

VGA 640x480, 800x600, 1024x768, 1280x960 full color ANSI text driver
 ersmith
Posts: 6,148
ersmith
Posts: 6,148
(2020-08-15): Version 1.0: Ported to PNut, added 16x32 font support, added 1280x960 mode
(2019-10-02: Version 0.6: 8bpp color support, new silicon support, and converted C driver for Catalina and riscvp2)
(3/01/2019: Version 0.5: Re-arranged to make using multiple monitors possible. Added simple C and BASIC demos.)
(2/19/2019: Version 0.4. Fixed a nasty bug in the vsync polarity. Please update!)
(2/19/2019: Updated again with a newer driver that supports 1024x768 and has better sync at 640x480)
(2/18/2019: Updated with a screenshot and newer driver.)
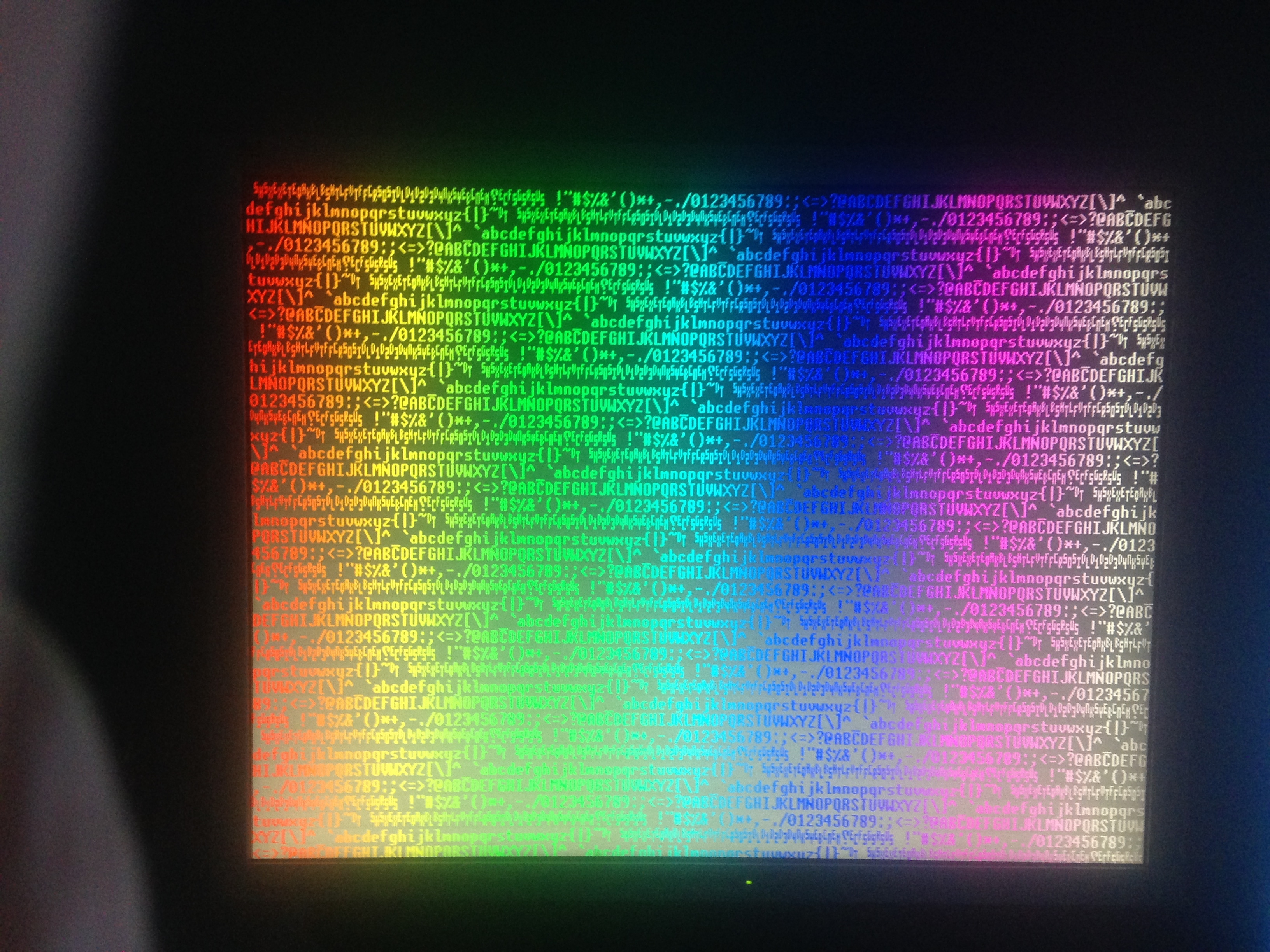
This is still a work in progress, but it seems to sync OK on my monitor. It uses a 1bpp bitmap with 256 characters. The font provided is 8x16, so we get 80x30 characters at 640x480 and 100x40 characters at 800x600 (we only use 15 rows of the font in the latter case). Each character can have arbitrary background and foreground colors, so each character takes up 8 bytes of memory; thus the 800x600 case uses 100*40*8 = 32000 bytes of memory for the screen. The way it works generates 8 pixels at a time, so practically speaking the font has to be 8 pixels wide, but can be any height.
Internally it loads one row of the font into COG RAM during horizontal blanking, and uses getbyte to look up the pixel data for each character from that font row, while placing the fg and bg colors into the LUT for display. Doing this for higher resolutions is probably going to be difficult, although I'm sure there are ways to shave some cycles off the inner loop.
The demo only works properly in the most recent fastspin (3.9.20) because it uses setpiv to blend pixel colors, and earlier fastspins had a bug in that instruction. The actual driver should be OK with older fastspin and should easily port to PNut (there's just the usual Start/Stop Spin methods, most of the driver code is in PASM).
 ;
;
(2019-10-02: Version 0.6: 8bpp color support, new silicon support, and converted C driver for Catalina and riscvp2)
(3/01/2019: Version 0.5: Re-arranged to make using multiple monitors possible. Added simple C and BASIC demos.)
(2/19/2019: Version 0.4. Fixed a nasty bug in the vsync polarity. Please update!)
(2/19/2019: Updated again with a newer driver that supports 1024x768 and has better sync at 640x480)
(2/18/2019: Updated with a screenshot and newer driver.)
This is still a work in progress, but it seems to sync OK on my monitor. It uses a 1bpp bitmap with 256 characters. The font provided is 8x16, so we get 80x30 characters at 640x480 and 100x40 characters at 800x600 (we only use 15 rows of the font in the latter case). Each character can have arbitrary background and foreground colors, so each character takes up 8 bytes of memory; thus the 800x600 case uses 100*40*8 = 32000 bytes of memory for the screen. The way it works generates 8 pixels at a time, so practically speaking the font has to be 8 pixels wide, but can be any height.
Internally it loads one row of the font into COG RAM during horizontal blanking, and uses getbyte to look up the pixel data for each character from that font row, while placing the fg and bg colors into the LUT for display. Doing this for higher resolutions is probably going to be difficult, although I'm sure there are ways to shave some cycles off the inner loop.
The demo only works properly in the most recent fastspin (3.9.20) because it uses setpiv to blend pixel colors, and earlier fastspins had a bug in that instruction. The actual driver should be OK with older fastspin and should easily port to PNut (there's just the usual Start/Stop Spin methods, most of the driver code is in PASM).
; 3264 x 2448 - 3M
zip
34K
Comments
XDIV needs to be a low value (like 1 or 2) for the current silicon.
800x600 doesn't work for me.
Also, changed basepin...
Adding the bitmap file into the DAT section seems to crash Fastspin…
Doesn't seem to like a giant file being dropped in... Works if change to a small file...
DAT ' ' ' Bitmap 'bitmap buffer starts at $1000 ' orgh '$1000 - $436 'justify pixels at $1000, pallete at $1000-$400 bitmap file "bitmap2.bmp"'combined1.bmp" 'bitmap2.bmp '640 x 480, 8pbb-lut buffer 'tile buffer long 0[COLS*ROWS*2] ' ' font buffer ' long fontdata file "unscii-16.bin" ' file "unscii-8-fantasy.bin" '================================================================================================================= ' BELOW HERE IS THE DEMO CODE '================================================================================================================= democolors long $FF000000, $FFFF0000, $00FF0000, $00FFFF00 long $0000FF00, $FF00FF00, $FFFFFF00, $00000000 long $7F000000, $007F7F00, $007F0000Can you post images of the jitter vs PFD MHz for your P2/Monitor combination ?
Does it suddenly get worse, or just gradually ?
ie is /3 usable (6.66'MHz), or is 10MHz PFD needed ?
Trying to get a feel for the 'minimum MHz' that P2 PFD can run at, for various VGA pairings.
How tolerant is your monitor to Line Scan and Pixel clocks ?
eg 26MHz, which is a cheap GPS TCXO value, can yield
PFD = 26M/3 = 8.666'MHz
Err = 1-29*(26M/3)/(25.175M*10) = 0.165%
I've optimized the pixel loop and can now display 1024x768. To do that I'm overclocking the P2 Eval board to 200 MHz, but my board at least doesn't feel too warm when I do this -- but your mileage may vary, so you may or may not want to actually try it yourself. (It sounds like many people have gone above 200 MHz so it's probably not too crazy.)
I think that's the limit for full color foreground and background, changing on every character (hah! someone will prove me wrong
IIRC Chip was hoping to target 250MHz as a more formal spec (HDMI min) , in the P2+ at OnSemi now - maybe with lower Max Tj, and tighter supply specs.
Of course, that depends on just how the P&R goes at OnSemi, and there is more logic in 2+... time will tell.
Although I think some gaming ones do 120 Hz...
The new version of the 640x480 demo runs at 60Hz (like the 800x600 and 1024x768 ones) and syncs fine on my monitor.
Gaming monitors come in 120Hz and 144Hz flavors.
Also, I doubt you would damage an analog monitor with bad signal data (like pos vs neg hsync, or off timings), unless it was a really crappy monitor in the first place.
Thanks for checking this on the scope! I wouldn't have noticed that the polarity was wrong, my monitor was only looking at horizontal polarity.
Given HDMI needs 10x the data rate of the pixel rate, 640x480's 250MHz data rate would normally be considered the only viable resolution for the Prop2. In an attempt to go higher I've been playing with display timing of the vgatile driver. My LCD TV seems extremely forgiving of timings for any particular known resolution ... but it doesn't accept an unknown resolution. I suspect modern 16:9 monitors/TVs will generally have similar "reduced blanking" capabilities. After all, they have no need of retrace times.
What I've been able to do is start from the spec'd 34MHz pixel rate of 848x480@60Hz mode and chop down the timings until I've even got 848x480 at 25MHz working.
Question is, does this work for anyone else at all?
https://forums.parallax.com/discussion/download/125779/vga848x480.spin2
One thing I'm not sure others are seeing though...I've seen it with all of these - is that the left and/or right is chopped off...haven't tried it with this mode yet, but have been able to adjust the timings set in the driver to get it to fit onscreen. This is a cheapo little 4-something inch LCD though. I suspect it's mostly to blame, as I remember running into the same with a lot of the P1-based drivers, as well...got to get my hands on a better VGA monitor, heh.
That means the image offered needs to have a definite edge - black backgrounds do not work as well, & any errant pixels outside display window can confuse it.
Not sure how that squeezed flyback will interact with the auto-fit ?
Yup! Neg and Pos both now reflect correctly here
This one should be more universal but will run hotter when targetting HDMI.
EDIT: Updated comments in source
EDIT2: Revised for 60 Hz vsync because it fit
Will be interesting to see how closely HDMI timings track these VGA timings and also if monitors and TVs differ from each other on HDMI.
EDIT: +1 to vsync
EDIT2: Added lots of experiments as options to the timings
Yes it will be. I know my 24 inch Dell LCD (over DVI) took all sorts of weird timing and resolutions I threw at it using an HDMI signal from my custom FPGA implementation. I suspect HDTV's may be somewhat less forgiving but it would probably vary and is worth playing around with.
Keeping above those two figures, the biggest problem mostly was that the TV or monitor would detect wrong resolution and make an ugly picture.
PS: I'm hoping HDMI devices have higher chance of making use of the integral clock and be much better with resolution detection.
I've also added some very simple examples of how to use this from C (fastspin only for now, sorry) and BASIC.
There are a bunch of improvements over the last version:
(1) The new silicon is supported. The hardware is checked at run time so both old and new silicon are supported by the same binary (only the streamer parameters have to change).
(2) Memory used is more configurable: you can have either 8 bytes per character (allowing for full 24bpp on each of the foreground and background colors for each character) or 4 bytes per character (allowing 8bpp ANSI palette for foreground and background colors). Other than the color we also have 2 bytes per character for the character itself and for special effects.
(3) A C version of the driver is provided. This is converted automatically from the Spin driver via spin2cpp. I've tested it with riscvp2 and Catalina. p2gcc doesn't have the propeller2.h support that's needed, but perhaps eventually the new PropGCC will. FlexC (aka fastspin) doesn't work with this converted C driver yet, but it can use the Spin code directly so that's not a big problem.
The documentation is still a little sparse, but I hope the demos (demo.spin2, basdemo.bas, and ccode/cdemo.c) will show basic usage at least. For C only the 800x600 driver is provided, but you can change ccode/Makefile to use one of the other sizes if you'd like. For BASIC or Spin (or FlexC), pick a driver and instantiate it like:
obj vga: "vgatext_640x480.spin2" ... vga.start(BASEPIN) vga.str(string("Hello, world!"))The parameter to the start function is the base pin of the VGA hardware. For the P2-Eval board this is usually a multiple of 8; I've defaulted to 48, but use whatever pin group your hardware is plugged in to. After initialization, you can write characters to the object using the usual methods .tx, .str, .dec, and so on. ANSI escape sequences may be used to change colors or provide special effects for the text.Source code is on my github at:
https://github.com/totalspectrum/p2_vga_text
I should try HDMI out again myself ...
- Support for a variety of resolutions from 640x480 to 1280x960
- Support for a variety of color depths, from monochrome with no effects (1 byte per character) to full color with underline, strikethrough, blinking, and similar effects (8 bytes per character)
- Included 8x8, 8x16, and 16x32 fonts (the latter is the Parallax P1 font)
- Interprets most ANSI escape sequences for cursor positioning, text modification, color changes, and effects changes, so standard terminal control codes may be used
- Runs with fastspin and PNut
Some of my applications need the 640 x480 resolution screen but with 15 x40 tile sizes, the original 16x32 P1 font is a plus. I also like that is works with FastSpin and PNut, and supports the "View Character Chart" pick & place P1 full character set. ( Is it possible to add a DAT file of custom/user P1 graphics/text characters? - I will see if I can modify the VGA driver to do this )
First look and test of Version 1.0 VGA driver looks very promising for what I need. I will be integrating it into my P2 WorkBench program in the next day or so. Stay tuned for some application programs...