN_BUILD -o build/optimize_ir.o -c backends/asm/optimize_ir.c gcc -MMD -MP -g -Wall -fwrapv -Wc++-compat -I. -I./backends -I./frontends -Ibuild -DFLEXSPIN_BUILD -o build/asm_peep.o -c backends/asm/asm_peep.c gcc -MMD -MP -g -Wall -fwrapv -Wc++-compat -I. -I./backends -I./frontends -Ibuild -DFLEXSPIN_BUILD -o build/inlineasm.o -c backends/asm/inlineasm.c gcc -MMD -MP -g -Wall -fwrapv -Wc++-compat -I. -I./backends -I./frontends -Ibuild -DFLEXSPIN_BUILD -o build/compress_ir.o -c backends/asm/compress_ir.c gcc -MMD -MP -g -Wall -fwrapv -Wc++-compat -I. -I./backends -I./frontends -Ibuild -DFLEXSPIN_BUILD -o build/outbc.o -c backends/bytecode/outbc.c gcc -MMD -MP -g -Wall -fwrapv -Wc++-compat -I. -I./backends -I./frontends -Ibuild -DFLEXSPIN_BUILD -o build/bcbuffers.o -c backends/bcbuffers.c gcc -MMD -MP -g -Wall -fwrapv -Wc++-compat -I. -I./backends -I./frontends -Ibuild -DFLEXSPIN_BUILD -o build/bcir.o -c backends/bytecode/bcir.c gcc -MMD -MP -g -Wall -fwrapv -Wc++-compat -I. -I./backends -I./frontends -Ibuild -DFLEXSPIN_BUILD -o build/bc_spin1.o -c backends/bytecode/bc_spin1.c gcc -MMD -MP -g -Wall -fwrapv -Wc++-compat -I. -I./backends -I./frontends -Ibuild -DFLEXSPIN_BUILD -o build/outnu.o -c backends/nucode/outnu.c gcc -MMD -MP -g -Wall -fwrapv -Wc++-compat -I. -I./backends -I./frontends -Ibuild -DFLEXSPIN_BUILD -o build/nuir.o -c backends/nucode/nuir.c gcc -MMD -MP -g -Wall -fwrapv -Wc++-compat -I. -I./backends -I./frontends -Ibuild -DFLEXSPIN_BUILD -o build/nupeep.o -c backends/nucode/nupeep.c gcc -MMD -MP -g -Wall -fwrapv -Wc++-compat -I. -I./backends -I./frontends -Ibuild -DFLEXSPIN_BUILD -o build/outcpp.o -c backends/cpp/outcpp.c gcc -MMD -MP -g -Wall -fwrapv -Wc++-compat -I. -I./backends -I./frontends -Ibuild -DFLEXSPIN_BUILD -o build/cppfunc.o -c backends/cpp/cppfunc.c gcc -MMD -MP -g -Wall -fwrapv -Wc++-compat -I. -I./backends -I./frontends -Ibuild -DFLEXSPIN_BUILD -o build/outgas.o -c backends/cpp/outgas.c gcc -MMD -MP -g -Wall -fwrapv -Wc++-compat -I. -I./backends -I./frontends -Ibuild -DFLEXSPIN_BUILD -o build/cppexpr.o -c backends/cpp/cppexpr.c gcc -MMD -MP -g -Wall -fwrapv -Wc++-compat -I. -I./backends -I./frontends -Ibuild -DFLEXSPIN_BUILD -o build/cppbuiltin.o -c backends/cpp/cppbuiltin.c gcc -MMD -MP -g -Wall -fwrapv -Wc++-compat -I. -I./backends -I./frontends -Ibuild -DFLEXSPIN_BUILD -o build/compress.o -c backends/compress/compress.c gcc -MMD -MP -g -Wall -fwrapv -Wc++-compat -I. -I./backends -I./frontends -Ibuild -DFLEXSPIN_BUILD -o build/lz4.o -c backends/compress/lz4/lz4.c gcc -MMD -MP -g -Wall -fwrapv -Wc++-compat -I. -I./backends -I./frontends -Ibuild -DFLEXSPIN_BUILD -o build/lz4hc.o -c backends/compress/lz4/lz4hc.c gcc -MMD -MP -g -Wall -fwrapv -Wc++-compat -I. -I./backends -I./frontends -Ibuild -DFLEXSPIN_BUILD -o build/outzip.o -c backends/zip/outzip.c gcc -MMD -MP -g -Wall -fwrapv -Wc++-compat -I. -I./backends -I./frontends -Ibuild -DFLEXSPIN_BUILD -o build/zip.o -c backends/zip/zip.c gcc -MMD -MP -g -Wall -fwrapv -Wc++-compat -I. -I./backends -I./frontends -Ibuild -DFLEXSPIN_BUILD -o build/directive.o -c mcpp/directive.c gcc -MMD -MP -g -Wall -fwrapv -Wc++-compat -I. -I./backends -I./frontends -Ibuild -DFLEXSPIN_BUILD -o build/expand.o -c mcpp/expand.c gcc -MMD -MP -g -Wall -fwrapv -Wc++-compat -I. -I./backends -I./frontends -Ibuild -DFLEXSPIN_BUILD -o build/mbchar.o -c mcpp/mbchar.c gcc -MMD -MP -g -Wall -fwrapv -Wc++-compat -I. -I./backends -I./frontends -Ibuild -DFLEXSPIN_BUILD -o build/mcpp_eval.o -c mcpp/mcpp_eval.c gcc -MMD -MP -g -Wall -fwrapv -Wc++-compat -I. -I./backends -I./frontends -Ibuild -DFLEXSPIN_BUILD -o build/mcpp_main.o -c mcpp/mcpp_main.c gcc -MMD -MP -g -Wall -fwrapv -Wc++-compat -I. -I./backends -I./frontends -Ibuild -DFLEXSPIN_BUILD -o build/mcpp_system.o -c mcpp/mcpp_system.c gcc -MMD -MP -g -Wall -fwrapv -Wc++-compat -I. -I./backends -I./frontends -Ibuild -DFLEXSPIN_BUILD -o build/mcpp_support.o -c mcpp/mcpp_support.c gcc -g -Wall -fwrapv -Wc++-compat -I. -I./backends -I./frontends -Ibuild -DFLEXSPIN_BUILD -DGITREV=v7.6.1-11-g71ce9b99 -o build/version.o -c version.c gcc -MMD -MP -g -Wall -fwrapv -Wc++-compat -I. -I./backends -I./frontends -Ibuild -DFLEXSPIN_BUILD -o build/becommon.o -c backends/becommon.c gcc -MMD -MP -g -Wall -fwrapv -Wc++-compat -I. -I./backends -I./frontends -Ibuild -DFLEXSPIN_BUILD -o build/brkdebug.o -c backends/brkdebug.c gcc -MMD -MP -g -Wall -fwrapv -Wc++-compat -I. -I./backends -I./frontends -Ibuild -DFLEXSPIN_BUILD -o build/printdebug.o -c frontends/printdebug.c gcc -g -Wall -fwrapv -Wc++-compat -I. -I./backends -I./frontends -Ibuild -DFLEXSPIN_BUILD -o build/spin.tab.o -c build/spin.tab.c build/spin.tab.c:8750:5: warning: variable 'spinyynerrs' set but not used [-Wunused-but-set-variable] int yynerrs; ^ build/spin.tab.c:68:17: note: expanded from macro 'yynerrs' #define yynerrs spinyynerrs ^ 1 warning generated. gcc -g -Wall -fwrapv -Wc++-compat -I. -I./backends -I./frontends -Ibuild -DFLEXSPIN_BUILD -o build/basic.tab.o -c build/basic.tab.c build/basic.tab.c:3843:5: warning: variable 'basicyynerrs' set but not used [-Wunused-but-set-variable] int yynerrs; ^ build/basic.tab.c:68:17: note: expanded from macro 'yynerrs' #define yynerrs basicyynerrs ^ 1 warning generated. gcc -g -Wall -fwrapv -Wc++-compat -I. -I./backends -I./frontends -Ibuild -DFLEXSPIN_BUILD -o build/cgram.tab.o -c build/cgram.tab.c build/cgram.tab.c:3944:5: warning: variable 'cgramyynerrs' set but not used [-Wunused-but-set-variable] int yynerrs; ^ build/cgram.tab.c:68:17: note: expanded from macro 'yynerrs' #define yynerrs cgramyynerrs ^ 1 warning generated. gcc -g -Wall -fwrapv -Wc++-compat -I. -I./backends -I./frontends -Ibuild -DFLEXSPIN_BUILD -o build/spin2cpp spin2cpp.c cmdline.c build/common.o build/case.o build/spinc.o build/lexer.o build/uni2sjis.o build/symbol.o build/ast.o build/expr.o build/dofmt.o build/flexbuf.o build/lltoa_prec.o build/strupr.o build/strrev.o build/strdupcat.o build/to_utf8.o build/from_utf8.o build/sha256.o build/softcordic.o build/preprocess.o build/functions.o build/cse.o build/loops.o build/hloptimize.o build/hltransform.o build/types.o build/pasm.o build/outdat.o build/outlst.o build/outobj.o build/spinlang.o build/basiclang.o build/clang.o build/bflang.o build/outasm.o build/assemble_ir.o build/optimize_ir.o build/asm_peep.o build/inlineasm.o build/compress_ir.o build/outbc.o build/bcbuffers.o build/bcir.o build/bc_spin1.o build/outnu.o build/nuir.o build/nupeep.o build/outcpp.o build/cppfunc.o build/outgas.o build/cppexpr.o build/cppbuiltin.o build/compress.o build/lz4.o build/lz4hc.o build/outzip.o build/zip.o build/directive.o build/expand.o build/mbchar.o build/mcpp_eval.o build/mcpp_main.o build/mcpp_system.o build/mcpp_support.o build/version.o build/becommon.o build/brkdebug.o build/printdebug.o build/spin.tab.o build/basic.tab.o build/cgram.tab.o -lm gcc -g -Wall -fwrapv -Wc++-compat -I. -I./backends -I./frontends -Ibuild -DFLEXSPIN_BUILD -o build/flexspin flexspin.c cmdline.c build/common.o build/case.o build/spinc.o build/lexer.o build/uni2sjis.o build/symbol.o build/ast.o build/expr.o build/dofmt.o build/flexbuf.o build/lltoa_prec.o build/strupr.o build/strrev.o build/strdupcat.o build/to_utf8.o build/from_utf8.o build/sha256.o build/softcordic.o build/preprocess.o build/functions.o build/cse.o build/loops.o build/hloptimize.o build/hltransform.o build/types.o build/pasm.o build/outdat.o build/outlst.o build/outobj.o build/spinlang.o build/basiclang.o build/clang.o build/bflang.o build/outasm.o build/assemble_ir.o build/optimize_ir.o build/asm_peep.o build/inlineasm.o build/compress_ir.o build/outbc.o build/bcbuffers.o build/bcir.o build/bc_spin1.o build/outnu.o build/nuir.o build/nupeep.o build/outcpp.o build/cppfunc.o build/outgas.o build/cppexpr.o build/cppbuiltin.o build/compress.o build/lz4.o build/lz4hc.o build/outzip.o build/zip.o build/directive.o build/expand.o build/mbchar.o build/mcpp_eval.o build/mcpp_main.o build/mcpp_system.o build/mcpp_support.o build/version.o build/becommon.o build/brkdebug.o build/printdebug.o build/spin.tab.o build/basic.tab.o build/cgram.tab.o -lm gcc -g -Wall -fwrapv -Wc++-compat -I. -I./backends -I./frontends -Ibuild -DFLEXSPIN_BUILD -o build/flexcc flexcc.c cmdline.c build/common.o build/case.o build/spinc.o build/lexer.o build/uni2sjis.o build/symbol.o build/ast.o build/expr.o build/dofmt.o build/flexbuf.o build/lltoa_prec.o build/strupr.o build/strrev.o build/strdupcat.o build/to_utf8.o build/from_utf8.o build/sha256.o build/softcordic.o build/preprocess.o build/functions.o build/cse.o build/loops.o build/hloptimize.o build/hltransform.o build/types.o build/pasm.o build/outdat.o build/outlst.o build/outobj.o build/spinlang.o build/basiclang.o build/clang.o build/bflang.o build/outasm.o build/assemble_ir.o build/optimize_ir.o build/asm_peep.o build/inlineasm.o build/compress_ir.o build/outbc.o build/bcbuffers.o build/bcir.o build/bc_spin1.o build/outnu.o build/nuir.o build/nupeep.o build/outcpp.o build/cppfunc.o build/outgas.o build/cppexpr.o build/cppbuiltin.o build/compress.o build/lz4.o build/lz4hc.o build/outzip.o build/zip.o build/directive.o build/expand.o build/mbchar.o build/mcpp_eval.o build/mcpp_main.o build/mcpp_system.o build/mcpp_support.o build/version.o build/becommon.o build/brkdebug.o build/printdebug.o build/spin.tab.o build/basic.tab.o build/cgram.tab.o -lmInteresting observation. Running CoreMark with the I-cache row count total configured as 4 active rows each containing 256 byte blocks (instead of 255 rows I used above) still works! Performance drops by half. It's quite a small test program so its working set is very small. In this case the I-cache is only 1kB in size holding 256 P2 instructions. I probably should add some cache row load/miss counter which would help in dimensioning the cache size for the application.
@rogloh
Go for it! Catalina could use some competition!")
Currently wondering where to go next with this code...
So far I've basically proven the general concept of using flexspin to build code to run with external memory can be made to work on a P2.
I've found that prefixing "FAR_" to function names to identify them for storage in the external memory segment is rather tedious when the project contains lots of files and functions. Not only do you need to modify all the source code that will target the external memory, the calling code also has to be modified to prefix the same FAR_ to the function name. This is not really very scalable and was only done for this proof of concept in order to get something working before flexspin might potentially be modified to enable a proper external memory solution.
Another alternative is to locate all code in external memory by default when the external memory option is enabled for the build and perhaps use some function list or attribute that places some subset of this code in internal memory otherwise. This is better if you wanted to port a large project to the P2, the bulk of which would be held in external RAM but has some small number of critical loop / non-cachable functions which make sense to keep in internal hub RAM for sharing with other COGs (eg. any included SPIN2 object APIs) or if it could really benefit from some optimizations that are only allowed in regular internal memory code to increase performance further.
I've started down that path but already found one big problem with this plan is that the cache initialization step at startup time requires some minimal number of functions to be called before the PSRAM is configured to respond to cache row loading. Right now it that would be identifying the PSRAM mailbox address and running the PSRAM startup code and these API functions are needed to be called before the system is ready to execute from external memory. So some method of identifying which functions need to remain in HUBRAM is going to be required even just for system initialization at the very start, even if everything else targets external memory for storage.
If this external memory functionality is going to become available in flexspin we ideally require some way to quickly identify which functions are to be placed into external memory, possibly by using some new #define or #pragma, or use some new attribute list option per function.
For now I believe it's probably easier to just enable this external memory code storage feature on a file by file basis and selectively pull out the functions that need to remain in internal hub memory - you could probably move them into other files if the set is small. One way I was thinking of how to achieve it is just to separate the internal/external module's functions by their module file order on the command line, with the extmem.c module that configures the external memory also being the delimiter that separates them. Something like
flexspin -2 main.c intmodule1.c intmodule2.c extmem.c extmodule1.c extmodule2.cThis keeps main.c, intmodule.c intmodule2.c and extmem.c in internal memory, while storing extmodule1.c and extmodule2.c in PSRAM for example.
I started going down this path and am already finding that for the standard library functions that get called, we don't really get much control as they are simply included by whatever parent module calls them, and they'll sit in the same location as their caller. So it's still not ideal.
Any other ideas on the best way forward with this...?
ps. I'm looking at the LVGL project (GUI/graphics library) as something that might be useful as a demo for this external memory feature. A large amount of its code could be stored in external memory keeping hub RAM free for other stuff (including a graphics framebuffer). Unfortunately I'm currently having issues with its build process with flexspin in general so it may not be a good example demo if I can't get it to build with flexspin. Still learning/persevering for now before possibly abandoning the idea...by default lvgl seems to want to build a static library that is then linked to the application code whilst flexspin wants all files on the same command line and doesn't directly support linking. Not sure if/how it can be split up instead.
@rogloh
I think you are on the right track doing it file by file using compile-time options. Trying to do it within the language without mangling things too much would be tricky (look at the complexities Microsoft had to introduce in their version of C to accommodate "near" and "far" pointers). Ideally, you compile each file separately with the appropriate memory model, and then use a binary linker to figure out to to put it all together and get it to execute.
But that assumes you have a suitable linker. I don't know much about flexspin - maybe it has one you can modify. But it would be a big job!
Catalina does not have a linker - for programs that use a single memory model you don't really need a linker - and for programs that use multiple memory models I built a separate utility (called Catapult) to help automate the build process. Catapult essentially turns anything to be executed from Hub RAM into a binary blob that can be loaded at run time either from external memory or from a disk file. The blobs can be loaded in separate Hub RAM locations, or all in the one location (i.e. as overlays). In Catalina, each component executes on a different cog, and they communicate via the Registry - this sounds complex but it actually simplifies many things. However, that would not be an option in flexspin - you might have to implement something similar yourself. But even when using Catapult you still effectively have do the linkage between the components yourself.
See (for example) demos/catapult/srv_c_p2.c - the my_service_list table in that program is essentially doing manually what it would be ideal to have a linker or other utility do automatically - it does so by using "proxy" functions. When I get time I may add the capability for Catapult to automatically generate those proxy functions. This would have been too difficult for me to do in lcc (which is a bit of a monster) but now that Catalina also uses Cake (which does semantic analysis of the C source code) it should be a lot easier. But even if the proxy functions have to be manually created, the idea of using them may be worth exploring - all the complexity could at least be contained in one file.
One downside of the way Catalina does things is that if both a hub function and an external function call the same functions, you end up with two completely separate copies of each called function - one that executes from Hub RAM, and the other that executes from external RAM. Again, this makes some things easier, but it also complicates other things if the functions are not built to deal with such a possibility - for example, you cannot use stdio library functions from two different components - all stdio library calls have to be done from within one of the components.
Ross.
@rogloh
I was thinking some more about this last night. In particular, the idea of using "proxy" functions, which do whatever is required to invoke the actual functions compiled to use a different memory model.
In my previous post I thought that this would require additional processing of the source code to generate the necessary information, but my midnight brainwave was that debuggers already require the same information. For example, Catalina's -g option causes lcc to generate a standard "stabs" file (with a .debug extension) containing information about each function in the source. Catalina's Blackbox debugger uses this information.
You may find that flexspin has something similar that could help automate the creation of proxy functions.
Another option would be to add pragmas to the source code to include the necessary information required to call each external function compiled with a different memory model. This does not require a change in the language, and is probably the option I will explore first, because Catapult already uses pragmas (and processing "stabs" files is a black art!).
Ross.
Interesting, I guess one issue with that is that it would slow down ALL function calls via these proxies.
I don't think flexspin has that. The only other output file I know of apart from the .p2asm intermediate source is the listing file. And that just gives me opcodes and preliminary HUB RAM addresses assuming a normal internal memory target for everything in the set of files passed. This p2asm file is what I mess about with with my sed scripts to reorder it and insert an ORG $100000 at the internal/external address boundary before re-assembling the updated file to a final binary.
I think a special pragma to enable and disable external memory target (applies globally) would be useful. If the command line input is sorted to be internal modules first following by external modules, then a single pragma could change the target model applied from then on when invoked (until it is optionally disabled). This would avoid needing lots of source code modifications. It could simply be placed in a single file once (e.g my extmem.c file) and it would also limit which optimizations can be applied to the functions it compiles when enabled. Otherwise adding a special "FAR" attribute per function is a lot of changes if the source code is extensive. Then if you do have a few special functions in your mostly external source that do need to target internal memory instead you could either pull them out into a separate file or if not, just place the pragma around those functions to disable/re-enable FAR mode at will. It's probably the most convenient way to go.
After testing out the method of separating code by command line order it looks like I was wrong about how flexspin brings in its dependent functions called by each of its compiled modules. I'm now not totally sure how it generates the order of code in the p2asm output file. A few internal library functions get pulled into the same part of the code that calls them, but most library functions seem to actually be placed at the end of the group of compiled files. What differentiates this actual placement I don't know.
Here's the function order in the image you get when building the coremark benchmark according to this command line file order.
flexspin -DITERATIONS=200 -O0,const -gbrk core_main.c extmem.c core_list_join.c core_util.c core_matrix.c core_state.c core_portme.cIt starts out with a small handful of internal functions, then the module code seem to follow, then some more internal library functions, then some SPIN2 modules incorporated in the C source, then a whole bunch of
__system__prefixed functions. I guess I can try to place some fixed file at the end of the compiled file list that defines a specific function name I can search for to disable external memory placement in my scripts... Messy but maybe achievable.UPDATE:
just modified my script to look for extmem_start and extmem_stop functions in the p2asm file to delineate the external memory target and this command seems to work (at least for the coremark application).
flexspin -l -DITERATIONS=200 -O0,const -gbrk core_main.c extmem.c core_list_join.c core_util.c core_matrix.c core_state.c core_portme.c extmemoff.cI just created a closing extmemoff.c file with this function
void extmem_end(void) { return; }which assembles to this code after I patched it in my output file. I can then use extmem_start and extmem_end function names to enclose the external memory target functions. Ugly but it works at least for now.
_extmem_end ' { ' return; callpa ##_extmem_end_ret, farjmp_handler _extmem_end_ret ret FARCODE_ENDI've never really studied memory caching hardware but I've just come to a realisation that I've probably had an incorrect view of their behaviour. I've just been looking at a block diagram of HBM4, as recently posted to a news site, and it kind of drove home to me that cache doesn't initiate memory accesses at all. It only sits on the side lines and intercepts the data flows as suits it.
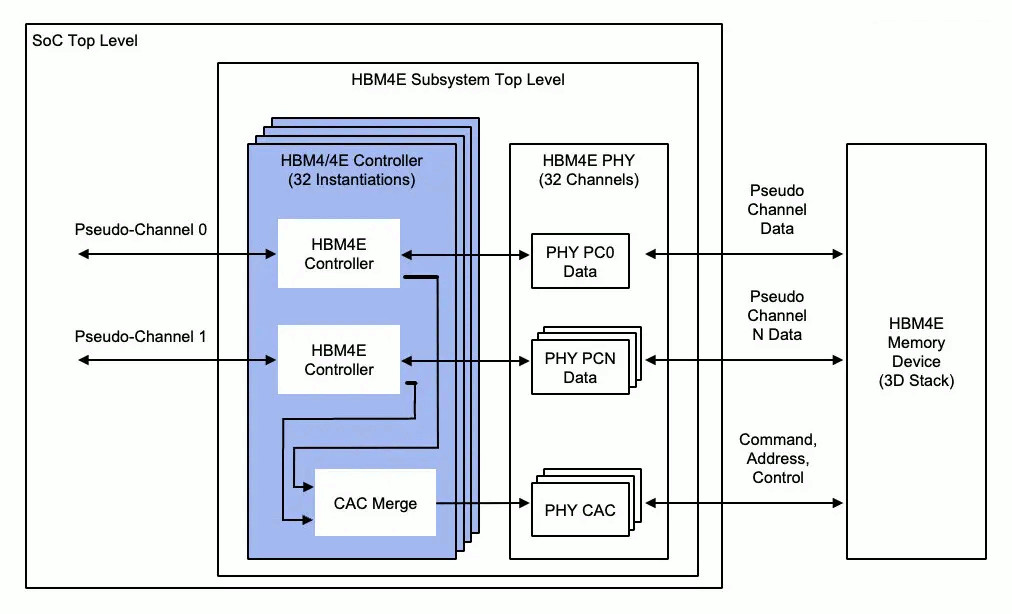
Note the allowance for up to 32 pseudo channels. A unified L3 cache isn't going to distinguish between threads/cores where as direct core to main memory accesses will easily be separable into channels matching each core or thread.
That's actually not at all how it typically works.
You definitely need memory access from the cache system, to store dirty evicted lines back into memory. There's also often an uncore prefetcher that observes LLC miss patterns. Shared caches also need to keep track of which core "owns" a line to avoid corruption. If e.g. two cores want to modify one value each that happen to be next to each other in the same line, the coherency algorithm needs to stop the second core from wholly overwriting the line with its own L1 cached version (where the first value hasn't been changed). That sort of "false sharing" typically causes severe slowdown to ensure correctness.
Mostly over and above where I was talking. The storing dirty lines I guess is slightly relevant in that the cache does address memory itself for that. But mainly I was talking about how the L3 cache is positioned in the data flow. For some reason I had imagined it stood in the middle, gobbling everything.
@rogloh Are there some small changes to flexspin we could make that would help you out? I think it would be straightforward to add new attributes like FAR and NEAR, but I'm not sure how to pass those through to the pasm file so that you could best make use of them. Maybe some kind of prefix/suffix attached to the name?
Yeah, as mentioned earlier, it's probably easier to just put support code for this in the actual compiler. It doesn't usually bite (unlike GCC or LLVM).
Incidentally, I'd for a while thought about adding more "classic style" overlay support (that you'd just load into memory as a whole). I feel like that could share a lot of implementation with roger's XMM thing here.
Basically need to be able to tag/color functions (and in the case of the classic overlays, constant data, too) as belonging to a group, then grouping them in the ASM output, ideally with useful marker comments to easily extract the portions needed. Ideally we'd be able to assemble usable binaries directly, but there's open questions as to how those should look like (alignments/checksums/etc). Though I'm thinking it'd be tricky to actually assemble it correctly, since the assembler doesn't really have a "pseudo PC" feature to assemble the code for a different load address.
Hi Eric. Yes some flexpin changes could be helpful. Here are my thoughts:
This external memory feature has two fundamental scenarios.
1) some greenfield C project code for the P2 that is or will become large needs to be placed into external RAM to make more HUB RAM space for other features & other COG's requirements. It's probably reasonably easy to rename or add some function attributes as you code it that control the function's placement in memory (hub vs external). It's a little tedious but still workable to do these changes as you code up your fresh project. This could involve attributes and/or prefixed names as long as they make it into the .p2asm file somehow. I think for that we could even have some commented out list at the end of the .p2asm file of all these external memory functions and my script could hunt for these function blocks to place them after $100000 in the modified file. Given the standardized formatting used in a .p2asm file it's fairly easy with SED to extract a given function name's code block up to the function_ret at the end of the function (plus the extra line after that).
2) some existing large codebase in C is being ported to the P2 and we need to put it into external RAM to make it fit. This was what I was attempting recently with LVGL (but now I think it probably has its own issues with its C99 requirements vs current flexspin capabilities as I'm seeing a very large number of errors when compiling - could still be some mistake in include file paths, but not sure yet - I could post more details on that topic after this).
We basically need a good way to identify which functions or files/C modules will be located in external memory that handle both scenarios. For now we might want any embedded SPIN2 object code to still remain in HUB RAM especially if they are to be shared with other regular SPIN2 COGs etc but maybe down the track these could also be optionally placed into high memory under our control.
I've already tried the prefixing approach and it works, but it's certainly going to become a bit of a nightmare for large C codebases under the second scenario as you need to edit lots of third party files/functions for this and anything written using existing macros for function names can be problematic too. So I think a better solution may be to have some binary switch state in the compiler (persisting across input files) that is on or off during compilation and probably under control of a #pragma which directs compilation to target either internal/external memory. Whenever the switch is off (the default) all output code targets internal memory as usual and when it is on the code targets external memory and will be generated after an ORGH $100000 statement in the p2asm file which separates low/high memory. My script can do this ORGH $100000 reordering step on a .p2asm file, but it just needs a list of functions which will be moved to the end of this file after the special ORGH statement. Perhaps we can add some comments at the end of the .p2asm file as mentioned above that lists this group of functions, or output it as another file that just contains the names of these functions that will need to be moved by my script.
For example the .p2asm file could print this at the end...
...<snip> local40 res 1 muldiva_ res 1 muldivb_ res 1 fit 480 ' EXT_TARGET external functions follow ' extfunction_name1 ' extfunction_name2 ' ...<more>Also while the switch is on we may have to override some of the optimizations to cancel those that will create unsupported instructions in the code. We can figure that part out as we go but I already have a list of all the unsupported instructions. I search through the high memory segment code to ensure the code doesn't have them before I try to run the code but ultimately it would be best enforced by the compiler, rather than checked after it generates the code.
For scenario 2 with this approach we can fairly easily enable/disable the switch state without even editing any imported project source files by compiling some dummy code in the module list order that simply enables or disables the external memory via the #pragma. For example to place some set of module's code in external memory we'd just separate these modules from the internal RAM target by ordering them on the command line (or in the .side file), as done with the following command:
flexspin -DITERATIONS=200 -O0,const -gbrk core_main.c extmem.c _core_list_join.c core_util.c core_matrix.c core_state.c core_portme.c_ extmemoff.cAt the end of extmem.c we'd have something like:
#pragma external-enableAnd in the extmemoff.c file at the end of the list of compiled files we'd simply have this:
#pragma external-disableThis would end up keeping core_main.c and extmem.c in internal memory, but the other functions in the other files would be placed in external memory.
In fact in this case we don't need to turn it off because it's the last thing in the list, we'd only need this if there were more internal modules following this.
The example above needs no file changes to the code targeting external memory, although if you wanted to you could still choose place the pragma's in these files.
One remaining issue are the library file functions called by the project file's C code. For now mostly they seem to be placed at the end of the .p2asm file. I'm assuming they won't be quite as large as the main project code's function so am just keeping these in internal memory for simplicity but eventually it would be nice to have a way to place them in external memory somehow as well. Not sure if/how that could be controlled. We'd potentially need some other input file like a linker's .ld file for example I suspect. This could use wildcards and other named strings to identify which functions from which files go where...?
Even the bare minimum of the #pragma that collects function names while it's enabled and then lists them also at the end of the .p2asm file is going to be helpful, although for now we probably need it to ignore embedded SPIN2 object API names detected while enabled. If its state can also reduce the optimizations applied to the external memory functions during the time it is activated that would still enable more optimizations to work with the internal functions (which otherwise would have to be turned off globally to be safe).
What are your own thoughts on the feasibility of these ideas for flexspin?
p.s. Also is there any way for flexspin to generate a pre-processor output file so we see the source code before its compiled but after the include files are included? Like the gcc -E option. Mainly relates to LVGL porting...
Also with this external memory feature in flexspin we may want to increase the number of source files that are allowed to be listed in a project file (or on the command line). I found that LVGL has over 400 smallish source files (after I reduced it down by removing extra demos/tests which are bundled in) and they already max out flexspin and I get an error. I'm still assuming its likely to fit into 16MB PSRAM as it only consumes 2.4MB of ARM64 code space when I build it all locally. So some increase to the compiler limits are likely needed for scaling up the image size.
Hi @ersmith
So I'm still trying to get this LVGL project to build with flexspin as an example of something large and ideal if it could run from external memory but am running into severe build issues using flexspin which almost makes it look like some include files are not being included or something related to unknown/unsupported types being assigned. It's meant to work with C99 compatible compilers so I was hoping that may include flexspin. What's weird is that it does build okay with the same list of files on my Mac locally using Gcc/Clang so it does appear that these could be real bugs/limitations of flexspin. I just don't really know if they are all known bugs or limitations or something new that might be fixable?
I did define the top level include path for the project file (included below in the zip) that is being passed into flexspin for this source tree and am presuming it is also recursive if there is an included file buried deeper and that flexspin won't simply silently fail if the file is not found in the defined include path(s).
The list of compiled C files in the project does get printed out initially (I'm presuming that's pass 1) then all the errors begin. I logged them all and split the errors and warnings into two different files in the attached zip and sorted and uniq'd them. Many are of the same type, like this sort of thing:
but I also got several other interesting things such as these presumably simple pointer conversion errors:
where this simple structure is defined
typedef struct { uint8_t blue; uint8_t green; uint8_t red; } lv_color_t;and the line numbered code using it is this:
266 uint32_t lv_color_to_int(lv_color_t c) 267 { 268 uint8_t * tmp = (uint8_t *) &c; // <-------------- ERRORS out, why? We can't get a pointer to a local? 269 return tmp[0] + (tmp[1] << 8) + (tmp[2] << 16); 270 } 271 272 bool lv_color_eq(lv_color_t c1, lv_color_t c2) 273 { 274 return lv_color_to_int(c1) == lv_color_to_int(c2); 275 } 276 277 bool lv_color32_eq(lv_color32_t c1, lv_color32_t c2) 278 { 279 return *((uint32_t *)&c1) == *((uint32_t *)&c2); // <-------- ERRORS out, why? 280 }Also this:
with the code shown below:
138 typedef union { 139 int32_t num; /**< Number integer number (opacity, enums, booleans or "normal" numbers)*/ 140 const void * ptr; /**< Constant pointers (font, cone text, etc)*/ 141 lv_color_t color; /**< Colors*/ 142 } lv_style_value_t; 416 lv_style_value_t lv_style_prop_get_default(lv_style_prop_t prop) 417 { 418 const lv_color_t black = LV_COLOR_MAKE(0x00, 0x00, 0x00); 419 const lv_color_t white = LV_COLOR_MAKE(0xff, 0xff, 0xff); 420 switch(prop) { 421 case LV_STYLE_TRANSFORM_SCALE_X: 422 case LV_STYLE_TRANSFORM_SCALE_Y: 423 return (lv_style_value_t) { 424 .num = LV_SCALE_NONE 425 }; 426 case LV_STYLE_BG_COLOR: 427 return (lv_style_value_t) { 428 .color = white // <--- doesn't like to assign a struct to the .color field element of lv_style_value_t union? 429 };And this sort of error:
with these defined types
47 typedef union { 48 int32_t num; /**< Integer number (opacity, enums, booleans or "normal" numbers) */ 49 const void * pointer; /**< Constant pointer (string buffer, format string, font, cone text, etc.) */ 50 lv_color_t color; /**< Color */ 51 #if LV_USE_FLOAT 52 float float_v; /**< Floating point value*/ 53 #endif 54 } lv_subject_value_t; 59 struct _lv_subject_t { 60 #if LV_USE_EXT_DATA 61 lv_ext_data_t ext_data; 62 #endif 63 lv_ll_t subs_ll; /**< Subscribers */ 64 lv_subject_value_t value; /**< Current value */ 65 lv_subject_value_t prev_value; /**< Previous value */ 66 lv_subject_value_t min_value; /**< Minimum value for min. int or float*/ 67 lv_subject_value_t max_value; /**< Maximum value for max. int or float*/ 68 void * user_data; /**< Additional parameter, can be used freely by user */ 69 uint32_t type : 4; /**< One of the LV_SUBJECT_TYPE_... values */ 70 uint32_t size : 24; /**< String buffer size or group length */ 71 uint32_t notify_restart_query : 1; /**< If an Observer was deleted during notification, 72 * start notifying from the beginning. */ 73 };and this assignment code:
356 void lv_subject_init_color(lv_subject_t * subject, lv_color_t color) 357 { 358 lv_memzero(subject, sizeof(lv_subject_t)); 359 subject->type = LV_SUBJECT_TYPE_COLOR; 360 subject->value.color = color; // <----- ERRORS 361 subject->prev_value.color = color; // <------ ERRORS 362 lv_ll_init(&(subject->subs_ll), sizeof(lv_observer_t)); 363 }Plus I get internal errors for which I'm not sure what is happening.
/Users/roger/Documents/Code/lvglproj/lvgl/src/core/lv_refr.c:336: error: Internal error, unknown type 114 passed to IsArrayTypeIt didn't like this expression below much:
/Users/roger/Documents/Code/lvglproj/lvgl/src/draw/lv_image_decoder.c:148: error: bad cast of expression147 /*Make a copy of args*/ 148 dsc->args = args ? *args : (lv_image_decoder_args_t) { 149 .stride_align = LV_DRAW_BUF_STRIDE_ALIGN != 1, 150 .premultiply = false, 151 .no_cache = false, 152 .use_indexed = false, 153 .flush_cache = false, 154 };So do you think there's much/any hope for fixes that could let this be built by flexspin or is this all too much for flexspin to work with?
Googling LVGL requirements resulted in this, which I thought may be reasonable on a P2 assuming the compiler worked:
Unfortunately LVGL is probably too much for flexspin to deal with, at least in its current state and particularly with the added complication of external memory.
You might have better luck with riscvp2, which is full GCC and already has support for putting code into flash memory. Although given the specs of LVGL it may not need external memory at all?
I'm still thinking about how to attack external memory in flexspin, but at least some of your suggestions seem feasible. We should be able to put some kind of annotations in the output .p2asm file. In the meantime, an easy fix was increasing the number of files that can fit in a .pide, and I've done that.
Ugh. Want to use native P2 code not RISCV instructions.
Want to use native P2 code not RISCV instructions.
I'm reasonably confident the external memory scheme I have is likely workable. The main issue is the final performance and how large the working set will be.
Thanks! Yeah the annotations in the .p2asm file will be a big help as will be increasing the number of files possible. Also some method of checking of this int/ext memory target mode (a new #pragma state) during optimization to restrict the actual enabled optimizations in external (far) target mode is likely needed so we can keep internal functions fully optimized and not need to disable them globally just because some will break the cached code. Although for now we can probably begin without that change and simply disable all risky optimizations but performance will be lowered more than it needs to be until such a change is done as well.
If you are looking for a good test program, how about Dave Hein's awesome P2 assembler (p2_asm)?
It is written in clean C and should compile "out of the box" with any C compiler. It is completely self-contained, self-verifying (from memory there is one test that fails - testjmploc - which I keep forgetting to fix because I never use the LOC instruction), is large enough to make a good test program, and is also a very useful tool to have available on any Propeller 2!
I think Dave's original source is still online somewhere (although I can't currently find it after doing a quick search) but the source is also included in Catalina (in catalina/source/p2_asm). There are a few minor Catalina-specific extensions, but these are surrounded by #ifdef ... #endif and are disabled unless you compile it with Catalina.
Ross.
Yeah I've used it before and also modified it slightly back then to allow native P2 MicroPython to work on the P2. Not a bad idea for something that might work if flexspin can compile it and if the internal RAM is sufficient for compiling programs. Will need to keep that in mind.
The reason I still have hope is that with some changes I made that make flexspin happier (remove inline and const and rename some variables) I've been able to get the error list down to only the same type of incompatible assignment type error and if you do end up finding a general fix for that issue it might potentially resolve all of them (with any luck).
I do have one other strange error left though which is some internal error now reported in the C startup code added automatically at the end - not part of my project list but something flexspin is adding. Strangely it is reported on line 24 and the file only goes up to line 23.
./Users/roger/Applications/spin2cpp/include/libsys/c_startup.c:24: error: Internal error, unknown type 114 passed to IsArrayType1 // 2 // startup code for C 3 // 4 #include <sys/ioctl.h> 5 #include <sys/argv.h> 6 #include <stdlib.h> 7 8 void _c_startup() 9 { 10 int r; 11 int argc = 0; 12 char **argv; 13 14 #ifdef __FLEXC_NO_CRNL__ 15 _setrxtxflags(TTY_FLAG_ECHO); // make sure TTY_FLAG_CRNL is off 16 #endif 17 18 _waitms(20); // brief pause 19 argv = __fetch_argv(&argc); 20 r = main(argc, argv); 21 _waitms(20); // brief pause 22 _Exit(r); 23 } ~All the other ~380 errors are this type of thing...
/Users/roger/Documents/Code/lvglproj/lvgl/src/core/lv_obj_draw.c:133: error: incompatible types in assignment: expected _struct___anon_98b868fb0000006d but got unknown type
/Users/roger/Documents/Code/lvglproj/lvgl/src/core/lv_obj_draw.c:243: error: incompatible types in assignment: expected _struct___anon_98b868fb0000006d but got unknown type
/Users/roger/Documents/Code/lvglproj/lvgl/src/core/lv_obj_draw.c:470: error: incompatible types in assignment: expected _struct___anon_98b868fb0000006d but got unknown type
/Users/roger/Documents/Code/lvglproj/lvgl/src/core/lv_obj_draw.c:471: error: incompatible types in assignment: expected _struct___anon_98b868fb0000006d but got unknown type
/Users/roger/Documents/Code/lvglproj/lvgl/src/core/lv_obj_draw.c:492: error: incompatible types in assignment: expected _struct___anon_98b868fb00000079 but got unknown type
/Users/roger/Documents/Code/lvglproj/lvgl/src/core/lv_obj_draw.c:493: error: incompatible types in assignment: expected _struct___anon_98b868fb00000079 but got unknown type
/Users/roger/Documents/Code/lvglproj/lvgl/src/core/lv_obj_draw.c:500: error: incompatible types in assignment: expected _struct___anon_98b868fb00000079 but got unknown type
/Users/roger/Documents/Code/lvglproj/lvgl/src/core/lv_obj_pos.c:1151: error: incompatible types in assignment: expected _struct___anon_ea3968a50000002a but got _struct___anon_306468b10000002a
/Users/roger/Documents/Code/lvglproj/lvgl/src/core/lv_obj_style.c:650: error: incompatible types in assignment: expected _struct___anon_98b868fb00000079 but got unknown type
/Users/roger/Documents/Code/lvglproj/lvgl/src/core/lv_obj_style.c:663: error: incompatible types in assignment: expected _struct___anon_98b868fb00000079 but got unknown type
/Users/roger/Documents/Code/lvglproj/lvgl/src/core/lv_obj_style.c:997: error: incompatible types in assignment: expected _struct___anon_98b868fb0000006d but got unknown type
/Users/roger/Documents/Code/lvglproj/lvgl/src/draw/lv_draw.c:107: error: incompatible types in assignment: expected _struct___anon_306468b10000002a but got const _struct___anon_ea3968a50000002a
/Users/roger/Documents/Code/lvglproj/lvgl/src/draw/lv_draw.c:108: error: incompatible types in assignment: expected _struct___anon_306468b10000002a but got const _struct___anon_ea3968a50000002a
/Users/roger/Documents/Code/lvglproj/lvgl/src/draw/lv_draw.c:426: error: incompatible types in assignment: expected _struct___anon_98b868fb00000079 but got unknown type
/Users/roger/Documents/Code/lvglproj/lvgl/src/draw/lv_draw.c:460: error: incompatible types in assignment: expected _struct___anon_306468b10000002a but got const _struct___anon_ea3968a50000002a
/Users/roger/Documents/Code/lvglproj/lvgl/src/draw/lv_draw.c:461: error: incompatible types in assignment: expected _struct___anon_306468b10000002a but got const _struct___anon_ea3968a50000002a
/Users/roger/Documents/Code/lvglproj/lvgl/src/draw/lv_draw.c:462: error: incompatible types in assignment: expected _struct___anon_306468b10000002a but got const _struct___anon_ea3968a50000002a
/Users/roger/Documents/Code/lvglproj/lvgl/src/draw/lv_draw.c:539: error: incompatible types in assignment: expected _struct___anon_ea3968a50000002a but got _struct___anon_306468b10000002a
/Users/roger/Documents/Code/lvglproj/lvgl/src/draw/lv_draw.c:560: error: incompatible types in assignment: expected _struct___anon_ea3968a50000002a but got _struct___anon_306468b10000002a
/Users/roger/Documents/Code/lvglproj/lvgl/src/draw/lv_draw_arc.c:44: error: incompatible types in assignment: expected _struct___anon_98b868fb0000006d but got unknown type
/Users/roger/Documents/Code/lvglproj/lvgl/src/draw/lv_draw_image.c:354: error: incompatible types in assignment: expected _struct___anon_d2d368f40000006d but got _struct___anon_98b868fb0000006d
/Users/roger/Documents/Code/lvglproj/lvgl/src/draw/lv_draw_image.c:53: error: incompatible types in assignment: expected _struct___anon_98b868fb0000006d but got unknown type
/Users/roger/Documents/Code/lvglproj/lvgl/src/draw/lv_draw_label.c:358: error: incompatible types in assignment: expected _struct___anon_98b868fb0000006d but got unknown type
/Users/roger/Documents/Code/lvglproj/lvgl/src/draw/lv_draw_label.c:460: error: incompatible types in assignment: expected _struct___anon_98b868fb0000006d but got unknown type
/Users/roger/Documents/Code/lvglproj/lvgl/src/draw/lv_draw_label.c:500: error: incompatible types in assignment: expected _struct___anon_98b868fb0000006d but got _struct___anon_d2d368f40000006d
/Users/roger/Documents/Code/lvglproj/lvgl/src/draw/lv_draw_label.c:510: error: incompatible types in assignment: expected _struct___anon_98b868fb0000006d but got _struct___anon_d2d368f40000006d
/Users/roger/Documents/Code/lvglproj/lvgl/src/draw/lv_draw_label.c:519: error: incompatible types in assignment: expected _struct___anon_98b868fb0000006d but got _struct___anon_d2d368f40000006d
/Users/roger/Documents/Code/lvglproj/lvgl/src/draw/lv_draw_label.c:523: error: incompatible types in assignment: expected _struct___anon_d2d368f40000006d but got _struct___anon_98b868fb0000006d
Following up from this. I just downloaded the late Dave Hein's code (found here: https://github.com/davehein/p2gcc )
It does seem to build on Flexspin first time (only two warnings) and consumes 884416 bytes, so yes it's a good candidate for running from external RAM. I'll have to see how much internal RAM it needs to run ok and try to setup some sort of test with a filesystem somehow. Unfortunately right now I'm getting segfaults with my psram driver and flexspin building it so not sure what is going on, worked fine a few days ago when I used it last. Need to figure it out and fix that first.
EDIT: Actually that 884416 was wrong because that number was before running my script on it, and it included some of the p2asm data structures. The symbol table consumed 320000 bytes, and the data buffer was set to 1000000 bytes. So of the 1408704 bytes reported the actual total assembler program code is very small, only 88704 bytes. It's arguable whether it's worth putting that into external memory when you still need a cache and block map table, may as well keep it in internal hub RAM. Maybe if the linker is included it will consume more...yep but only 47kB, and data is 2.6MB! I guess some of that could be put into external RAM as well).
Cheers,
Roger.
Another good candidate would be Lua - written in clean C which should compile with any C compiler, completely self-contained and also easy to verify. And with a code size around 250kb.
A word of warning though - once you start programming in Lua, you won't ever want to go back to any other language!")
Ross.
How much are you writing in assembly though? If you're worried about performance, riscvp2 does eventually compile the code to native P2, just at runtime rather than ahead of time. It's coremark score is around 52 iterations/sec at 180 MHz (when run from HUB or Flash; results are the same either way) vs around 37 iterations/sec for flexspin and 17 for an older Catalina.
I was remiss earlier in not mentioning Catalina, which already has external memory support too. Although I'd definitely be very happy to have you continue to work on an external memory solution for flexspin, which would be awesome") but if you need something working sooner then Catalina may do the job.
but if you need something working sooner then Catalina may do the job.
I'll continue looking into that. On that note, do you think you could re-post your current code? The all.zip that you posted up-thread was missing the actual lvgl directory .
.
When the error comes at the end of the file like that it usually means it's some internal issue not really associated with any source code (and the source file name is probably bogus too). The particular error is complaining about trying to find the type, and 114 is an AST_USING, so it's probably upset about a
struct __usingstatement somewhere. It might be related somehow to the other struct errors, hard to say.